HyperSU: Corpus-Driven Semantic-Unit Hypergraph for Retrieval-Augmented Generation
Pith reviewed 2026-06-30 11:21 UTC · model grok-4.3
The pith
HyperSU constructs hyperedges via entity-aware minimum-description-length optimization on semantic units to ground retrieval-augmented generation in source text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
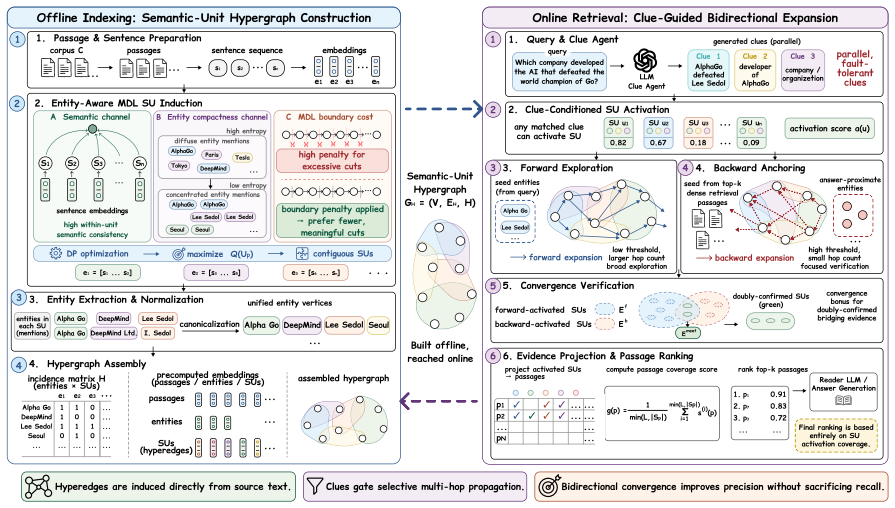
HyperSU models each semantic unit as a hyperedge over its co-mentioned entities after solving an entity-aware minimum-description-length optimization that produces source-grounded hyperedges; it then performs clue-guided bidirectional expansion over the hypergraph so that retrieval discovers multi-hop evidence while the clue limits propagation through hub nodes.
What carries the argument
Entity-aware minimum-description-length optimization that induces semantic-unit hyperedges over co-mentioned entities.
If this is right
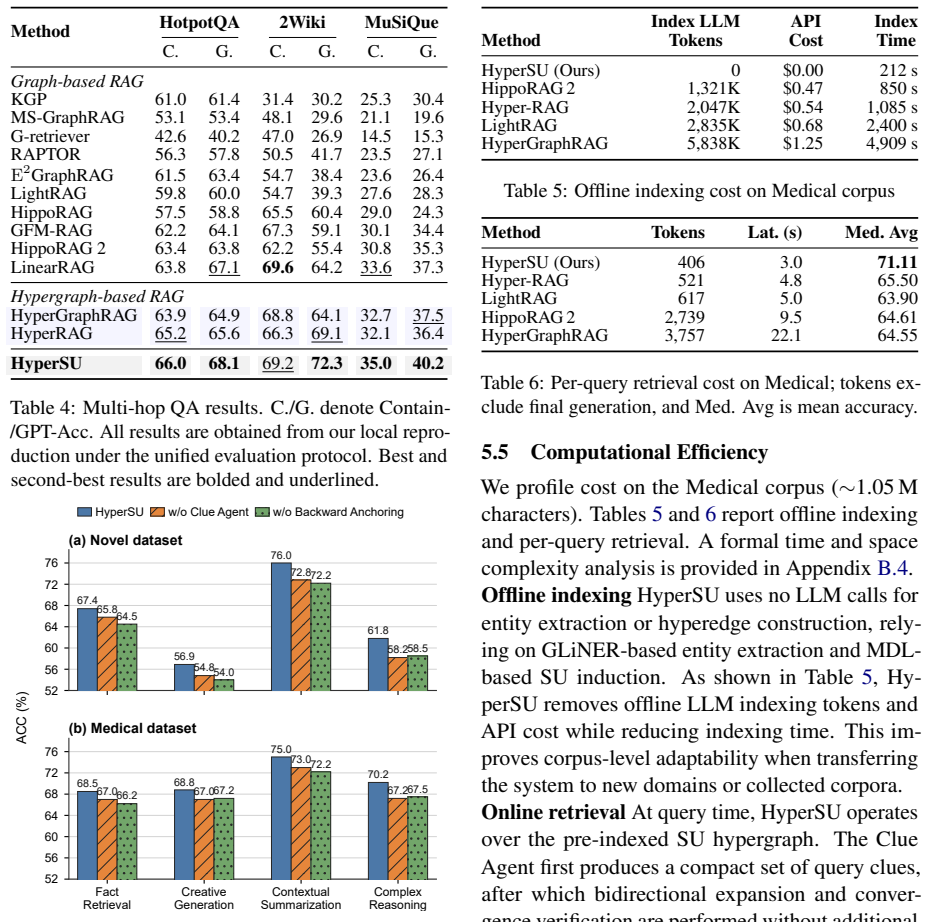
- Answer accuracy rises by up to 14.7 percent relative to prior graph and hypergraph RAG baselines on GraphRAG-Bench.
- Gains are larger on reasoning-intensive tasks that require chaining multiple pieces of evidence.
- Indexing cost drops because hyperedges are derived directly from the corpus rather than from separate LLM calls.
- Bidirectional expansion captures multi-hop evidence without the semantic drift that occurs under uncontrolled PageRank diffusion.
Where Pith is reading between the lines
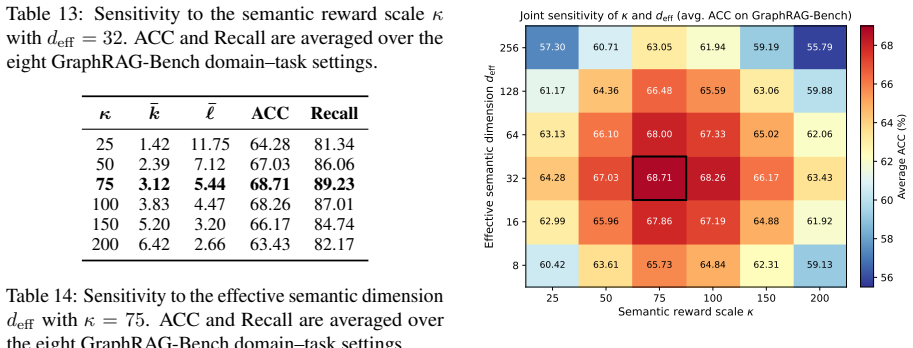
- The same MDL-driven construction could be tested on corpora outside the evaluated benchmarks to check whether the coherence-compactness tradeoff holds at larger scale.
- If the method generalizes, RAG pipelines could shift from generative indexing to purely corpus-driven structuring, lowering dependence on LLM calls during setup.
- The bidirectional clue mechanism suggests a general pattern for controlling diffusion in any hypergraph retrieval setting where hub nodes are common.
Load-bearing premise
The entity-aware minimum-description-length optimization produces hyperedges that are both more reliable and cheaper than LLM-generated summaries while preserving semantic coherence.
What would settle it
A controlled experiment in which replacing the MDL step with standard LLM summarization for hyperedge construction yields equal or higher accuracy on the same reasoning-intensive benchmarks.
Figures


read the original abstract
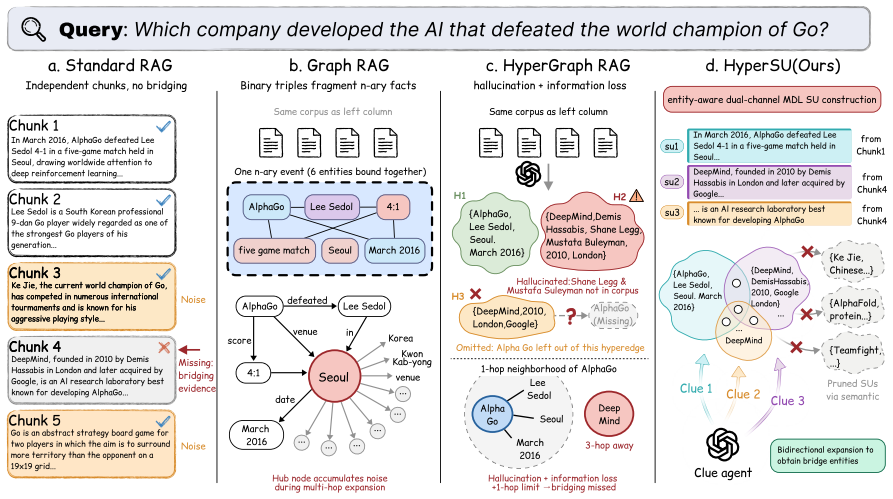
Recent Hypergraph-based retrieval-augmented generation (HyperRAG) methods use hyperedges to connect multiple entities simultaneously, enabling more efficient multi-entity evidence organization than pairwise graph structures. However, existing HyperRAG methods often rely on LLM-generated summaries to construct hyperedges, which can introduce hallucinations while also incurring high indexing costs. In addition, during retrieval, existing methods typically rely on either one-hop neighbor expansion or PageRank diffusion. The former may miss useful multi-hop evidence, while the latter can suffer from uncontrolled propagation over excessive hub nodes, leading to semantic drift and noisy reasoning chains. To address these challenges, we propose HyperSU, a novel hypergraph-based RAG framework featuring semantic-unit hyperedges and clue-guided bidirectional retrieval. During construction, HyperSU formulates hyperedge construction as an entity-aware minimum-description-length (MDL) optimization problem, inducing source-grounded semantic-unit hyperedges that balance sentence-level semantic coherence and entity compactness. It then constructs a hypergraph by modeling each semantic unit as a hyperedge over its co-mentioned entities. During retrieval, HyperSU performs clue-guided bidirectional expansion over the semantic-unit hypergraph, enabling both multi-hop evidence discovery and answer-aware noise reduction. Experiments show that HyperSU consistently improves answer accuracy over standard, graph-based, and hypergraph-based RAG baselines, achieving up to a 14.7% relative accuracy improvement on GraphRAG-Bench, with larger gains on reasoning-intensive tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HyperSU, a hypergraph-based RAG framework that formulates hyperedge construction as an entity-aware minimum-description-length (MDL) optimization problem to induce source-grounded semantic-unit hyperedges, then performs clue-guided bidirectional expansion during retrieval. It claims consistent answer accuracy improvements over standard, graph-based, and hypergraph-based RAG baselines, with up to 14.7% relative improvement on GraphRAG-Bench and larger gains on reasoning-intensive tasks.
Significance. If the central claims hold, the work offers a corpus-driven alternative to LLM-generated hyperedges that could reduce hallucinations and indexing costs while improving multi-hop evidence organization. The bidirectional retrieval mechanism addresses documented limitations of one-hop expansion and PageRank diffusion. The explicit MDL formulation is a technical contribution that merits evaluation.
major comments (2)
- [Experiments] Experiments section: The reported results compare only end-to-end answer accuracy against baselines. No ablation is described that replaces the entity-aware MDL hyperedge construction with LLM-generated summaries, leaving the claim that MDL yields more reliable and cheaper hyperedges unsubstantiated by direct evidence.
- [Construction] Hyperedge construction section: No separate metrics (indexing time, entity-consistency hallucination rate, or coherence scores) are provided for the MDL optimization step itself, which is load-bearing for the abstract's positioning against LLM summaries.
minor comments (1)
- [Abstract] Abstract: The accuracy claims would be easier to assess if the number of datasets, exact baselines, and any statistical significance tests were stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The comments highlight important aspects of experimental validation for the MDL-based construction claims. We respond point by point below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The reported results compare only end-to-end answer accuracy against baselines. No ablation is described that replaces the entity-aware MDL hyperedge construction with LLM-generated summaries, leaving the claim that MDL yields more reliable and cheaper hyperedges unsubstantiated by direct evidence.
Authors: We agree that the current results provide only indirect support via end-to-end gains over hypergraph baselines (which rely on LLM-generated hyperedges). A direct ablation replacing the MDL step with LLM-generated summaries would more conclusively substantiate the reliability and cost claims. In the revision we will add this ablation, reporting accuracy deltas together with any available indexing-cost measurements. revision: yes
-
Referee: [Construction] Hyperedge construction section: No separate metrics (indexing time, entity-consistency hallucination rate, or coherence scores) are provided for the MDL optimization step itself, which is load-bearing for the abstract's positioning against LLM summaries.
Authors: The referee is correct that isolated metrics for the MDL construction step are absent. While overall system accuracy is reported, dedicated measurements of indexing time, hallucination rate, and coherence would strengthen the positioning against LLM summaries. We will add a dedicated subsection or table with these metrics (including feasible comparisons to LLM baselines) in the revised manuscript. revision: yes
Circularity Check
No circularity: derivation is self-contained against external benchmarks
full rationale
The paper defines HyperSU via standard MDL optimization applied to corpus sentences for hyperedge construction, followed by clue-guided bidirectional retrieval on the resulting hypergraph. Accuracy gains are measured via end-to-end comparisons to independent baselines on GraphRAG-Bench; no equation or step reduces a claimed prediction to a fitted input by construction, and no load-bearing premise rests on self-citation chains. The MDL step is an external information-theoretic method whose output (hyperedges) is then evaluated separately from the final RAG metric.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RAPTOR: Recursive abstractive processing for tree-organized retrieval. InThe Twelfth Interna- tional Conference on Learning Representations. Gideon Schwarz. 1978. Estimating the dimension of a model.The Annals of Statistics, 6(2):461–464. Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. Musique: Multi- hop questions via si...
-
[5]
Dance in the
950: Bernardo Bertolucci 16 March 1941–26 November 2018 was an Italian director and screenwriter... ×Not specified Finds the film page but diffuses through the broad film-director neighborhood. HyperGraphRAG Local generated hyperedges can capture the film–director association, but the death-place evidence is in a separate biography chunk. Top-5 retrieved ...
1941
-
[8]
4050: Ernst Ingmar Bergman 14 July 1918–30 July 2007 was a Swedish director, writer, and producer
1918
-
[9]
Dance in the
4931: Barry Levinson born April 6, 1942 is an American filmmaker, screenwriter, and actor... ×No answer evidence Local hyperedges preserve the bridge name but do not reliably compose to the answer-bearing biography. Hyper-RAG Diffusion keeps evidence around films and directors, but does not surface Chunk 578. Top-5 retrieved chunks: [1]577: Ples v dežju i...
1942
-
[10]
5489: Roman Pola ´nski born 18 August 1933 in Paris; original name Raymond Thierry Liebling is a French-Polish film director, producer
1933
-
[12]
950: Bernardo Bertolucci 16 March 1941–26 November 2018 was an Italian director and screenwriter
1941
-
[13]
Dance in the
4050: Ernst Ingmar Bergman 14 July 1918–30 July 2007 was a Swedish director, writer, and producer... ×No answer evidence The signal remains in a topical director region instead of converging on the specific Hladnik page. HyperSU Ranks both supporting chunks in the top context: Chunk 577 identifies Boštjan Hladnik as the director, and Chunk 578 states that...
1918
-
[14]
579: Dancing in the Rain may refer to:
-
[15]
4931: Barry Levinson born April 6, 1942 is an American filmmaker, screenwriter, and actor
1942
-
[16]
died in Ljubljana
950: Bernardo Bertolucci 16 March 1941–26 November 2018 was an Italian director and screenwriter... √ Ljubljana Forward and backward activation meet on the bridge entity and promote both supporting chunks. film page to the biography page of its director. Table 17 compares HyperSU with representative RAG baselines. The baselines either retrieve only partia...
1941
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.