Toward Agentic SysAdmin: Rethinking System Administration with AI Agents
Pith reviewed 2026-06-26 02:22 UTC · model grok-4.3
The pith
Solver design lifts a 14B model's correctness on network tasks from 0.43 to 0.88 and lets it match trillion-parameter systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
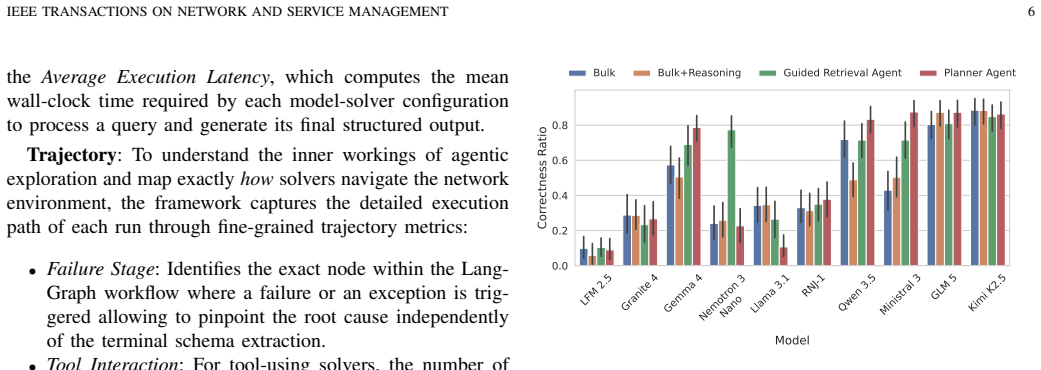
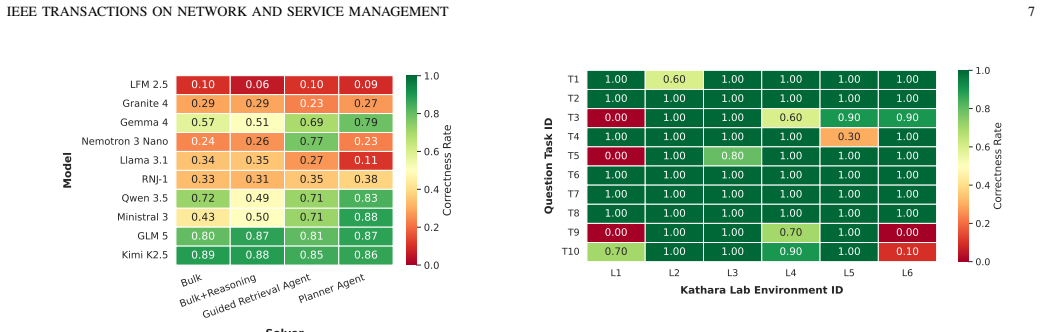
Through the NetLLMeval framework and its 24000-run study, solver architecture has a substantial impact on the accuracy of LLM systems performing network administration, raising a 14B open-weight model from 0.43 to 0.88 correctness and enabling locally deployable models to match trillion-parameter frontier systems under appropriate solver choices.
What carries the argument
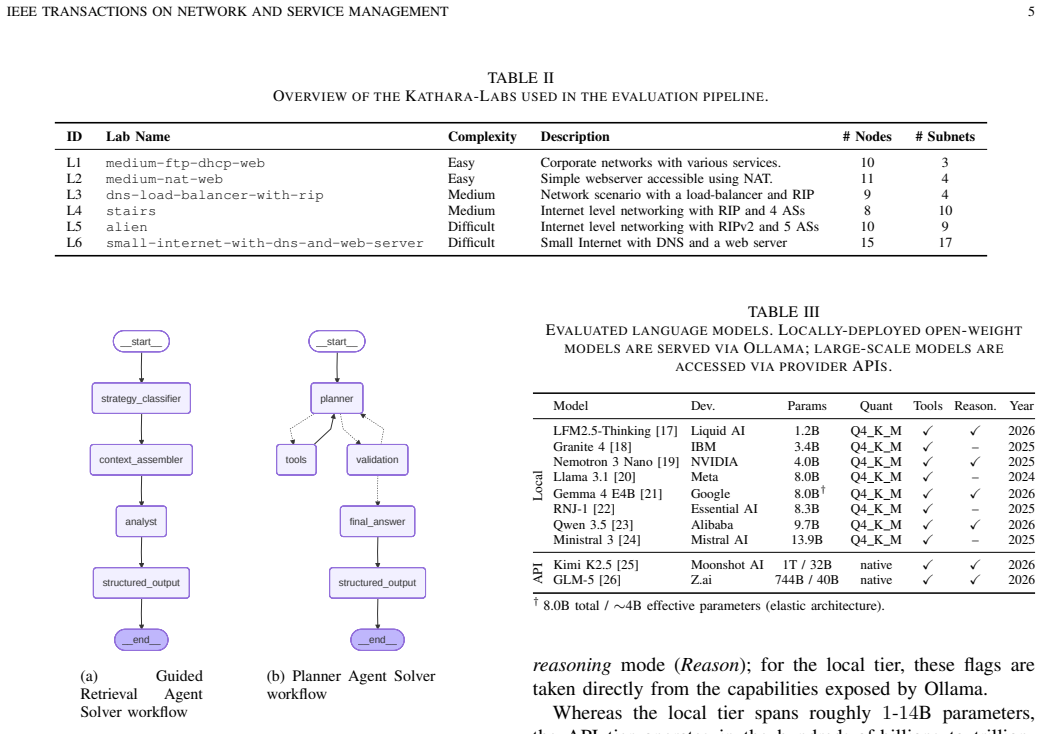
NetLLMeval, a framework that derives ground truth via live network emulation to benchmark LLM solver architectures on network administration tasks.
If this is right
- Solver choice, spanning monolithic prompting to fully agentic pipelines, determines whether smaller models reach high correctness on network tasks.
- Locally deployable models can achieve parity with frontier systems when paired with suitable solver designs.
- Automated emulation-based evaluation removes the need for static references or manual expert checks, enabling larger-scale benchmarking.
- Performance differences appear across task types and topologies of increasing complexity.
Where Pith is reading between the lines
- Engineering the solver pipeline may matter more than raw model scale for practical deployment in network management.
- The framework could be extended to measure additional operational constraints such as latency, security posture, or recovery from failures.
- Standardized emulation benchmarks might accelerate comparison of new agentic designs against existing approaches in systems administration.
Load-bearing premise
Live network emulation produces reliable ground truth for diverse real-world network states and orchestration strategies without fidelity gaps that would invalidate the correctness metric.
What would settle it
A side-by-side comparison of emulation-derived ground truth against results obtained from equivalent physical network hardware or from expert human validation on the same tasks and topologies.
Figures


read the original abstract
The growing complexity of computer networks, driven by cloud-native architectures, heterogeneous devices, and distributed systems, places increasing pressure on network administrators who must simultaneously manage configuration, troubleshooting, and security under tight operational constraints. Large Language Models (LLMs) have emerged as a promising tool to assist and partially automate these tasks, yet their systematic evaluation in networking scenarios remains an open challenge. Existing benchmarks rely on static reference outputs or manual expert validation, neither of which scales to the diversity of real-world network states or to the variety of orchestration strategies -- from monolithic prompting to fully agentic pipelines --through which LLMs are increasingly deployed. In this paper, we present NetLLMeval, a framework for automatically evaluating LLM-based systems on network administration tasks by leveraging live network emulation to derive ground truth without human intervention. Through a full-factorial study of 24000 runs spanning 10 foundation models, 4 solver architectures, 10 task types, and 6 network topologies of increasing complexity, we show that solver design has a great impact on accuracy -- lifting a 14B open-weight model from 0.43 to 0.88 correctness -- and that such locally-deployable models can match trillion-parameter frontier systems under the right configuration. NetLLMeval is released open-source to support reproducible benchmarking of future models and solver designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NetLLMeval, a framework for automatically evaluating LLM-based agentic systems on network administration tasks via live network emulation to derive ground truth without human intervention. It reports results from a full-factorial study of 24,000 runs across 10 foundation models, 4 solver architectures, 10 task types, and 6 network topologies, claiming that solver design has a large impact on accuracy (e.g., lifting a 14B open-weight model from 0.43 to 0.88 correctness) and that optimized locally-deployable models can match trillion-parameter frontier systems.
Significance. If the emulation faithfully reproduces real network behavior and the success predicates are valid, the work offers a scalable, reproducible benchmark for agentic networking systems that avoids the scalability limits of static or manual evaluation. The open-source release and emphasis on solver architecture over raw model scale are strengths that could influence future benchmarking practices in the field.
major comments (1)
- [Section 3 and evaluation protocol] Section 3 and the evaluation protocol: the correctness metric and all reported accuracy deltas (including the 0.43 to 0.88 lift and local-vs-frontier comparisons) are derived solely from automated success/failure labels produced by the emulator. No human validation, cross-check against production traces, or fidelity assessment is described, making the assumption that emulator outcomes equal operational correctness load-bearing for the central empirical claims.
minor comments (1)
- [Abstract and results presentation] The abstract states a 'full-factorial study of 24000 runs' but provides no visible error bars, exclusion criteria, or statistical controls in the high-level summary; these details should be added to the results section for interpretability.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the evaluation protocol. We address the concern directly below and will revise the manuscript to improve transparency around the emulator's role.
read point-by-point responses
-
Referee: [Section 3 and evaluation protocol] Section 3 and the evaluation protocol: the correctness metric and all reported accuracy deltas (including the 0.43 to 0.88 lift and local-vs-frontier comparisons) are derived solely from automated success/failure labels produced by the emulator. No human validation, cross-check against production traces, or fidelity assessment is described, making the assumption that emulator outcomes equal operational correctness load-bearing for the central empirical claims.
Authors: We acknowledge that all reported metrics rely exclusively on automated emulator labels and that no human validation, production-trace cross-checks, or explicit fidelity assessment appears in the current manuscript. This is by design: the framework's primary goal is to support reproducible, large-scale evaluation (24,000 runs) that would be infeasible under manual labeling. We agree the emulator-fidelity assumption is load-bearing for the accuracy deltas and model comparisons. In the revision we will add to Section 3: (i) a precise description of the emulation stack and success predicates, (ii) any internal consistency checks performed during framework development, and (iii) an explicit limitations paragraph stating the assumption that emulator outcomes approximate operational correctness, together with a note that large-scale human validation remains future work. This change makes the assumption transparent without altering the experimental results. revision: yes
Circularity Check
Empirical benchmarking study with no circular derivations
full rationale
The paper is a full-factorial empirical benchmarking study (24000 runs across models, solvers, tasks, and topologies) that measures LLM correctness against ground truth generated by live network emulation. No equations, fitted parameters, or self-referential definitions appear in the provided text; the accuracy deltas (e.g., 0.43 to 0.88) are computed directly from emulation outcomes rather than being forced by construction or prior self-citations. The work is therefore self-contained against external benchmarks with no load-bearing steps that reduce results to their own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The evolution of distributed computing systems: from fundamental to new frontiers,
D. Lindsay, S. S. Gill, D. Smirnova, and P. Garraghan, “The evolution of distributed computing systems: from fundamental to new frontiers,” Computing, vol. 103, no. 8, pp. 1859–1878, 2021
2021
-
[2]
Unraveling the complexity of network management
T. Benson, A. Akella, and D. A. Maltz, “Unraveling the complexity of network management.” inNSDI, 2009, pp. 335–348
2009
-
[3]
Machine learning for networking: Workflow, advances and opportunities,
M. Wang, Y . Cui, X. Wang, S. Xiao, and J. Jiang, “Machine learning for networking: Workflow, advances and opportunities,”Ieee Network, vol. 32, no. 2, pp. 92–99, 2017
2017
-
[4]
Large language models for networking: Workflow, advances and challenges,
C. Liu, X. Xie, X. Zhang, and Y . Cui, “Large language models for networking: Workflow, advances and challenges,” 2024. [Online]. Available: https://arxiv.org/abs/2404.12901
arXiv 2024
-
[5]
A review on large language models: Archi- tectures, applications, taxonomies, open issues and challenges,
M. A. K. Raiaanet al., “A review on large language models: Archi- tectures, applications, taxonomies, open issues and challenges,”IEEE access, vol. 12, pp. 26 839–26 874, 2024
2024
-
[6]
Can llms understand computer networks? towards a virtual system administrator,
D. Donadel, F. Marchiori, L. Pajola, and M. Conti, “Can llms understand computer networks? towards a virtual system administrator,” in2024 IEEE 49th Conference on Local Computer Networks (LCN). IEEE, 2024, pp. 1–10
2024
-
[7]
Netconfeval: Can llms facilitate network configuration?
C. Wang, M. Scazzariello, A. Farshin, S. Ferlin, D. Kosti ´c, and M. Chiesa, “Netconfeval: Can llms facilitate network configuration?” Proceedings of the ACM on Networking, vol. 2, no. CoNEXT2, pp. 1– 25, 2024
2024
-
[8]
Aiopslab: A holistic framework to evaluate ai agents for enabling autonomous clouds,
Y . Chenet al., “Aiopslab: A holistic framework to evaluate ai agents for enabling autonomous clouds,”Proceedings of Machine Learning and Systems, vol. 7, 2025
2025
-
[9]
Netarena: Dynamic benchmarks for ai agents in network automation,
Y . Zhouet al., “Netarena: Dynamic benchmarks for ai agents in network automation,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[10]
A network arena for benchmarking ai agents on network troubleshoot- ing,
Z. Wang, A. Cornacchia, A. Sacco, F. Galante, M. Canini, and D. Jiang, “A network arena for benchmarking ai agents on network troubleshoot- ing,”arXiv preprint arXiv:2512.16381, 2025
arXiv 2025
-
[11]
A comprehensive survey on llm-based network management and operations,
J. Hong, N. V . Tu, and J. W.-K. Hong, “A comprehensive survey on llm-based network management and operations,”International Journal of Network Management, vol. 35, no. 6, p. e70029, 2025
2025
-
[12]
Netllm: Adapting large language models for networking,
D. Wuet al., “Netllm: Adapting large language models for networking,” inProceedings of the ACM SIGCOMM 2024 Conference, 2024, pp. 661– 678
2024
-
[13]
Mobile-llama: Instruction fine-tuning open-source llm for network analysis in 5g networks,
K. B. Kan, H. Mun, G. Cao, and Y . Lee, “Mobile-llama: Instruction fine-tuning open-source llm for network analysis in 5g networks,”IEEE Network, vol. 38, no. 5, pp. 76–83, 2024
2024
-
[14]
A novel framework for detecting anomalies in network security using llm and deep learning,
M. Entezami, S. Rahimi Harsini, D. Houshangi, and Z. Entezami, “A novel framework for detecting anomalies in network security using llm and deep learning,”Journal of Electrical Systems, vol. 21, no. 1s, pp. 294–302, 2025
2025
-
[15]
An llm agent for functional bug detection in network protocols,
M. Zheng, C. Wang, X. Liu, J. Guo, S. Feng, and X. Zhang, “An llm agent for functional bug detection in network protocols,”arXiv e-prints, pp. arXiv–2506, 2025
2025
-
[16]
React: Synergizing reasoning and acting in language models,
S. Yaoet al., “React: Synergizing reasoning and acting in language models,” 2023. [Online]. Available: https://arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[17]
L. AI, “Lfm2 technical report,”arXiv preprint arXiv:2511.23404, 2025
arXiv 2025
-
[18]
Granite 4.0 language models,
IBM Research, “Granite 4.0 language models,” https://github.com/ ibm-granite/granite-4.0-language-models, 2025, accessed: 2025-10-01
2025
-
[19]
Nvidia nemotron 3: Efficient and open intelligence,
A. Blakemanet al., “Nvidia nemotron 3: Efficient and open intelligence,” arXiv preprint arXiv:2512.20856, 2025
Pith/arXiv arXiv 2025
-
[20]
A. Grattafioriet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[21]
Gemma 4: Frontier multimodal intelligence on device,
Google DeepMind, “Gemma 4: Frontier multimodal intelligence on device,” Google AI, Technical Report, 2026. [Online]. Available: https://deepmind.google/models/gemma/gemma-4/
2026
-
[22]
Rnj-1-5-Instruct,
E. M. Callahanet al., “Rnj-1-5-Instruct,” 2026, long-context Instruction- tuned model release. [Online]. Available: https://huggingface.co/ EssentialAI/rnj-1-5-instruct
2026
-
[23]
Qwen3.5: Towards native multimodal agents,
Qwen Team, “Qwen3.5: Towards native multimodal agents,” February
-
[24]
Available: https://qwen.ai/blog?id=qwen3.5
[Online]. Available: https://qwen.ai/blog?id=qwen3.5
-
[25]
A. H. Liuet al., “Ministral 3,”arXiv preprint arXiv:2601.08584, 2026
Pith/arXiv arXiv 2026
-
[26]
Kimi k2.5: Visual agentic intelligence,
K. Teamet al., “Kimi k2.5: Visual agentic intelligence,” 2026. [Online]. Available: https://arxiv.org/abs/2602.02276
Pith/arXiv arXiv 2026
-
[27]
Glm-5: from vibe coding to agentic engineering,
GLM-5-Teamet al., “Glm-5: from vibe coding to agentic engineering,”
-
[28]
Available: https://arxiv.org/abs/2602.15763
[Online]. Available: https://arxiv.org/abs/2602.15763
-
[29]
Kathar ´a: A container-based framework for implementing network function virtu- alization and software defined networks,
G. Bonofiglio, V . Iovinella, G. Lospoto, and G. Di Battista, “Kathar ´a: A container-based framework for implementing network function virtu- alization and software defined networks,” inNOMS - 2018 IEEE/IFIP Network Operations and Management Symposium, 2018, pp. 1–9
2018
-
[30]
Understanding the planning of llm agents: A survey,
X. Huanget al., “Understanding the planning of llm agents: A survey,” arXiv preprint arXiv:2402.02716, 2024. Gianmaria Frigois currently pursuing the M.Sc. degree in Computer Engi- neering at the University of Padua, Italy, with a specialization in artificial in- telligence and robotics. He received the B.Sc. degree in Computer Engineering from the Univer...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.