Frequency-Aware Self-Supervised Music Representation Learning
Pith reviewed 2026-06-25 19:23 UTC · model grok-4.3
The pith
A visual JEPA trained on 2D spectrograms outperforms 1D sequence models on music retrieval tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
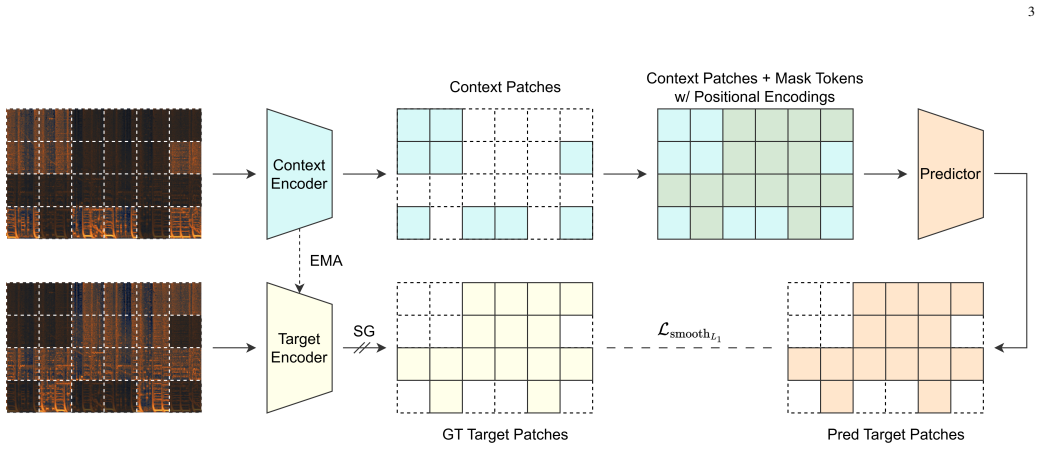
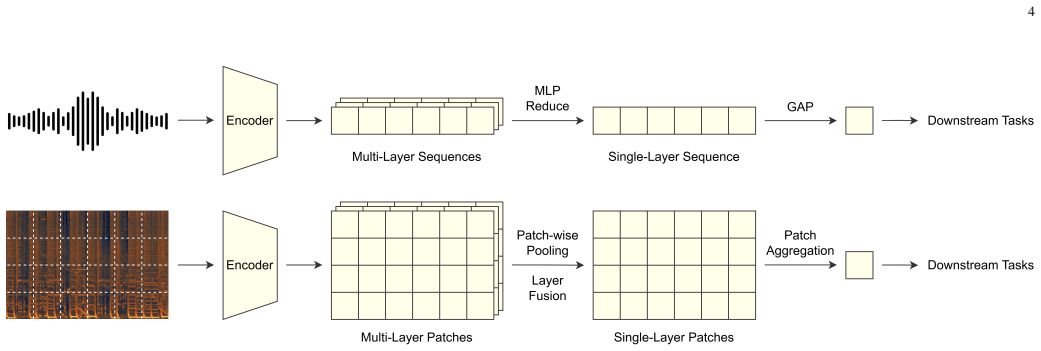
PupuJEPA is a visual Joint-Embedding Predictive Architecture trained directly on 2D spectrograms that learns by predicting the latent embeddings of masked 2D patches from unmasked contexts, rather than using masked language modeling on 1D sequences; domain-specific modifications are added to the model, training, and inference, and the resulting representations outperform 1D sequence-based SSL models across multiple MIR tasks under linear probing on the MARBLE benchmark while attention maps indicate capture of musically meaningful time-frequency patterns.
What carries the argument
Joint-Embedding Predictive Architecture (JEPA) that predicts latent embeddings of masked 2D spectrogram patches from visible context instead of masked language modeling on 1D sequences.
If this is right
- PupuJEPA achieves higher linear-probing accuracy than 1D SSL models on multiple MIR tasks in the MARBLE benchmark.
- Ablation studies indicate that the domain-specific modifications to architecture, training, and inference each contribute to the gains.
- Attention maps extracted from the trained model highlight musically meaningful patterns within the 2D time-frequency domain.
- The approach demonstrates that predicting embeddings of masked 2D patches can replace masked language modeling for audio SSL.
Where Pith is reading between the lines
- The same 2D patch-prediction approach could be tested on non-music audio tasks where time-frequency structure is also salient.
- Because MIDI and spectrograms share a time-frequency grid layout, the learned representations may align more naturally with symbolic music data.
- Scaling the context window or combining 2D spectrogram inputs with raw waveform branches might further improve results.
Load-bearing premise
That the 2D time-frequency grid structure plus music-specific adaptations to a visual JEPA are sufficient to extract more musically meaningful patterns than 1D sequence models.
What would settle it
A re-run of the MARBLE linear-probing experiments in which PupuJEPA does not exceed the performance of the strongest 1D SSL baselines on the reported tasks.
Figures


read the original abstract
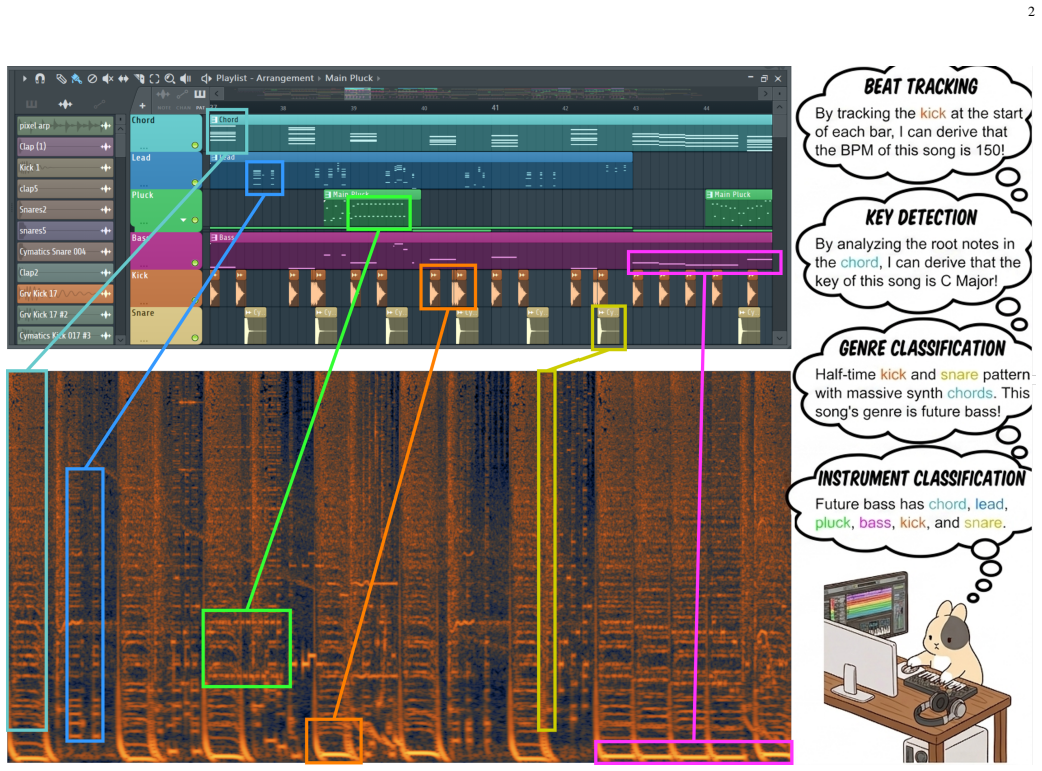
Self-supervised learning (SSL) has emerged as an essential paradigm for music information retrieval (MIR). While current SSL models achieve state-of-the-art performance across various MIR tasks, they typically treat audio as 1D sequences, either operating on time-domain waveforms or on flattened time-frequency-domain spectrograms. This discards the rich spatial and structural information in time-frequency representations and overlooks a fundamental intuition in music production. In particular, music is naturally represented as time-frequency grids in MIDI-based workflows, a structure that tightly corresponds to 2D spectrograms and inherently makes many MIR tasks trivial. Motivated by this intuition, we propose PupuJEPA, a visual Joint-Embedding Predictive Architecture (JEPA) that is trained directly on 2D spectrograms. Instead of applying masked language modeling (MLM) to 1D sequences, PupuJEPA learns robust representations by predicting the latent embeddings of masked 2D spectrogram patches from unmasked contexts. To optimally adapt such a visual framework to music signals, we also apply domain-specific modifications to model architecture, training scheme, and inference paradigm, with comprehensive ablation studies showing their effectiveness. Evaluations on the MARBLE benchmark show that PupuJEPA outperforms the 1D sequence-based SSL models across multiple MIR tasks in linear probing. Additionally, case studies of the attention maps also confirm that PupuJEPA captures musically meaningful patterns within the 2D time-frequency domain. Codes and checkpoints are available at: https://www.yichenggu.com/PupuJEPA/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PupuJEPA, a visual JEPA model adapted for music by training directly on 2D spectrograms to predict latent embeddings of masked 2D patches. It incorporates domain-specific modifications to architecture, training, and inference, with ablations claimed to show their value. On the MARBLE benchmark, it reports outperforming prior 1D sequence-based SSL models in linear probing across multiple MIR tasks, and attention maps are presented as evidence that it captures musically meaningful 2D time-frequency patterns. Code and checkpoints are released.
Significance. If the performance gains are attributable to the 2D spectrogram structure rather than confounding factors in the training recipe, the work would provide evidence that preserving time-frequency grid structure in SSL yields representations better aligned with MIR tasks than 1D sequence models. The release of code and checkpoints strengthens reproducibility.
major comments (1)
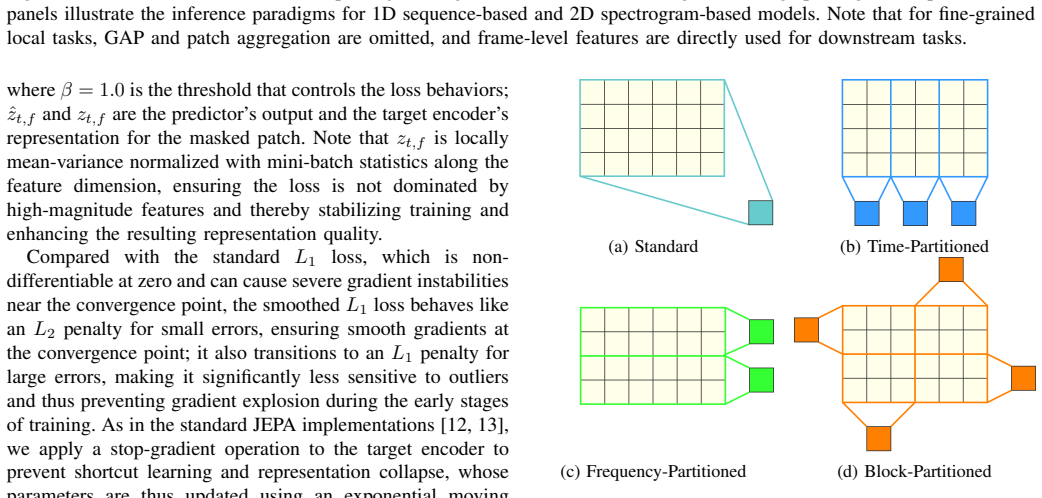
- [§4] §4 and ablation tables: the central claim attributes gains to 2D spectrogram processing under the JEPA objective, yet the reported comparisons use 1D MLM baselines from prior work rather than a controlled 1D-JEPA variant (same predictor, masking, and latent target construction applied to flattened spectrograms). Without this ablation the attribution to 2D structure versus the JEPA framework or other modifications remains under-supported.
minor comments (1)
- The abstract states that 'comprehensive ablation studies' demonstrate effectiveness of the modifications, but the main text should explicitly list which hyperparameters were varied and report the exact metric deltas for each.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the attribution of gains to the 2D spectrogram structure. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4 and ablation tables: the central claim attributes gains to 2D spectrogram processing under the JEPA objective, yet the reported comparisons use 1D MLM baselines from prior work rather than a controlled 1D-JEPA variant (same predictor, masking, and latent target construction applied to flattened spectrograms). Without this ablation the attribution to 2D structure versus the JEPA framework or other modifications remains under-supported.
Authors: We agree that the current comparisons to prior 1D MLM models do not fully isolate the contribution of 2D processing from the JEPA objective itself. To address this, the revised manuscript will include a new controlled 1D-JEPA baseline: spectrograms will be flattened to 1D sequences and trained with the identical predictor architecture, masking strategy, and latent target construction as PupuJEPA. Results from this ablation will be added to §4 and the corresponding tables to better support the claim that the 2D time-frequency grid structure is a key factor. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks and ablations
full rationale
The paper advances an empirical architecture (PupuJEPA) adapted from visual JEPA to 2D spectrograms, with domain-specific modifications justified by ablation studies and evaluated on the external MARBLE benchmark. No derivation chain, equation, or prediction reduces to its own inputs by construction; there are no self-definitional relations, fitted parameters renamed as predictions, or load-bearing self-citations. The central performance claims are falsifiable against independent baselines and benchmarks, making the work self-contained against external evidence.
Axiom & Free-Parameter Ledger
free parameters (1)
- domain-specific modification hyperparameters
axioms (1)
- domain assumption Music is naturally represented as time-frequency grids that correspond to MIDI-based workflows.
invented entities (1)
-
PupuJEPA
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.