Human-in-the-Loop Nugget Annotation for Accountable LLM-as-a-Judge Evaluations
Pith reviewed 2026-06-30 08:20 UTC · model grok-4.3
The pith
Humans identify what information matters as nuggets while LLMs match them to outputs in a new evaluation workflow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a prototype annotation tool achieves accountable LLM-as-a-judge evaluations by having humans identify nuggets of important information and LLMs perform high-volume matching of those nuggets to system outputs, thereby playing to each party's strengths while preserving genuine human oversight rather than producing rubber-stamping or unsupported high-variance labels.
What carries the argument
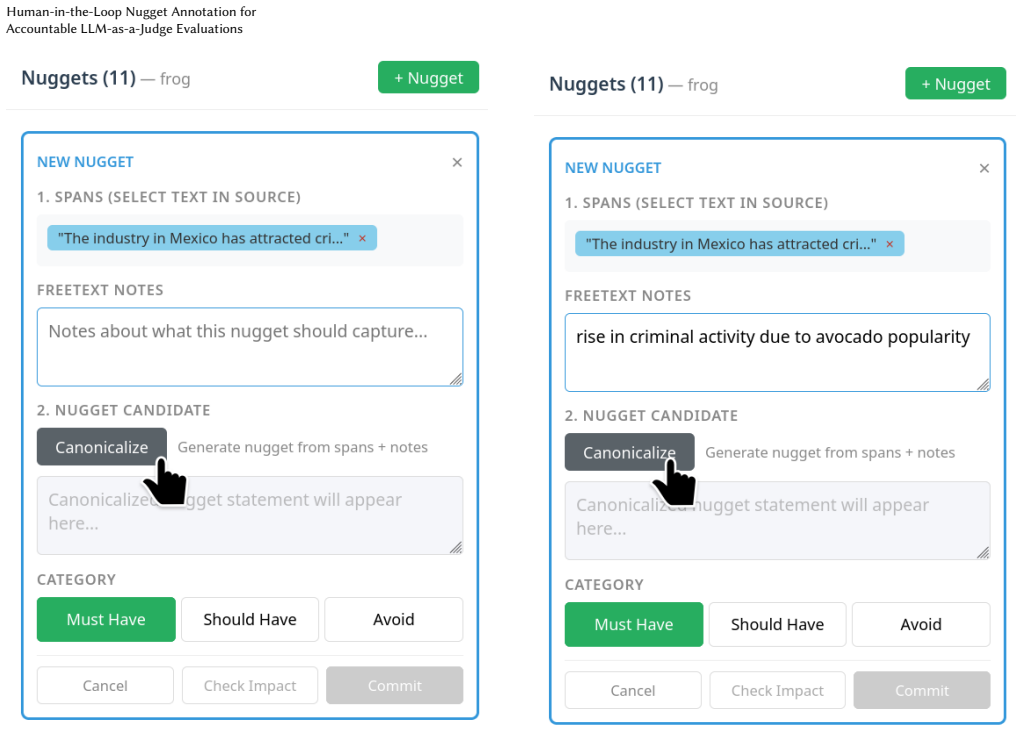
The nugget annotation tool that separates human identification of important information from LLM-based matching of nuggets to outputs.
If this is right
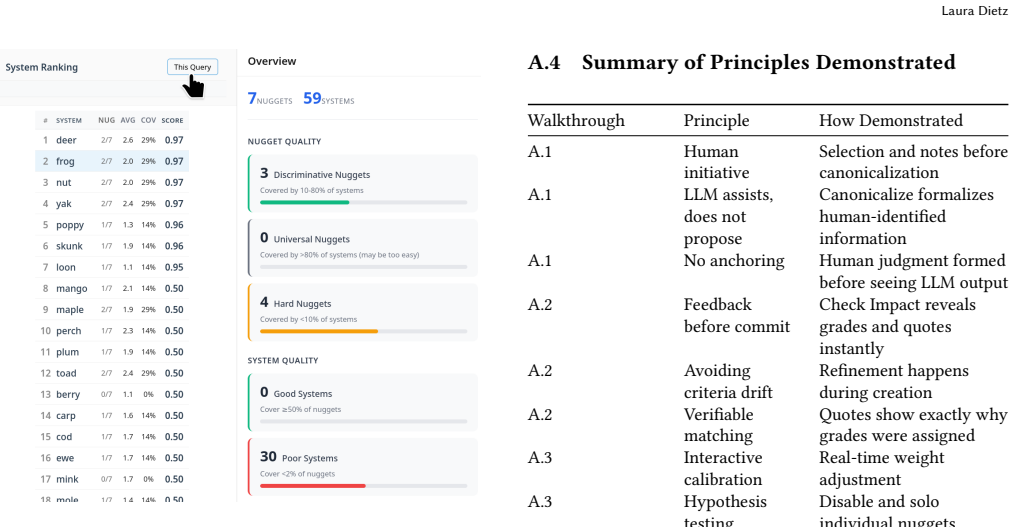
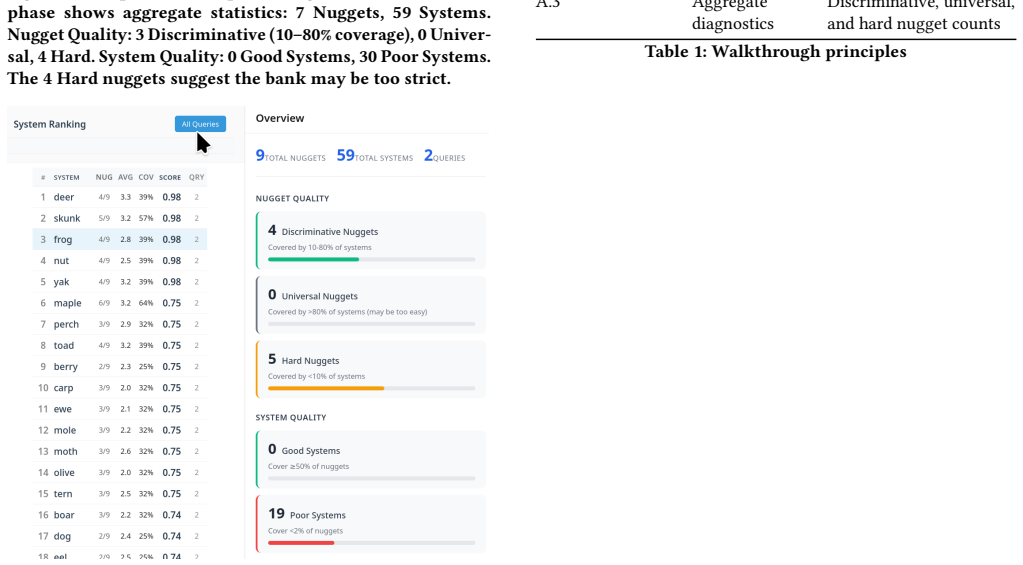
- Exported nugget banks integrate directly with automated judges for scalable use.
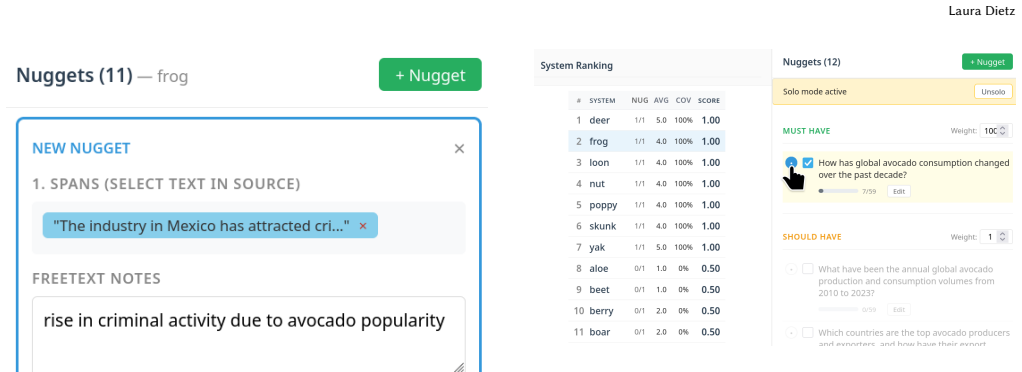
- The three-phase workflow supports reliable evaluation of AI and agentic system outputs.
- Human oversight stays focused on content selection rather than repetitive matching.
- The method avoids both expert anchoring and unsupported labeling tasks.
Where Pith is reading between the lines
- The approach might allow reusable nugget sets across multiple systems being evaluated.
- It could be tested by measuring how much the final scores change when the same nuggets are applied by different matching models.
- Neighboring evaluation settings that rely on passage-level relevance might adopt similar human-first identification steps.
Load-bearing premise
That separating nugget identification from matching will produce a genuine quality signal instead of the anchoring or variance problems found in other human-LLM divisions.
What would settle it
A direct comparison in which judgments produced by the nugget workflow show no higher agreement with independent full-human preference ratings than judgments from standard LLM-as-a-judge methods that lack the human nugget step.
Figures

read the original abstract
Evaluating AI/Agentic system outputs reliably requires human judgment, but how one incorporates the human determines whether one gets a real quality signal or expensive theater. The common approaches either accidentally anchor human experts (leading to rubber-stamping) or leave them unsupported in high-variance labeling tasks. We present a prototype annotation tool that implements a different division of labor: humans identify what information matters (nuggets), while LLMs handle high-volume matching of nuggets to system outputs. This plays to each party's strengths while maintaining genuine human oversight. We describe the three-phase workflow, key design decisions, and how exported nugget banks integrate with automated judges.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a prototype annotation tool implementing a human-in-the-loop workflow for evaluating AI/agentic system outputs. Humans identify key information as 'nuggets,' while LLMs perform high-volume matching of nuggets to outputs; the goal is to combine human oversight with LLM scalability for more accountable LLM-as-a-judge evaluations. The paper describes the three-phase workflow, key design decisions, and integration of exported nugget banks with automated judges.
Significance. If empirically validated, the proposed division of labor could address documented issues of anchoring and high variance in human evaluation tasks, offering a practical advance for scalable, accountable evaluation in information retrieval and NLP. The conceptual separation of nugget creation from matching is a clear strength of the design rationale.
major comments (2)
- [Abstract] Abstract: The central claim that the workflow 'maintains genuine human oversight' while avoiding 'anchoring' and 'high-variance labeling tasks' of prior methods is load-bearing but unsupported; the manuscript supplies only a workflow description with no annotation studies, inter-annotator agreement metrics, error analysis, or comparisons to direct human judgment or LLM baselines.
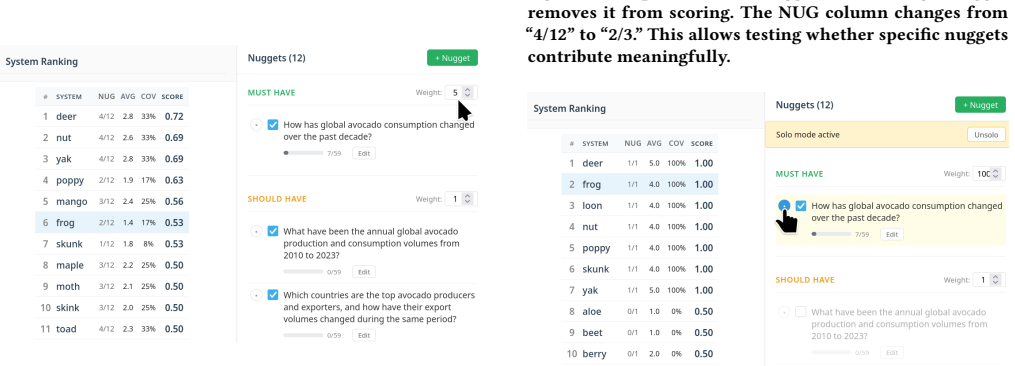
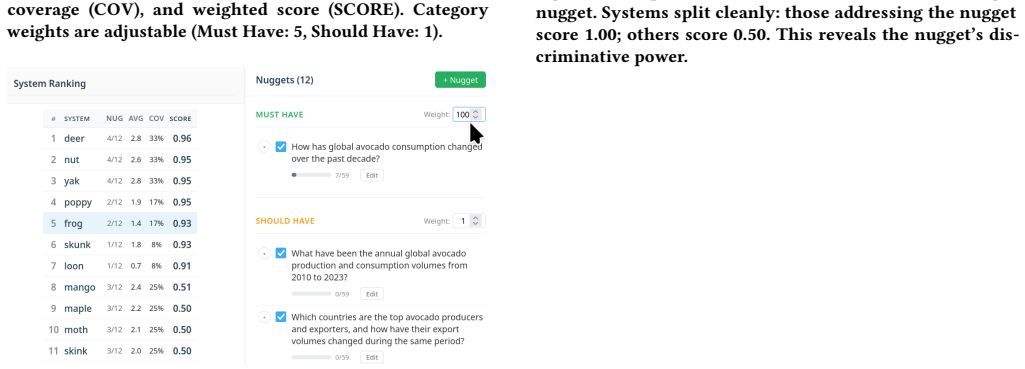
- [three-phase workflow] Description of the three-phase workflow: No measurement is provided of whether exported nugget banks produce more stable or less biased judgments than the approaches criticized in the abstract, leaving the claimed quality signal untested.
minor comments (1)
- The manuscript would benefit from a figure or diagram illustrating the three-phase workflow and the interface for nugget identification.
Simulated Author's Rebuttal
We thank the referee for the detailed review. The manuscript is a description of a prototype tool and three-phase workflow; we agree that the current text does not contain empirical validation of the claimed benefits and will revise the abstract and body to align claims with the scope of the work presented.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the workflow 'maintains genuine human oversight' while avoiding 'anchoring' and 'high-variance labeling tasks' of prior methods is load-bearing but unsupported; the manuscript supplies only a workflow description with no annotation studies, inter-annotator agreement metrics, error analysis, or comparisons to direct human judgment or LLM baselines.
Authors: We agree. The abstract currently presents the benefits of the division of labor as established, whereas the manuscript provides only the workflow design and rationale. We will revise the abstract to describe the approach as one that is intended to maintain oversight and reduce anchoring through separation of nugget creation from matching, and we will add an explicit limitations section stating that empirical validation (including agreement metrics and baseline comparisons) remains future work. revision: yes
-
Referee: [three-phase workflow] Description of the three-phase workflow: No measurement is provided of whether exported nugget banks produce more stable or less biased judgments than the approaches criticized in the abstract, leaving the claimed quality signal untested.
Authors: This observation is accurate. The manuscript does not include any measurements or studies comparing nugget-bank judgments to other methods. We will revise the workflow description sections to present the expected stability and bias-reduction properties as design hypotheses rather than demonstrated results, and we will note in the limitations that such measurements have not yet been conducted. revision: yes
Circularity Check
No circularity: workflow description only, no derivations or fitted claims
full rationale
The manuscript presents a prototype tool and three-phase workflow for human nugget identification paired with LLM matching. No equations, parameters, predictions, or derivations appear in the abstract or described content. The central claim is a design rationale for division of labor, not a reduction of any quantity to its own inputs or to a self-citation chain. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. This is a self-contained descriptive paper; the absence of any mathematical or statistical claim that could be circular yields score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ujué Agudo, Karlos G Liberal, Miren Arrese, and Helena Matute. 2024. The impact of AI errors in a human-in-the-loop process.Cognitive Research: Principles and Implications9, 1 (2024), 1
2024
-
[2]
Charles L. A. Clarke and Laura Dietz. 2025. LLM-based relevance assessment still can’t replace human relevance assessment. InEVIA 2025: Proceedings of the Tenth International Workshop on Evaluating Information Access (EVIA 2025), a Satellite Workshop of the NTCIR-18 Conference, June 10-13, 2025, Tokyo, Japan. 1–5. doi:10.20736/0002002105
-
[3]
Laura Dietz. 2024. A workbench for autograding retrieve/generate systems. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1963–1972
2024
-
[4]
Laura Dietz, Naghmeh Farzi, Eugene Yang, and Dawn Lawrie. 2026. Too Many Questions: Deriving Concise and Effective Nugget Banks. InProceedings of the 49th International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval (SIGIR ’26)(July 20–24, 2026). ACM, Melbourne, VIC, Australia
2026
- [5]
-
[6]
Laura Dietz, Oleg Zendel, Peter Bailey, Charles Clarke, Ellese Cotterill, Jeff Dalton, Faegheh Hasibi, Mark Sanderson, and Nick Craswell. 2025. Principles and Guidelines for the Use of LLM Judges. InProceedings of the 11th ACM SIGIR / The 15th International Conference on Innovative Concepts and Theories in Information Retrieval
2025
-
[7]
Laura Dietz, Oleg Zendel, Peter Bailey, Charles L. A. Clarke, Ellese Cotterill, Jeff Dalton, Faegheh Hasibi, Mark Sanderson, and Nick Craswell. 2025. Principles and Guidelines for the Use of LLM Judges. InProceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Retrieval (ICTIR ’25). doi:10.1145/3731120.3744588
-
[8]
Guglielmo Faggioli, Laura Dietz, Charles L. A. Clarke, Gianluca Demartini, Matthias Hagen, Claudia Hauff, Noriko Kando, Evangelos Kanoulas, Martin Potthast, Benno Stein, et al . 2023. Perspectives on Large Language Models for Relevance Judgment. InProceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval. 39–50
2023
-
[9]
Naghmeh Farzi and Laura Dietz. 2024. Exam++: Llm-based answerability met- rics for ir evaluation. InProceedings of LLM4Eval: The First Workshop on Large Language Models for Evaluation in Information Retrieval
2024
- [10]
-
[11]
Raymond Fok and Daniel S Weld. 2024. In search of verifiability: Explanations rarely enable complementary performance in AI-advised decision making.AI Magazine45, 3 (2024), 317–332
2024
-
[12]
Bryan Li, William Walden, Yu Hou, Gabrielle Kaili-May Liu, Dawn Lawrie, James Mayfield, Eugene Yang, Chris Callison-Burch, and Laura Dietz. 2026. DoGMaTiQ: Automated Generation of Question-and-Answer Nuggets for Report Evaluation. InProceedings of the 2026 ACM SIGIR International Conference on the Theory of Information Retrieval (ICTIR ’26). ACM, Melbourn...
2026
-
[13]
Jimmy Lin and Dina Demner-Fushman. 2006. Will pyramids built of nuggets topple over?. InProceedings of the Human Language Technology Conference of the NAACL, Main Conference. 383–390
2006
-
[14]
Yiqi Liu, Nafise Sadat Moosavi, and Chenghua Lin. 2024. LLMs as Narcissistic Evaluators: When Ego Inflates Evaluation Scores. InFindings of the Association for Computational Linguistics (ACL) 2024. https://aclanthology.org/2024.findings- acl.753/ Investigates bias in LLM-based evaluation metrics favoring their own outputs
2024
-
[15]
Ani Nenkova and Rebecca J Passonneau. 2004. Evaluating content selection in summarization: The pyramid method. InProceedings of the human language tech- nology conference of the north american chapter of the association for computational linguistics: Hlt-naacl 2004. 145–152
2004
-
[16]
Golbus, and Javed A
Virgil Pavlu, Shahzad Rajput, Peter B. Golbus, and Javed A. Aslam. 2012. IR System Evaluation Using Nugget-Based Test Collections. InProceedings of the Fifth ACM International Conference on Web Search and Data Mining (WSDM 2012). ACM, Seattle, Washington, 393–402
2012
- [17]
-
[18]
Ronak Pradeep, Nandan Thakur, Shivani Upadhyay, Daniel Campos, Nick Craswell, Ian Soboroff, Hoa Trang Dang, and Jimmy Lin. 2025. The Great Nugget Recall: Automating Fact Extraction and RAG Evaluation with Large Language Models. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 180–190
2025
-
[19]
David P Sander and Laura Dietz. 2021. EXAM: How to Evaluate Retrieve-and- Generate Systems for Users Who Do Not (Yet) Know What They Want.. In DESIRES. 136–146
2021
-
[20]
Shreya Shankar, JD Zamfirescu-Pereira, Björn Hartmann, Aditya Parameswaran, and Ian Arawjo. 2024. Who validates the validators? aligning llm-assisted evalu- ation of llm outputs with human preferences. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. 1–14
2024
-
[21]
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, Weicheng Ma, and Soroush Vosoughi. 2025. Judging the judges: A systematic study of position bias in llm- as-a-judge. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics. 292–314
2025
-
[22]
Amos Tversky and Daniel Kahneman. 1974. Judgment under Uncertainty: Heuris- tics and Biases: Biases in judgments reveal some heuristics of thinking under uncertainty.science185, 4157 (1974), 1124–1131
1974
-
[23]
Voorhees
Ellen M. Voorhees. 2003. Overview of the TREC 2003 Question Answering Track. InProceedings of the Twelfth Text REtrieval Conference (TREC 2003). NIST, Gaithersburg, Maryland. 5 Laura Dietz
2003
-
[24]
William Walden, Marc Mason, Orion Weller, Laura Dietz, John Conroy, Neil Molino, Hannah Recknor, Bryan Li, Gabrielle Kaili-May Liu, Yu Hou, et al. 2026. Auto-argue: Llm-based report generation evaluation. InSIGIR
2026
-
[25]
Rising Demand for Avocado
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023). 46595–46623. Figure 5: Step 1: Human reads ...
2023
-
[26]
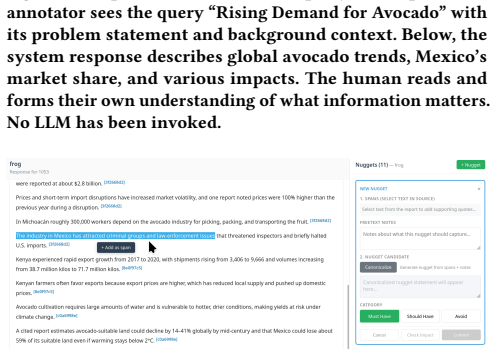
In Mexico, criminal groups are tied to avocado production and distribution, with violence including politi- cian killings
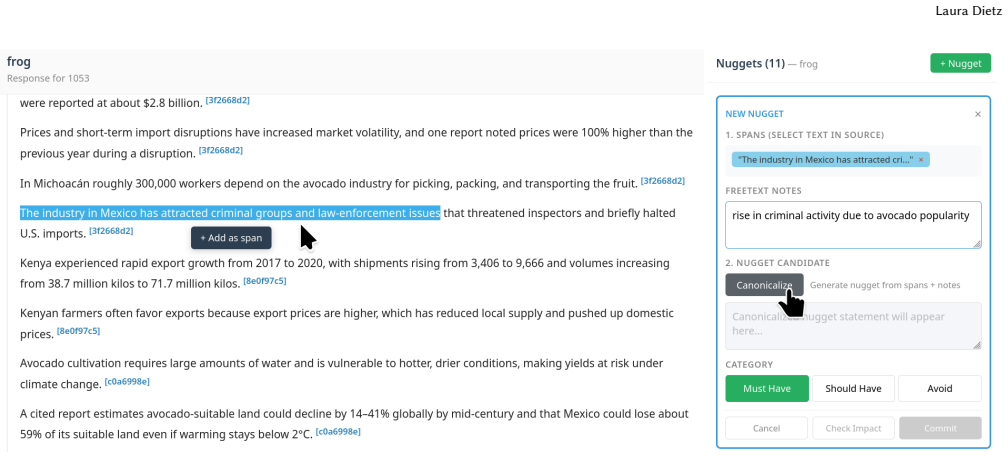
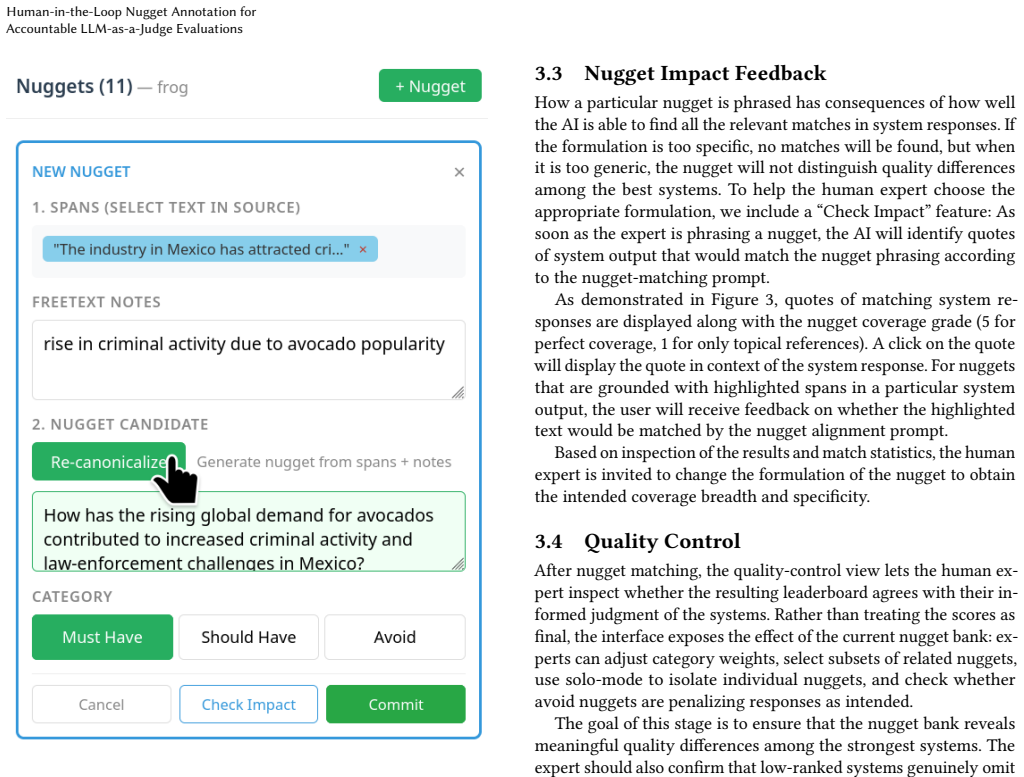
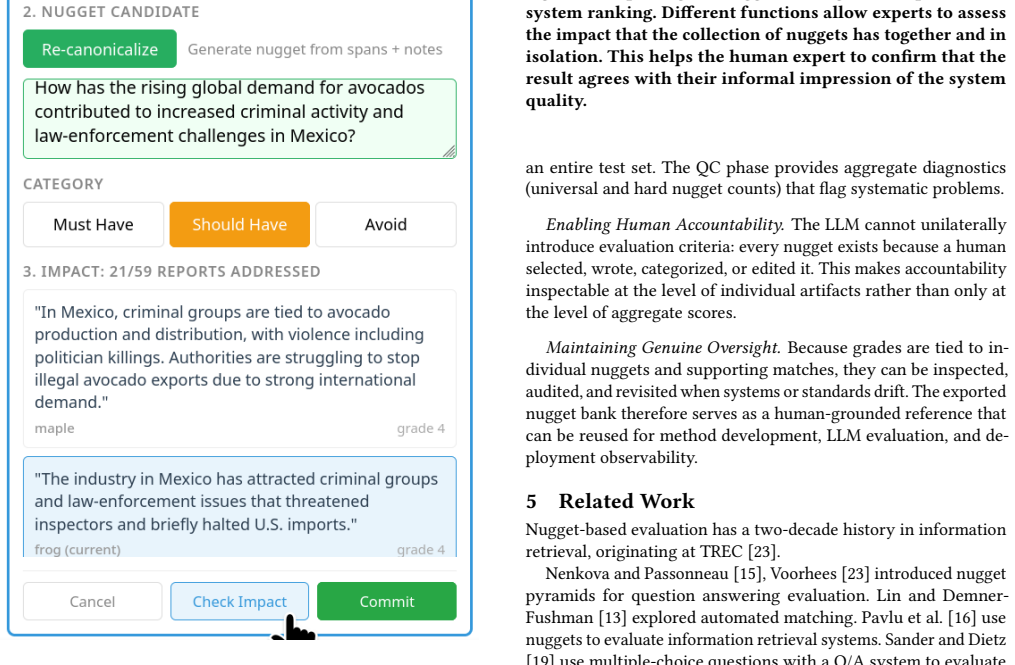
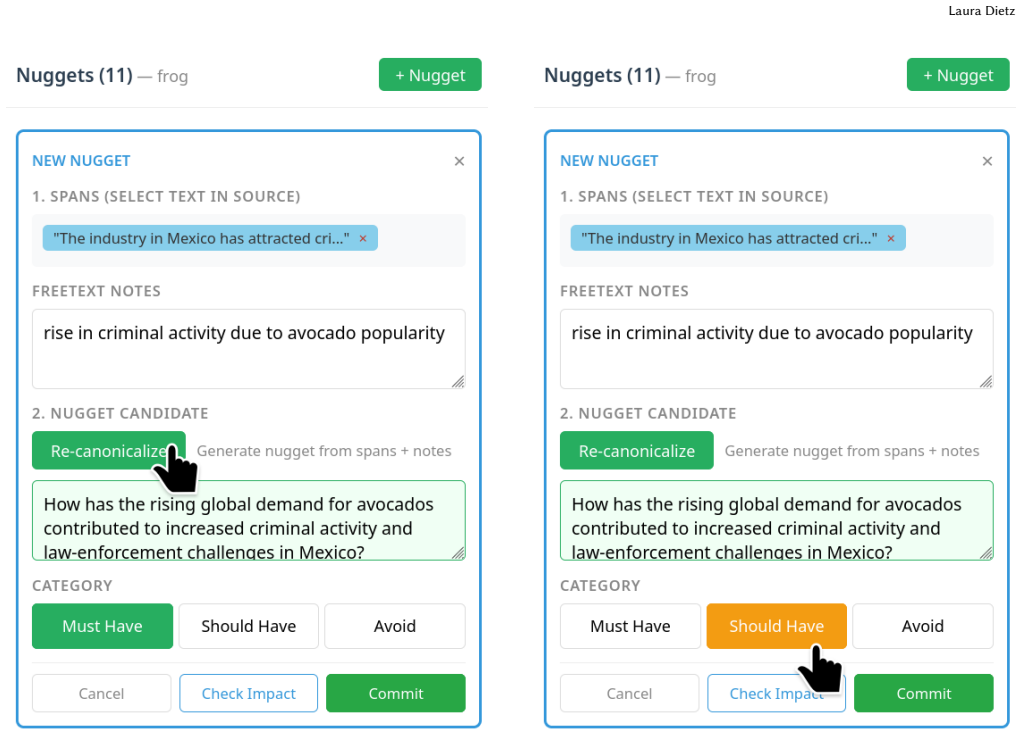
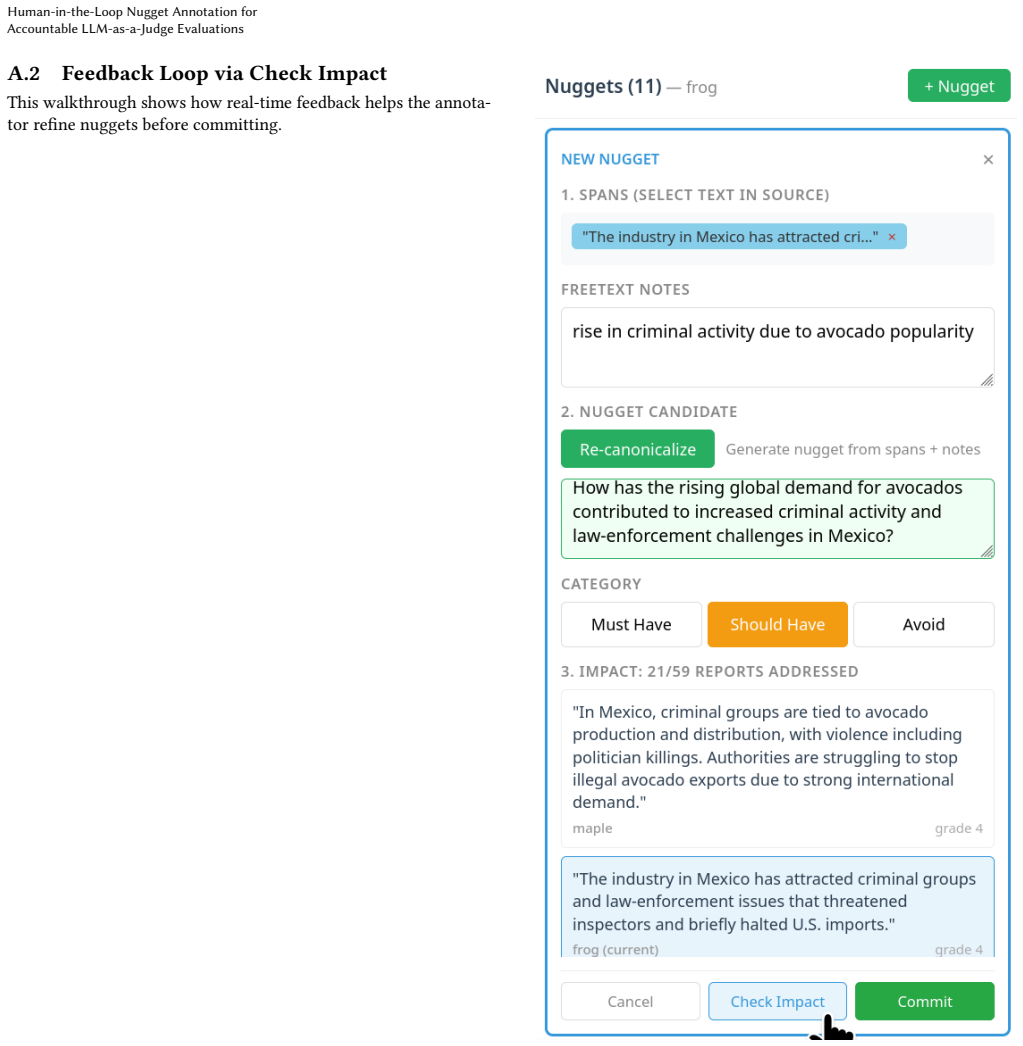
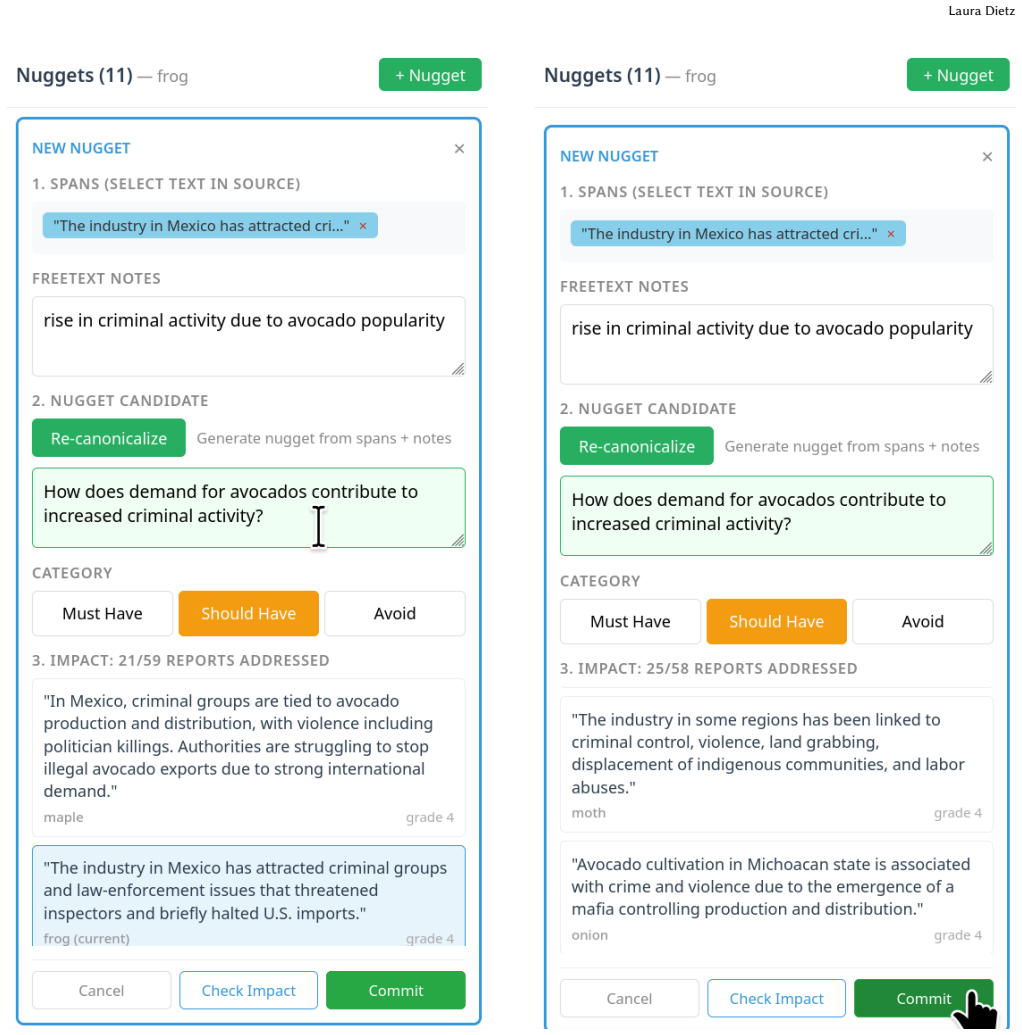
shows: “In Mexico, criminal groups are tied to avocado production and distribution, with violence including politi- cian killings. . . ” The annotator sees exactly how this nugget grades and why. 9 Laura Dietz Figure 12: Step 2: Refining based on feedback. Based on the preview, the annotator edits the nugget text to be more con- cise: “How does demand for...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.