Energy-Efficient Multimodal Inference Serving with Tri-serve
Pith reviewed 2026-07-01 06:25 UTC · model grok-4.3
The pith
Tri-serve delivers 22% better energy efficiency for multimodal inference on GPUs by fixing three classes of power waste without any latency or throughput penalty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
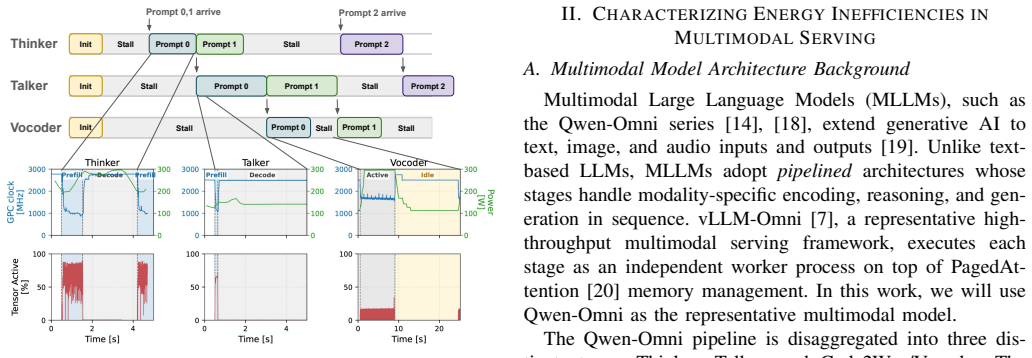
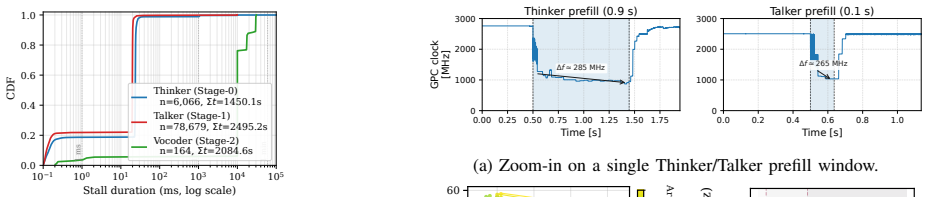
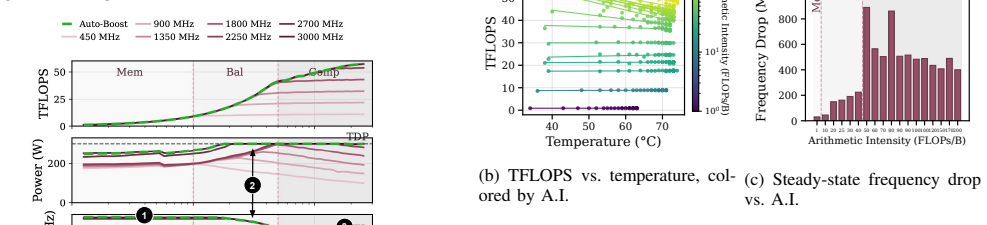
Tri-serve, a software-based DVFS controller, jointly accounts for inter-stage dependency stalls, the arithmetic-intensity effect on frequency and power, and the thermal-throttling effect of high A.I. phases to achieve 22% energy efficiency improvement in multimodal inference serving with no impacts on latency or throughput.
What carries the argument
Tri-serve software DVFS controller that monitors and adjusts for dependency stalls, arithmetic intensity mismatches, and thermal effects to optimize frequency and power.
If this is right
- Multimodal inference serving systems can achieve higher energy efficiency on current GPU hardware.
- Software overrides can effectively manage power where hardware PMUs fall short.
- Energy savings are possible without trading off performance in real-time serving scenarios.
- Commodity GPUs become more viable for energy-constrained multimodal deployments.
Where Pith is reading between the lines
- Similar controllers could be developed for other types of AI inference workloads that have pipeline stages.
- Integration with cluster-level schedulers might amplify the energy benefits across multiple servers.
- Long-term, this suggests hardware PMUs could be improved by exposing more control to software for AI-specific patterns.
Load-bearing premise
The three classes of inefficiency are the main sources of power waste in multimodal inference and a software controller can fix them without adding overhead or needing hardware modifications.
What would settle it
Running Tri-serve on a multimodal inference workload and measuring no reduction in energy use or an increase in latency or drop in throughput would falsify the claim.
Figures




read the original abstract
Multimodal model inference creates substantial energy demand with growing performance requirements. Within GPUs, power is autonomously managed by an on-board power management unit (PMU), which makes frequency boosting/throttling decisions. However, we find that these hardware-managed frequency decisions can cause significant power inefficiency. This work identifies three classes of power inefficiencies within modern multimodal inference serving: (1) inter-stage dependency stalls run at near maximum frequency despite being idle; (2) anti-correlation between auto-boost frequency and arithmetic intensity (A.I.) results in compute-bound phases (e.g., prefill) running at lower frequency and vice versa; and (3) thermal throttling degrades SM frequency and throughput. We propose Tri-serve, a software-based DVFS controller that jointly accounts for three classes of inefficiency -- inter-stage Dependency stalls, the Arithmetic-intensity effect on frequency and power, and the Thermal-throttling effect of high A.I. phases -- to deliver energy-efficient multimodal serving on commodity GPUs. We show that Tri-serve achieves 22% energy efficiency improvement with no latency or throughput impacts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies three classes of power inefficiencies in GPU hardware PMU frequency management for multimodal inference serving—(1) inter-stage dependency stalls running at near-max frequency while idle, (2) anti-correlation between arithmetic intensity and auto-boost frequency, and (3) thermal throttling during high-A.I. phases—and proposes Tri-serve, a software-only DVFS controller that jointly corrects for dependency stalls, A.I.-frequency effects, and thermal throttling. It reports that this yields a 22% energy-efficiency improvement with no measurable latency or throughput penalty on commodity GPUs.
Significance. If the empirical claims are substantiated with detailed experiments, the result would be significant for energy-efficient inference serving: it offers a deployable software intervention that realigns hardware frequency decisions with multimodal workload structure without hardware changes or performance cost, directly addressing rising power demands in data-center multimodal serving.
major comments (1)
- [Abstract] Abstract: the central claim of a 22% energy-efficiency gain 'with no latency or throughput impacts' is presented as a measured outcome, yet the abstract supplies no experimental setup, baselines, workload traces, measurement methodology, or microbenchmarks isolating controller overhead. This is load-bearing because the no-overhead guarantee for the real-time DVFS loop is required to support the efficiency result; without explicit fixed-frequency comparisons or cycle-accounting data, the claim cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of Tri-serve's significance for energy-efficient multimodal serving. We address the single major comment on the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 22% energy-efficiency gain 'with no latency or throughput impacts' is presented as a measured outcome, yet the abstract supplies no experimental setup, baselines, workload traces, measurement methodology, or microbenchmarks isolating controller overhead. This is load-bearing because the no-overhead guarantee for the real-time DVFS loop is required to support the efficiency result; without explicit fixed-frequency comparisons or cycle-accounting data, the claim cannot be evaluated.
Authors: We acknowledge that the abstract is intentionally concise and omits explicit experimental details. The full manuscript (Sections 4–6) supplies the requested information: evaluation uses production multimodal traces on A100/H100 GPUs, compares against fixed-frequency baselines and stock DVFS, reports cycle-accounting and PMU telemetry for controller overhead (<0.5% latency), and isolates each of the three inefficiency classes via microbenchmarks. We will revise the abstract to add one sentence summarizing the evaluation platform, workloads, and overhead result so the central claim can be evaluated from the abstract alone. revision: yes
Circularity Check
No significant circularity; empirical measurement of controller performance.
full rationale
The paper identifies three classes of GPU power inefficiency through observation and evaluates a software DVFS controller (Tri-serve) via direct experimentation on commodity hardware. The 22% efficiency claim is presented as a measured outcome of the controller, with no equations, fitted parameters, self-citations, or ansatzes that reduce any prediction or result to its own inputs by construction. The derivation chain consists of empirical identification followed by system implementation and benchmarking, which is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Claude code: Agentic coding in the terminal,
Anthropic, “Claude code: Agentic coding in the terminal,” https://www. anthropic.com/claude-code, 2025, accessed: 2026-04-30
2025
-
[2]
Cursor: The AI code editor,
Anysphere, “Cursor: The AI code editor,” https://www.cursor.com, 2024, accessed: 2026-04-30
2024
-
[3]
Openai codex: A cloud-based software engineering agent,
OpenAI, “Openai codex: A cloud-based software engineering agent,” https://openai.com/codex, 2025, accessed: 2026-04-30
2025
-
[4]
OpenClaw: An open-source conversational AI assistant,
OpenClaw, “OpenClaw: An open-source conversational AI assistant,” https://openclaw.ai, 2024, accessed: 2026-04-30
2024
-
[5]
Introducing ChatGPT,
OpenAI, “Introducing ChatGPT,” https://openai.com/blog/chatgpt, 2022, accessed: 2026-04-30
2022
-
[6]
Gemini: A family of highly capable multimodal models,
Google DeepMind, “Gemini: A family of highly capable multimodal models,” https://deepmind.google/technologies/gemini/, 2023, accessed: 2026-04-30
2023
-
[7]
vllm-omni: Fully disaggregated serving for any-to-any multimodal models,
P. Yin, J. Zhu, H. Gao, C. Zheng, Y . Huanget al., “vllm-omni: Fully disaggregated serving for any-to-any multimodal models,”arXiv preprint arXiv:2602.02204, 2026
arXiv 2026
-
[8]
Char- acterizing power management opportunities for llms in the cloud,
P. Patel, E. Choukse, C. Zhang, I. n. Goiri, B. Warrieret al., “Char- acterizing power management opportunities for llms in the cloud,” in Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ser. ASPLOS ’24, 2024, p. 207–222
2024
-
[9]
Slo-aware gpu dvfs for energy-efficient llm inference serving,
A. K. Kakolyris, D. Masouros, S. Xydis, and D. Soudris, “Slo-aware gpu dvfs for energy-efficient llm inference serving,”IEEE Computer Architecture Letters, vol. 23, pp. 150–153, 2024
2024
-
[10]
Power-aware deep learning model serving withµ-Serve,
H. Qiu, W. Mao, A. Patke, S. Cui, S. Jhaet al., “Power-aware deep learning model serving withµ-Serve,” in2024 USENIX Annual Technical Conference (USENIX ATC 24), Jul. 2024, pp. 75–93
2024
-
[11]
throttll’em: Predictive gpu throttling for energy efficient llm inference serving,
A. K. Kakolyris, D. Masouros, P. Vavaroutsos, S. Xydis, and D. Soudris, “throttll’em: Predictive gpu throttling for energy efficient llm inference serving,” in2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2025, pp. 1363–1378
2025
-
[12]
Qwen2. 5-coder technical report,
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liuet al., “Qwen2. 5-coder technical report,”arXiv preprint arXiv:2409.12186, 2024
Pith/arXiv arXiv 2024
-
[13]
A. Yang, A. Li, B. Yang, B. Zhang, B. Huiet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[14]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wanget al., “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025
Pith/arXiv arXiv 2025
-
[15]
An integrated gpu power and performance model,
S. Hong and H. Kim, “An integrated gpu power and performance model,” inProceedings of the 37th Annual International Symposium on Computer Architecture, ser. ISCA ’10, 2010, p. 280–289
2010
-
[16]
Gpgpu power modeling for multi-domain voltage-frequency scaling,
J. Guerreiro, A. Ilic, N. Roma, and P. Tomas, “Gpgpu power modeling for multi-domain voltage-frequency scaling,” in2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2018, pp. 789–800
2018
-
[17]
Leakage temperature dependency mod- eling in system level analysis,
H. Huang, G. Quan, and J. Fan, “Leakage temperature dependency mod- eling in system level analysis,” in2010 11th International Symposium on Quality Electronic Design (ISQED), 2010, pp. 447–452
2010
-
[18]
Qwen3.5-omni technical report,
Q. Team, “Qwen3.5-omni technical report,”arXiv preprint arXiv:2604.15804, 2026
Pith/arXiv arXiv 2026
-
[19]
Mme-unify: A comprehensive benchmark for unified multimodal understanding and generation models,
W. Xie, Y .-F. Zhang, C. Fu, Y . Shi, B. Nieet al., “Mme-unify: A comprehensive benchmark for unified multimodal understanding and generation models,”arXiv preprint arXiv:2504.03641, 2025
arXiv 2025
-
[20]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zhenget al., “Efficient memory management for large language model serving with pagedattention,” in Proceedings of the 29th Symposium on Operating Systems Principles, ser. SOSP ’23, 2023, p. 611–626
2023
-
[21]
The energy cost of execution-idle in gpu clusters,
Y . Lei, J. Fernandez, V . Kypriotis, D. Skarlatos, E. Strubellet al., “The energy cost of execution-idle in gpu clusters,”arXiv preprint arXiv:2604.04745, 2026
Pith/arXiv arXiv 2026
-
[22]
Pccl: Energy-efficient llm training with power-aware collective communication,
Z. Jia, L. N. Bhuyan, and D. Wong, “Pccl: Energy-efficient llm training with power-aware collective communication,” in2024 IEEE 42nd Inter- national Conference on Computer Design (ICCD), 2024, pp. 84–91
2024
-
[23]
Towards improved power management in cloud gpus,
P. Patel, Z. Gong, S. Rizvi, E. Choukse, P. Misraet al., “Towards improved power management in cloud gpus,”IEEE Comput. Archit. Lett., vol. 22, p. 141–144, Jul. 2023
2023
-
[24]
Roofline: an insightful visual performance model for multicore architectures,
S. Williams, A. Waterman, and D. Patterson, “Roofline: an insightful visual performance model for multicore architectures,”Communications of the ACM, vol. 52, pp. 65–76, 2009
2009
-
[25]
Nvidia nsight compute: Gpu profiler,
NVIDIA, “Nvidia nsight compute: Gpu profiler,” https://docs.nvidia.com/nsight-compute/, 2024
2024
-
[26]
Seed-tts: A family of high-quality versatile speech generation models,
P. Anastassiou, J. Chen, J. Chen, Y . Chen, Z. Chenet al., “Seed-tts: A family of high-quality versatile speech generation models,”arXiv preprint arXiv:2406.02430, 2024
Pith/arXiv arXiv 2024
-
[27]
Orca: A distributed serving system for Transformer-Based generative models,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun, “Orca: A distributed serving system for Transformer-Based generative models,” in 16th USENIX Symposium on Operating Systems Design and Implemen- tation (OSDI 22), Jul. 2022, pp. 521–538
2022
-
[28]
Taming Throughput-Latency tradeoff in LLM inference with Sarathi-Serve,
A. Agrawal, N. Kedia, A. Panwar, J. Mohan, N. Kwatraet al., “Taming Throughput-Latency tradeoff in LLM inference with Sarathi-Serve,” in 18th USENIX Symposium on Operating Systems Design and Implemen- tation (OSDI 24), Jul. 2024, pp. 117–134
2024
-
[29]
AlpaServe: Statistical multiplexing with model parallelism for deep learning serving,
Z. Li, L. Zheng, Y . Zhong, V . Liu, Y . Shenget al., “AlpaServe: Statistical multiplexing with model parallelism for deep learning serving,” in17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23), Jul. 2023, pp. 663–679
2023
-
[30]
DistServe: Disaggre- gating prefill and decoding for goodput-optimized large language model serving,
Y . Zhong, S. Liu, J. Chen, J. Hu, Y . Zhuet al., “DistServe: Disaggre- gating prefill and decoding for goodput-optimized large language model serving,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 2024, pp. 193–210
2024
-
[31]
Powerinfer: Fast large language model serving with a consumer-grade gpu,
Y . Song, Z. Mi, H. Xie, and H. Chen, “Powerinfer: Fast large language model serving with a consumer-grade gpu,” inProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles, ser. SOSP ’24, 2024, p. 590–606
2024
-
[32]
Towards sustainable ai: a comprehensive framework for green ai,
A. Tabbakh, L. Al Amin, M. Islam, G. I. Mahmud, I. K. Chowdhury et al., “Towards sustainable ai: a comprehensive framework for green ai,”Discover Sustainability, vol. 5, p. 408, 2024
2024
-
[33]
Hotspot: a compact thermal modeling methodology for early- stage vlsi design,
W. Huang, S. Ghosh, S. Velusamy, K. Sankaranarayanan, K. Skadron et al., “Hotspot: a compact thermal modeling methodology for early- stage vlsi design,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 14, pp. 501–513, 2006
2006
-
[34]
Roofline-aware dvfs for gpus,
C. Nugteren, G.-J. van den Braak, and H. Corporaal, “Roofline-aware dvfs for gpus,” inProceedings of International Workshop on Adaptive Self-tuning Computing Systems, 2014, pp. 8–10
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.