Memory Shot for Long-Term Dialogue
Pith reviewed 2026-06-30 11:38 UTC · model grok-4.3
The pith
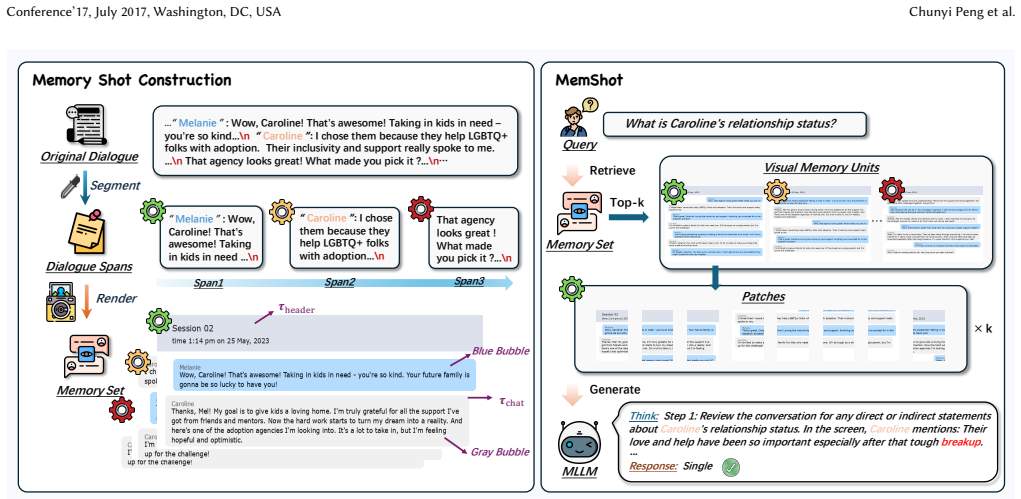
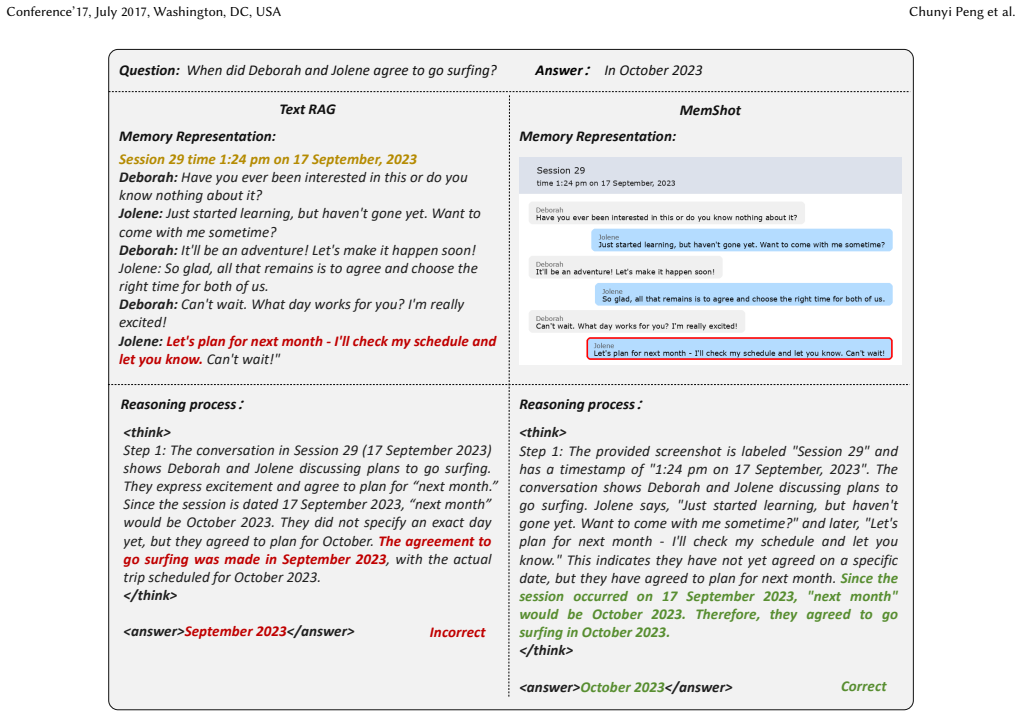
MemShot renders local dialogue spans as visual units so models can link episodes across sessions using internal visual reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MemShot renders local contiguous dialogue spans into structured visual memory units, preserving meta-information such as speaker transitions and turn boundaries, and relies on the model's internal visual reasoning capabilities to associate key episodes across sessions, avoiding the computational overhead of text-centered memory construction.
What carries the argument
Structured visual memory units created by rendering local contiguous dialogue spans, which carry chronological order and speaker meta-information for visual reasoning.
If this is right
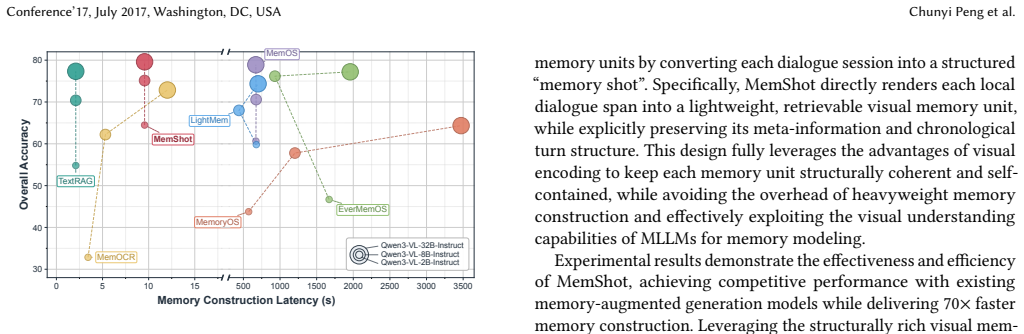
- MemShot matches prior methods on accuracy for LoCoMo and LongMemEval while shortening the memory pipeline.
- It produces a 70 times speedup in memory construction.
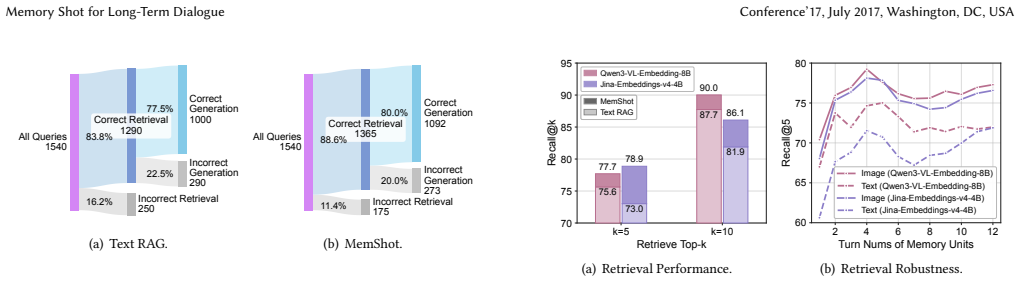
- Memory search shifts from surface lexical matching in flat text to structured local dialogue cues.
- Speaker transitions and turn boundaries remain available inside each memory unit.
Where Pith is reading between the lines
- The same visual-unit approach could be tested on sequential tasks outside dialogue, such as long document chains.
- Performance may vary on models whose visual training is weaker than the ones evaluated here.
- Adding color or layout variations to the visual renders might further strengthen episode separation.
Load-bearing premise
That the model's visual reasoning will reliably connect key episodes when presented with rendered visual dialogue units that retain speaker and turn structure.
What would settle it
A benchmark dataset of long dialogues with many cross-session references where the visual memory method retrieves fewer correct historical episodes than a text-based baseline.
Figures







read the original abstract
Large Language Models (LLMs) have demonstrated strong capabilities in general conversation, instruction following, and complex reasoning. However, in long-term dialogue settings, they often struggle to locate and utilize historical information most relevant to the current query. Existing approaches address this issue by constructing structured text-centered memory units through compressing and reorganizing user interaction history. However, these systems often rely on brute-force extraction of crucial evidence to associate episodes across dialogue sessions, causing substantial computational overhead and weakening structural cues such as speaker transitions, turn boundaries, and local contextual relationships. To avoid fragile text-based memory representations, we propose MemShot, which leverages dialogue structuring for long-term dialogue modeling and relies on the model's internal visual reasoning capabilities to associate key episodes. Specifically, MemShot renders local contiguous dialogue spans into structured visual memory units, preserving meta-information and chronological dialogue turns while avoiding heavy-weight textual memory construction. Experimental results show that MemShot achieves stable and competitive performance on both LoCoMo and LongMemEval, while substantially shortening the memory construction pipeline and delivering 70$\times$ speedup. Further analysis reveals that MemShot enhances the localization and utilization of historical evidence by directing memory processing toward structured local dialogue cues rather than surface-level lexical matching in a flat text stream. All codes are released on https://github.com/NEUIR/MemShot.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemShot, a method for long-term dialogue that renders local contiguous dialogue spans into structured visual memory units. This leverages the LLM's internal visual reasoning to associate key episodes across sessions while preserving meta-information such as speaker transitions and turn boundaries. It claims to avoid the computational overhead of brute-force text extraction in prior structured memory approaches, achieving competitive results on the LoCoMo and LongMemEval benchmarks along with a 70× speedup in the memory construction pipeline. Code is released at the provided GitHub link.
Significance. If the empirical results hold, the work demonstrates a practical efficiency gain for memory-augmented long-term dialogue systems by shifting from text-centric to visual memory representations. The approach preserves structural dialogue cues that text compression often weakens and supplies reproducible code, which strengthens its utility for follow-on research in dialogue modeling.
major comments (1)
- The experimental claims of stable competitive performance rest on benchmark results whose presentation omits error bars, ablation studies isolating the visual reasoning component, and basic dataset statistics for LoCoMo and LongMemEval; these omissions make it difficult to assess whether the reported gains are robust or attributable to the proposed visual memory mechanism rather than other pipeline choices.
minor comments (2)
- The abstract states that MemShot 'directs memory processing toward structured local dialogue cues rather than surface-level lexical matching'; a brief concrete example of this distinction in the main text would clarify the claimed advantage over prior text-based methods.
- The phrase 'All codes are released' should be revised to 'The code is released' for grammatical consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: The experimental claims of stable competitive performance rest on benchmark results whose presentation omits error bars, ablation studies isolating the visual reasoning component, and basic dataset statistics for LoCoMo and LongMemEval; these omissions make it difficult to assess whether the reported gains are robust or attributable to the proposed visual memory mechanism rather than other pipeline choices.
Authors: We agree that the original presentation omitted these elements. In the revision we will add basic dataset statistics for LoCoMo and LongMemEval. We will also report error bars (standard deviation across repeated runs) to support the claim of stable performance. Our existing comparisons against text-centered structured memory baselines already isolate the contribution of the visual representation; a dedicated ablation study focused solely on the visual reasoning component would require new experiments that exceed the scope of a minor revision, but we can expand the discussion of the existing comparisons if space allows. These additions will strengthen the manuscript without changing the core claims or the reported 70× speedup. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper introduces MemShot as an empirical method that renders local dialogue spans into structured visual memory units to leverage LLM visual reasoning for episode association, with claims resting on benchmark results (LoCoMo, LongMemEval) and measured 70× speedup from pipeline shortening. No equations, fitted parameters, predictions, or derivation chain exist that could reduce to self-defined inputs or self-citations. The approach is presented directly via implementation details and experimental protocols without invoking load-bearing self-citations, uniqueness theorems, or ansatzes; the central performance claims are externally falsifiable via the released code and benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs have internal visual reasoning capabilities sufficient to associate key episodes from rendered dialogue images
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.ArXiv preprintabs/2511.21631 (2025). https://arxiv.org/abs/ 2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [2]
- [3]
-
[4]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Ya- dav. 2025. Mem0: Building production-ready ai agents with scalable long-term memory.ArXiv preprintabs/2504.19413 (2025). https://arxiv.org/abs/2504.19413
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Yiming Du, Wenyu Huang, Danna Zheng, Zhaowei Wang, Sebastien Montella, Mirella Lapata, Kam-Fai Wong, and Jeff Z Pan. 2025. Rethinking Memory in LLM based Agents: Representations, Operations, and Emerging Topics.ArXiv preprint abs/2505.00675 (2025). https://arxiv.org/abs/2505.00675
-
[6]
Sinan Fan, Liang Xie, Chen Shen, Ge Teng, Xiaosong Yuan, Xiaofeng Zhang, Chenxi Huang, Wenxiao Wang, Xiaofei He, and Jieping Ye. 2025. Improving complex reasoning with dynamic prompt corruption: A soft prompt optimization approach.ArXiv preprintabs/2503.13208 (2025). https://arxiv.org/abs/2503.13208
-
[7]
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, et al . 2025. Light- mem: Lightweight and efficient memory-augmented generation.ArXiv preprint abs/2510.18866 (2025). https://arxiv.org/abs/2510.18866
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Michael Günther, Saba Sturua, Mohammad Kalim Akram, Isabelle Mohr, An- drei Ungureanu, Bo Wang, Sedigheh Eslami, Scott Martens, Maximilian Werk, Nan Wang, et al. 2025. jina-embeddings-v4: Universal embeddings for multi- modal multilingual retrieval. InProceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025). 531–550
2025
-
[9]
Helia Hashemi, Jason Eisner, Corby Rosset, Benjamin Van Durme, and Chris Kedzie. 2024. Llm-rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 13806– 13834
2024
-
[10]
Demis Hassabis and Eleanor A Maguire. 2007. Deconstructing episodic memory with construction.Trends in cognitive sciences11, 7 (2007), 299–306
2007
-
[11]
Chuanrui Hu, Xingze Gao, Zuyi Zhou, Dannong Xu, Yi Bai, Xintong Li, Hui Zhang, Tong Li, Chong Zhang, Lidong Bing, et al . 2026. EverMemOS: A Self- Organizing Memory Operating System for Structured Long-Horizon Reasoning. ArXiv preprintabs/2601.02163 (2026). https://arxiv.org/abs/2601.02163
-
[12]
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, et al. 2025. Memory in the age of ai agents.ArXiv preprintabs/2512.13564 (2025). https://arxiv.org/abs/ 2512.13564
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Dongming Jiang, Yi Li, Songtao Wei, Jinxin Yang, Ayushi Kishore, Alysa Zhao, Dingyi Kang, Xu Hu, Feng Chen, Qiannan Li, et al. 2026. Anatomy of Agentic Memory: Taxonomy and Empirical Analysis of Evaluation and System Limita- tions.ArXiv preprintabs/2602.19320 (2026). https://arxiv.org/abs/2602.19320
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. 2025. Memory os of ai agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 25972–25981
2025
-
[15]
Patrick AF Laing and Joseph E Dunsmoor. 2025. Event segmentation promotes the reorganization of emotional memory.Journal of Cognitive Neuroscience37, 1 (2025), 110–134
2025
-
[16]
Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural In- formation Processing Systems 33: Annual Conference on Neural Inf...
2020
-
[17]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, et al . 2026. Qwen3-VL- Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the- Art Multimodal Retrieval and Ranking.ArXiv preprintabs/2601.04720 (2026). https://arxiv.org/abs/2601.04720
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Yanhong Li, Zixuan Lan, and Jiawei Zhou. 2025. Text or Pixels? Evaluating Efficiency and Understanding of LLMs with Visual Text Inputs. InFindings of the Association for Computational Linguistics: EMNLP 2025. 10564–10578
2025
-
[19]
Zhiyu Li, Chenyang Xi, Chunyu Li, Ding Chen, Boyu Chen, Shichao Song, Simin Niu, Hanyu Wang, Jiawei Yang, Chen Tang, et al. 2025. Memos: A memory os for ai system.ArXiv preprintabs/2507.03724 (2025). https://arxiv.org/abs/2507.03724
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [20]
-
[21]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173. doi:10.1162/tacl_a_00638
-
[22]
Zhenghao Liu, Pengcheng Huang, Zhipeng Xu, Xinze Li, Shuliang Liu, Chunyi Peng, Haidong Xin, Yukun Yan, Shuo Wang, Xu Han, et al . 2026. Knowledge intensive agents.AI Open(2026)
2026
- [23]
-
[24]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating very long-term conversational mem- ory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 13851–13870
2024
-
[25]
Yufan Mao, Hanjing Ye, Wenlong Dong, Chengjie Zhang, and Hong Zhang. 2025. Meta-Memory: Retrieving and Integrating Semantic-Spatial Memories for Robot Conference’17, July 2017, Washington, DC, USA Chunyi Peng et al. Spatial Reasoning.ArXiv preprintabs/2509.20754 (2025). https://arxiv.org/abs/ 2509.20754
-
[26]
Sophie Nolden, Gözem Turan, Berna Güler, and Eren Günseli. 2024. Prediction error and event segmentation in episodic memory.Neuroscience & Biobehavioral Reviews157 (2024), 105533
2024
-
[27]
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. 2023. MemGPT: towards LLMs as operating systems. (2023)
2023
-
[28]
Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. In-Context Retrieval-Augmented Lan- guage Models.Transactions of the Association for Computational Linguistics11 (2023), 1316–1331. doi:10.1162/tacl_a_00605
-
[29]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: a temporal knowledge graph architecture for agent memory. ArXiv preprintabs/2501.13956 (2025). https://arxiv.org/abs/2501.13956
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
2026.Seed 2.0 Model Card: Towards Intelligence Frontier for Real- World Complexity
ByteDance Seed. 2026.Seed 2.0 Model Card: Towards Intelligence Frontier for Real- World Complexity. Technical Report. Technical report (model card), February
2026
-
[31]
URL https://lf3-static
-
[32]
Yaorui Shi, Shugui Liu, Yu Yang, Wenyu Mao, Yuxin Chen, Qi Gu, Hui Su, Xunliang Cai, Xiang Wang, and An Zhang. 2026. MemOCR: Layout-Aware Visual Memory for Efficient Long-Horizon Reasoning.ArXiv preprintabs/2601.21468 (2026). https://arxiv.org/abs/2601.21468
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, et al. 2025. In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 8416–8439
2025
-
[34]
Alex Jinpeng Wang, Linjie Li, Yiqi Lin, Min Li, Lijuan Wang, and Mike Zheng Shou. 2024. Leveraging Visual Tokens for Extended Text Contexts in Multi- Modal Learning. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, Amir Glob...
2024
-
[35]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. 2025. Internvl3. 5: Ad- vancing open-source multimodal models in versatility, reasoning, and efficiency. ArXiv preprintabs/2508.18265 (2025). https://arxiv.org/abs/2508.18265
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Xindi Wang, Mahsa Salmani, Parsa Omidi, Xiangyu Ren, Mehdi Rezagholizadeh, and Armaghan Eshaghi. 2024. Beyond the Limits: A Survey of Techniques to Extend the Context Length in Large Language Models. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI 2024, Jeju, South Korea, August 3-9, 2024. ijcai.org, 8299...
2024
-
[37]
Haoran Wei, Yaofeng Sun, and Yukun Li. 2025. Deepseek-ocr: Contexts optical compression.ArXiv preprintabs/2510.18234 (2025). https://arxiv.org/abs/2510. 18234
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompt- ing Elicits Reasoning in Large Language Models. InAdvances in Neural Infor- mation Processing Systems 35: Annual Conference on Neural Information Pro- cessing Systems 2022, NeurIPS 2022, New Orleans, LA, USA,...
2022
-
[39]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. 2024. Longmemeval: Benchmarking chat assistants on long-term interactive memory.ArXiv preprintabs/2410.10813 (2024). https://arxiv.org/abs/2410.10813
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [40]
-
[41]
Haidong Xin, Xinze Li, Zhenghao Liu, Yukun Yan, Shuo Wang, Cheng Yang, Yu Gu, Ge Yu, and Maosong Sun. 2026. MetaMem: Evolving Meta-Memory for Knowledge Utilization through Self-Reflective Symbolic Optimization.ArXiv preprintabs/2602.11182 (2026). https://arxiv.org/abs/2602.11182
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang
-
[43]
A-MEM: Agentic Memory for LLM Agents
A-mem: Agentic memory for llm agents.ArXiv preprintabs/2502.12110 (2025). https://arxiv.org/abs/2502.12110
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.ArXiv preprintabs/2505.09388 (2025). https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wenshuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, et al. 2025. Minicpm-v 4.5: Cooking efficient mllms via architecture, data, and training recipe.ArXiv preprintabs/2509.18154 (2025). https://arxiv.org/abs/2509.18154
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Peter Zeidman, Sinéad L Mullally, and Eleanor A Maguire. 2015. Construct- ing, perceiving, and maintaining scenes: hippocampal activity and connectivity. Cerebral Cortex25, 10 (2015), 3836–3855
2015
-
[47]
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chengxing Xie, Cunxiang Wang, et al. 2026. GLM-5: from Vibe Coding to Agentic Engineering.ArXiv preprintabs/2602.15763 (2026). https: //arxiv.org/abs/2602.15763
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. Memo- ryBank: Enhancing Large Language Models with Long-Term Memory. InThirty- Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Con- ference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artific...
-
[49]
Zihan Zhou, Chong Li, Xinyi Chen, Shuo Wang, Yu Chao, Zhili Li, Haoyu Wang, Qi Shi, Zhixing Tan, Xu Han, et al. 2025. LLM × MapReduce: Simplified Long- Sequence Processing using Large Language Models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 27664–27678. Memory Shot for Long-Term Di...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.