Legible and Intuitive Multi-modal Robot State and Intent Communication Validated in Online and Real-world Studies
Pith reviewed 2026-06-25 23:58 UTC · model grok-4.3
The pith
Highly expressive multimodal robot communication with gaze, gestures and voice is perceived as more legible and intuitive than unimodal LED-based signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
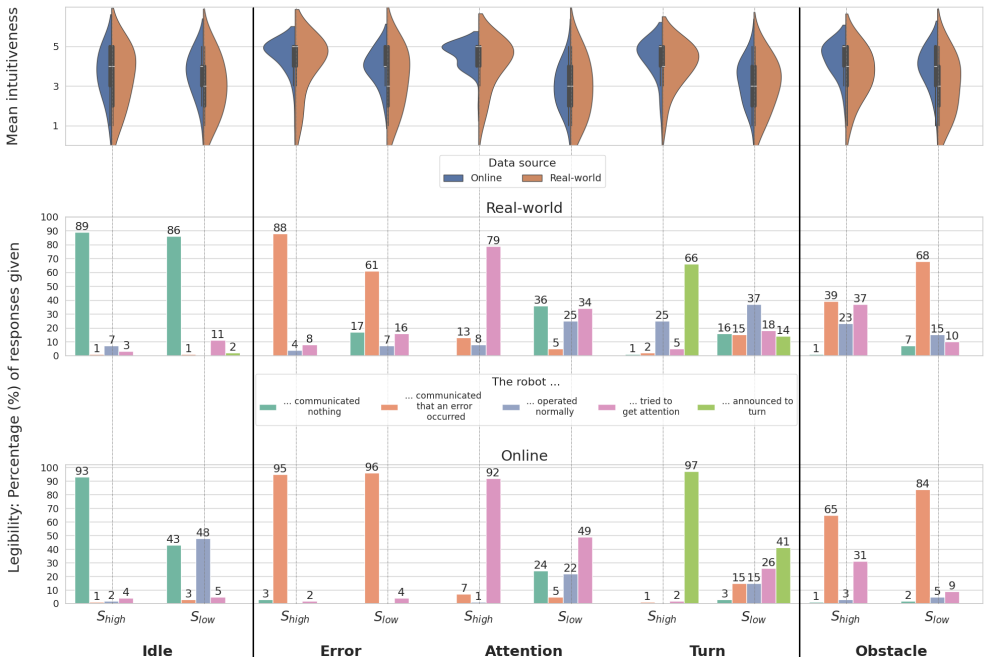
We present a systematic, large-scale comparative validation of existing communication strategies for a mobile non-humanoid robot across message types and settings (online and in-person). Based on the prescribed message types in the existing standards for industrial robots, we realize and compare a low-expressive, unimodal LED-based strategy with a highly expressive, multimodal one that leverages robotic gaze, gestures, and voice. For each strategy, we analyze the communication of a turning intention, an attention request, error status, whether the robot is stuck, and whether it is functioning normally. We find strong evidence that highly expressive multimodal communication is perceived as mo
What carries the argument
The direct comparison of a unimodal LED-based strategy versus a multimodal strategy using gaze, gestures, and voice, applied to the five message types prescribed by industrial robot standards.
If this is right
- Multimodal communication using gaze, gestures, and voice receives higher legibility and intuitiveness ratings than LED-only signals in both online and real-world settings.
- Overall legibility decreases when shifting from online video evaluations to real-world physical interactions, with a larger drop for LED-based signals.
- User confidence in correctly interpreting robot messages is lower in real-world evaluations than in online studies.
- Clearer multimodal communication can contribute to safer human-robot collaboration by reducing uncertainty about robot state and intent.
Where Pith is reading between the lines
- Designers of mobile robots may need to add expressive modalities even when hardware constraints favor simple LEDs, because the legibility gain appears consistent across tested conditions.
- Video-based studies of robot communication likely overestimate real-world performance, especially for low-expressivity methods like LEDs.
- Future work could test whether the observed online-to-real drop persists across different robot morphologies or additional message types beyond the five industrial standards.
- The gap between settings suggests that in-person validation should become standard practice before deploying communication strategies in collaborative environments.
Load-bearing premise
That the five prescribed message types from industrial robot standards, together with the specific LED implementation versus gaze/gesture/voice choices, capture the main real-world interpretation differences and that online video-based judgments generalize meaningfully to in-person physical interactions.
What would settle it
An experiment using a broader set of message types or different robot hardware in which participants rate multimodal communication no higher in legibility or intuitiveness than LED-only communication during in-person trials.
Figures



read the original abstract
Effective robot-to-human communication can increase transparency and trust, reduce uncertainty, and contribute to safer collaboration in shared workspaces. Designing and validating an effective robot communication strategy is challenging due to the varying and often limited communication modalities across robots, differences in how diverse recipients interpret messages, and the underexplored virtual-to-real gap in studies of communication legibility. We present a systematic, large-scale comparative validation of existing communication strategies for a mobile non-humanoid robot across message types and settings (online and in-person). Based on the prescribed message types in the existing standards for industrial robots, we realize and compare a low-expressive, unimodal LED-based strategy with a highly expressive, multimodal one that leverages robotic gaze, gestures, and voice. For each strategy, we analyze the communication of a turning intention, an attention request, error status, whether the robot is stuck, and whether it is functioning normally. We evaluate these strategies in replicated online and in-person experiments. We find strong evidence that highly expressive multimodal communication is perceived as more legible and intuitive than unimodal LED-based communication. Comparing the online and real-world study findings, we observe a notable decrease in overall legibility, particularly for signaling with LEDs. Similarly, confidence in message interpretation decreases during the real-world evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a comparative empirical study of communication strategies for a mobile non-humanoid robot. It implements and evaluates a low-expressive unimodal LED-based approach against a highly expressive multimodal approach (gaze, gestures, voice) for five message types drawn from industrial robot standards (turning intention, attention request, error status, stuck, normal functioning). The strategies are tested in replicated online video-based and in-person real-world experiments, with the central finding that multimodal communication is perceived as more legible and intuitive, accompanied by an overall drop in legibility in the real-world setting (especially for LEDs) and reduced confidence in interpretations.
Significance. If the reported outcomes are supported by adequate sample sizes, statistical controls, and transparent methods, the work supplies useful evidence on the benefits of multimodal over unimodal signaling in HRI and on the virtual-to-real gap in legibility judgments. The choice to anchor the message types in existing industrial standards and the replicated online/in-person design are strengths that enhance applicability to collaborative robotics.
major comments (1)
- [Abstract] Abstract: the assertion of 'strong evidence' that multimodal communication is superior rests on study outcomes, yet the abstract supplies no participant numbers, statistical tests, effect sizes, or controls for confounds. This information is load-bearing for evaluating whether the data actually support the headline claim of superiority and the reported real-world drop.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below and agree that the abstract requires revision to better support its claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'strong evidence' that multimodal communication is superior rests on study outcomes, yet the abstract supplies no participant numbers, statistical tests, effect sizes, or controls for confounds. This information is load-bearing for evaluating whether the data actually support the headline claim of superiority and the reported real-world drop.
Authors: We agree with this observation. The abstract's claim of 'strong evidence' would be more transparent if it included key quantitative details. We will revise the abstract to report the sample sizes for both the online and real-world studies, reference the statistical tests performed (including any corrections for multiple comparisons), note effect sizes for the primary comparisons between multimodal and LED conditions, and briefly acknowledge controls such as randomized message order and participant screening. These additions will be kept concise to respect abstract length limits while addressing the concern directly. revision: yes
Circularity Check
No significant circularity
full rationale
This is a purely empirical comparative study reporting legibility ratings from online video and in-person experiments across five message types. No equations, derivations, fitted parameters, predictions, or self-citation chains appear in the abstract or described structure. All claims rest on direct study outcomes rather than any reduction to inputs by construction, self-definition, or imported uniqueness theorems. The central finding (multimodal preference) is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of human-subject experiments including representative participant sampling and unbiased message interpretation
Reference graph
Works this paper leans on
-
[1]
A literature survey of how to convey transparency in co-located human–robot interaction,
S. Y . Sch ¨ott, R. M. Amin, and A. Butz, “A literature survey of how to convey transparency in co-located human–robot interaction,” Multimodal Technologies and Interaction, vol. 7, no. 3, p. 25, 2023
2023
-
[2]
External human–machine interfaces for automated vehicles in shared spaces: A review of the human–computer interaction literature,
S. Brill, W. Payre, A. Debnath, B. Horan, and S. Birrell, “External human–machine interfaces for automated vehicles in shared spaces: A review of the human–computer interaction literature,”Sensors, 2023
2023
-
[3]
External human–machine interfaces for autonomous vehicle-to-pedestrian communication: A review of empirical work,
A. Rouchitsas and H. Alm, “External human–machine interfaces for autonomous vehicle-to-pedestrian communication: A review of empirical work,”Frontiers in psychology, 2019
2019
-
[4]
Enhancing human under- standing of a mobile robot’s state and actions using expressive lights,
K. Baraka, S. Rosenthal, and M. Veloso, “Enhancing human under- standing of a mobile robot’s state and actions using expressive lights,” inProceedings the 25th IEEE RO-MAN, 2016
2016
-
[5]
Ad- vantages of multimodal versus verbal-only robot-to-human communi- cation with an anthropomorphic robotic mock driver,
T. Schreiter, L. Morillo-Mendez, R. T. Chadalavada, A. Rudenko, E. Billing, M. Magnusson, K. O. Arras, and A. J. Lilienthal, “Ad- vantages of multimodal versus verbal-only robot-to-human communi- cation with an anthropomorphic robotic mock driver,” in2023 32nd International Conference on Robot and Human Interactive Communi- cation (RO-MAN). IEEE, 2023
2023
-
[6]
Do you feel safe with your robot? factors influencing perceived safety in human-robot interaction based on subjective and objective measures,
N. Akalin, A. Kristoffersson, and A. Loutfi, “Do you feel safe with your robot? factors influencing perceived safety in human-robot interaction based on subjective and objective measures,”International journal of human-computer studies, 2022
2022
-
[7]
Help or hindrance: Understanding the impact of robot communication in action teams,
T. Tanjim, J. S. George, K. Ching, and A. Taylor, “Help or hindrance: Understanding the impact of robot communication in action teams,” arXiv preprint arXiv:2506.08892, 2025
arXiv 2025
-
[8]
Virtually the same or realistically different?: A meta-analysis of real vs.‘not so real’robots,
C. Esterwood, R. H. Guan, X. Ye, and L. P. Robert, “Virtually the same or realistically different?: A meta-analysis of real vs.‘not so real’robots,” inProceedings of the 20th ACM/IEEE HRI, 2025
2025
-
[9]
Legibility and predictability of robot motion,
A. D. Dragan, K. C. Lee, and S. S. Srinivasa, “Legibility and predictability of robot motion,” inProc. of the ACM/IEEE Int. Conf. on Human-Robot Interaction (HRI), 2013
2013
-
[10]
Legibility of robot behavior: A literature review,
C. Lichtenth ¨aler and A. Kirsch, “Legibility of robot behavior: A literature review,”HAL open science, 2016
2016
-
[11]
Show me your moves! conveying navigation intention of a mobile robot to humans,
A. D. May, C. Dondrup, and M. Hanheide, “Show me your moves! conveying navigation intention of a mobile robot to humans,” in European Conference on Mobile Robots (ECMR), 2015
2015
-
[12]
Passive demonstrations of light-based robot signals for improved human interpretability,
R. Fernandez, N. John, S. Kirmani, J. Hart, J. Sinapov, and P. Stone, “Passive demonstrations of light-based robot signals for improved human interpretability,” inProc. of the IEEE Int. Symp. on Robot and Human Interactive Comm. (RO-MAN), 2018
2018
-
[13]
Methods for expressing robot intent for human–robot collaboration in shared workspaces,
G. Lemasurier, G. Bejerano, V . Albanese, J. Parrillo, H. A. Yanco, N. Amerson, R. Hetrick, and E. Phillips, “Methods for expressing robot intent for human–robot collaboration in shared workspaces,” ACM Transactions on Human-Robot Interaction (THRI), 2021
2021
-
[14]
Seeing meaning: How congruent robot speech and gestures impact human intuitive understanding of robot intentions,
M. van Otterdijk, B. Laeng, D. Saplacan-Lindblom, A. Baselizadeh, and J. Tørresen, “Seeing meaning: How congruent robot speech and gestures impact human intuitive understanding of robot intentions,” International Journal of Social Robotics (IJSR), 2025
2025
-
[15]
A framework to study and design communication with social robots,
L. Kunold and L. Onnasch, “A framework to study and design communication with social robots,”Robotics, 2022
2022
-
[16]
Computerimplementiertes Verfahren zum Trainieren wenigstens eines Algorithmus f ¨ur eine Steuereinheit eines Kraftfahrzeugs,
C. Thiem and U. Eberle, “Computerimplementiertes Verfahren zum Trainieren wenigstens eines Algorithmus f ¨ur eine Steuereinheit eines Kraftfahrzeugs,” German Patent Application DE102 021 202 083A1
-
[17]
Mobile service robot state revealing through expressive lights: formalism, design, and evaluation,
K. Baraka and M. M. Veloso, “Mobile service robot state revealing through expressive lights: formalism, design, and evaluation,”Inter- national Journal of Social Robotics (IJSR), 2018
2018
-
[18]
Integrat- ing robot manufacturer perspectives into legible factory robot light communications,
A. Bacula, J. Mercer, J. Berger, J. Adams, and H. Knight, “Integrat- ing robot manufacturer perspectives into legible factory robot light communications,”ACM Transactions on HRI, 2023
2023
-
[19]
The semantic specificity of gestures when verbal communication is not possible: The case of emergency evacuation,
G. Prati, L. Pietrantoni, and representatives of the Main School of Fire Service in Warsaw, “The semantic specificity of gestures when verbal communication is not possible: The case of emergency evacuation,” International Journal of Psychology, vol. 48, no. 5, pp. 762–771, 2013
2013
-
[20]
Let me explain why i didn’t take the action you wanted!
N. Akalin and M. Riveiro, “Let me explain why i didn’t take the action you wanted!”Proc. of the IEEE Int. Symp. on Robot and Human Interactive Comm. (RO-MAN), 2025
2025
-
[21]
Exploring the impact of explanation representation on user satisfaction in robot navigation,
A. Halilovic, V . Chandrayan, and S. Krivic, “Exploring the impact of explanation representation on user satisfaction in robot navigation,” in Proceedings of the 2024 International Symposium on Technological Advances in Human-Robot Interaction, 2024
2024
-
[22]
Unlocking human-robot synergy: The power of intent communication in warehouse robotics,
S. S. Bhattathiri, A. Bogovik, M. Abdollahi, C. Hochgraf, M. E. Kuhl, A. Ganguly, A. Kwasinski, and E. Rashedi, “Unlocking human-robot synergy: The power of intent communication in warehouse robotics,” Applied Ergonomics, 2024
2024
-
[23]
Social robotics,
C. Breazeal, K. Dautenhahn, and T. Kanda, “Social robotics,”Springer handbook of robotics, 2016
2016
-
[24]
Embodiment matters in social hri research: Effectiveness of anthropomorphism on subjective and objective outcomes,
E. Roesler, D. Manzey, and L. Onnasch, “Embodiment matters in social hri research: Effectiveness of anthropomorphism on subjective and objective outcomes,”ACM Transactions on HRI, 2023
2023
-
[25]
Watzlawick, J
P. Watzlawick, J. B. Bavelas, and D. D. Jackson,Pragmatics of human communication. WW Norton & Company, 2011
2011
-
[26]
In-body experiences: embodi- ment, control, and trust in robot-mediated communication,
I. Rae, L. Takayama, and B. Mutlu, “In-body experiences: embodi- ment, control, and trust in robot-mediated communication,” inSIGCHI Conference on Human Factors in Computing Systems, 2013
2013
-
[27]
Social eye gaze in human-robot interaction: a review,
H. Admoni and B. Scassellati, “Social eye gaze in human-robot interaction: a review,”Journal of HRI, 2017
2017
-
[28]
The role of coherent robot behavior and embodiment in emotion perception and recognition during human-robot interaction: experimental study,
L. Fiorini, G. D’Onofrio, A. Sorrentino, F. G. Cornacchia Loizzo, S. Russo, F. Ciccone, F. Giuliani, D. Sancarlo, and F. Cavallo, “The role of coherent robot behavior and embodiment in emotion perception and recognition during human-robot interaction: experimental study,” JMIR Human Factors, 2024
2024
-
[29]
Communicating aware- ness and intent in autonomous vehicle-pedestrian interaction,
K. Mahadevan, S. Somanath, and E. Sharlin, “Communicating aware- ness and intent in autonomous vehicle-pedestrian interaction,” in Proceedings of the CHI conference, 2018
2018
-
[30]
Evaluation of unimodal and multimodal communication cues for attracting attention in human–robot interaction,
E. Torta, J. van Heumen, F. Piunti, L. Romeo, and R. Cuijpers, “Evaluation of unimodal and multimodal communication cues for attracting attention in human–robot interaction,”IJSR, 2015
2015
-
[31]
Encountering autonomous robots on public streets,
H. R. Pelikan, S. Reeves, and M. N. Cantarutti, “Encountering autonomous robots on public streets,” inProc. of the ACM/IEEE Int. Conf. on Human-Robot Interaction (HRI), 2024
2024
-
[32]
Feedback interpretation based on facial expressions in human-robot interaction,
C. Lang, M. Hanheide, M. Lohse, H. Wersing, and G. Sagerer, “Feedback interpretation based on facial expressions in human-robot interaction,” inProc. of the IEEE Int. Symp. on Robot and Human Interactive Comm. (RO-MAN), 2009
2009
-
[33]
Robot communication via motion: A study on modalities for robot-to-human communication in the field,
M. Fulton, C. Edge, and J. Sattar, “Robot communication via motion: A study on modalities for robot-to-human communication in the field,” ACM Transactions on Human-Robot Interaction (THRI), 2022
2022
-
[34]
Embodied com- munication: How robots and people communicate through physical interaction,
A. Kalinowska, P. M. Pilarski, and T. D. Murphey, “Embodied com- munication: How robots and people communicate through physical interaction,”Annual review robotics, and autonomous systems, 2023
2023
-
[35]
Children’s views on identification and intention communication of self-driving vehicles,
V . Charisi, A. Habibovic, J. Andersson, J. Li, and V . Evers, “Children’s views on identification and intention communication of self-driving vehicles,” inConference on interaction design and children, 2017
2017
-
[36]
Led strip based robot movement intention signs for human-robot interactions,
M. Domonkos, Z. Dombi, and J. Botzheim, “Led strip based robot movement intention signs for human-robot interactions,” inInt. Sym- posium on Computational Intelligence and Informatics (CINTI), 2020
2020
-
[37]
Familiar acoustic cues for legible service robots,
G. Angelopoulos, F. Vigni, A. Rossi, G. Russo, M. Turco, and S. Rossi, “Familiar acoustic cues for legible service robots,” inProc. of the IEEE Int. Symp. on Robot and Human Interactive Comm. (RO-MAN), 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.