RouterVLA: Turning Smoke Tests into Supervision for Heterogeneous VLA Selection
Pith reviewed 2026-06-26 04:21 UTC · model grok-4.3
The pith
Smoke-test rollouts can supervise selection among vision-language-action policies and raise held-out success by 14.64 percentage points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
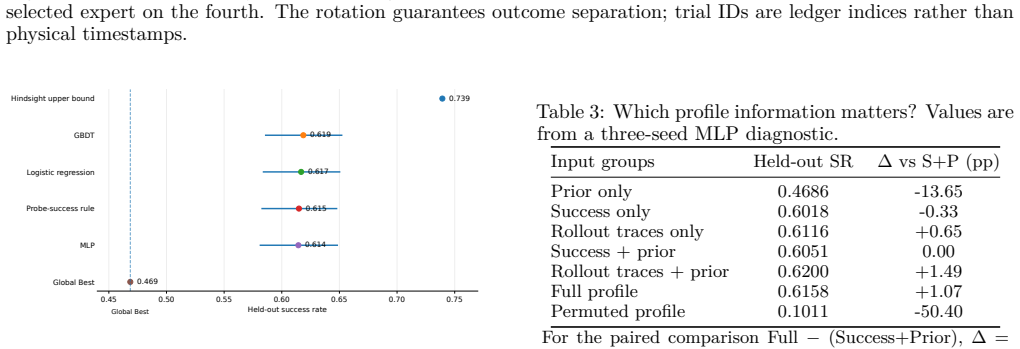
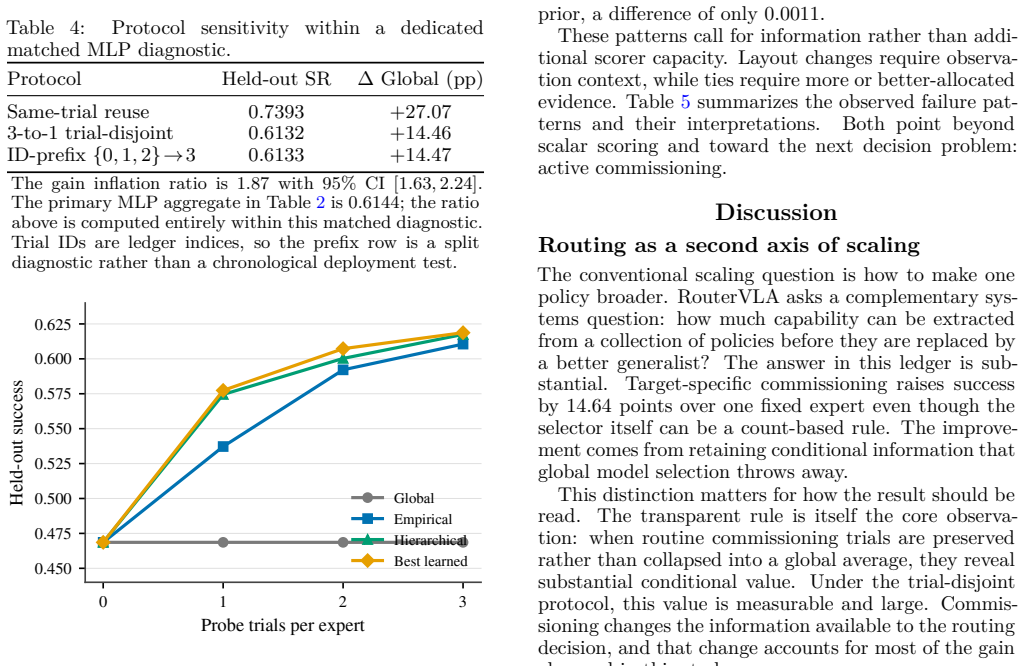
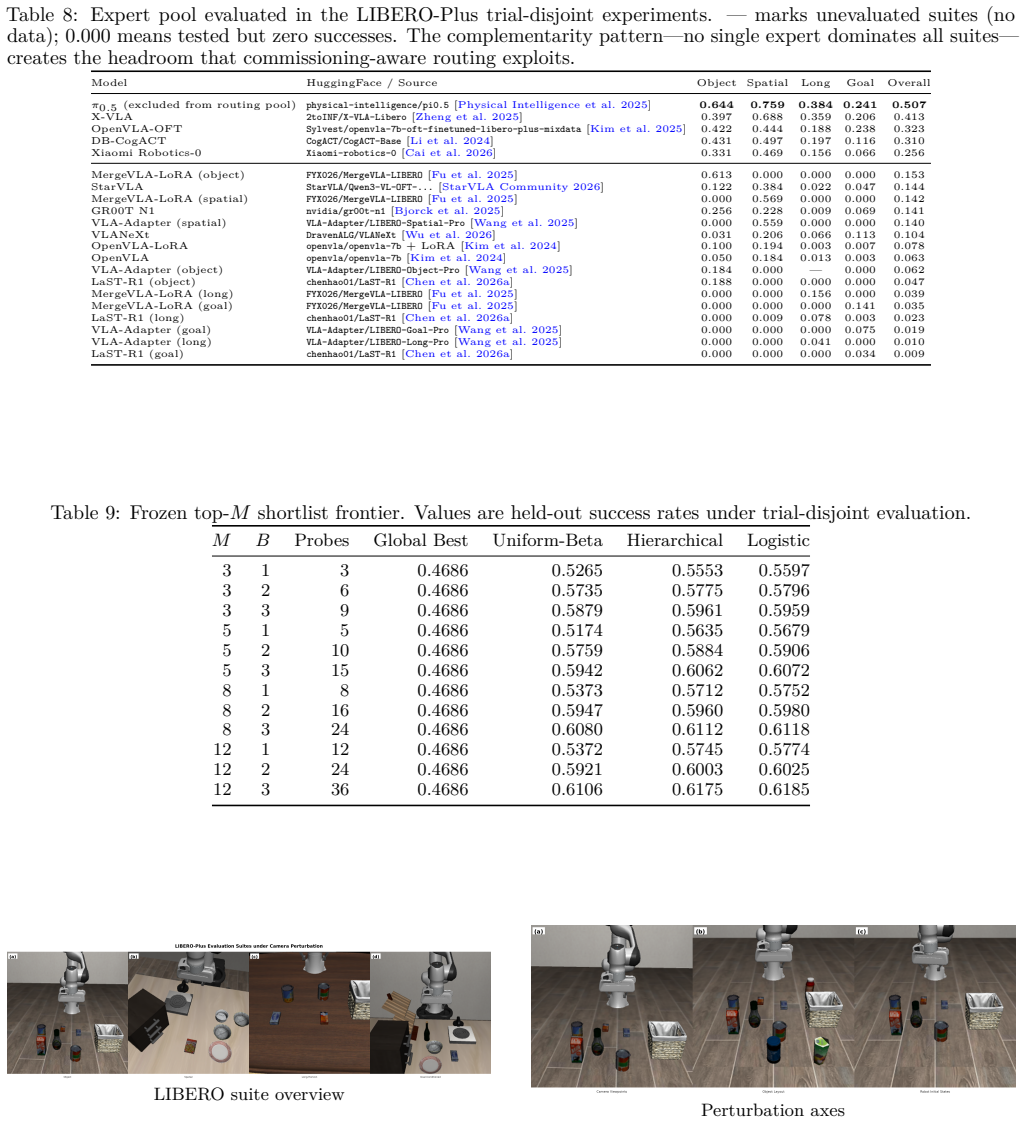
Pre-deployment evaluation rollouts can be reused to supervise policy selection among heterogeneous vision-language-action models through outcome-disjoint cross-fitting. A transparent probe-success rule raises held-out success from 0.4686 to 0.6149 across 34,752 rollout records. Learned scorers are statistically indistinguishable from this rule when profiles are scalar-only. Reusing the scored trial inflates the measured gain by 1.87 times, demonstrating that credible routing requires outcome separation. Model scaling improves individual policies while commissioning-aware routing improves the system.
What carries the argument
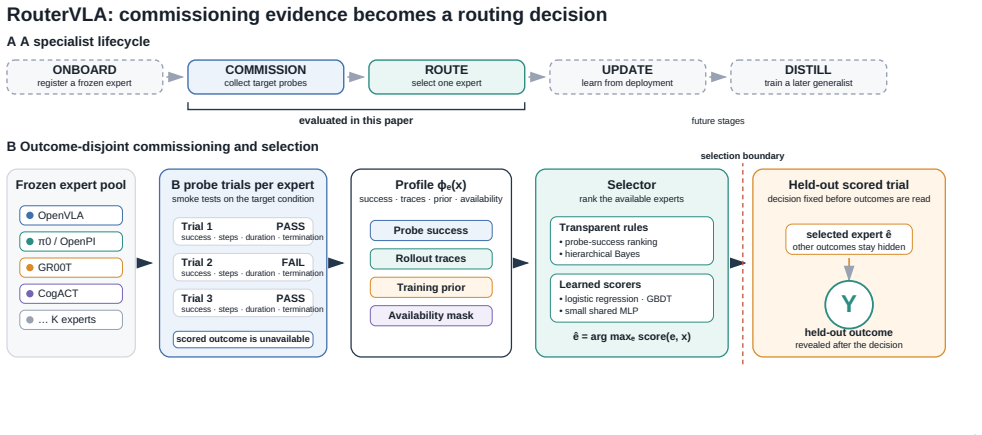
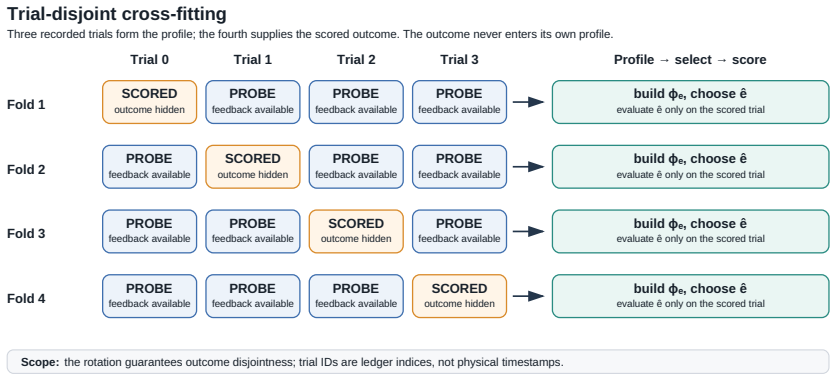
Outcome-disjoint cross-fitting, in which recorded probe rollouts build a profile for each frozen expert and a separate trial scores the selected expert.
If this is right
- Commissioning carries the routing value while extra scalar scorer capacity does not create it.
- Credible ledger routing needs outcome separation.
- Model scaling improves individual policies, while commissioning-aware routing improves the system built from them.
Where Pith is reading between the lines
- This selection method might apply to other robot policy ensembles where smoke testing is standard practice.
- Richer profiles that include more than scalar success rates could potentially benefit from learned scorers in future extensions.
- Similar routing techniques could help in selecting among models for other sequential decision tasks beyond robotics.
Load-bearing premise
The smoke-test rollouts used to build each policy profile are representative of that policy's performance on the target tasks and remain strictly outcome-disjoint from the held-out scoring trials.
What would settle it
Finding a collection of tasks where the probe-success rule selects policies that perform worse on held-out trials than a random or fixed choice would falsify the central claim.
Figures
read the original abstract
We study whether pre-deployment evaluation rollouts can be reused to supervise policy selection. Robot teams routinely smoke test candidate vision-language-action (VLA) policies, then compress those trials into a global winner. RouterVLA evaluates this idea with outcome-disjoint cross-fitting: recorded probes build a profile for each frozen expert, and a separate trial scores the selected expert without entering its profile. Across 34,752 LIBERO-Plus rollout records, a transparent probe-success rule raises held-out success from 0.4686 to 0.6149, a +14.64pp gain. Under the scalar-only profiles studied here, learned scorers are statistically indistinguishable from this rule, showing that commissioning carries the routing value while extra scalar scorer capacity does not create it. Reusing the scored trial inflates the measured gain by $1.87\times$, so credible ledger routing needs outcome separation; model scaling improves individual policies, while commissioning-aware routing improves the system built from them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents RouterVLA, a framework for reusing pre-deployment smoke-test rollouts to supervise selection among heterogeneous vision-language-action (VLA) policies. Employing outcome-disjoint cross-fitting across 34,752 LIBERO-Plus rollout records, it reports that a transparent probe-success rule improves held-out success from 0.4686 to 0.6149 (+14.64pp). Learned scalar scorers are statistically indistinguishable from this rule, and reusing the scored trial inflates measured gains by 1.87x, underscoring the necessity of outcome separation. The work concludes that commissioning data drives routing value while extra scorer capacity does not.
Significance. If the result holds, the paper demonstrates that simple, transparent rules derived from smoke tests can deliver substantial system-level gains in VLA ensembles, with limited marginal benefit from learned scorers under the scalar profiles examined. The scale of the empirical evaluation (34,752 records) and the explicit handling of circularity via outcome separation are notable strengths that support credible claims about practical policy selection. This has potential implications for deployment of policy teams in robotics, shifting emphasis toward evaluation data reuse over complex learned selectors.
major comments (1)
- [Results / abstract] The central +14.64pp gain from the probe-success rule (reported in the abstract and results) depends on smoke-test rollouts being representative of each policy's performance distribution on the target tasks. The manuscript provides only aggregate success rates and states that learned scorers are indistinguishable, but does not report per-policy probe-vs-held-out correlation coefficients, task-distribution overlap statistics, or sensitivity checks under different smoke-test sampling regimes. This assumption is load-bearing for attributing the improvement to the selection rule rather than policy heterogeneity.
minor comments (2)
- [Abstract] The abstract refers to 'scalar-only profiles' without a concise definition or pointer to the exact feature set used; adding this would aid readability.
- [Methods] A diagram or pseudocode illustrating the outcome-disjoint cross-fitting procedure (profile building vs. scoring trials) would clarify the separation mechanism.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the load-bearing assumption in our evaluation. We address the comment directly below.
read point-by-point responses
-
Referee: [Results / abstract] The central +14.64pp gain from the probe-success rule (reported in the abstract and results) depends on smoke-test rollouts being representative of each policy's performance distribution on the target tasks. The manuscript provides only aggregate success rates and states that learned scorers are indistinguishable, but does not report per-policy probe-vs-held-out correlation coefficients, task-distribution overlap statistics, or sensitivity checks under different smoke-test sampling regimes. This assumption is load-bearing for attributing the improvement to the selection rule rather than policy heterogeneity.
Authors: We agree that the manuscript currently reports only aggregate rates and does not include the requested per-policy statistics. The outcome-disjoint cross-fitting on 34,752 records from the identical LIBERO-Plus task distribution provides the primary support for representativeness, and the 1.87x inflation under trial reuse already isolates the effect of the selection rule. To strengthen attribution, the revision will add per-policy probe-vs-held-out Spearman correlations, task-distribution overlap metrics, and sensitivity results under varied smoke-test sampling fractions. revision: yes
Circularity Check
No circularity: outcome-disjoint trials keep held-out gains independent of profile construction
full rationale
The paper measures routing gains on held-out trials that are explicitly outcome-disjoint from the smoke-test rollouts used to build each policy profile. It directly reports the 1.87× inflation that occurs when this separation is violated, confirming the measurement procedure does not force the reported +14.64pp improvement. No equations reduce a prediction to a fitted input by construction, no self-citations carry load-bearing uniqueness claims, and the probe-success rule is a transparent non-learned baseline. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Smoke-test rollouts provide representative profiles of policy performance when kept outcome-disjoint from scoring trials.
Reference graph
Works this paper leans on
-
[1]
Ong, Isaac and Almahairi, Amjad and Wu, Vincent and Chiang, Wei-Lin and Wu, Tianhao and Gonzalez, Joseph E. and Kadous, M. Waleed and Stoica, Ion , year =. 2406.18665 , archivePrefix =
- [2]
-
[3]
Moo Jin Kim and Karl Pertsch and Siddharth Karamcheti and others , year =. 2406.09246 , archivePrefix =
-
[4]
Advances in Neural Information Processing Systems , volume =
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[5]
Senyu Fei and Siyin Wang and Junhao Shi and Zihao Dai and Jikun Cai and Pengfang Qian and Li Ji and Xinzhe He and Shiduo Zhang and Zhaoye Fei and Jinlan Fu and Jingjing Gong and Xipeng Qiu , year =. 2510.13626 , url =
-
[6]
2025 , eprint =
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success , author =. 2025 , eprint =
2025
-
[7]
Fu, Yuxia and Zhang, Zhizhen and Zhang, Yuqi and Wang, Zijian and Huang, Zi and Luo, Yadan , year =. 2511.18810 , archivePrefix =
-
[8]
Advances in Computers , volume =
The Algorithm Selection Problem , author =. Advances in Computers , volume =. 1976 , publisher =. doi:10.1016/S0065-2458(08)60520-3 , url =
-
[9]
and Leyton-Brown, Kevin , booktitle =
Thornton, Chris and Hutter, Frank and Hoos, Holger H. and Leyton-Brown, Kevin , booktitle =. 2013 , doi =
2013
-
[10]
Advances in Neural Information Processing Systems , volume =
Efficient and Robust Automated Machine Learning , author =. Advances in Neural Information Processing Systems , volume =. 2015 , url =
2015
-
[11]
Journal of Machine Learning Research , volume =
Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization , author =. Journal of Machine Learning Research , volume =. 2018 , url =
2018
-
[12]
Proceedings of the 33rd International Conference on Machine Learning , pages =
Doubly Robust Off-policy Value Evaluation for Reinforcement Learning , author =. Proceedings of the 33rd International Conference on Machine Learning , pages =. 2016 , url =
2016
-
[13]
Proceedings of the 33rd International Conference on Machine Learning , pages =
Data-Efficient Off-Policy Policy Evaluation for Reinforcement Learning , author =. Proceedings of the 33rd International Conference on Machine Learning , pages =. 2016 , url =
2016
-
[14]
Journal of Machine Learning Research , volume =
Scikit-learn: Machine Learning in Python , author =. Journal of Machine Learning Research , volume =. 2011 , url =
2011
-
[15]
Advances in Neural Information Processing Systems , volume =
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and Desmaison, Alban and K. Advances in Neural Information Processing Systems , volume =. 2019 , url =
2019
-
[16]
Liu, Songming and Wu, Lingxuan and Li, Bangguo and Tan, Hengkai and Chen, Huayu and Wang, Zhengyi and Xu, Ke and Su, Hang and Zhu, Jun , year =. 2410.07864 , archivePrefix =
-
[17]
Chen, Yiteng and Cao, Zhe and Ren, Hongjia and Yang, Chenjie and Li, Wenbo and Wang, Shiyi and Wang, Yemin and Zhang, Li and Shao, Yanming and Zhao, Zhenjun and Zhuang, Huiping and Wu, Qingyao , year =. 2603.07892 , archivePrefix =
-
[18]
2026 , eprint =
Agon: An Autonomous Large-Scale Omnidisciplinary Research System Built on Prompt Economy , author =. 2026 , eprint =
2026
-
[19]
2026 , eprint=
PerspectiveGap: A Benchmark for Multi-Agent Orchestration Prompting , author=. 2026 , eprint=
2026
-
[20]
Anthony Brohan and Noah Brown and Justice Carbajal and Yevgen Chebotar and Joseph Dabis and Chelsea Finn and Keerthana Gopalakrishnan and Karol Hausman and Alex Herzog and Jasmine Hsu and Julian Ibarz and Brian Ichter and Alex Irpan and Tomas Jackson and Sally Jesmonth and Nikhil J. Joshi and Ryan Julian and Dmitry Kalashnikov and Yuheng Kuang and Isabel ...
2023
-
[21]
Anthony Brohan and Noah Brown and Justice Carbajal and Yevgen Chebotar and Xi Chen and Krzysztof Choromanski and Tianli Ding and Danny Driess and Avinava Dubey and Chelsea Finn and Pete Florence and Chuyuan Fu and Montse Gonzalez Arenas and Keerthana Gopalakrishnan and Kehang Han and Karol Hausman and Alexander Herzog and Jasmine Hsu and Brian Ichter and ...
-
[22]
2024 , doi =
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages =. 2024 , doi =
2024
-
[23]
_0 : A Vision-Language-Action Flow Model for General Robot Control , author =. Proceedings of Robotics: Science and Systems , year =. doi:10.15607/RSS.2025.XXI.010 , eprint =
-
[24]
Octo: An Open-Source Generalist Robot Policy
Proceedings of Robotics: Science and Systems , year =. doi:10.15607/RSS.2024.XX.090 , url =
-
[25]
Machine Learning , volume =
Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning , author =. Machine Learning , volume =. 1992 , doi =
1992
-
[26]
2015 , eprint =
Distilling the Knowledge in a Neural Network , author =. 2015 , eprint =
2015
-
[27]
2020 , eprint =
Scaling Laws for Neural Language Models , author =. 2020 , eprint =
2020
-
[28]
2025 , eprint =
Johan Bjorck and Fernando Casta. 2025 , eprint =
2025
-
[29]
Qixiu Li and Yaobo Liang and Zeyu Wang and others , year =. 2411.19650 , url =
-
[30]
Xiao-Ming Wu and Bin Fan and Kang Liao and Jian-Jian Jiang and Runze Yang and Yihang Luo and Zhonghua Wu and Wei-Shi Zheng and Chen Change Loy , year =. 2602.18532 , url =
-
[31]
Yihao Wang and Pengxiang Ding and Lingxiao Li and Can Cui and Zirui Ge and Xinyang Tong and Wenxuan Song and Han Zhao and Wei Zhao and Pengxu Hou and Siteng Huang and Yifan Tang and Wenhui Wang and Ru Zhang and Jianyi Liu and Donglin Wang , year =. 2509.09372 , url =
- [32]
-
[33]
Jinliang Zheng and Jianxiong Li and Zhihao Wang and Dongxiu Liu and Xirui Kang and others , year =. 2510.10274 , url =
- [34]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.