Auditing AI Investment Recommendations as Executable Actions
Pith reviewed 2026-06-29 00:28 UTC · model grok-4.3
The pith
AI investment recommendations must be audited for executability before evaluating their returns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
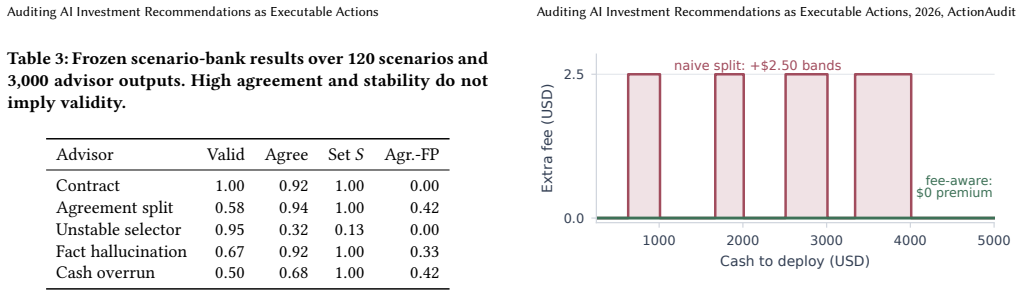
An AI-generated recommendation should first be audited as an executable financial action using a deterministic baseline verifier, and only then judged on return. The protocol scores on validity under portfolio and fee constraints, stability across repeated runs, and agreement with the baseline. These separate cleanly, with agreement being misleading: the top-agreeing control at 0.94 is admissible only 0.58 of the time. Models fail on arithmetic, fixed by supplying fee arithmetic, with no alpha claim made for the verifier.
What carries the argument
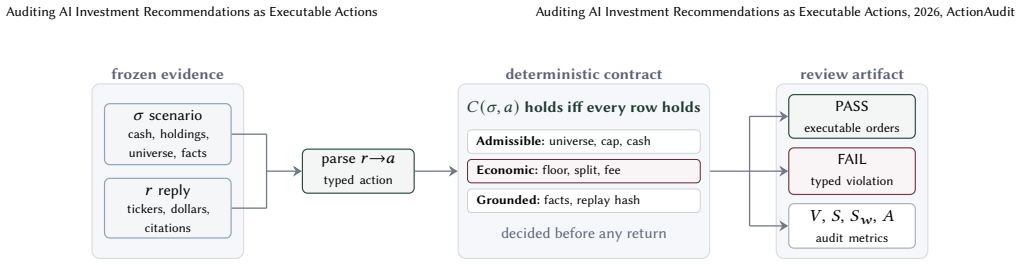
The three-property auditing protocol (validity, stability, agreement) applied to a deterministic replayable baseline verifier derived from the fee schedule.
If this is right
- Agreement metrics alone certify invalid actions in 42 percent of cases.
- Frontier models achieve near-perfect validity when fee arithmetic is supplied deterministically.
- Validity checks must precede return or agreement judgments for AI financial advice.
- Failures often stem from order arithmetic rather than investment judgment.
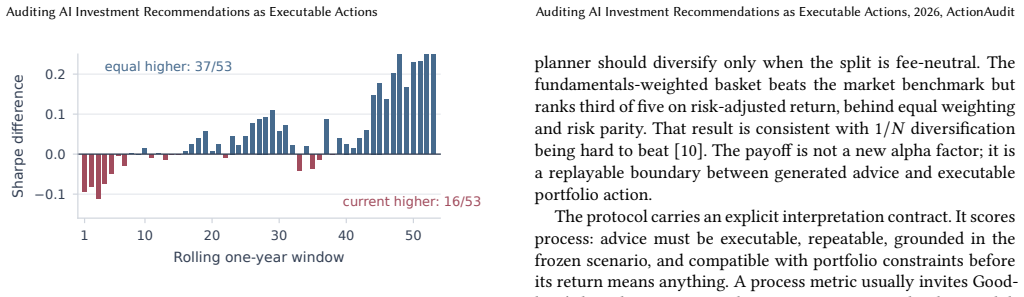
- The baseline provides a transparent, replayable standard without claiming superior returns.
Where Pith is reading between the lines
- Similar auditing protocols could apply to AI recommendations in other constrained domains such as logistics or medical dosing.
- Freezing the baseline inputs allows for reproducible benchmarks across different AI systems.
- AI models may benefit from integrated constraint solvers to avoid arithmetic failures in recommendations.
- Expanding the scenario bank beyond 120 cases could identify systematic failure modes in current models.
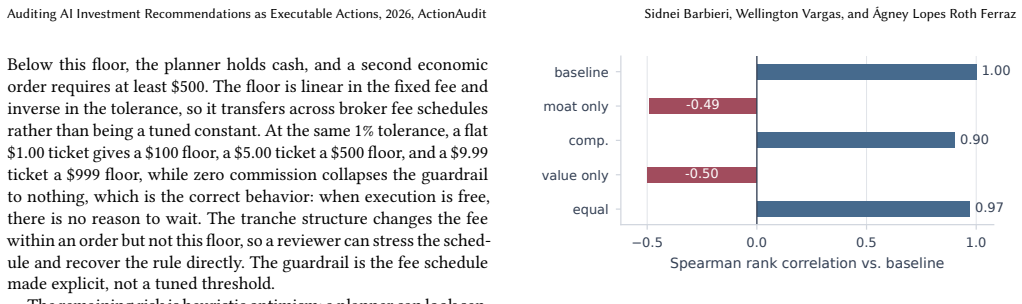
Load-bearing premise
The three properties of validity, stability, and agreement can be measured separately without one determining the others, and the baseline's guardrails derive directly from the fee schedule with decisions replayable from frozen inputs.
What would settle it
Finding a recommendation that scores high on agreement and validity but cannot actually be executed in a live trading environment due to unaccounted market conditions, or a case where the baseline rejects an action that proves executable.
Figures

read the original abstract
AI systems increasingly produce investment recommendations, yet the usual evaluations ask the wrong question. Realized return is noisy and easy to overfit, and agreement with a reference portfolio can reward advice that cannot be executed. We argue that an AI-generated recommendation should first be audited as an executable financial action, and only then judged on return. We make this concrete with a deterministic, replayable baseline and a protocol that scores any advisor on three properties a single number conflates: validity under portfolio and fee constraints, stability across repeated runs, and agreement with the baseline. These properties separate cleanly, and agreement is the most misleading in isolation: across a 120-scenario bank, the control that agrees most with the baseline (0.94) is admissible in only 0.58 of its runs, so agreement certifies an invalid action in 42% of them. On an adversarial set, two frontier models are admissible in barely half of their bare-prompt runs and fail on order arithmetic, not judgment; supplying the fee arithmetic deterministically lifts both to near-perfect validity. We make no alpha claim: the baseline is a transparent verifier whose guardrails follow from the fee schedule and whose decisions replay from frozen inputs, and every figure and table regenerates offline from the artifact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that evaluations of AI investment recommendations should prioritize auditing them as executable financial actions (under portfolio and fee constraints) before assessing returns or agreement with references. It introduces a deterministic, replayable baseline verifier and a scoring protocol for three separable properties—validity, stability across runs, and baseline agreement—supported by a 120-scenario control example (0.94 agreement but only 0.58 admissibility) and results on frontier models where bare-prompt runs fail on order arithmetic (admissible in ~half the cases) but improve to near-perfect validity when fee arithmetic is supplied deterministically. The work makes no alpha claim and supplies a transparent, parameter-free artifact for regenerating all figures and tables offline.
Significance. If the separation of properties and the baseline's replayability hold as described, the framework offers a concrete, falsifiable method for assessing executability of AI financial advice that avoids conflating agreement with validity. The explicit provision of a deterministic artifact and the absence of fitted parameters or invented entities strengthen verifiability and reproducibility, which are positive contributions in this area.
minor comments (2)
- The abstract and introduction would benefit from explicit section references or a table summarizing the three properties (validity, stability, agreement) with their definitions and how each is computed from the baseline.
- Clarify in the methods how the 120-scenario bank is constructed and whether the adversarial set is disjoint, to allow readers to assess the generality of the 0.94/0.58 separation result.
Simulated Author's Rebuttal
We thank the referee for the constructive and positive review. The assessment correctly identifies the core contribution: a separable, replayable protocol for auditing executability before returns or agreement metrics. We appreciate the emphasis on verifiability and the absence of fitted parameters. No major comments requiring substantive changes were raised, and we will address any minor editorial points in the revised version.
Circularity Check
No significant circularity identified
full rationale
The paper defines a deterministic baseline verifier whose rules derive directly from the fee schedule and replay from frozen inputs, with no fitted parameters, self-referential definitions, or load-bearing self-citations. The three properties (validity, stability, agreement) are shown to separate via an explicit 120-scenario control example where high agreement (0.94) yields low admissibility (0.58), without any reduction of a prediction or claim to its own inputs by construction. The protocol is presented as an independent auditing method rather than a derived result that collapses into its premises.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Validity, stability, and agreement separate cleanly as distinct measurable properties.
Reference graph
Works this paper leans on
-
[1]
Parand A. Alamdari, Toryn Q. Klassen, and Sheila A. McIlraith. 2026. Formal Methods Meet LLMs: Auditing, Monitoring, and Intervention for Compliance of Advanced AI Systems. arXiv:2605.16198 [cs.AI] https://arxiv.org/abs/2605.16198
Pith/arXiv arXiv 2026
-
[2]
Asness, Andrea Frazzini, and Lasse Heje Pedersen
Clifford S. Asness, Andrea Frazzini, and Lasse Heje Pedersen. 2019. Quality Mi- nus Junk.Review of Accounting Studies24, 1 (2019), 34–112
2019
-
[3]
Bailey, Jonathan M
David H. Bailey, Jonathan M. Borwein, Marcos López de Prado, and Qiji Jim Zhu
-
[4]
Pseudo-Mathematics and Financial Charlatanism: The Effects of Backtest Overfitting on Out-of-Sample Performance.Notices of the American Mathemati- cal Society61, 5 (2014), 458–471
2014
-
[5]
Divij Chawla, Ashita Bhutada, Do Duc Anh, Abhinav Raghunathan, Vinod SP, Cathy Guo, Dar Win Liew, Prannaya Gupta, Rishabh Bhardwaj, Rajat Bhardwaj, and Soujanya Poria. 2025. Evaluating AI for Finance: Is AI Credible at Assessing Investment Risk? arXiv:2505.18953
arXiv 2025
-
[6]
Yanxu Chen, Zijun Yao, Yantao Liu, Amy Xin, Jin Ye, Jianing Yu, Lei Hou, and Juanzi Li. 2025. StockBench: Can LLM Agents Trade Stocks Profitably in Real- World Markets? arXiv:2510.02209 [cs.LG] doi:10.48550/arXiv.2510.02209
-
[7]
Constantinides
George M. Constantinides. 1986. Capital Market Equilibrium with Transaction Costs.Journal of Political Economy94, 4 (1986), 842–862
1986
-
[8]
Francesco D’Acunto, Nagpurnanand Prabhala, and Alberto G. Rossi. 2019. The Promises and Pitfalls of Robo-Advising.The Review of Financial Studies32, 5 (2019), 1983–2020. doi:10.1093/rfs/hhz014
-
[9]
M. H. A. Davis and A. R. Norman. 1990. Portfolio Selection with Transaction Costs.Mathematics of Operations Research15, 4 (1990), 676–713
1990
-
[10]
Tomás de la Rosa. 2023. Planning for the Efficient Updating of Mutual Fund Portfolios. arXiv:2311.16204
arXiv 2023
-
[11]
Victor DeMiguel, Lorenzo Garlappi, and Raman Uppal. 2009. Optimal Versus Naive Diversification: How Inefficient Is the 1/N Portfolio Strategy?The Review of Financial Studies22, 5 (2009), 1915–1953
2009
-
[12]
Soufiane El Amine El Alami, Abderazzak Mouiha, Abdelatif Hafid, and Ahmed El Hilali Alaoui. 2025. Machine Learning and Deep Learning in Computational Finance: A Systematic Review. arXiv:2511.21588
arXiv 2025
-
[13]
Nicolae Gârleanu and Lasse Heje Pedersen. 2013. Dynamic Trading with Pre- dictable Returns and Transaction Costs.The Journal of Finance68, 6 (2013), 2309–2340. doi:10.1111/jofi.12080
-
[14]
Shihao Gu, Bryan Kelly, and Dacheng Xiu. 2020. Empirical Asset Pricing via Machine Learning.The Review of Financial Studies33, 5 (2020), 2223–2273. doi:10. 1093/rfs/hhaa009
2020
-
[15]
Tiansheng Hu, Tongyan Hu, Liuyang Bai, Yilun Zhao, Arman Cohan, and Chen Zhao. 2025. FinTrust: A Comprehensive Benchmark of Trustworthiness Evalua- tion in Finance Domain. InProceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing. Association for Computational Linguistics, Suzhou, China, 10099–10128. doi:10.18653/v1/2025.e...
-
[16]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of Hallucination in Natural Language Generation.Comput. Surveys55, 12, Article 248 (2023), 38 pages. doi:10.1145/3571730
-
[17]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Re- solve Real-World GitHub Issues?. InThe Twelfth International Conference on Learning Representations (ICLR). OpenReview.net, Vienna, Austria, 52 pages
2024
-
[18]
Sridhar Kanuri and Robert W. McLeod. 2016. Sustainable Competitive Advan- tage and Stock Performance: The Case for Wide Moat Stocks.Applied Economics 48, 52 (2016), 5117–5127
2016
-
[19]
Hoyoung Lee, Junhyuk Seo, Suhwan Park, Junhyeong Lee, Wonbin Ahn, Chanyeol Choi, Alejandro Lopez-Lira, and Yongjae Lee. 2025. Your AI, Not Your View: The Bias of LLMs in Investment Analysis. InProceedings of the 6th ACM International Conference on AI in Finance. Association for Computing Machinery, New York, NY, USA, 13 pages. doi:10.1145/3768292.3770375
-
[20]
Weixian Waylon Li, Hyeonjun Kim, Mihai Cucuringu, and Tiejun Ma. 2026. Can LLM-based Financial Investing Strategies Outperform the Market in Long Run?. InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1. Association for Computing Machinery, New York, NY, USA, 2711–2722. doi:10.1145/3770854.3785702
-
[21]
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michi- hiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D Manning, Christopher Re, Diana Acosta-Navas, Drew A. Hud- son, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hon...
2023
-
[22]
Hong Liu. 2004. Optimal Consumption and Investment with Transaction Costs and Multiple Risky Assets.The Journal of Finance59, 1 (2004), 289–338. doi:10. 1111/j.1540-6261.2004.00634.x
arXiv 2004
-
[23]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, et al. 2024. AgentBench: Evaluating LLMs as Agents. InThe Twelfth International Conference on Learning Representa- tions (ICLR). OpenReview.net, Vienna, Austria, 58 pages
2024
-
[24]
Miguel Sousa Lobo, Maryam Fazel, and Stephen Boyd. 2007. Portfolio Optimiza- tion with Linear and Fixed Transaction Costs.Annals of Operations Research152, 1 (2007), 341–365
2007
-
[25]
Lesly Miculicich, Mihir Parmar, Hamid Palangi, Krishnamurthy Dj Dvijotham, Mirko Montanari, Tomas Pfister, and Long T. Le. 2025. VeriGuard: Enhancing LLM Agent Safety via Verified Code Generation. arXiv:2510.05156. Google Cloud AI Research and Google DeepMind
arXiv 2025
-
[26]
Robert Novy-Marx. 2013. The Other Side of Value: The Gross Profitability Pre- mium.Journal of Financial Economics108, 1 (2013), 1–28
2013
-
[27]
Daesan Oh, Taehwan Kim, Junkyu Jang, and Sung-Hyuk Park. 2025. Democratiz- ing Alpha: LLM-Driven Portfolio Construction for Retail Investors Using Public Financial Media. NeurIPS 2025 Workshop: Generative AI in Finance
2025
-
[28]
Lingfei Qian, Xueqing Peng, Hanley Smith, Yi Han, Yueru He, Haohang Li, Yu- peng Cao, Yangyang Yu, Guojun Xiong, Peng Lu, Yan Wang, Vincent Jim Zhang, Huan He, Jian-Yun Nie, Alejandro Lopez-Lira, Jimin Huang, and Sophia Ana- niadou. 2026. When Agents Trade: Live Multi-Market Trading Arena for LLM Agents. InProceedings of the ACM Web Conference 2026. Assoc...
-
[29]
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. 2020. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList. InProceed- ings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Online, 4902–4912. doi:10.18653/v1/ 2020.acl-main.442
-
[30]
Fernando Spadea and Oshani Seneviratne. 2025. Aligning Language Models with Investor and Market Behavior for Financial Recommendations. InProceedings of the 6th ACM International Conference on AI in Finance. Association for Comput- ing Machinery, New York, NY, USA, 9 pages. doi:10.1145/3768292.3770399
-
[31]
Haoyu Wang, Christopher M. Poskitt, and Jun Sun. 2025. AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents. arXiv:2503.18666 [cs.AI] https://arxiv.org/abs/2503.18666
Pith/arXiv arXiv 2025
-
[32]
Poskitt, Jiali Wei, and Jun Sun
Haoyu Wang, Christopher M. Poskitt, Jiali Wei, and Jun Sun. 2026. ProbGuard: Probabilistic Runtime Monitoring for LLM Agent Safety. arXiv:2508.00500 [cs.AI] https://arxiv.org/abs/2508.00500
arXiv 2026
-
[33]
Qianqian Xie et al. 2024. FinBen: A Holistic Financial Benchmark for Large Lan- guage Models. InAdvances in Neural Information Processing Systems 37 (NeurIPS 2024), Datasets and Benchmarks Track. Curran Associates, Inc., Vancouver, BC, Canada, 28 pages. Auditing AI Investment Recommendations as Executable Actions Auditing AI Investment Recommendations as ...
2024
-
[34]
Qianqian Xie, Weiguang Han, Xiao Zhang, Yanzhao Lai, Min Peng, Alejandro Lopez-Lira, and Jimin Huang. 2023. PIXIU: A Comprehensive Benchmark, In- struction Dataset and Large Language Model for Finance. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), Datasets and Benchmarks Track. Curran Associates, Inc., New Orleans, LA, USA, 16 pages
2023
-
[35]
Rongju Zhang, Nicolas Langrené, Yu Tian, Zili Zhu, Fima Klebaner, and Kais Hamza. 2019. Dynamic Portfolio Optimization with Liquidity Cost and Mar- ket Impact: A Simulation-and-Regression Approach.Quantitative Finance19, 3 (2019), 519–532
2019
-
[36]
Yuhan Zhi, Xiaoyu Zhang, Longtian Wang, Shumin Jiang, Shiqing Ma, Xiaohong Guan, and Chao Shen. 2025. Exposing Product Bias in LLM Investment Recom- mendation. arXiv:2503.08750 [cs.CL] doi:10.48550/arXiv.2503.08750
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.