Scaling Nonlinear Optimization: Many Problems One GPU
Pith reviewed 2026-06-26 01:42 UTC · model grok-4.3
The pith
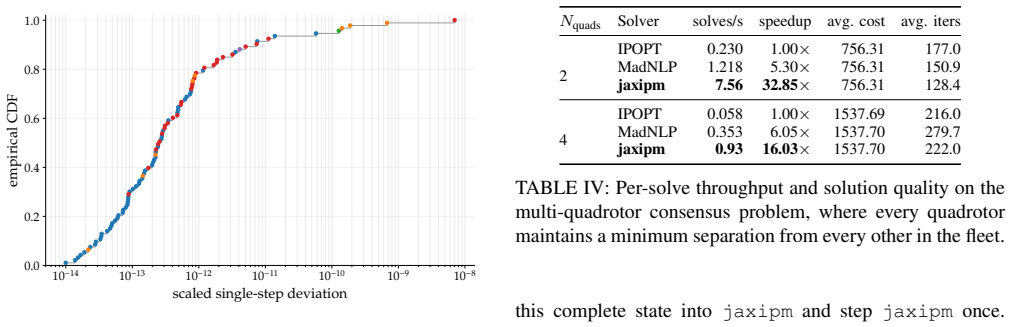
A JAX-based redesign of IPOPT solves batches of nonlinear programs on one GPU at up to 32.85 times the throughput of the CPU version.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
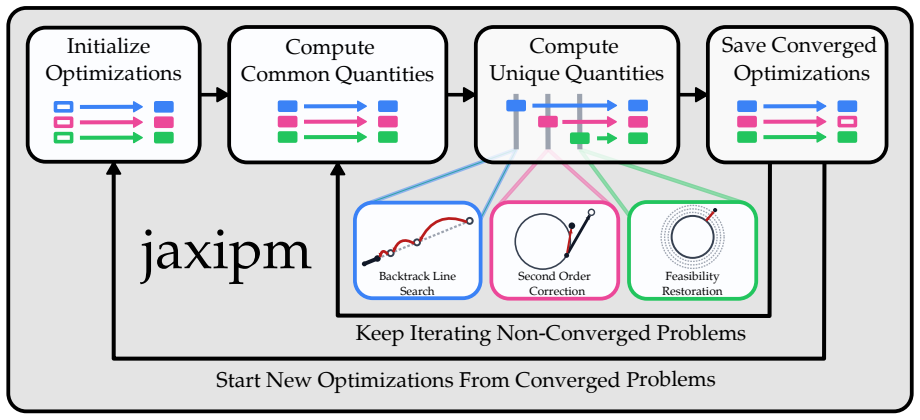
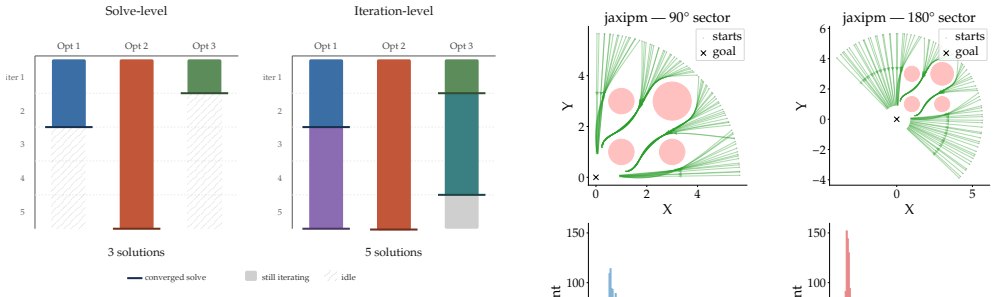
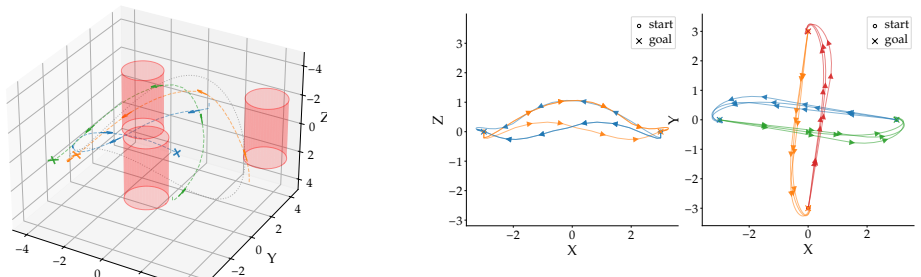
jaxipm is the first GPU-batched NLP solver based on IPOPT and implemented in JAX. The redesign eliminates control flow via heterogeneous iteration fusion and minimizes idle time via iteration-level batching. On quadrotor nonlinear model predictive control benchmarks that include reference tracking with obstacles, multi-agent collision-free navigation, and cluttered environments, it delivers up to 32.85 times higher throughput than standard IPOPT.
What carries the argument
Heterogeneous iteration fusion combined with iteration-level batching, which adapts IPOPT's interior-point iterations to execute without branching and with synchronized processing across problem batches on GPU.
If this is right
- NLP solvers can move from single-problem CPU execution to concurrent solution of many problems on one GPU.
- Constrained optimization becomes compatible with GPU-batched simulators and learning frameworks in robotics.
- The rate at which locally optimal trajectories are generated for tasks such as model predictive control increases by more than an order of magnitude.
- Hard constraint satisfaction and optimality properties carry over from the original IPOPT algorithm to the batched GPU setting.
Where Pith is reading between the lines
- The same fusion and batching techniques could be applied to other sequential optimization codes to achieve similar GPU scaling.
- Hybrid pipelines that interleave batched optimal control with large numbers of sampling-based rollouts become practical on a single accelerator.
- The method invites direct tests on higher-dimensional state spaces or contact-rich problems to measure where the batching overhead begins to dominate.
Load-bearing premise
The algorithmic changes for batching on GPU preserve IPOPT's convergence behavior, constraint satisfaction, and local optimality guarantees when the solver runs in batched form.
What would settle it
A set of benchmark NLPs on which standard IPOPT returns feasible locally optimal solutions but the batched jaxipm version returns infeasible points or fails to converge.
Figures
read the original abstract
Many robotics problems, including trajectory optimization, inverse kinematics, and contact-rich motion planning, reduce to nonlinear programs (NLPs). Mature NLP solvers such as IPOPT can solve these problems, offering hard constraint satisfaction, optimality guarantees, and favorable scaling with problem dimension. These solvers underpin gradient-based methods in robotics, yet remain CPU-bound and solve only one problem at a time, preventing their integration into GPU-batched learning pipelines. On the other hand, sampling-based approaches such as reinforcement learning, model predictive path integral, and imitation learning have become the core of modern robotics research due to their ability to leverage GPU-batched simulators. These simulators can generate orders of magnitude more dynamics rollouts per second than was previously possible. If a GPU-batched NLP solver existed, it would unlock similar speedups in the number of constrained, locally optimal solutions generated per second. This regime of solving many problems concurrently versus solving a single problem at a time is a key requirement for integrating NLP solvers in modern GPU-batched robotics frameworks. To this end, we introduce \texttt{jaxipm}, the first GPU-batched NLP solver, based on IPOPT, and implemented in JAX. We accomplish this by redesigning IPOPT's algorithm to eliminate control flow with \textit{heterogeneous iteration fusion}, and by minimizing GPU idle time with \textit{iteration level batching}. We evaluate \texttt{jaxipm} on a variety of quadrotor nonlinear model predictive control benchmarks, including reference tracking in the presence of obstacles, multi-quadrotor navigation without collision, and navigation in a cluttered environment. We demonstrate up to a $32.85\times$ increase in throughput over IPOPT. Our complete open-source codebase is available at https://github.com/johnviljoen/jaxipm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces jaxipm, the first GPU-batched NLP solver based on IPOPT and implemented in JAX. It redesigns the algorithm using heterogeneous iteration fusion to eliminate control flow and iteration-level batching to minimize GPU idle time. The method is evaluated on quadrotor NMPC benchmarks (reference tracking with obstacles, multi-quadrotor navigation, cluttered environments), reporting up to 32.85× throughput gains over sequential IPOPT, with an open-source codebase provided.
Significance. If the batched solver is shown to preserve IPOPT convergence, KKT satisfaction, and local optimality, the work would bridge CPU-based constrained optimization with GPU-batched robotics pipelines, enabling orders-of-magnitude more locally optimal solutions per second in learning and planning frameworks. The open-source release at https://github.com/johnviljoen/jaxipm is a clear strength for reproducibility.
major comments (1)
- [Algorithmic redesign (heterogeneous iteration fusion and iteration-level batching sections)] The central empirical claim (up to 32.85× throughput) depends on heterogeneous iteration fusion and iteration-level batching producing mathematically equivalent behavior to sequential IPOPT, including identical adaptive barrier updates, filter line search decisions, inertia correction, and restoration-phase logic per problem. No explicit verification (e.g., per-instance KKT residual matching, iteration-count equivalence, or constraint violation statistics) is reported on the quadrotor benchmarks to confirm that the fused/batched execution solves the same NLPs.
minor comments (1)
- [Abstract and evaluation section] The abstract and evaluation description would benefit from stating the exact problem dimensions, number of concurrent NLPs, and hardware used for the throughput measurements to allow direct comparison with future work.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment regarding verification of algorithmic equivalence below.
read point-by-point responses
-
Referee: [Algorithmic redesign (heterogeneous iteration fusion and iteration-level batching sections)] The central empirical claim (up to 32.85× throughput) depends on heterogeneous iteration fusion and iteration-level batching producing mathematically equivalent behavior to sequential IPOPT, including identical adaptive barrier updates, filter line search decisions, inertia correction, and restoration-phase logic per problem. No explicit verification (e.g., per-instance KKT residual matching, iteration-count equivalence, or constraint violation statistics) is reported on the quadrotor benchmarks to confirm that the fused/batched execution solves the same NLPs.
Authors: We concur that confirming mathematical equivalence is critical for validating the throughput claims. Our redesign using heterogeneous iteration fusion and iteration-level batching aims to preserve the exact per-problem behavior of IPOPT by replacing control flow with data-dependent masking and ensuring identical barrier updates, line search decisions, inertia corrections, and restoration logic. While the manuscript focuses on the throughput results assuming this equivalence by construction, we did not include explicit per-instance verification metrics. We will revise the manuscript to include such verification, for example by reporting average and maximum KKT residual differences, iteration count matches, and constraint violation statistics across the benchmark instances. revision: yes
Circularity Check
No circularity; empirical implementation and throughput claims are self-contained
full rationale
The paper introduces jaxipm as a JAX-based GPU-batched reimplementation of IPOPT, achieved via heterogeneous iteration fusion and iteration-level batching. Its central claims consist of empirical throughput measurements (up to 32.85×) on quadrotor NMPC benchmarks, with no mathematical derivation chain, fitted parameters renamed as predictions, or self-referential equations. The algorithmic redesigns are presented as engineering modifications whose equivalence to sequential IPOPT is asserted but not derived from prior results within the paper; verification is external via open-source code and direct benchmarking. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided text. The work is therefore an independent implementation contribution whose performance numbers do not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption IPOPT's interior-point algorithm converges to locally optimal solutions satisfying constraints under standard NLP assumptions
Reference graph
Works this paper leans on
-
[1]
An introduction to trajectory optimization: How to do your own direct collocation,
M. Kelly, “An introduction to trajectory optimization: How to do your own direct collocation,”SIAM review, vol. 59, no. 4, pp. 849–904, 2017
2017
-
[2]
Nonlinear model pre- dictive control: From theory to application,
F. Allgower, R. Findeisen, Z. K. Nagyet al., “Nonlinear model pre- dictive control: From theory to application,”Journal-Chinese Institute Of Chemical Engineers, vol. 35, no. 3, pp. 299–316, 2004
2004
-
[3]
An experimental evaluation of a novel minimum-jerk cartesian controller for humanoid robots,
U. Pattacini, F. Nori, L. Natale, G. Metta, and G. Sandini, “An experimental evaluation of a novel minimum-jerk cartesian controller for humanoid robots,” in2010 IEEE/RSJ international conference on intelligent robots and systems. IEEE, 2010, pp. 1668–1674
2010
-
[4]
A direct method for trajectory op- timization of rigid bodies through contact,
M. Posa, C. Cantu, and R. Tedrake, “A direct method for trajectory op- timization of rigid bodies through contact,”The International Journal of Robotics Research, vol. 33, no. 1, pp. 69–81, 2014
2014
-
[5]
Model predictive path integral control: From theory to parallel computation,
G. Williams, A. Aldrich, and E. A. Theodorou, “Model predictive path integral control: From theory to parallel computation,”Journal of Guidance, Control, and Dynamics, vol. 40, no. 2, pp. 344–357, 2017
2017
-
[6]
A tutorial on the cross-entropy method,
P.-T. De Boer, D. P. Kroese, S. Mannor, and R. Y . Rubinstein, “A tutorial on the cross-entropy method,”Annals of operations research, vol. 134, no. 1, pp. 19–67, 2005
2005
-
[7]
On the implementation of an interior- point filter line-search algorithm for large-scale nonlinear program- ming,
A. W ¨achter and L. T. Biegler, “On the implementation of an interior- point filter line-search algorithm for large-scale nonlinear program- ming,”Mathematical programming, vol. 106, pp. 25–57, 2006
2006
-
[8]
Knitro: An integrated pack- age for nonlinear optimization,
R. H. Byrd, J. Nocedal, and R. A. Waltz, “Knitro: An integrated pack- age for nonlinear optimization,” inLarge-scale nonlinear optimization. Springer, 2006, pp. 35–59
2006
-
[9]
Snopt: An sqp algorithm for large-scale constrained optimization,
P. E. Gill, W. Murray, and M. A. Saunders, “Snopt: An sqp algorithm for large-scale constrained optimization,”SIAM review, vol. 47, no. 1, pp. 99–131, 2005
2005
-
[10]
MuJoCo XLA (MJX),
MuJoCo XLA Authors, “MuJoCo XLA (MJX),” https://mujoco. readthedocs.io/en/stable/mjx.html, 2024, accessed: March 25, 2026
2024
-
[11]
Isaac lab: A gpu- accelerated simulation framework for multi-modal robot learning,
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano- Munoz, X. Yao, R. Zurbr ¨ugg, N. Rudinet al., “Isaac lab: A gpu- accelerated simulation framework for multi-modal robot learning,” arXiv preprint arXiv:2511.04831, 2025
Pith/arXiv arXiv 2025
-
[12]
Brax–a differentiable physics engine for large scale rigid body simulation,
C. D. Freeman, E. Frey, A. Raichuk, S. Girgin, I. Mordatch, and O. Bachem, “Brax–a differentiable physics engine for large scale rigid body simulation,”arXiv preprint arXiv:2106.13281, 2021
arXiv 2021
-
[13]
Synthesis of model predictive control and reinforcement learning: Survey and classifica- tion,
R. Reiter, J. Hoffmann, D. Reinhardt, F. Messerer, K. Baumg ¨artner, S. Sawant, J. Boedecker, M. Diehl, and S. Gros, “Synthesis of model predictive control and reinforcement learning: Survey and classifica- tion,”Annual Reviews in Control, vol. 61, p. 101045, 2026
2026
-
[14]
Towards out-of-distribution generalization: A survey,
J. Liu, Z. Shen, Y . He, X. Zhang, R. Xu, H. Yu, and P. Cui, “Towards out-of-distribution generalization: A survey,”arXiv preprint arXiv:2108.13624, 2021
arXiv 2021
-
[15]
Complementarity-free multi-contact modeling and optimiza- tion for dexterous manipulation,
W. Jin, “Complementarity-free multi-contact modeling and optimiza- tion for dexterous manipulation,”arXiv preprint arXiv:2408.07855, 2024
arXiv 2024
-
[16]
3d dynamic walking with underactuated humanoid robots: A direct collocation framework for optimizing hybrid zero dynamics,
A. Hereid, E. A. Cousineau, C. M. Hubicki, and A. D. Ames, “3d dynamic walking with underactuated humanoid robots: A direct collocation framework for optimizing hybrid zero dynamics,” in2016 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2016, pp. 1447–1454
2016
-
[17]
Convexification and real-time optimization for mpc with aerospace applications,
Y . Mao, D. Dueri, M. Szmuk, and B. Ac ¸ıkmes ¸e, “Convexification and real-time optimization for mpc with aerospace applications,” in Handbook of model predictive control. Springer, 2018, pp. 335–358
2018
-
[18]
Casadi—a software framework for nonlinear optimization and optimal control,
J. Andersson, J. Gillis, G. Horn, J. Rawlings, and M. Diehl, “Casadi—a software framework for nonlinear optimization and optimal control,” Mathematical Programming Computation, vol. 11, no. 1, pp. 1–36, 2018
2018
-
[19]
Drake: Model-based design and verification for robotics,
R. Tedrake and the Drake Development Team, “Drake: Model-based design and verification for robotics,” 2019. [Online]. Available: https://drake.mit.edu
2019
-
[20]
Pyomo: modeling and solving mathematical programs in python,
W. E. Hart, J.-P. Watson, and D. L. Woodruff, “Pyomo: modeling and solving mathematical programs in python,”Mathematical Program- ming Computation, vol. 3, no. 3, pp. 219–260, 2011
2011
-
[21]
JuMP 1.0: Recent improvements to a modeling language for mathematical optimization,
M. Lubin, O. Dowson, J. Dias Garcia, J. Huchette, B. Legat, and J. P. Vielma, “JuMP 1.0: Recent improvements to a modeling language for mathematical optimization,”Mathematical Programming Compu- tation, 2023
2023
-
[22]
JAX: composable transformations of Python+NumPy programs,
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman- Milne, and Q. Zhang, “JAX: composable transformations of Python+NumPy programs,” http://github.com/jax-ml/jax, 2018
2018
-
[23]
Strategic decision-making in multi- agent domains: A weighted constrained potential dynamic game approach,
M. Bhatt, Y . Jia, and N. Mehr, “Strategic decision-making in multi- agent domains: A weighted constrained potential dynamic game approach,”IEEE Transactions on Robotics, 2025
2025
-
[24]
Hykkt: a hybrid direct-iterative method for solving kkt linear systems,
S. Regev, N.-Y . Chiang, E. Darve, C. G. Petra, M. A. Saunders, K. ´Swirydowicz, and S. Peleˇs, “Hykkt: a hybrid direct-iterative method for solving kkt linear systems,”Optimization Methods and Software, vol. 38, no. 2, pp. 332–355, 2023
2023
-
[25]
Gpu-accelerated dynamic nonlinear optimiza- tion with examodels and madnlp,
F. Pacaud and S. Shin, “Gpu-accelerated dynamic nonlinear optimiza- tion with examodels and madnlp,” in2024 IEEE 63rd Conference on Decision and Control (CDC). IEEE, 2024, pp. 5963–5968
2024
-
[26]
Accelerating optimal power flow with gpus: Simd abstraction of nonlinear programs and condensed- space interior-point methods,
S. Shin, M. Anitescu, and F. Pacaud, “Accelerating optimal power flow with gpus: Simd abstraction of nonlinear programs and condensed- space interior-point methods,”Electric Power Systems Research, vol. 236, p. 110651, 2024
2024
-
[27]
NVIDIA cuDSS (Preview): A High-Performance CUDA Library for Direct Sparse Solvers,
NVIDIA, “NVIDIA cuDSS (Preview): A High-Performance CUDA Library for Direct Sparse Solvers,” https://docs.nvidia.com/cuda/cudss/ index.html, accessed: 2025
2025
-
[28]
Optnet: Differentiable optimization as a layer in neural networks,
B. Amos and J. Z. Kolter, “Optnet: Differentiable optimization as a layer in neural networks,”arXiv preprint arXiv:1703.00443, 2017
arXiv 2017
-
[29]
A differentiable interior-point method in single precision,
J. Arrizabalaga, K. Tracy, and Z. Manchester, “A differentiable interior-point method in single precision,” 2026. [Online]. Available: https://arxiv.org/abs/2605.17913
Pith/arXiv arXiv 2026
-
[30]
Moreau: GPU-native differen- tiable optimization,
S. Barratt, P. Nobel, and S. Diamond, “Moreau: GPU-native differen- tiable optimization,” https://moreau.so, 2026
2026
-
[31]
Mpax: Mathematical programming in jax,
H. Lu, Z. Peng, and J. Yang, “Mpax: Mathematical programming in jax,”arXiv preprint arXiv:2412.09734, 2024
arXiv 2024
-
[32]
Efficient and modular implicit differentiation,
M. Blondel, Q. Berthet, M. Cuturi, R. Frostig, S. Hoyer, F. Llinares- L´opez, F. Pedregosa, and J.-P. Vert, “Efficient and modular implicit differentiation,”arXiv preprint arXiv:2105.15183, 2021
arXiv 2021
-
[33]
Opt2skill: Imitating dynamically-feasible whole-body trajectories for versatile humanoid loco-manipulation,
F. Liu, Z. Gu, Y . Cai, Z. Zhou, H. Jung, J. Jang, S. Zhao, S. Ha, Y . Chen, D. Xuet al., “Opt2skill: Imitating dynamically-feasible whole-body trajectories for versatile humanoid loco-manipulation,” IEEE Robotics and Automation Letters, 2025
2025
-
[34]
Imitation learning from mpc for quadrupedal multi-gait control,
A. Reske, J. Carius, Y . Ma, F. Farshidian, and M. Hutter, “Imitation learning from mpc for quadrupedal multi-gait control,” in2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 5014–5020
2021
-
[35]
Good old-fashioned engineering can close the 100,000- year “data gap
K. Goldberg, “Good old-fashioned engineering can close the 100,000- year “data gap” in robotics,” p. eaea7390, 2025
2025
-
[36]
A trust region method based on interior point techniques for nonlinear programming,
R. H. Byrd, J. C. Gilbert, and J. Nocedal, “A trust region method based on interior point techniques for nonlinear programming,”Math- ematical programming, vol. 89, no. 1, pp. 149–185, 2000
2000
-
[37]
A primal- dual trust-region algorithm for non-convex nonlinear programming,
A. R. Conn, N. I. Gould, D. Orban, and P. L. Toint, “A primal- dual trust-region algorithm for non-convex nonlinear programming,” Mathematical programming, vol. 87, no. 2, pp. 215–249, 2000
2000
-
[38]
A. V . Fiacco and G. P. McCormick,Nonlinear programming: sequen- tial unconstrained minimization techniques. SIAM, 1990
1990
-
[39]
Line search filter methods for nonlinear programming: Motivation and global convergence,
A. W ¨achter and L. T. Biegler, “Line search filter methods for nonlinear programming: Motivation and global convergence,”SIAM Journal on Optimization, vol. 16, no. 1, pp. 1–31, 2005
2005
-
[40]
Quadrotor kinematics and dynamics,
C. Powers, D. Mellinger, and V . Kumar, “Quadrotor kinematics and dynamics,”Handbook of unmanned aerial vehicles, pp. 307–328, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.