PPO-EAL: Exact Augmented Lagrangian Proximal Policy Optimization for Safe Robotic Control
Pith reviewed 2026-06-29 04:47 UTC · model grok-4.3
The pith
PPO-EAL integrates exact augmented Lagrangian terms into PPO to enforce robotic safety constraints without large penalty factors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
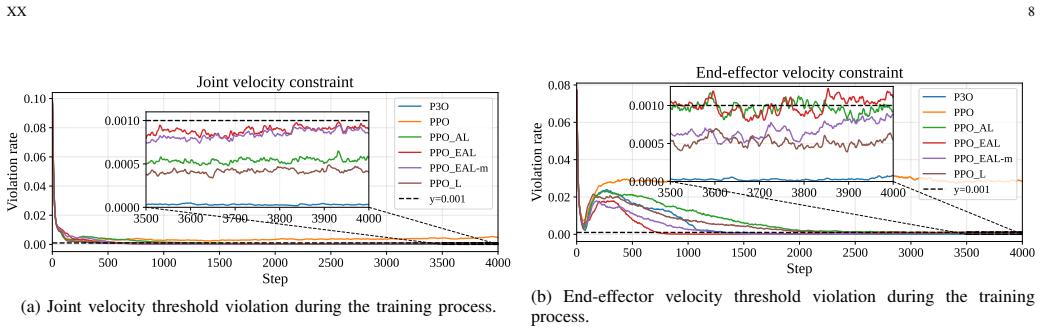
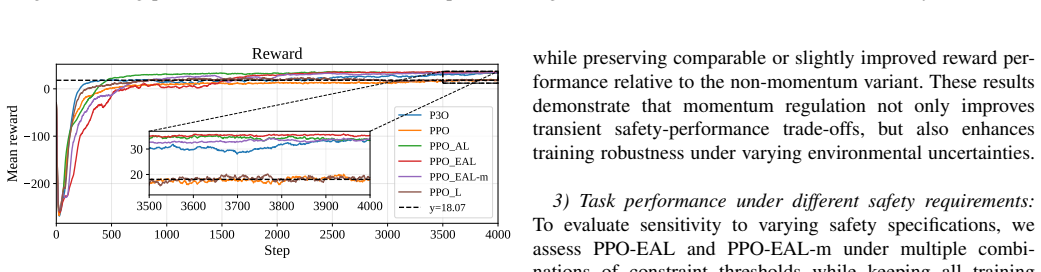
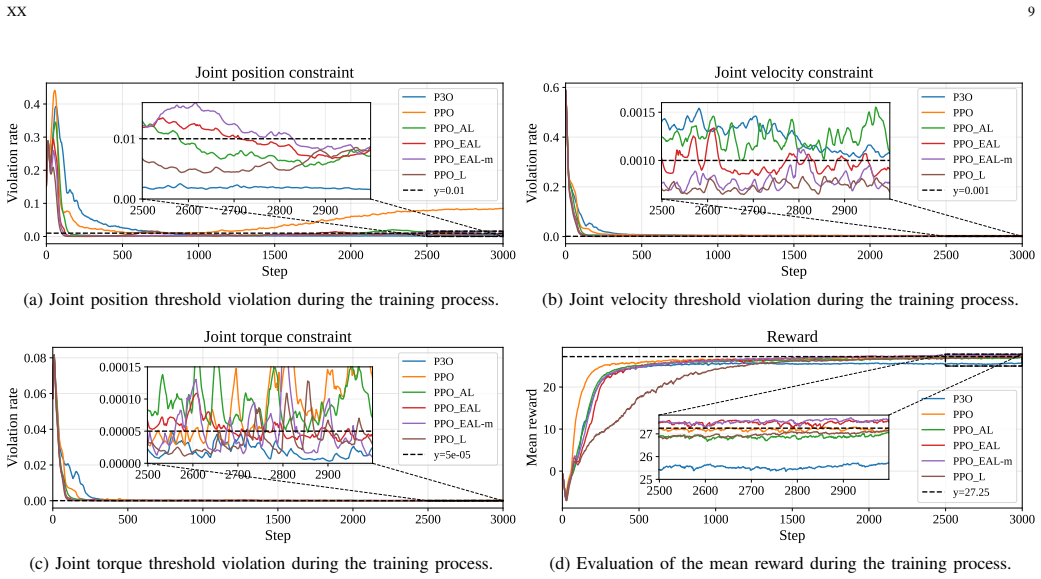
PPO-EAL achieves theoretically grounded constraint enforcement without requiring impractically large penalty factors by combining clipped policy updates with exact quadratic penalty terms. A momentum-regulated multiplier update further improves dual-variable stability, reducing constraint oscillation and unsafe behavior while preserving task performance. The paper supplies exactness and convergence analysis under standard stochastic approximation assumptions and validates the approach on cart-pole balancing, cart-double-pendulum stabilization, 7-DoF Franka reaching, quadrupedal locomotion, and a contact-rich gear assembly task.
What carries the argument
Exact augmented Lagrangian optimization embedded in proximal policy optimization, using exact quadratic penalties and momentum-regulated multiplier updates.
If this is right
- Constraint satisfaction becomes exact rather than approximate without inflating penalty coefficients.
- Dual-variable stability improves, lowering unsafe oscillations during learning.
- Task performance is maintained while safety metrics improve across cart-pole, pendulum, manipulator, and locomotion benchmarks.
- Zero-shot sim-to-real transfer yields higher success rates and lower peak contact forces in contact-rich assembly.
Where Pith is reading between the lines
- The same exact-penalty structure could be tested inside other first-order policy optimizers beyond PPO.
- Momentum regulation might be adapted as a general stabilizer for dual variables in constrained RL on new robot platforms.
- The framework could be examined on tasks with time-varying or learned constraints not covered in the current benchmarks.
Load-bearing premise
The exactness and convergence claims rest on standard stochastic approximation assumptions, and the momentum update reduces oscillation for the tested robotic tasks.
What would settle it
Running PPO-EAL on the reported robotic benchmarks and observing either sustained high constraint violations or large drops in reward relative to the baselines would falsify the central performance claims.
Figures
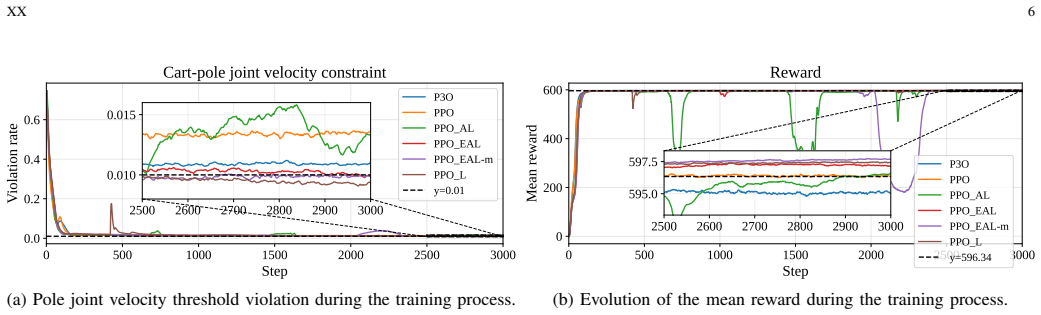
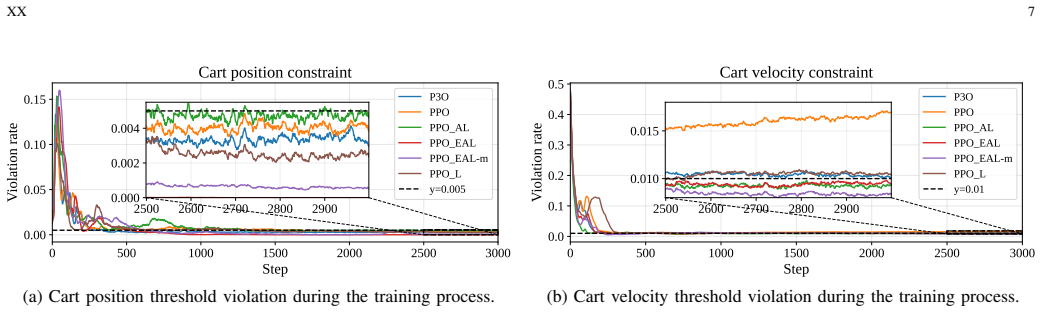
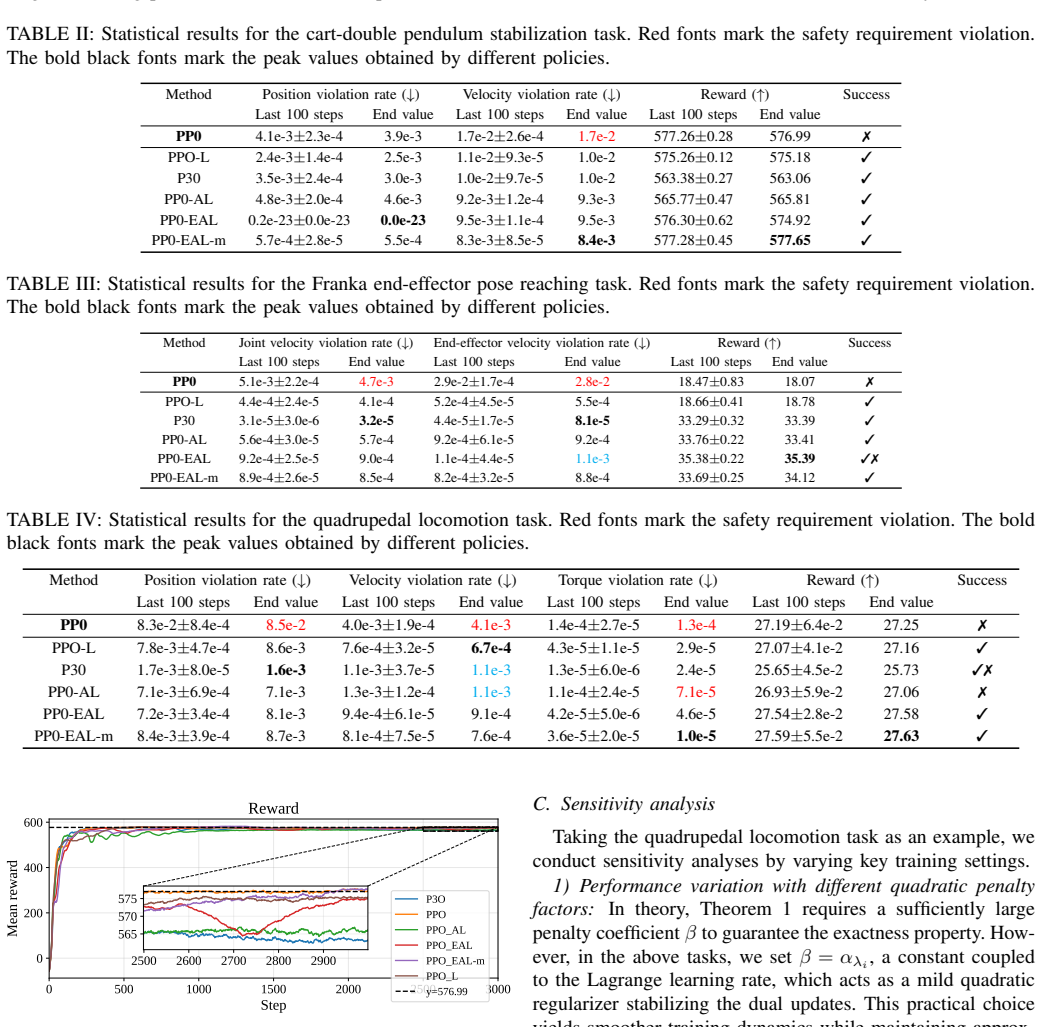
read the original abstract
Reinforcement learning (RL) has emerged as a promising solution to accomplish complex robotic control tasks; however, most of the current work ignores the safety requirements. Safe RL seeks to maximize task performance while satisfying explicit physical constraints, but current algorithms struggle to learn the policy efficiently with precise constraint satisfaction. This work proposes PPO-EAL, a novel first-order constrained policy optimization framework that integrates exact augmented Lagrangian optimization into proximal policy optimization for safe robotic control. By combining clipped policy updates with exact quadratic penalty terms, PPO-EAL achieves theoretically grounded constraint enforcement without requiring impractically large penalty factors. A momentum-regulated multiplier update further improves dual-variable stability, reducing constraint oscillation and unsafe behavior while preserving task performance. We provide exactness and convergence analysis under standard stochastic approximation assumptions. Extensive validation across diverse GPU-accelerated robotic benchmarks-including cart-pole balancing, cart-double-pendulum stabilization, 7-DoF Franka end-effector reaching, and quadrupedal locomotion-demonstrates superior safety precision and reward performance compared with state-of-the-art first-order safe RL baselines. Finally, we demonstrate zero-shot sim-to-real deployment in a contact-rich gear assembly task, where PPO-EAL substantially improves task success, reduces peak contact force, and enhances operational robustness. These results establish PPO-EAL as a general and practically deployable safe RL framework for diverse safety-critical robotic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PPO-EAL, a first-order constrained RL algorithm that augments proximal policy optimization with an exact augmented Lagrangian formulation and a momentum-regulated multiplier update. It claims theoretically grounded exact constraint satisfaction (without impractically large penalties) and convergence under standard stochastic approximation assumptions, plus superior empirical safety and task performance on GPU-accelerated robotic benchmarks (cart-pole, double-pendulum, Franka reaching, quadruped locomotion) and zero-shot sim-to-real transfer on a contact-rich gear assembly task.
Significance. If the exactness and convergence claims hold, the work would offer a practically deployable first-order safe RL method that avoids the tuning difficulties of large-penalty approaches while improving dual-variable stability; the extensive benchmark suite and sim-to-real demonstration would strengthen its relevance for safety-critical robotics.
major comments (1)
- [Theoretical Analysis / Convergence Proof] The exactness and convergence analysis (referenced in the abstract and presumably detailed in the theoretical section) invokes only 'standard stochastic approximation assumptions,' yet does not address the non-stationary state-action distribution induced by PPO's clipped surrogate and on-policy sampling; standard SA results typically require i.i.d. or fixed distributions, so the guarantee may not transfer to the algorithm as implemented.
Simulated Author's Rebuttal
We thank the referee for highlighting this important subtlety in the convergence analysis. We address the concern directly below.
read point-by-point responses
-
Referee: [Theoretical Analysis / Convergence Proof] The exactness and convergence analysis (referenced in the abstract and presumably detailed in the theoretical section) invokes only 'standard stochastic approximation assumptions,' yet does not address the non-stationary state-action distribution induced by PPO's clipped surrogate and on-policy sampling; standard SA results typically require i.i.d. or fixed distributions, so the guarantee may not transfer to the algorithm as implemented.
Authors: The referee correctly identifies that standard stochastic approximation (SA) theorems often assume i.i.d. samples or stationary distributions, while PPO-EAL employs on-policy sampling with a clipped surrogate that induces non-stationarity. Our analysis applies the SA framework to the augmented Lagrangian subproblems after each policy update, treating the multiplier and penalty updates as outer iterations; we implicitly rely on the fact that policy changes occur at a slower timescale than the inner gradient steps and that the Markov chain mixes sufficiently between updates. However, we did not explicitly state the additional regularity conditions (e.g., bounded policy drift or ergodicity under slowly varying policies) needed to justify transferring the SA guarantees. We will revise the theoretical section to include a dedicated remark clarifying these conditions and their relation to the clipped surrogate. revision: yes
Circularity Check
No significant circularity; convergence claims rest on external standard assumptions
full rationale
The provided abstract states that exactness and convergence analysis holds under standard stochastic approximation assumptions, which are external and not defined within the paper. No self-citations, fitted inputs renamed as predictions, or self-definitional steps are present in the text. The central claims about constraint enforcement and momentum-regulated updates do not reduce to the paper's own inputs by construction. This is the most common honest finding when the derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard stochastic approximation assumptions hold for the exactness and convergence analysis.
Reference graph
Works this paper leans on
-
[1]
R. S. Sutton and A. G. Barto,Reinforcement Learning: An Introduction, 2nd ed. Cambridge, MA: MIT Press, 2018
2018
-
[2]
Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning,
J. Luo, C. Xu, J. Wu, and S. Levine, “Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning,”Science Robotics, vol. 10, no. 105, p. eads5033, 2025
2025
-
[3]
On policy learning robust to irreversible events: An application to robotic in-hand manipu- lation,
P. Falco, A. Attawia, M. Saveriano, and D. Lee, “On policy learning robust to irreversible events: An application to robotic in-hand manipu- lation,”IEEE Robotics and Automation Letters, vol. 3, no. 3, pp. 1482– 1489, 2018
2018
-
[4]
Robot deformable object manipulation via nmpc-generated demonstrations in deep reinforcement learning,
H. Wang, Z. Dong, T. Zhu, H. Lei, W. Shi, Z. Zhang, W. Luo, W. Wan, X. Chen, and J. Huang, “Robot deformable object manipulation via nmpc-generated demonstrations in deep reinforcement learning,”IEEE Transactions on Automation Science and Engineering, vol. 22, pp. 23 566–23 578, 2025
2025
-
[5]
Real-world humanoid locomotion with reinforcement learning,
I. Radosavovic, T. Xiao, B. Zhang, T. Darrell, J. Malik, and K. Sreenath, “Real-world humanoid locomotion with reinforcement learning,”Sci- ence Robotics, vol. 9, no. 89, p. eadi9579, 2024
2024
-
[6]
Anymal parkour: Learning agile navigation for quadrupedal robots,
D. Hoeller, N. Rudin, D. Sako, and M. Hutter, “Anymal parkour: Learning agile navigation for quadrupedal robots,”Science Robotics, vol. 9, no. 88, p. eadi7566, 2024
2024
-
[7]
Curriculum-based reinforcement learning for quadrupedal jumping: A reference-free design,
V . Atanassov, J. Ding, J. Kober, I. Havoutis, and C. Della Santina, “Curriculum-based reinforcement learning for quadrupedal jumping: A reference-free design,”IEEE Robotics & Automation Magazine, vol. 32, no. 2, pp. 35–48, 2024
2024
-
[8]
Ex- plosive jumping with rigid and articulated soft quadrupeds via example guided reinforcement learning,
G. Apostolides, W. Pan, J. Kober, C. Della Santina, and J. Ding, “Ex- plosive jumping with rigid and articulated soft quadrupeds via example guided reinforcement learning,” inIEEE/RSJ International Conference on Intelligent Robots and Systems, 2025, pp. 18 903–18 910
2025
-
[9]
Curriculum-enhanced rein- forcement learning for robust humanoid locomotion,
Y . Zhou, J. Qiu, S. Jia, F. Ni, and W. Zhang, “Curriculum-enhanced rein- forcement learning for robust humanoid locomotion,”IEEE Transactions on Automation Science and Engineering, vol. 23, pp. 5779–5789, 2026
2026
-
[10]
Physics-informed multi-agent reinforcement learning for distributed multi-robot problems,
E. Sebasti ´an, T. Duong, N. Atanasov, E. Montijano, and C. Sag ¨u´es, “Physics-informed multi-agent reinforcement learning for distributed multi-robot problems,”IEEE Transactions on Robotics, vol. 41, pp. 4499–4517, 2025
2025
-
[11]
Multi-agent reinforcement learning for connected and automated vehicles control: Recent advancements and future prospects,
M. Hua, X. Qi, D. Chen, K. Jiang, Z. E. Liu, H. Sun, Q. Zhou, and H. Xu, “Multi-agent reinforcement learning for connected and automated vehicles control: Recent advancements and future prospects,” IEEE Transactions on Automation Science and Engineering, vol. 22, pp. 16 266–16 286, 2025
2025
-
[12]
Altman,Constrained Markov decision processes
E. Altman,Constrained Markov decision processes. Routledge, 2021
2021
-
[13]
Not only rewards but also constraints: Applications on legged robot locomotion,
Y . Kim, H. Oh, J. Lee, J. Choi, G. Ji, M. Jung, D. Youm, and J. Hwangbo, “Not only rewards but also constraints: Applications on legged robot locomotion,”IEEE Transactions on Robotics, vol. 40, pp. 2984–3003, 2024
2024
-
[14]
Constrained policy optimization,
J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained policy optimization,” inInternational conference on machine learning. PMLR, 2017, pp. 22–31
2017
-
[15]
Projection-based constrained policy optimization,
T.-Y . Yang, J. Rosca, K. Narasimhan, and P. J. Ramadge, “Projection-based constrained policy optimization,”arXiv preprint arXiv:2010.03152, 2020
-
[16]
Benchmarking Batch Deep Reinforcement Learning Algorithms
A. Ray, J. Achiam, and D. Amodei, “Benchmarking safe exploration in deep reinforcement learning,”arXiv preprint arXiv:1910.01708, vol. 7, no. 1, p. 2, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[17]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
First order constrained optimization in policy space,
Y . Zhang, Q. Vuong, and K. Ross, “First order constrained optimization in policy space,”Advances in Neural Information Processing Systems, vol. 33, pp. 15 338–15 349, 2020
2020
-
[19]
Reward Constrained Policy Optimization
C. Tessler, D. J. Mankowitz, and S. Mannor, “Reward constrained policy optimization,”arXiv preprint arXiv:1805.11074, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Con- strained reinforcement learning has zero duality gap,
S. Paternain, L. Chamon, M. Calvo-Fullana, and A. Ribeiro, “Con- strained reinforcement learning has zero duality gap,”Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[21]
Responsive safety in reinforce- ment learning by pid lagrangian methods,
A. Stooke, J. Achiam, and P. Abbeel, “Responsive safety in reinforce- ment learning by pid lagrangian methods,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 9133–9143
2020
-
[22]
Ipo: Interior-point policy optimization under constraints,
Y . Liu, J. Ding, and X. Liu, “Ipo: Interior-point policy optimization under constraints,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 04, 2020, pp. 4940–4947
2020
-
[23]
Penalty and barrier methods for constrained optimiza- tion,
R. M. Freund, “Penalty and barrier methods for constrained optimiza- tion,”Lecture Notes, Massachusetts Institute of Technology, 2004
2004
-
[24]
Penalized proximal policy optimization for safe reinforcement learn- ing,
L. Zhang, L. Shen, L. Yang, S. Chen, B. Yuan, X. Wang, and D. Tao, “Penalized proximal policy optimization for safe reinforcement learn- ing,”arXiv preprint arXiv:2205.11814, 2022
-
[25]
Exploring constrained reinforcement learning algorithms for quadrupedal locomotion,
J. Lee, L. Schroth, V . Klemm, M. Bjelonic, A. Reske, and M. Hut- ter, “Exploring constrained reinforcement learning algorithms for quadrupedal locomotion,” inIEEE/RSJ International Conference on Intelligent Robots and Systems, 2024, pp. 11 132–11 138
2024
-
[26]
Augmented proximal policy optimization for safe reinforcement learning,
J. Dai, J. Ji, L. Yang, Q. Zheng, and G. Pan, “Augmented proximal policy optimization for safe reinforcement learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 6, 2023, pp. 7288–7295
2023
-
[27]
Approximately optimal approximate rein- forcement learning,
S. Kakade and J. Langford, “Approximately optimal approximate rein- forcement learning,” inInternational conference on machine learning, 2002, pp. 267–274
2002
-
[28]
High- dimensional continuous control using generalized advantage estimation,
J. Schulman, P. Moritz, S. Levine, M. I. Jordan, and P. Abbeel, “High- dimensional continuous control using generalized advantage estimation,” International Conference on Learning Representations, 2015
2015
-
[29]
D. P. Bertsekas,Constrained optimization and Lagrange multiplier methods. Academic press, 2014
2014
-
[30]
Natural actor–critic algorithms,
S. Bhatnagar, R. S. Sutton, M. Ghavamzadeh, and M. Lee, “Natural actor–critic algorithms,”Automatica, vol. 45, no. 11, pp. 2471–2482, 2009
2009
-
[31]
Bhatnagar, H
S. Bhatnagar, H. Prasad, and L. Prashanth,Stochastic Recursive Algo- rithms for Optimization. Springer, 2013, vol. 434
2013
-
[32]
Risk- constrained reinforcement learning with percentile risk criteria,
Y . Chow, M. Ghavamzadeh, L. Janson, and M. Pavone, “Risk- constrained reinforcement learning with percentile risk criteria,”Journal of Machine Learning Research, vol. 18, no. 167, pp. 1–51, 2018
2018
-
[33]
Augmented lagrangians and applications of the proximal point algorithm in convex programming,
R. T. Rockafellar, “Augmented lagrangians and applications of the proximal point algorithm in convex programming,”Mathematics of operations research, vol. 1, no. 2, pp. 97–116, 1976
1976
-
[34]
Orbit: A unified simulation framework for interactive robot learning environments,
M. Mittal, C. Yu, Q. Yu, J. Liu, N. Rudin, D. Hoeller, J. L. Yuan, R. Singh, Y . Guo, H. Mazhar, A. Mandlekar, B. Babich, G. State, M. Hutter, and A. Garg, “Orbit: A unified simulation framework for interactive robot learning environments,”IEEE Robotics and Automation Letters, vol. 8, no. 6, pp. 3740–3747, 2023
2023
-
[35]
Isaac Sim
NVIDIA, “Isaac Sim.” [Online]. Available: https://github.com/isaac-sim/ IsaacSim
-
[36]
Rsl-rl: A learning library for robotics research,
C. Schwarke, M. Mittal, N. Rudin, D. Hoeller, and M. Hutter, “Rsl-rl: A learning library for robotics research,”arXiv preprint arXiv:2509.10771, 2025
-
[37]
The franka emika robot: A standard platform in robotics research [survey],
S. Haddadin, “The franka emika robot: A standard platform in robotics research [survey],”IEEE Robotics & Automation Magazine, vol. 31, no. 4, pp. 136–148, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.