Enterprise Data Modelling Methodologies: A Comparative Analysis of Inmon, Kimball, and Data Vault
Pith reviewed 2026-06-30 02:22 UTC · model grok-4.3
The pith
No single data warehousing methodology is universally optimal; choice depends on an organization's scale, regulations, maturity, and investment tolerance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The analysis concludes that no single methodology among Inmon, Kimball, and Data Vault is universally optimal; the appropriate choice is contingent on an organisation's scale, regulatory environment, analytical maturity, and tolerance for upfront architectural investment, with a synthesis of decision criteria provided to guide selection aligned with strategic objectives.
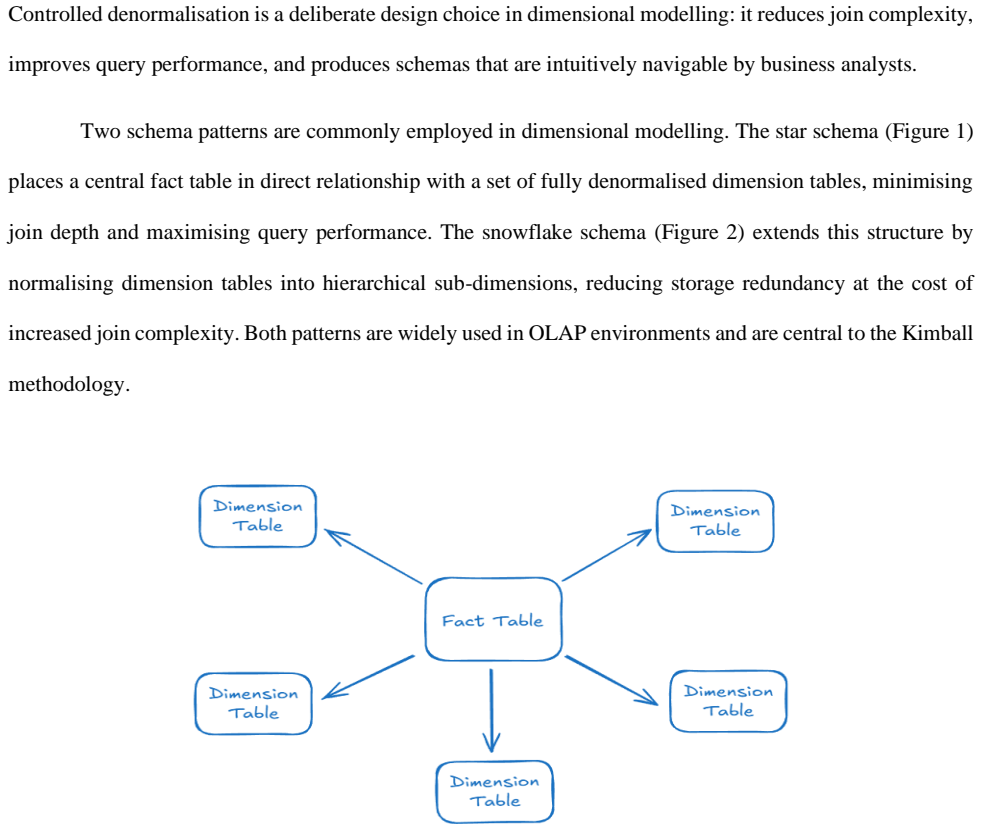
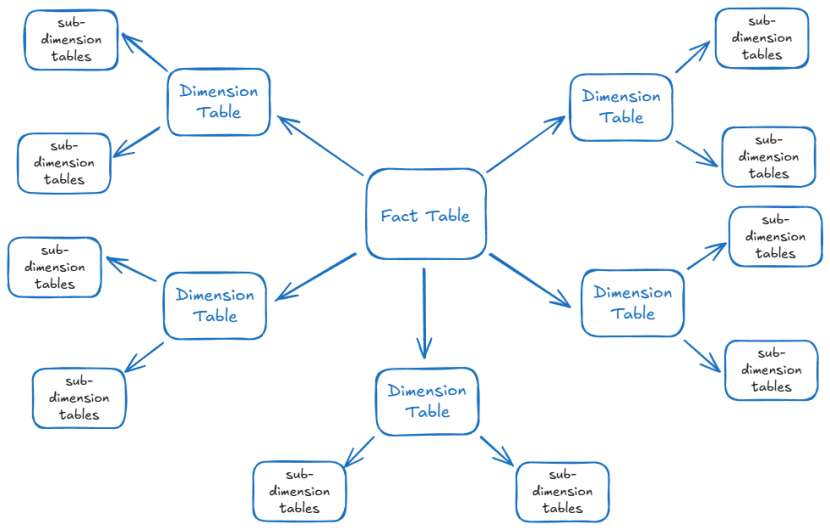
What carries the argument
The comparative framework that evaluates each methodology across the dimensions of architectural philosophy, modelling technique, scalability, agility, query performance, audit capability, and organisational suitability.
If this is right
- High-regulation organizations gain audit advantages from Data Vault while accepting its modeling overhead.
- Organizations needing rapid delivery benefit from Kimball's dimensional focus and lower upfront effort.
- Large-scale normalized architectures favor Inmon when long-term consistency outweighs initial investment.
- Decision criteria allow practitioners to map methodology selection directly to strategic objectives like compliance or agility.
Where Pith is reading between the lines
- The decision criteria could be tested in practice by tracking outcomes when organizations switch methodologies mid-project.
- Hybrid implementations that draw elements from more than one approach may emerge as a practical response to the contingency finding.
- The framework could be extended to evaluate newer data architectures that build on the same OLTP/OLAP and modeling foundations.
Load-bearing premise
The common technical foundations of OLTP/OLAP distinction, relational normalisation, and entity-relationship/dimensional modelling are adequate bases for evaluating the three methodologies.
What would settle it
A controlled comparison of data warehouse projects across matched organizations of varying scale and regulatory needs that shows one methodology delivering consistently superior outcomes on the measured dimensions regardless of context.
Figures

read the original abstract
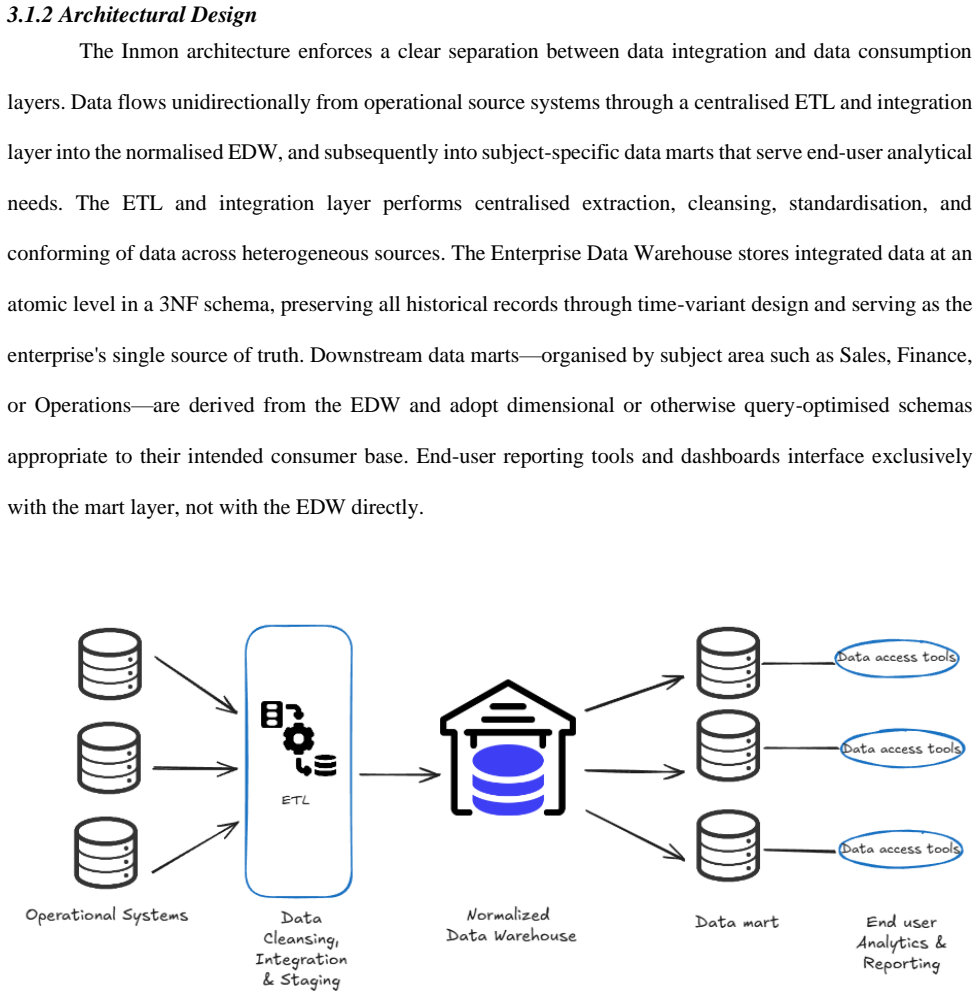
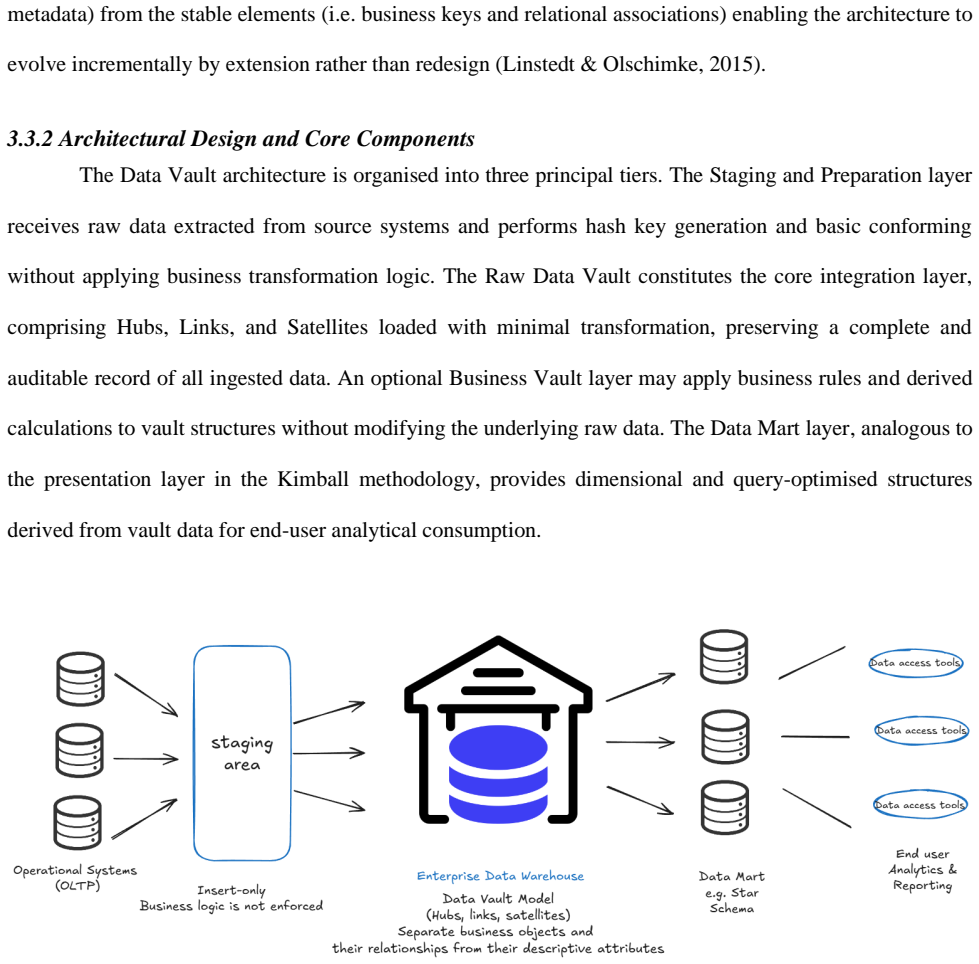
The design and governance of enterprise data warehouses constitute foundational decisions in modern data-driven organisations, with long-term impact for analytical capability, operational agility, and regulatory compliance. This paper presents a structured comparative analysis of three prevailing data warehousing methodologies: the Inmon approach, the Kimball approach, and Data Vault. The paper first establishes the technical foundations common to all three enterprise frameworks, in particular the distinction between Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP) systems, the principles of relational normalisation, and the core techniques of entity-relationship and dimensional data modelling. The comparative analysis examines each methodology across a set of dimensions including architectural philosophy, modelling technique, scalability, agility, query performance, audit capability, and suitability for different organisational profiles. Findings indicate that no single methodology is universally optimal; rather, the appropriate choice is contingent on an organisation's scale, regulatory environment, analytical maturity, and tolerance for upfront architectural investment. This paper concludes with a synthesis of decision criteria to guide practitioners and researchers in selecting the methodology most aligned with their strategic objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a structured comparative analysis of three enterprise data warehousing methodologies: Inmon, Kimball, and Data Vault. It first establishes common technical foundations including the OLTP/OLAP distinction, relational normalisation, and entity-relationship/dimensional modelling. The analysis then evaluates the methodologies across dimensions of architectural philosophy, modelling technique, scalability, agility, query performance, audit capability, and organisational suitability. The central claim is that no single methodology is universally optimal; the appropriate choice is contingent on an organisation's scale, regulatory environment, analytical maturity, and tolerance for upfront architectural investment. The paper concludes with a synthesis of decision criteria to guide selection.
Significance. If the comparative analysis holds, the work offers a useful consolidation of established trade-offs in data warehousing for practitioners, organising existing literature along conventional dimensions into an explicit decision framework. As a qualitative literature synthesis rather than an empirical or formal study, its value lies in the systematic presentation of well-documented distinctions without introducing new claims or parameters.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript and the recommendation to accept. The review accurately captures the paper's scope as a qualitative synthesis of established trade-offs and its intended value as a decision framework for practitioners.
Circularity Check
No significant circularity; qualitative synthesis of established methodologies
full rationale
The paper performs a structured comparative analysis of Inmon, Kimball, and Data Vault approaches using standard dimensions (architectural philosophy, scalability, etc.) drawn from existing literature on OLTP/OLAP, normalisation, and ER/dimensional modelling. No equations, predictions, fitted parameters, or derivation chains exist. The central claim—that optimality is contingent on organisational factors—is the direct, non-circular outcome of enumerating documented trade-offs. No self-citation load-bearing steps, self-definitional constructs, or ansatz smuggling are present. The analysis is self-contained against external benchmarks in the data-warehousing literature.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The distinction between Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP) systems, along with principles of relational normalisation and entity-relationship/dimensional modelling, form the common technical foundations for the three methodologies.
Reference graph
Works this paper leans on
-
[1]
Chaudhuri, S., & Dayal, U. (1997). An overview of data warehousing and OLAP technology. ACM SIGMOD Record, 26(1), 65–74. https://doi.org/10.1145/248603.248616 Chen, P. P. -S. (1976). The entity -relationship model: Toward a unified view of data. ACM Transactions on Database Systems, 1(1), 9–36. https://doi.org/10.1145/320434.320440 Codd, E. F. (1970). A r...
-
[2]
https://doi.org/10.1145/362384.362685 Codd, E. F. (1972). Further normalization of the data base relational model. In R. Rustin (Ed.), Data Base Systems (pp. 33–64). Prentice-Hall. Arab, I.; Falah, B.; Magel, K. SCMS: Tool for Assessing a Novel Taxonomy of Complexity Metrics for any Java Project at the Class and Method Levels based on Statement Level Metr...
-
[3]
https://doi.org/10.3390/computers14060222 Ravi, V. K., & Cheruku, S. R. (2024). AI and machine learning in predictive data architecture. International Research Journal of Modernization in Engineering Technology and Science. Inmon, W. H. (2005). Building the data warehouse (4th ed.). Wiley. Inmon, W. H. (2016). Data lake architecture: Designing the data la...
-
[4]
An attempt towards a formalizing UML class diagram semantics
https://dx.doi.org/10.14569/IJACSA.2018.090402 Falah, B.; Akour, M.; Arab, I.; M’hanna, Y. An attempt towards a formalizing UML class diagram semantics. In Proceedings of the New Trends in Information Technology (NTIT -2017), Amman, Jordan, 25 –27 April 2017; pp. 21–27. Arab, I.; Bourhnane, S. Reducing the cost of mutation operators through a novel taxono...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.