LLM Agents as Static Level-k Players in Behavioural Games
Pith reviewed 2026-06-29 02:29 UTC · model grok-4.3
The pith
LLMs retrieve static level-k strategies in behavioral games based on model scale without performing belief updating or backward induction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
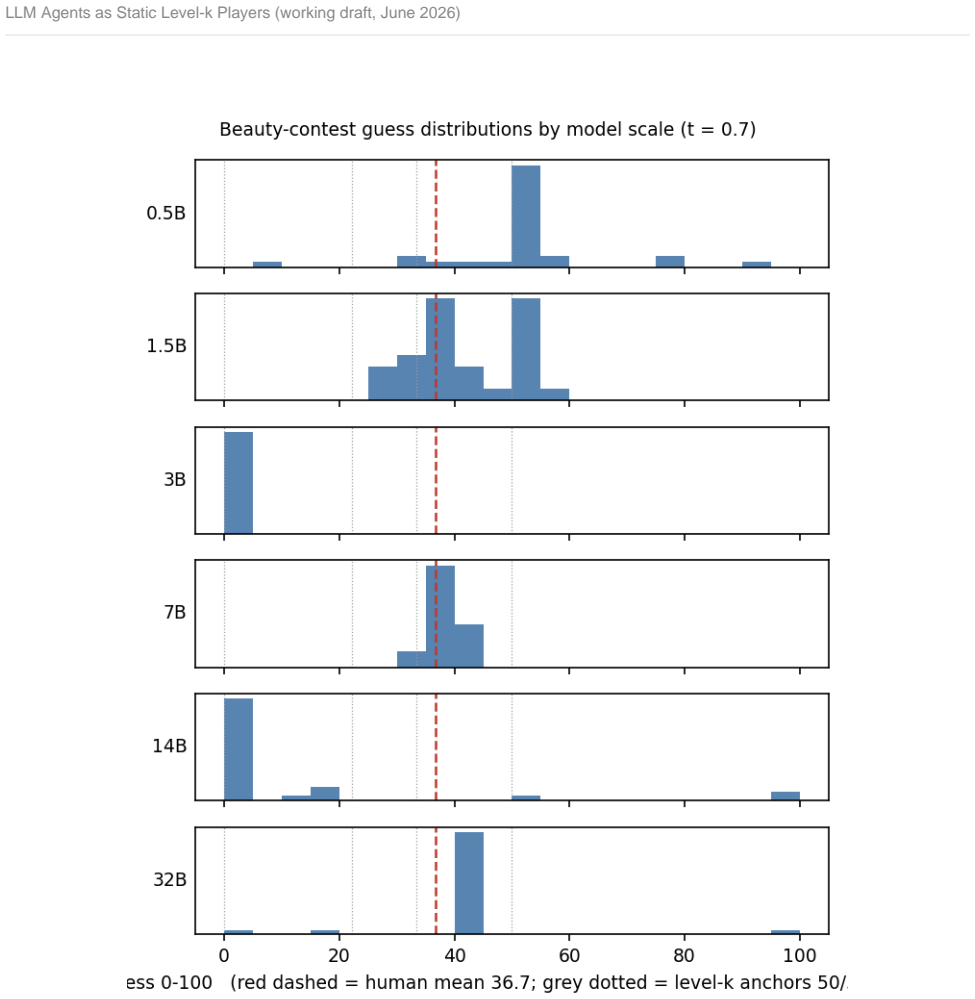
Through the lens of the level-k cognitive theory, we find that LLMs act as static, category-retrieved level-k players, where k is set by the model scale. The models also do not run within-game belief-updating or backward induction throughout multiple-round horizon settings. While human contributions decayed in the public goods game, LLMs stayed flat or rose at every scale. When the horizon test was administered, LLMs were more cooperative under an indefinite horizon compared to a finite one. However, LLMs ignore their relative round position, so no last-round defection was displayed. This implies that LLMs retrieved levels relative to the horizon category rather than working out iteratively
What carries the argument
static, category-retrieved level-k players, where the chosen level k is fixed by model scale and retrieved from the game category instead of being computed through iterative updating or backward induction.
If this is right
- LLM contributions in repeated public goods games remain flat or rise instead of decaying.
- LLMs cooperate more under indefinite horizons than finite ones but display no last-round defection.
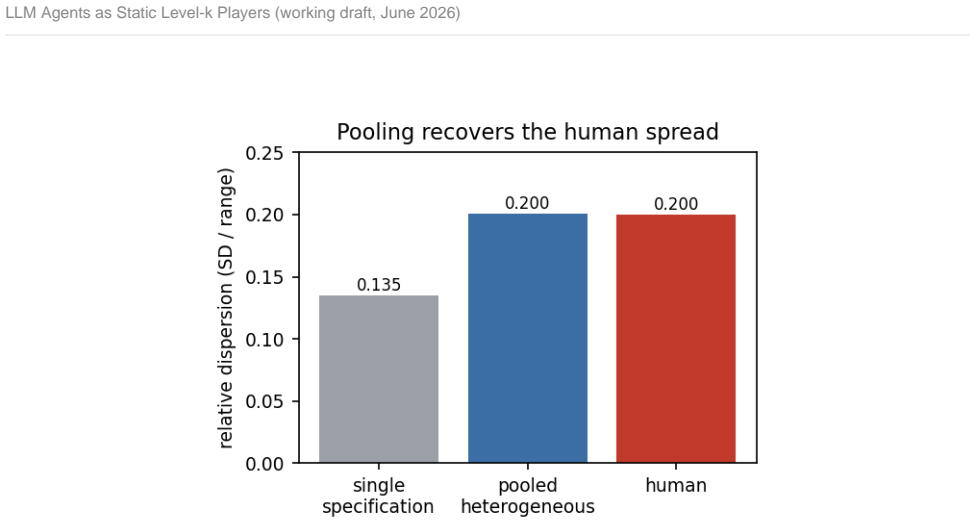
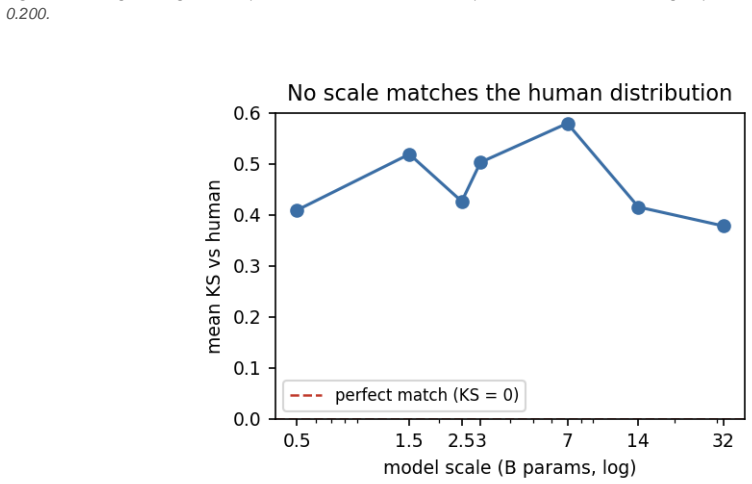
- Deployment settings such as scale and framing can adjust choice dispersion toward human data but cannot recover the dynamic strategic process.
- Quantisation has no measurable effect on fidelity to human distributions.
- Strategic behavior in LLMs is retrieved relative to game category rather than derived from the specific round structure.
Where Pith is reading between the lines
- LLM-based simulations of repeated strategic interactions may systematically miss human-style learning and end-game effects unless explicit updating modules are added.
- Category-based retrieval could limit generalization to game variants that differ from patterns in training data.
- The scale dependence of k suggests that larger models might approximate higher human levels but still without dynamic adjustment.
- Similar static retrieval patterns may appear in other domains requiring iterative reasoning such as multi-step planning tasks.
Load-bearing premise
That differences in contribution decay, horizon effects, and absence of last-round defection arise specifically from lack of belief-updating and backward induction rather than prompt sensitivity or training data patterns.
What would settle it
A controlled test in which LLMs are prompted to update beliefs from observed opponent play within a finite-horizon public goods game and then checked for emergence of last-round defection.
Figures
read the original abstract
Large Language Models (LLMs) are increasingly used as stand-ins in behavioural games. These stand-ins rely on the assumption that the LLM's distribution of choices meaningfully matches how humans play the same game. This study tests that assumption through two games. The first is a p-beauty contest, and the second one is a public goods game. The study first investigates five local-model settings within the same model family. These settings are varied together in a 360-cell factorial, which balances temperature, scale (0.5-32B), quantisation, instruct vs base, and framing. Each cell's distribution is then compared against whole choice distributions in published human data. Each deployment setting, except for quantisation, governs a different aspect of fidelity. Mechanically, while the dispersion of human players can be somewhat recovered through deployment settings, the strategic process behind it cannot. Through the lens of the level-k cognitive theory, we find that LLMs act as static, category-retrieved level-k players, where k is set by the model scale. The models also do not run within-game belief-updating or backward induction throughout multiple-round horizon settings. While human contributions decayed in the public goods game, LLMs stayed flat or rose at every scale. When the horizon test was administered, LLMs were more cooperative under an indefinite horizon compared to a finite one. However, LLMs ignore their relative round position, so no last-round defection was displayed. This implies that LLMs retrieved levels relative to the horizon category rather than working out iteratively from the specific game setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript tests LLMs as stand-ins for human players in the p-beauty contest and repeated public-goods games. Using a 360-cell factorial that crosses temperature, scale (0.5–32B), quantization, instruct vs. base, and framing, it compares each cell’s choice distribution to published human data. The central claim is that LLMs function as static, category-retrieved level-k players whose k is fixed by model scale; they retrieve a horizon category rather than performing within-game belief updating or backward induction, as shown by flat or rising contributions (versus human decay) and higher cooperation under indefinite versus finite horizons without round-position sensitivity or last-round defection.
Significance. If the attribution to absent belief-updating holds, the result would show that current LLMs cannot substitute for human subjects in multi-round strategic settings without additional controls, and that scale primarily governs which static level is retrieved. The 360-cell design and direct distributional comparisons to external human data are strengths that allow the claim to be tested rather than merely asserted.
major comments (2)
- [Abstract / horizon test] Abstract / horizon-test description: the claim that LLMs 'retrieve levels relative to the horizon category rather than working out iteratively' rests on the absence of last-round defection and round-position sensitivity. The 360-cell factorial already varies framing, yet contains no explicit condition that forces step-by-step reasoning about others’ contributions and the terminal round; without that ablation it is impossible to separate prompt framing or training-data patterns from an intrinsic inability to run backward induction.
- [Public goods game results] Public-goods results paragraph: the attribution of flat/rising contributions to absent belief-updating is load-bearing for the 'static level-k' conclusion. The manuscript does not report how level-k categories were assigned from the observed distributions, nor the exact statistical comparisons to human decay rates, leaving open the possibility that post-hoc categorization or prompt sensitivity drives the pattern rather than the claimed cognitive process.
minor comments (2)
- [Methods] The description of the 360-cell design would benefit from an explicit table listing which factors are crossed with which and how many observations per cell.
- [Throughout] Notation for 'level-k' and 'horizon category' should be defined once at first use rather than re-explained in each results subsection.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the interpretation of our results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / horizon test] Abstract / horizon-test description: the claim that LLMs 'retrieve levels relative to the horizon category rather than working out iteratively' rests on the absence of last-round defection and round-position sensitivity. The 360-cell factorial already varies framing, yet contains no explicit condition that forces step-by-step reasoning about others’ contributions and the terminal round; without that ablation it is impossible to separate prompt framing or training-data patterns from an intrinsic inability to run backward induction.
Authors: The horizon test already contrasts indefinite versus finite horizons and documents the absence of round-position sensitivity and last-round defection, which differs from human backward induction. Framing variations within the 360-cell design include different horizon descriptions. We nevertheless agree that an explicit ablation prompting step-by-step reasoning about terminal-round contributions would strengthen the separation from training-data or prompt effects. We will add this condition in the revision. revision: yes
-
Referee: [Public goods game results] Public-goods results paragraph: the attribution of flat/rising contributions to absent belief-updating is load-bearing for the 'static level-k' conclusion. The manuscript does not report how level-k categories were assigned from the observed distributions, nor the exact statistical comparisons to human decay rates, leaving open the possibility that post-hoc categorization or prompt sensitivity drives the pattern rather than the claimed cognitive process.
Authors: We agree that the assignment procedure for level-k categories and the precise statistical comparisons to human decay rates should be reported explicitly. In the revised manuscript we will add a dedicated subsection describing how level-k categories were derived from the choice distributions together with the exact statistical tests against human data. revision: yes
Circularity Check
No circularity: claims rest on empirical distribution comparisons
full rationale
The paper reports results from a 360-cell factorial experiment comparing LLM choice distributions in p-beauty contest and public-goods games against published human data. The central interpretation—that LLMs behave as static category-retrieved level-k players with k set by scale and without within-game updating—is presented as an inference from observed patterns (flat contributions, horizon-category sensitivity, absence of last-round defection). No equations, fitted parameters renamed as predictions, self-citations, or ansatzes appear in the described chain; the methodology is self-contained against external human benchmarks and does not reduce any claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Affonso, F. M. (2026). Large Language Models Converge on Competitive Rationality but Diverge on Cooperation across Providers and Generations. arXiv:2604.18596. Aher, G., Arriaga, R. I., & Kalai, A. T. (2023). Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies. Proceedings of the 40th International Conference on Mac...
Pith/arXiv arXiv 2026
-
[2]
Akata, E., Schulz, L., Coda-Forno, J., Oh, S. J., Bethge, M., & Schulz, E. (2025). Playing Repeated Games with Large Language Models. Nature Human Behaviour. Alekseenko, I., Dagaev, D., Paklina, S., & Parshakov, P. (2025). Strategizing with AI: Insights from a Beauty Contest Experiment. Journal of Economic Behavior & Organization. arXiv:2502.03158. Argyle...
arXiv 2025
-
[3]
Isaac, R. M., & Walker, J. M. (1988). Group Size Effects in Public Goods Provision: The Voluntary Contributions Mechanism. Quarterly Journal of Economics, 103(1), 179-199. Jia, J., Yuan, Z., Pan, J., McNamara, P. E., & Chen, D. (2025). LLM Strategic Reasoning: Agentic Study through Behavioral Game Theory. arXiv:2502.20432. Kahneman, D., Knetsch, J. L., & ...
arXiv 1988
-
[4]
arXiv:2502.17720. Liberman, V., Samuels, S. M., & Ross, L. (2004). The Name of the Game: Predictive Power of Reputations versus Situational Labels in Determining Prisoner's Dilemma Game Moves. Personality and Social Psychology Bulletin, 30(9), 1175-1185. McKelvey, R. D., & Palfrey, T. R. (1995). Quantal Response Equilibria for Normal Form Games. Games and...
arXiv 2004
-
[5]
Appendix B: The Punishment Condition The original human ground-truth study included both a punishment condition and a non-punishment control. This punishment condition is reported here rather than in the body because its findings are a property of the sanctioning institution and its mechanisms, as opposed to the level-k parameters elicited from the main r...
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.