Position-Aware Target Speaker Extraction for Long-Form Multi-Party Conversations: A Diarization-Free Framework for ASR
Pith reviewed 2026-06-30 02:04 UTC · model grok-4.3
The pith
A position-aware target speaker extraction front-end uses direction of arrival to produce speaker-attributed streams without diarization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PATSE combines a DOA-guided spatial encoder and conditioner to generate speaker-attributed streams, enabling speaker activity inference via post-processing like VAD without explicit diarization, and experiments demonstrate consistent ASR gains over CSS and diarization-based pipelines on both replayed and real conversations.
What carries the argument
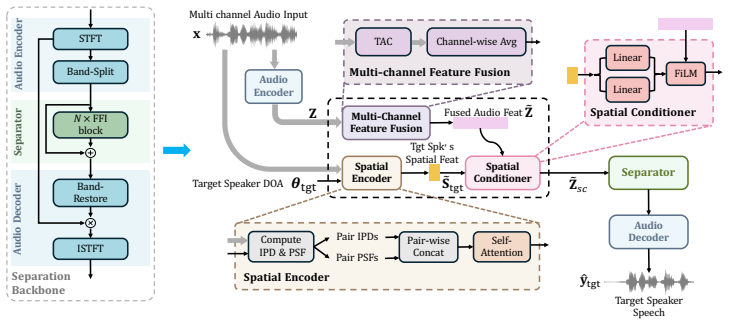
The PATSE front-end, which employs a DOA-guided spatial encoder and conditioner to extract target speaker speech using direction of arrival as a spatial prior.
If this is right
- Consistent improvements in ASR performance for long-form conversations.
- Elimination of the need for separate diarization modules.
- Reduced residual crosstalk and speaker inconsistency issues.
- Applicability to both replayed and real meeting scenarios.
Where Pith is reading between the lines
- If DOA stability holds across different room acoustics, the method could generalize to varied meeting environments.
- Integration with end-to-end ASR systems might further streamline the pipeline by combining extraction and recognition.
- Potential for adaptation to single-channel scenarios if spatial priors can be estimated differently.
Load-bearing premise
Speakers' directions of arrival remain sufficiently stable in meetings to serve as a reliable spatial prior.
What would settle it
A test where DOA estimates fluctuate significantly during conversations, resulting in no ASR improvement or degradation compared to baseline methods.
Figures
read the original abstract
In long-form multi-party conversations, highly imbalanced speaker activity and frequent overlap make it difficult to identify "who spoke when and what". Sliding-window continuous speech separation (CSS) mitigates sparse supervision, but often suffers from cross-window speaker inconsistency and residual crosstalk, which in practice requires diarization for reliable speaker attribution. Motivated by the stability of speakers' directions of arrival (DOAs) in meetings, we propose PATSE, a multi-channel Position-Aware Target Speaker Extraction front-end that uses DOA as a spatial prior to directly extract the speech of each target speaker. PATSE combines a DOA-guided spatial encoder and conditioner to generate speaker-attributed streams, from which speaker activity can be inferred via simple post-processing (e.g., VAD) without explicit diarization. Experiments on both replayed and real conversations show consistent ASR gains outperforming CSS and diarization-based pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PATSE, a multi-channel position-aware target speaker extraction front-end for long-form multi-party conversations. It uses speakers' directions of arrival (DOAs) as a spatial prior in a DOA-guided encoder and conditioner to produce speaker-attributed streams, from which activity is inferred via post-processing such as VAD, avoiding explicit diarization. Experiments on replayed and real conversations are claimed to show consistent ASR gains over CSS and diarization-based pipelines.
Significance. If the results hold and the DOA prior proves reliable, the method could streamline speaker-attributed ASR pipelines by removing the diarization step, offering efficiency gains in handling overlap and imbalance in meeting data.
major comments (2)
- [Abstract] Abstract (motivation paragraph): The central claim that DOA stability enables a reliable spatial prior for diarization-free extraction is load-bearing, yet the manuscript supplies no quantitative validation such as DOA variance statistics, speaker movement analysis, or ablation with perturbed DOAs on the real-conversation test set. Without this, the reported ASR gains cannot be attributed to the proposed framework rather than dataset-specific stability.
- [Experiments] Experiments section: The abstract asserts 'consistent ASR gains' outperforming baselines, but the description provides no dataset sizes, error bars, number of trials, or ablation results (e.g., with/without DOA conditioning). This absence prevents assessment of whether the gains are statistically robust or sensitive to the untested DOA assumption.
minor comments (1)
- [Abstract] Abstract: Consider adding one or two key quantitative metrics (e.g., WER reduction ranges) to make the performance claim concrete rather than qualitative.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the presentation of the DOA assumption and experimental details.
read point-by-point responses
-
Referee: [Abstract] Abstract (motivation paragraph): The central claim that DOA stability enables a reliable spatial prior for diarization-free extraction is load-bearing, yet the manuscript supplies no quantitative validation such as DOA variance statistics, speaker movement analysis, or ablation with perturbed DOAs on the real-conversation test set. Without this, the reported ASR gains cannot be attributed to the proposed framework rather than dataset-specific stability.
Authors: We agree that the current manuscript motivates the approach with DOA stability but does not supply quantitative validation of that assumption. In the revision we will add DOA variance statistics computed on the real-conversation test set, a brief speaker-movement analysis, and an ablation that perturbs the supplied DOAs; these additions will allow readers to assess how sensitive the reported gains are to the spatial prior. revision: yes
-
Referee: [Experiments] Experiments section: The abstract asserts 'consistent ASR gains' outperforming baselines, but the description provides no dataset sizes, error bars, number of trials, or ablation results (e.g., with/without DOA conditioning). This absence prevents assessment of whether the gains are statistically robust or sensitive to the untested DOA assumption.
Authors: We acknowledge that the experimental section as written omits these quantitative details. The revised version will report dataset sizes, error bars across multiple runs, the number of trials, and an explicit ablation with/without DOA conditioning so that the statistical robustness of the gains can be evaluated directly. revision: yes
Circularity Check
No circularity: empirical claims rest on experiments, not self-referential definitions
full rationale
The provided abstract and text contain no equations, fitted parameters, or derivation chain that reduces outputs to inputs by construction. The method is introduced via the assumption of DOA stability in meetings to motivate a DOA-guided encoder, but this is an external modeling choice rather than a self-definitional loop or renamed fit. Reported ASR gains on replayed and real data are presented as validation against baselines, with no self-citation load-bearing the central result or uniqueness theorem invoked from prior author work. The paper is therefore self-contained against external benchmarks with no detectable circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Speakers' directions of arrival remain stable enough in meetings to serve as a reliable spatial prior.
Reference graph
Works this paper leans on
-
[1]
who spoke when and what
Introduction In multi-party conversations such as meetings and discussions, the fundamental problem is to identify “who spoke when and what” [1, 2, 3]. Real-world recordings are typically long and continuous, where spontaneous conversations results in highly imbalanced speaker activity, and back-channel responses and brief interruptions cause frequent spe...
-
[2]
Proposed Method 2.1. Architecture As shown in Figure 1, PATSE treats DOA as an explicit cue for “who” and conditions the separation backbone on this spatial prior. Letx={x m}M m=1 denote the multi-channel audio signal captured byMmicrophones, wheremindexes the channels. The azimuth angleθ tgt denotes the DOA of the target speaker. 1https://huggingface.co/...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
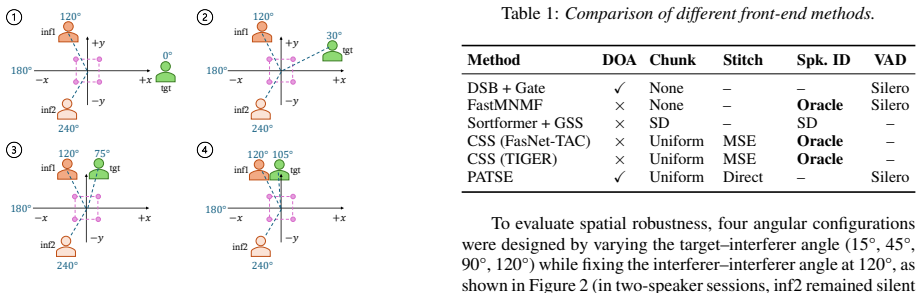
Experiments 3.1. Datasets LibriReplay-DOA Dataset.Most speech separation bench- marks rely on simulated Room Impulse Responses (RIRs) that may not fully reflect real-world conditions, while real-world corpora often lack ground-truth DOA labels. To evaluate DOA- based methods reliably, we construct LibriReplay-DOA, a real- room playback dataset with ground...
-
[4]
Results LibriReplay-DOA.Table 2 reports WER on LibriReplay-DOA across four target–interferer angles (15 ◦, 45 ◦, 90 ◦, 120 ◦) and four overlap ranges (0–25%, 25–50%, 50–75%, 75–100%). In theTraining Strategycolumn,NTdenotes no training;Scratch denotes training from scratch on the training data in Sec- tion 3.1; andPT+FTdenotes initialization from a pretra...
-
[5]
who spoke when and what
Conclusion In this paper, we presented PATSE, a position-aware target speaker extraction framework for addressing the “who spoke when and what” problem in multi-party conversations. By pro- ducing target-conditioned, speaker-attributed streams, PATSE derived speaker activity via simple post-processing without ex- plicit diarization. To facilitate evaluati...
-
[6]
Acknowledgments This work was supported by JST BOOST JPMJBS2407 and JST Moonshot R&D JPMJMS2011
-
[7]
Generative AI Use Disclosure Generative AI tools (Gemini and ChatGPT) were used for lan- guage editing and improving the phrasing of this manuscript
-
[8]
One model to rule them all? towards end-to-end joint speaker diarization and speech recognition,
S. Cornell, J.-w. Jung, S. Watanabe, and S. Squartini, “One model to rule them all? towards end-to-end joint speaker diarization and speech recognition,” inProc. ICASSP, 2024, pp. 11 856–11 860
2024
-
[9]
Train short, in- fer long: Speech-llm enables zero-shot streamable joint asr and diarization on long audio,
M. Shi, X. Xiao, R. Fan, S. Ling, and J. Li, “Train short, in- fer long: Speech-llm enables zero-shot streamable joint asr and diarization on long audio,” inProc. ICASSP, 2026, pp. 17 442– 17 446
2026
-
[10]
Casa-asr: Context-aware speaker-attributed asr,
M. Shi, Z. Du, Q. Chen, F. Yu, Y . Li, S. Zhang, J. Zhang, and L.- R. Dai, “Casa-asr: Context-aware speaker-attributed asr,” inProc. Interspeech, 2023, pp. 411–415
2023
-
[11]
DCF-DS: Deep cascade fusion of diarization and separa- tion for speech recognition under realistic single-channel condi- tions,
S.-T. Niu, J. Du, R.-Y . Wang, G.-B. Yang, T. Gao, J. Pan, and Y . Hu, “DCF-DS: Deep cascade fusion of diarization and separa- tion for speech recognition under realistic single-channel condi- tions,”IEEE/ACM Trans. ASLP, 2025
2025
-
[12]
Continuous speech separation: Dataset and analysis,
Z. Chen, T. Yoshioka, L. Lu, T. Zhou, Z. Meng, Y . Luo, J. Wu, X. Xiao, and J. Li, “Continuous speech separation: Dataset and analysis,” inProc. ICASSP, 2020, pp. 7284–7288
2020
-
[13]
Integration of speech separation, diarization, and recognition for multi-speaker meetings: System description, comparison, and analysis,
D. Raj, P. Denisov, Z. Chen, H. Erdogan, Z. Huang, M. He, S. Watanabe, J. Du, T. Yoshioka, Y . Luoet al., “Integration of speech separation, diarization, and recognition for multi-speaker meetings: System description, comparison, and analysis,” inProc. SLT, 2021, pp. 897–904
2021
-
[14]
Multi-resolution location-based train- ing for multi-channel continuous speech separation,
H. Taherian and D. Wang, “Multi-resolution location-based train- ing for multi-channel continuous speech separation,” inProc. ICASSP, 2023, pp. 1–5
2023
-
[15]
Low-latency speaker-independent continuous speech separation,
T. Yoshioka, Z. Chen, C. Liu, X. Xiao, H. Erdogan, and D. Dim- itriadis, “Low-latency speaker-independent continuous speech separation,” inProc. ICASSP, 2019, pp. 6980–6984
2019
-
[16]
Graph-PIT: Generalized permutation invari- ant training for continuous separation of arbitrary numbers of speakers,
T. von Neumann, K. Kinoshita, C. Boeddeker, M. Delcroix, and R. Haeb-Umbach, “Graph-PIT: Generalized permutation invari- ant training for continuous separation of arbitrary numbers of speakers,” inProc. Interspeech, 2021, pp. 3490–3494
2021
-
[17]
Speaker activity driven neural speech extraction,
M. Delcroix, K. Zmolikova, T. Ochiai, K. Kinoshita, and T. Nakatani, “Speaker activity driven neural speech extraction,” inProc. ICASSP, 2021, pp. 6099–6103
2021
-
[18]
Gpu-accelerated guided source separation for meeting transcription,
D. Raj, D. Povey, and S. Khudanpur, “Gpu-accelerated guided source separation for meeting transcription,” inProc. Interspeech, 2023, pp. 3507–3511
2023
-
[19]
The STC system for the chime-6 challenge,
I. Medennikov, M. Korenevsky, T. Prisyach, Y . Khokhlov, M. Ko- renevskaya, I. Sorokin, T. Timofeeva, A. Mitrofanov, A. An- drusenko, I. Podluzhnyet al., “The STC system for the chime-6 challenge,” inCHiME 2020 Workshop on Speech Processing in Everyday Environments, 2020
2020
-
[20]
End-to-end neural speaker diarization with permutation-free objectives,
Y . Fujita, N. Kanda, S. Horiguchi, K. Nagamatsu, and S. Watan- abe, “End-to-end neural speaker diarization with permutation-free objectives,” inProc. Interspeech, 2019, pp. 4300–4304
2019
-
[21]
Multi-channel conversational speaker separation via neural diarization,
H. Taherian and D. Wang, “Multi-channel conversational speaker separation via neural diarization,”IEEE/ACM Trans. ASLP, vol. 32, pp. 2467–2476, 2024
2024
-
[22]
Exploiting spatial information with the informed complex-valued spatial au- toencoder for target speaker extraction,
A. Briegleb, M. M. Halimeh, and W. Kellermann, “Exploiting spatial information with the informed complex-valued spatial au- toencoder for target speaker extraction,” inProc. ICASSP, 2023, pp. 1–5
2023
-
[23]
Beamformer- guided target speaker extraction,
M. Elminshawi, S. R. Chetupalli, and E. A. Habets, “Beamformer- guided target speaker extraction,” inProc. ICASSP, 2023, pp. 1–5
2023
-
[24]
End-to-End speakerbeam for single channel target speech recognition
M. Delcroix, S. Watanabe, T. Ochiai, K. Kinoshita, S. Karita, A. Ogawa, and T. Nakatani, “End-to-End speakerbeam for single channel target speech recognition.” inProc. Interspeech, 2019, pp. 451–455
2019
-
[25]
V oice- Filter: Targeted voice separation by speaker-conditioned spectro- gram masking,
Q. Wang, H. Muckenhirn, K. Wilson, P. Sridhar, Z. Wu, J. R. Her- shey, R. A. Saurous, R. J. Weiss, Y . Jia, and I. L. Moreno, “V oice- Filter: Targeted voice separation by speaker-conditioned spectro- gram masking,” inProc. Interspeech, 2019, pp. 2728–2732
2019
-
[26]
TS-SEP: Joint diarization and separation con- ditioned on estimated speaker embeddings,
C. Boeddeker, A. S. Subramanian, G. Wichern, R. Haeb-Umbach, and J. Le Roux, “TS-SEP: Joint diarization and separation con- ditioned on estimated speaker embeddings,”IEEE/ACM Trans. ASLP, vol. 32, pp. 1185–1197, 2024
2024
-
[27]
DOA or Speaker em- bedding: Which is better for multi-microphone target speaker ex- traction,
S. Zhang, J. Zhang, Y . Wang, and H. Yan, “DOA or Speaker em- bedding: Which is better for multi-microphone target speaker ex- traction,”IEEE Signal Processing Letters, 2025
2025
-
[28]
A study of multichannel spatiotemporal features and knowledge distillation on robust target speaker extraction,
Y . Wang, J. Zhang, S. Chen, W. Zhang, Z. Ye, X. Zhou, and L. Dai, “A study of multichannel spatiotemporal features and knowledge distillation on robust target speaker extraction,” inProc. ICASSP, 2024, pp. 431–435
2024
-
[29]
Lever- aging boolean directivity embedding for binaural target speaker extraction,
Y . Wang, J. Zhang, C. Jiang, W. Zhang, Z. Ye, and L. Dai, “Lever- aging boolean directivity embedding for binaural target speaker extraction,” inProc. ICASSP, 2025, pp. 1–5
2025
-
[30]
Triadic multi- party voice activity projection for turn-taking in spoken dialogue systems,
M. Elmers, K. Inoue, D. Lala, and T. Kawahara, “Triadic multi- party voice activity projection for turn-taking in spoken dialogue systems,” inProc. Interspeech, 2025, pp. 3015–3019
2025
-
[31]
M. Xu, K. Li, G. Chen, and X. Hu, “Tiger: Time-frequency in- terleaved gain extraction and reconstruction for efficient speech separation,”arXiv preprint arXiv:2410.01469, 2024
-
[32]
End-to-end mi- crophone permutation and number invariant multi-channel speech separation,
Y . Luo, Z. Chen, N. Mesgarani, and T. Yoshioka, “End-to-end mi- crophone permutation and number invariant multi-channel speech separation,” inProc. ICASSP, 2020, pp. 6394–6398
2020
-
[33]
Combining spectral and spatial features for deep learning based blind speaker separation,
Z.-Q. Wang and D. Wang, “Combining spectral and spatial features for deep learning based blind speaker separation,” IEEE/ACM Trans. ASLP, vol. 27, no. 2, pp. 457–468, 2018
2018
-
[34]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” in Proc. AAAI., vol. 32, no. 1, 2018
2018
-
[35]
USEV: Universal speaker extraction with visual cue,
Z. Pan, M. Ge, and H. Li, “USEV: Universal speaker extraction with visual cue,”IEEE/ACM Trans. ASLP, vol. 30, pp. 3032– 3045, 2022
2022
-
[36]
Lib- rispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: an asr corpus based on public domain audio books,” inProc. ICASSP, 2015, pp. 5206–5210
2015
-
[37]
gpuRIR: A python library for room impulse response simulation with GPU accel- eration,
D. Diaz-Guerra, A. Miguel, and J. R. Beltran, “gpuRIR: A python library for room impulse response simulation with GPU accel- eration,”Multimedia Tools and Applications, vol. 80, no. 4, pp. 5653–5671, 2021
2021
-
[38]
C. K. Reddy, V . Gopal, R. Cutler, E. Beyrami, R. Cheng, H. Dubey, S. Matusevych, R. Aichner, A. Aazami, S. Braun et al., “The interspeech 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results,” arXiv preprint arXiv:2005.13981, 2020
-
[39]
Fast multichannel nonnegative matrix factorization with directivity-aware jointly-diagonalizable spatial covariance matri- ces for blind source separation,
K. Sekiguchi, Y . Bando, A. A. Nugraha, K. Yoshii, and T. Kawa- hara, “Fast multichannel nonnegative matrix factorization with directivity-aware jointly-diagonalizable spatial covariance matri- ces for blind source separation,”IEEE/ACM Trans. ASLP, vol. 28, pp. 2610–2625, 2020
2020
-
[40]
and Balam, Jagadeesh and Ginsburg, Boris , month = dec, year =
T. Park, I. Medennikov, K. Dhawan, W. Wang, H. Huang, N. R. Koluguri, K. C. Puvvada, J. Balam, and B. Ginsburg, “Sortformer: A novel approach for permutation-resolved speaker supervision in speech-to-text systems,”arXiv preprint arXiv:2409.06656, 2024
-
[41]
GPU-accelerated guided source separation for meeting transcription,
D. Raj, D. Povey, and S. Khudanpur, “GPU-accelerated guided source separation for meeting transcription,”arXiv preprint arXiv:2212.05271, 2022
-
[42]
Robust speech recognition via large-scale weak supervision,
A. Radfordet al., “Robust speech recognition via large-scale weak supervision,” 2022
2022
-
[43]
Silero V AD: pre-trained enterprise-grade voice activity detector (V AD), number detector and language classifier,
S. Team, “Silero V AD: pre-trained enterprise-grade voice activity detector (V AD), number detector and language classifier,” https: //github.com/snakers4/silero-vad, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.