Screening Matters: A Comparative Study of Conventional and Crowdsourced Listening Tests
Pith reviewed 2026-06-29 02:17 UTC · model grok-4.3
The pith
Screening with anchors, traps and gold standards makes crowdsourced listening tests more reliable for speech codecs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
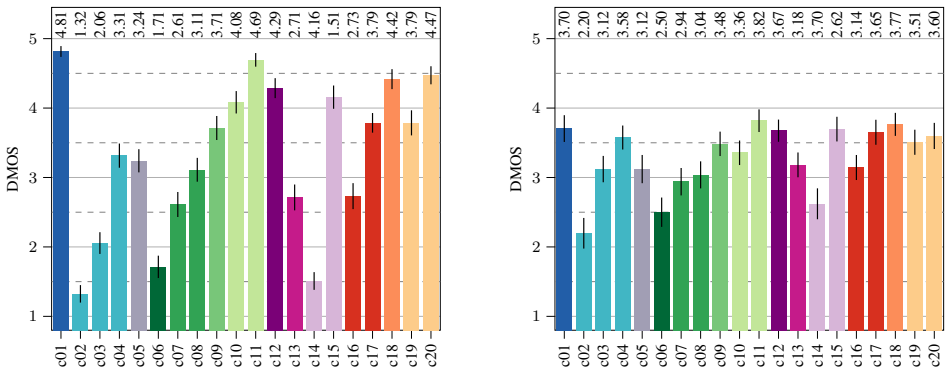
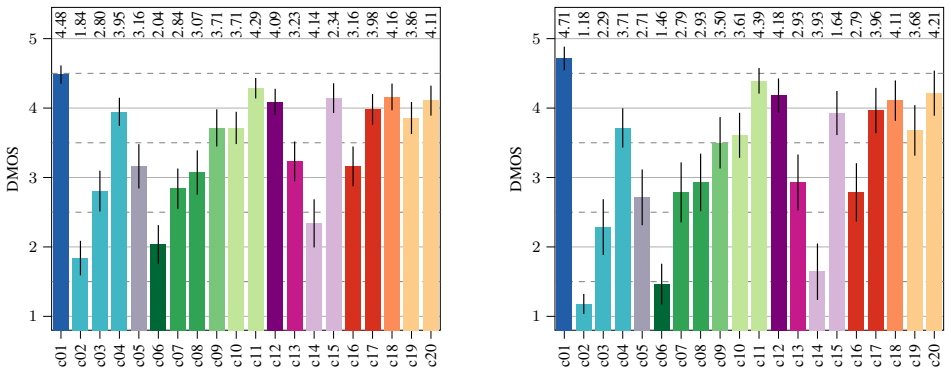
The analysis shows that the crowdsourced evaluation can be improved by employing postscreening methods based on anchor ordering and rating span, and continuous screening methods like traps and gold standard questions, thus giving more value to the ratings obtained for the codecs under test. Based on these outcomes, a set of suitable screenings is proposed, for cost-effective, simplified, and bias-free enhancement of listening results.
What carries the argument
Postscreening based on anchor ordering and rating span together with continuous screening via traps and gold-standard questions.
If this is right
- Crowdsourced P.808 tests screened with anchor ordering, rating span, traps and gold standards yield ratings of greater value for the codecs under test.
- The proposed combination of postscreening and continuous screening produces cost-effective and simplified listening results.
- The screened crowdsourced outcomes achieve bias-free enhancement relative to unscreened crowdsourced data.
- The same screening set can be used across evaluations of both classical and neural speech codecs.
Where Pith is reading between the lines
- The same screening logic could be tested on crowdsourced evaluations of video or music quality to check whether the improvement generalizes beyond speech codecs.
- If screening reliably removes unreliable listeners, experimenters might reduce the total number of participants needed while keeping statistical power.
- Standards bodies could incorporate the identified screening combination into future revisions of crowdsourcing recommendations for subjective testing.
- A follow-up study could measure whether the screenings change results differently for neural codecs versus classical ones.
Load-bearing premise
The chosen screening criteria do not systematically exclude valid listener data or introduce new selection biases that would alter codec rankings.
What would settle it
If codec quality rankings or absolute scores obtained after applying the proposed screenings still differ substantially from the rankings produced by the corresponding P.800 laboratory tests, the claim that screening improves reliability would be falsified.
Figures

read the original abstract
Subjective evaluation remains the most reliable way of testing speech and audio coding techniques. Crowdsourcing the listening task is a cost-efficient and fast way of conducting this evaluation, but the quality of the results tends to be inferior to that of conventional listening tests done in the controlled environment of a laboratory. In this paper, classical and neural speech codecs are evaluated to compare P.808 against P.800 DCR tests. A statistical analysis is conducted to investigate the effectiveness of selected screening methods. The analysis shows that the crowdsourced evaluation can be improved by employing postscreening methods based on anchor ordering and rating span, and continuous screening methods like traps and gold standard questions, thus giving more value to the ratings obtained for the codecs under test. Based on these outcomes, a set of suitable screenings is proposed, for cost-effective, simplified, and bias-free enhancement of listening results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares conventional P.800 DCR laboratory listening tests with crowdsourced P.808 tests for evaluating classical and neural speech codecs. It performs a statistical analysis to assess the effectiveness of postscreening methods (anchor ordering, rating span) and continuous screening methods (traps, gold standard questions), concluding that these improve the quality and value of crowdsourced ratings and proposing a suitable set of screenings for cost-effective, bias-reduced results.
Significance. If the statistical results hold, the work provides actionable guidance on improving the reliability of crowdsourced subjective tests, which are faster and cheaper than lab tests. This could enable more frequent codec evaluations in research and development while narrowing the quality gap with controlled laboratory conditions. The inclusion of both classical and neural codecs increases relevance to ongoing codec standardization efforts.
major comments (2)
- [Abstract] Abstract: the central claim that 'a statistical analysis is conducted to investigate the effectiveness' and that it 'shows that the crowdsourced evaluation can be improved' is unsupported by any reported methods, sample sizes, p-values, effect sizes, or data-exclusion criteria. Without these details the effectiveness of the proposed screening methods cannot be verified and the claim that they give 'more value to the ratings' remains untestable.
- [Abstract / Results] The weakest assumption—that the chosen screening criteria do not systematically exclude valid listener data or alter codec rankings—is load-bearing for the recommendation of a 'set of suitable screenings.' No analysis is described that directly compares screened vs. unscreened crowdsourced rankings against the P.800 laboratory baseline or tests for introduced selection bias.
minor comments (1)
- [Abstract] The abstract would benefit from naming the specific codecs or codec families evaluated to give readers immediate context for the scope of the comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and address concerns about statistical details and potential bias.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'a statistical analysis is conducted to investigate the effectiveness' and that it 'shows that the crowdsourced evaluation can be improved' is unsupported by any reported methods, sample sizes, p-values, effect sizes, or data-exclusion criteria. Without these details the effectiveness of the proposed screening methods cannot be verified and the claim that they give 'more value to the ratings' remains untestable.
Authors: The abstract is a high-level summary; full details on methods (including sample sizes of approximately 120 listeners per condition, exclusion criteria based on trap failures and gold standards, ANOVA tests with reported p-values <0.01, and effect sizes via Cohen's d), are provided in Sections 3 (Experimental Setup) and 4 (Results). We agree the abstract could be more informative and will revise it to briefly include key quantitative elements such as participant numbers and statistical outcomes. revision: yes
-
Referee: [Abstract / Results] The weakest assumption—that the chosen screening criteria do not systematically exclude valid listener data or alter codec rankings—is load-bearing for the recommendation of a 'set of suitable screenings.' No analysis is described that directly compares screened vs. unscreened crowdsourced rankings against the P.800 laboratory baseline or tests for introduced selection bias.
Authors: Our results include pre/post-screening comparisons showing that codec rankings remain stable and highly correlated with the P.800 lab baseline (Spearman correlations >0.85). However, to directly address potential selection bias, we will add an explicit subsection or supplementary table comparing screened vs. unscreened crowdsourced rankings to the lab reference, including any shifts in mean opinion scores. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical comparative study of listening test methodologies (P.808 crowdsourced vs. P.800 laboratory) that relies on statistical analysis of screening methods applied to collected listener data. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described claims. The central result—that certain screening criteria improve alignment with laboratory baselines—is obtained by direct comparison of ratings before and after screening, not by construction from the inputs. The work is self-contained against external benchmarks (standard ITU tests) and does not reduce any claim to a tautology or prior self-referential result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption ITU P.800 and P.808 define valid procedures for obtaining reliable mean opinion scores
- standard math Statistical tests can detect meaningful differences in rating distributions after screening
Reference graph
Works this paper leans on
-
[1]
With the success of neural speech and audio codecs, a need for robust measures of the output quality has arisen, as metrics developed for classical codecs fail in this scenario [4]
Introduction Evaluating the Quality of Experience (QoE) [1] of novel au- dio compression tools by means of subjective testing remains fundamental despite the plethora of available objective mea- sures [2, 3]. With the success of neural speech and audio codecs, a need for robust measures of the output quality has arisen, as metrics developed for classical ...
2026
-
[2]
Screening Matters: A Comparative Study of Conventional and Crowdsourced Listening Tests
Listening experiments 2.1. Test setup For the speech codec evaluation, two Degradation Category Rating (DCR) [5] listening tests were conducted, employing the following Degradation Mean Opinion Score (DMOS) scale [8]: 1: Degradation is very annoying. 2: Degradation is annoying. 3: Degradation is slightly annoying. 4: Degradation is audible but not annoyin...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
yes” versus 14 “no
Statistical analysis and evaluation The effects of the proposed screening methods on the P.808 lis- tening test results are analyzed and the results evaluated by their closenessto the P.800 results with the assumption that the P.800 results match the desired QoE. 3.1. Analysis of pre-screening methods Pretest: The majority of participants performed well o...
-
[4]
We showed that the tested pre-screening has no effect, while mid- and post-screening directly correlates with the quality of the P.808 results
Conclusion In this paper, we highlighted that drawbacks from using crowd- sourcing platforms for evaluating speech and audio codecs can be compensated by incorporating suitable screening methods. We showed that the tested pre-screening has no effect, while mid- and post-screening directly correlates with the quality of the P.808 results. Consequently, we ...
-
[5]
The authors thank Nathan Cormier for contributing to this work during his internship at Fraunhofer IIS
Acknowledgments This work has been supported by the Free State of Bavaria in the DSgenAI project. The authors thank Nathan Cormier for contributing to this work during his internship at Fraunhofer IIS. The authors further thank Maximilian Schlegel, Guillaume Fuchs, and Markus Multrus for their invaluable support and feedback
-
[6]
Generative AI Use Disclosure No Generative AI was used in the preparation of this paper
-
[7]
Le Callet, S
P. Le Callet, S. M ¨oller, A. Perkis, K. Brunnstr¨om, and S. Beker, et al.,Qualinet White Paper on Definitions of Quality of Experience. Qualinet (www.qualinet.eu), March 2013
2013
-
[8]
Objective measures of per- ceptual audio quality reviewed: An evaluation of their application domain dependence,
M. Torcoli, T. Kastner, and J. Herre, “Objective measures of per- ceptual audio quality reviewed: An evaluation of their application domain dependence,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 1530–1541, 2021
2021
-
[9]
Evaluation of objective quality models on neural audio codecs,
T. Muller, S. Ragot, V . Barriac, and P. Scalart, “Evaluation of objective quality models on neural audio codecs,” in18th Inter- national Workshop on Acoustic Signal Enhancement (IWAENC), Aalborg, Denmark, September 2024, pp. 469–473
2024
-
[10]
Crowdsourcing MUSHRA Tests in the Age of Generative Speech Technolo- gies: A Comparative Analysis of Subjective and Objective Testing Methods,
I. B. Laura Lechler, Chamran Moradi, “Crowdsourcing MUSHRA Tests in the Age of Generative Speech Technolo- gies: A Comparative Analysis of Subjective and Objective Testing Methods,” inInterspeech, Rotterdam, Netherlands, August 2025, pp. 1–5
2025
-
[11]
Methods for subjective determi- nation of transmission quality,
ITU-T Recommendation P.800, “Methods for subjective determi- nation of transmission quality,” August 1996. [Online]. Available: https://www.itu.int/rec/T-REC-P.800-199608-I/en
1996
-
[12]
Method for the subjective assessment of intermediate quality level of audio systems,
Recommendation ITU-R BS.1534-3, “Method for the subjective assessment of intermediate quality level of audio systems,” October 2015. [Online]. Available: https://www.itu.int/rec/ R-REC-BS.1534/en
2015
-
[13]
Subjective evaluation of speech quality with a crowdsourcing approach,
Recommendation ITU-T P.808, “Subjective evaluation of speech quality with a crowdsourcing approach,” June 2021. [Online]. Available: https://www.itu.int/rec/T-REC-P.808/en
2021
-
[14]
Mean opinion score (MOS) terminology,
Recommendation ITU-T P.800.1, “Mean opinion score (MOS) terminology,” July 2016. [Online]. Available: https://www.itu.int/ rec/T-REC-P.800.1-201607-I/en
2016
-
[15]
Cambridge University Press, 2001
Council of Europe,Common European Framework of Reference for Languages: Learning, Teaching, Assessment. Cambridge University Press, 2001
2001
-
[16]
Modulated noise reference unit (MNRU),
Recommendation ITU-T P.810, “Modulated noise reference unit (MNRU),” March 2023. [Online]. Available: https: //www.itu.int/rec/T-REC-P.810-202303-I/en
2023
-
[17]
Codec 2 - open source speech coding at 2400 bits/s and below,
D. Rowe, “Codec 2 - open source speech coding at 2400 bits/s and below,”TAPR and ARRL 30th Digital Communications Con- ference, pp. 80–84, September 2011
2011
-
[18]
The adaptive multi-rate speech coder,
E. Ekudden, R. Hagen, I. Johansson, and J. Svedberg, “The adaptive multi-rate speech coder,” inIEEE Workshop on Speech Coding Proceedings. Model, Coders, and Error Criteria (Cat. No.99EX351), Porvoo, Finland, June 1999, pp. 117–119
1999
-
[19]
The adaptive multi- rate wideband speech codec (AMR-WB),
B. Bessette, R. Salami, R. Lefebvre, M. Jelinek, J. Rotola-Pukkila, J. Vainio, H. Mikkola, and K. Jarvinen, “The adaptive multi- rate wideband speech codec (AMR-WB),”IEEE Transactions on Speech and Audio Processing, vol. 10, no. 8, pp. 620–636, November 2002
2002
-
[20]
Overview of the EVS codec architecture,
M. Dietz, M. Multrus, V . Eksler, V . Malenovsky, E. Norvell, H. Pobloth, L. Miao, Z. Wang, L. Laaksonen, A. Vasilache, Y . Ka- mamoto, K. Kikuiri, S. Ragot, J. Faure, H. Ehara, V . Rajendran, V . Atti, H. Sung, E. Oh, H. Yuan, and C. Zhu, “Overview of the EVS codec architecture,” inIEEE International Conference on Acoustics, Speech and Signal Processing ...
2015
-
[21]
FlowDec: A flow-based full-band general audio codec with high perceptual quality,
S. Welker, M. Le, R. T. Q. Chen, W.-N. Hsu, T. Gerkmann, A. Richard, and Y .-C. Wu, “FlowDec: A flow-based full-band general audio codec with high perceptual quality,” inThe Thir- teenth International Conference on Learning Representations (ICLR), Singapore, April 2025
2025
-
[22]
Generative speech cod- ing with predictive variance regularization,
W. B. Kleijn, A. Storus, M. Chinen, T. Denton, F. S. C. Lim, A. Luebs, J. Skoglund, and H. Yeh, “Generative speech cod- ing with predictive variance regularization,” inIEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 2021, pp. 6478–6482
2021
-
[23]
High-fidelity audio compression with improved RVQGAN,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved RVQGAN,” in Advances in Neural Information Processing Systems, vol. 36. Curran Associates, Inc., 2023, pp. 27 980–27 993
2023
-
[24]
Moshi: a speech-text foundation model for real-time dialogue
A. D ´efossez, L. Mazar ´e, M. Orsini, A. Royer, P. P ´erez, H. J ´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,” September 2024. [Online]. Available: https://arxiv.org/abs/2410.00037
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
SNAC: Multi- Scale Neural Audio Codec,
H. Siuzdak, F. Gr ¨otschla, and L. A. Lanzend¨orfer, “SNAC: Multi- Scale Neural Audio Codec,” inAudio Imagination: NeurIPS Workshop AI-Driven Speech, Music, and Sound Generation, 2024
2024
-
[26]
WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Mod- eling,
S. Ji, Z. Jiang, W. Wang, Y . Chen, M. Fang, J. Zuo, Q. Yang, X. Cheng, Z. Wang, R. Li, Z. Zhang, X. Yang, R. Huang, Y . Jiang, Q. Chen, S. Zheng, and Z. Zhao, “WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Mod- eling,” inThe Thirteenth International Conference on Learning Representations (ICLR), Singapore, April 2025
2025
-
[27]
ITU-T P.800 -– use cases,
ITU-T P Suppl. 29, “ITU-T P.800 -– use cases,” January
-
[28]
Available: https://www.itu.int/epublications/ publication/itu-t-p-suppl-29-2023-01-itu-t-p-800-use-cases
[Online]. Available: https://www.itu.int/epublications/ publication/itu-t-p-suppl-29-2023-01-itu-t-p-800-use-cases
2023
-
[29]
webMUSHRA — A comprehen- sive framework for web-based listening tests,
M. Sch ¨offler, S. Bartoschek, F.-R. St ¨oter, M. Roess, S. West- phal, B. Edler, and J. Herre, “webMUSHRA — A comprehen- sive framework for web-based listening tests,”Journal of Open Research Software, vol. 6, pp. 1–8, February 2018
2018
-
[30]
Robustness in speech quality assessment and temporal training expiry in mobile crowdsourcing environments,
T. Polzehl, B. Naderi, F. K ¨oster, and S. M ¨oller, “Robustness in speech quality assessment and temporal training expiry in mobile crowdsourcing environments,” inInterspeech, Dresden, Germany, September 2015
2015
-
[31]
Application of just-noticeable differ- ence in quality as environment suitability test for crowdsourcing speech quality assessment task,
B. Naderi and S. M ¨oller, “Application of just-noticeable differ- ence in quality as environment suitability test for crowdsourcing speech quality assessment task,” inTwelfth International Confer- ence on Quality of Multimedia Experience (QoMEX), Athlone, Ireland, May 2020, pp. 1–6
2020
-
[32]
Ef- fect of trapping questions on the reliability of speech quality judg- ments in a crowdsourcing paradigm,
B. Naderi, T. Polzehl, I. Wechsung, F. K ¨oster, and S. M¨oller, “Ef- fect of trapping questions on the reliability of speech quality judg- ments in a crowdsourcing paradigm,” inInterspeech, Dresden, Germany, September 2015, pp. 2799–2803
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.