Adaptive Re-Ranking
Pith reviewed 2026-06-25 20:50 UTC · model grok-4.3
The pith
Routing queries to lighter re-rankers via utility labels cuts median latency by up to 53 times while keeping nDCG@10 competitive.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
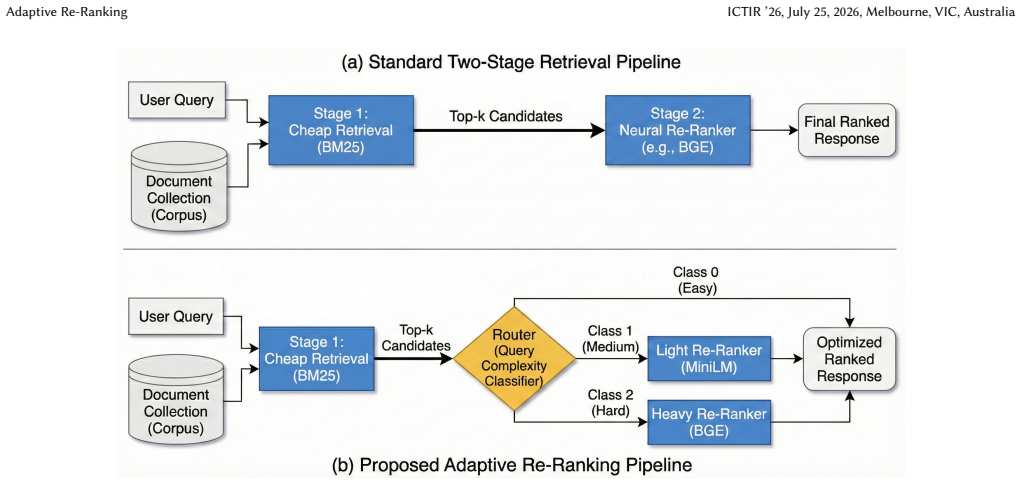
A utility-based labeling framework assigns each query the lowest-cost model that still delivers acceptable ranking quality; a classifier trained on these labels from three fixed models routes new queries accordingly, producing large latency reductions with nDCG@10 that stays within a few percent of the heaviest model on the tested collections.
What carries the argument
Utility-based labeling framework that derives per-query supervision from the effectiveness-cost tradeoff among sparse retrieval, light dense re-ranking, and heavy neural re-ranking.
If this is right
- IR pipelines can handle higher query volumes at fixed compute budget by skipping heavy re-ranking on easy queries.
- Effectiveness remains within a few percent of the strongest single model on several collections.
- The same labeling approach can be reused to compare any set of candidate re-rankers.
- Latency gains appear consistently across the tested datasets when the router is applied.
Where Pith is reading between the lines
- The method could be applied to earlier pipeline stages such as initial retrieval or query expansion.
- Production systems might periodically retrain the router on fresh traffic to maintain generalization.
- Extending the label set to include more model sizes could produce finer-grained cost-quality tradeoffs.
Load-bearing premise
A router trained on utility labels from the three chosen models will generalize to new queries and datasets without large drops in effectiveness or unexpected latency spikes.
What would settle it
Measurement on a held-out dataset showing either median latency higher than the heavy model or nDCG@10 more than 10 points below the heavy model's score.
Figures
read the original abstract
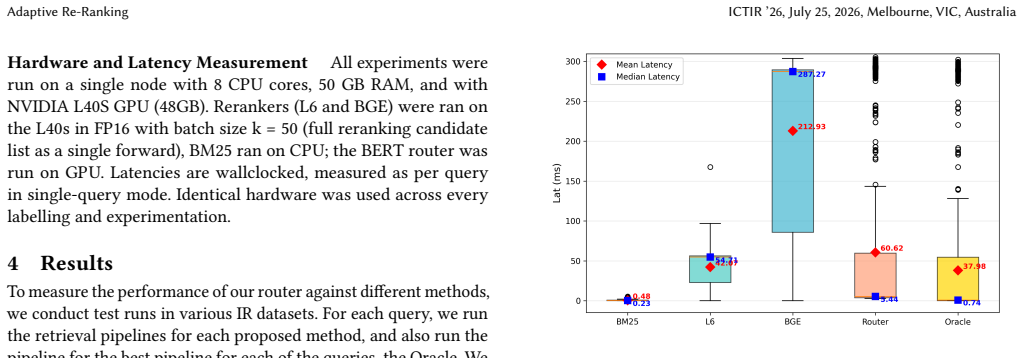
Modern Information Retrieval (IR) systems typically use a "retrieve-then-rerank" pipeline, where a computationally expensive, pre-determined cross-encoder re-ranks the top results from a fast initial retriever. While effective, this approach often applies heavy re-ranking models regardless of query complexity, resulting in high latency and wasted computational resources on simple queries. We propose Adaptive Re-Ranking, an utility-based labeling framework for cost-aware routing and present empirical evidence (via oracle analysis and a trained baseline router) that per-query routing offers large potential gains but is non-trivial to learn from limited supervision. We train a routing classifier with 3 strategies: sparse retrieval (BM25), dense re-ranking (MiniLM-L6-v2), and heavy neural re-ranking (BGE-v2-m3). Compared to BGE our method achieves 1.15-53x lower median latency and 1.11-5.22x lower mean latency across all datasets we have tested, while delivering -17.5% to +4.0% nDCG@10, which is competitive in some datasets. Our findings show that routing queries based on our novel utility function offers a scalable solution for reducing computational costs and latency in a variety of IR systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
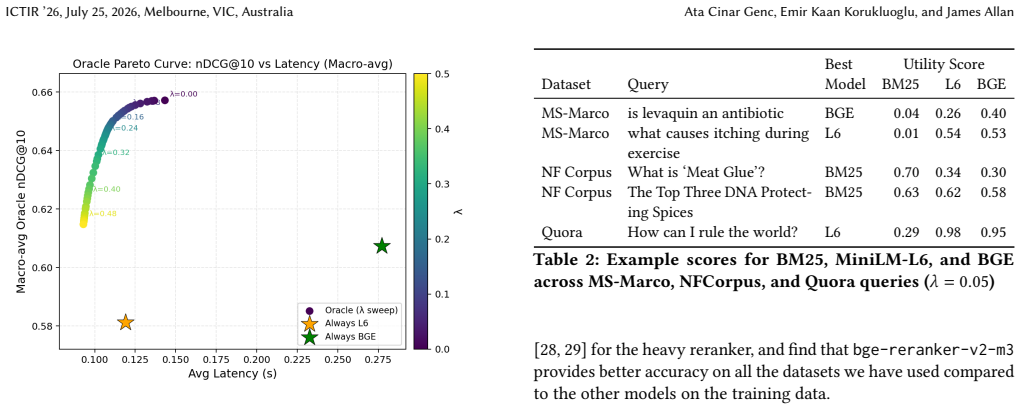
Summary. The paper proposes Adaptive Re-Ranking, a utility-based labeling framework for cost-aware per-query routing among three fixed strategies (BM25 sparse retrieval, MiniLM-L6-v2 dense reranking, and BGE-v2-m3 heavy reranking) in retrieve-then-rerank IR pipelines. It reports oracle analysis plus results from a trained routing classifier, claiming 1.15-53x lower median latency and 1.11-5.22x lower mean latency versus always using BGE, with nDCG@10 ranging from -17.5% to +4.0% (competitive on some datasets) across tested collections.
Significance. If the router generalizes without leakage or overfitting, the approach could meaningfully reduce average latency in production IR systems by avoiding heavy rerankers on easy queries while preserving effectiveness. The empirical latency ranges and multi-dataset testing provide concrete evidence of potential gains, and the explicit acknowledgment that routing is 'non-trivial' to learn from limited supervision is a strength.
major comments (2)
- [description of trained baseline router and empirical evaluation] The central empirical claim (latency reductions with nDCG@10 in [-17.5%, +4.0%]) depends on the trained router generalizing to unseen queries. The utility labels are generated from exactly the three models used at inference time; the manuscript provides no explicit statement or table confirming that the evaluation queries/datasets are fully disjoint from those used to derive the labels or train the classifier. Without this separation, the reported ranges may be optimistic.
- [empirical results and oracle analysis] The abstract states that the router is trained 'with 3 strategies' and reports aggregate latency/nDCG ranges, but no per-dataset breakdown, statistical significance tests, or failure-case analysis (e.g., queries where the router selects the heavy model more often than the oracle) is referenced. This makes it impossible to assess whether the -17.5% nDCG floor is breached on harder queries.
minor comments (2)
- The abstract claims results 'across all datasets we have tested' without naming the collections or providing a table of per-dataset statistics; this information should appear in the introduction or experimental setup.
- Notation for the utility function and how labels are computed from the three models should be formalized with an equation or pseudocode to allow replication.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, indicating where revisions will be made to improve clarity and completeness of the empirical evaluation.
read point-by-point responses
-
Referee: The central empirical claim (latency reductions with nDCG@10 in [-17.5%, +4.0%]) depends on the trained router generalizing to unseen queries. The utility labels are generated from exactly the three models used at inference time; the manuscript provides no explicit statement or table confirming that the evaluation queries/datasets are fully disjoint from those used to derive the labels or train the classifier. Without this separation, the reported ranges may be optimistic.
Authors: We acknowledge that the manuscript does not currently contain an explicit statement or table confirming the disjoint nature of the evaluation queries from those used for label generation and classifier training. To address this concern directly, the revised manuscript will include a dedicated subsection on the experimental protocol with a table specifying the train/test splits per dataset, confirming that evaluation queries are held out from the labeling and training process. revision: yes
-
Referee: The abstract states that the router is trained 'with 3 strategies' and reports aggregate latency/nDCG ranges, but no per-dataset breakdown, statistical significance tests, or failure-case analysis (e.g., queries where the router selects the heavy model more often than the oracle) is referenced. This makes it impossible to assess whether the -17.5% nDCG floor is breached on harder queries.
Authors: We agree that aggregate reporting alone limits interpretability. The revised version will expand the results section to include per-dataset tables for both latency and nDCG@10, report statistical significance tests comparing the router to the always-BGE baseline, and add a failure-case analysis examining queries where the router deviates from oracle behavior, with particular attention to instances approaching the reported nDCG@10 lower bound. revision: yes
Circularity Check
No circularity: empirical routing claims rest on external dataset comparisons
full rationale
The paper advances an empirical framework for query routing among BM25, MiniLM, and BGE using utility labels, supported by oracle analysis and a trained classifier. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Latency and nDCG results are measured directly against fixed baselines on tested datasets rather than reducing to self-definition or ansatz smuggling. The central claims therefore remain self-contained against external benchmarks and do not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Negar Arabzadeh, Maryam Khodabakhsh, and Ebrahim Bagheri. 2021. BERT- QPP: Contextualized Pre-trained Transformers for Query Performance Prediction. InProceedings of the 30th ACM International Conference on Information and Knowledge Management (CIKM ’21). 2857–2861. doi:10.1145/3459637.3482063
-
[2]
Negar Arabzadeh, Xinyi Yan, and Charles L. A. Clarke. 2021. Predicting Effi- ciency/Effectiveness Trade-offs for Dense vs. Sparse Retrieval Strategy Selection. arXiv:2109.10739 [cs.IR] https://arxiv.org/abs/2109.10739
arXiv 2021
-
[3]
Broder, David Carmel, Michael Herscovici, Aya Soffer, and Jason Zien
Andrei Z. Broder, David Carmel, Michael Herscovici, Aya Soffer, and Jason Zien
-
[4]
Broder, David Carmel, Michael Herscovici, Aya Soffer, and Jason Zien
Efficient Query Evaluation Using a Two-Level Retrieval Process. InPro- ceedings of the 12th International Conference on Information and Knowledge Man- agement (CIKM ’03). 426–434. doi:10.1145/956863.956944
-
[5]
Francesco Busolin, Claudio Lucchese, Franco Maria Nardini, Salvatore Orlando, Raffaele Perego, Salvatore Trani, and Alberto Veneri. 2025. Efficient Re-ranking with Cross-encoders via Early Exit. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(Padua, Italy)(SIGIR ’25). Association for Comput...
-
[6]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu
-
[7]
M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. arXiv:2402.03216 [cs.CL]
-
[8]
Ruey-Cheng Chen, Luke Gallagher, Roi Blanco, and J. Shane Culpepper. 2017. Efficient Cost-Aware Cascade Ranking in Multi-Stage Retrieval. InProceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’17). 445–454. doi:10.1145/3077136.3080819
-
[9]
Charles L. A. Clarke, J. Shane Culpepper, and Alistair Moffat. 2016. Assessing efficiency–effectiveness tradeoffs in multi-stage retrieval systems without using relevance judgments.Information Retrieval Journal19, 4 (2016), 351–377. doi:10. 1007/s10791-016-9279-1
2016
-
[10]
Averil Coxhead. 2000. A New Academic Word List.TESOL Quarterly34, 2 (2000), 213–238. doi:10.2307/3587951
-
[11]
Steve Cronen-Townsend, Yun Zhou, and W. Bruce Croft. 2002. Predicting Query Performance. InProceedings of the 25th Annual International ACM SIGIR Confer- ence on Research and Development in Information Retrieval (SIGIR ’02). 299–306. doi:10.1145/564376.564429
-
[12]
Shuai Ding and Torsten Suel. 2011. Faster Top-k Document Retrieval Using Block-Max Indexes. InProceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’11). 993–1002. doi:10. 1145/2009916.2010048
arXiv 2011
-
[13]
Hugging Face. 2024. BAAI/bge-reranker-v2-m3·Hugging Face. https:// huggingface.co/BAAI/bge-reranker-v2-m3
2024
-
[14]
Hugging Face. 2026. cross-encoder/ms-marco-MiniLM-L6-v2·Hugging Face. https://huggingface.co/cross-encoder/ms-marco-MiniLM-L6-v2
2026
-
[15]
Guglielmo Faggioli, Laura Dietz, Charles L. A. Clarke, Gianluca Demartini, Matthias Hagen, Claudia Hauff, Noriko Kando, Evangelos Kanoulas, Martin Potthast, Benno Stein, and Henning Wachsmuth. 2023. Perspectives on Large Language Models for Relevance Judgment. InProceedings of the 2023 ACM SIGIR International Conference on the Theory of Information Retrie...
-
[16]
Safayat Bin Hakim, Muhammad Adil, Alvaro Velasquez, and Houbing Herbert Song. 2025. SymRAG: Efficient Neuro-Symbolic Retrieval Through Adaptive Query Routing. InProceedings of The 19th International Conference on Neurosym- bolic Learning and Reasoning (NeSy) (Proceedings of Machine Learning Research, Vol. 284). PMLR, 540–564. https://proceedings.mlr.press...
2025
-
[17]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C Park
-
[18]
https://arxiv.org/abs/2403.14403
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity.arXiv preprint arXiv:2403.14403(2024). https://arxiv.org/abs/2403.14403
arXiv 2024
-
[19]
Jushaan Singh Kalra, Xinran Zhao, To Eun Kim, Fengyu Cai, Fernando Diaz, and Tongshuang Wu. 2025. MoR: Better Handling Diverse Queries with a Mixture of Sparse, Dense, and Human Retrievers.arXiv preprint arXiv:2506.15862(2025). https://arxiv.org/abs/2506.15862
arXiv 2025
-
[20]
Shane Culpepper, Roi Blanco, Matt Crane, Charles L
Joel Mackenzie, J. Shane Culpepper, Roi Blanco, Matt Crane, Charles L. A. Clarke, and Jimmy Lin. 2018. Query Driven Algorithm Selection in Early Stage Retrieval. InProceedings of the Eleventh ACM International Conference on Web Search and Data Mining(Marina Del Rey, CA, USA)(WSDM ’18). Association for Computing Machinery, New York, NY, USA, 396–404. doi:1...
-
[21]
2008.Intro- duction to information retrieval
Christopher D Manning, Prabhakar Raghavan, and Hinrich Schütze. 2008.Intro- duction to information retrieval. Cambridge university press. https://nlp.stanford. edu/IR-book/
2008
-
[22]
Chuan Meng, Negar Arabzadeh, Arian Askari, Mohammad Aliannejadi, and Maarten de Rijke. 2024. Query Performance Prediction using Relevance Judg- ments Generated by Large Language Models.arXiv preprint arXiv:2404.01012 (2024). https://arxiv.org/abs/2404.01012
arXiv 2024
-
[23]
Rodrigo Nogueira and Kyunghyun Cho. 2019. Passage Re-ranking with BERT. arXiv preprint arXiv:1901.04085(2019). https://arxiv.org/abs/1901.04085
Pith/arXiv arXiv 2019
-
[24]
Gonzalez, M Waleed Kadous, and Ion Stoica
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. 2025. RouteLLM: Learning to Route LLMs with Preference Data. InThe Thirteenth International Conference on Learning Representations (ICLR). https://openreview.net/forum?id=8sSqNntaMr
2025
-
[25]
Open Language Profiles. 2021. CEFR-J Wordlist for English. https://github.com/ openlanguageprofiles/olp-en-cefrj
2021
-
[26]
OpenRouter. 2024. Auto Mode - Automatic Model Selection. https://openrouter. ai/openrouter/auto
2024
-
[27]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, Hong Kong, China, 3982–3992. doi...
-
[28]
Stephen E Robertson and Steve Walker. 1994. Some simple effective approxi- mations to the 2-poisson model for probabilistic weighted retrieval. InSIGIR’94. Springer, 232–241. doi:10.1007/978-1-4471-2099-5_24
-
[29]
Xiaqiang Tang, Qiang Gao, Jian Li, Nan Du, Qi Li, and Sihong Xie. 2025. MBA- RAG: a Bandit Approach for Adaptive Retrieval-Augmented Generation through Question Complexity. InProceedings of the 31st International Conference on Computational Linguistics, Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaer...
2025
-
[30]
Yongquan Tao and Shengli Wu. 2014. Query Performance Prediction By Consid- ering Score Magnitude and Variance Together. InProceedings of the 23rd ACM International Conference on Information and Knowledge Management (CIKM ’14). 1891–1894. doi:10.1145/2661829.2661906
-
[31]
2025.Qwen3-Reranker-0.6B
Qwen Team. 2025.Qwen3-Reranker-0.6B. https://huggingface.co/Qwen/Qwen3- Reranker-0.6B
2025
-
[32]
2025.Qwen3-Reranker-8B
Qwen Team. 2025.Qwen3-Reranker-8B. https://huggingface.co/Qwen/Qwen3- Reranker-8B
2025
-
[33]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models.arXiv preprint arXiv:2104.08663(4 2021). https: //arxiv.org/abs/2104.08663
Pith/arXiv arXiv 2021
-
[34]
Nicola Tonellotto, Craig Macdonald, and Iadh Ounis. 2013. Efficient and Effective Retrieval Using Selective Pruning. InProceedings of the 6th ACM International Conference on Web Search and Data Mining (WSDM ’13). 63–72. doi:10.1145/ 2433396.2433407
arXiv 2013
-
[35]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. At- tention is all you need. InAdvances in neural information process- ing systems, Vol. 30. https://proceedings.neurips.cc/paper/2017/hash/ 3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
2017
-
[36]
Lidan Wang, Jimmy Lin, and Donald Metzler. 2011. A Cascade Ranking Model for Efficient Ranked Retrieval. InProceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’11). 105–114. doi:10.1145/2009916.2009934
-
[37]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. 2020. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 33. 5776–5788. https://proceedings.neurips.cc/paper/2020/hash/ 3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
2020
-
[38]
Hamed Zamani, W. Bruce Croft, and J. Shane Culpepper. 2018. Neural Query Per- formance Prediction using Weak Supervision from Multiple Signals. InProceed- ings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’18). 105–114. doi:10.1145/3209978.3210041
-
[39]
Yun Zhou and W. Bruce Croft. 2007. Query Performance Prediction in Web Search Environments. InProceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’07). 543–550. doi:10.1145/1277741.1277835
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.