TACO: Tool-Augmented Credit Optimization for Agentic Tool Use
Pith reviewed 2026-06-30 03:50 UTC · model grok-4.3
The pith
TACO credits each tool call by the difference it makes to final answer accuracy using inserted probe tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
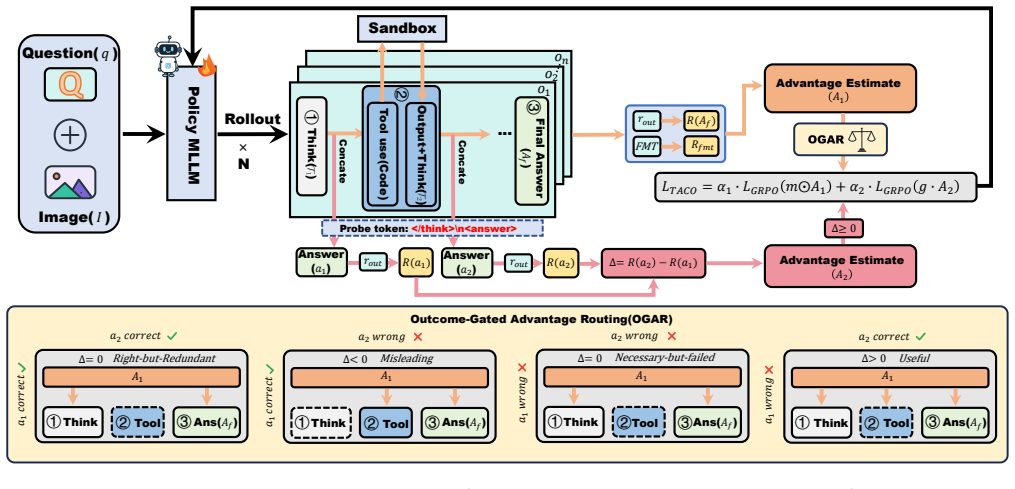
TACO is a GRPO variant built on Differential Answer-Probe Reward, which computes a self-supervised advantage for each tool call as the difference in outcome reward between predictions with and without the call, and Outcome-Gated Advantage Routing, which routes the final-answer advantage only to responsible segments when the call is useful. The two channels together allow the model to receive positive credit for helpful calls, negative credit for misleading ones, and zero for redundant ones, all while reusing the existing answer checker.
What carries the argument
Differential Answer-Probe Reward (DAPR) paired with Outcome-Gated Advantage Routing (OGAR) as two coupled advantage channels inside a GRPO training loop.
If this is right
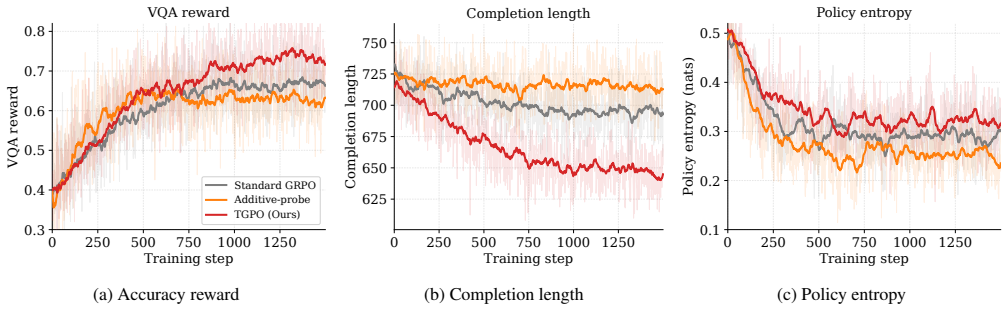
- Models reach higher accuracy on perception, reasoning, and general multimodal benchmarks.
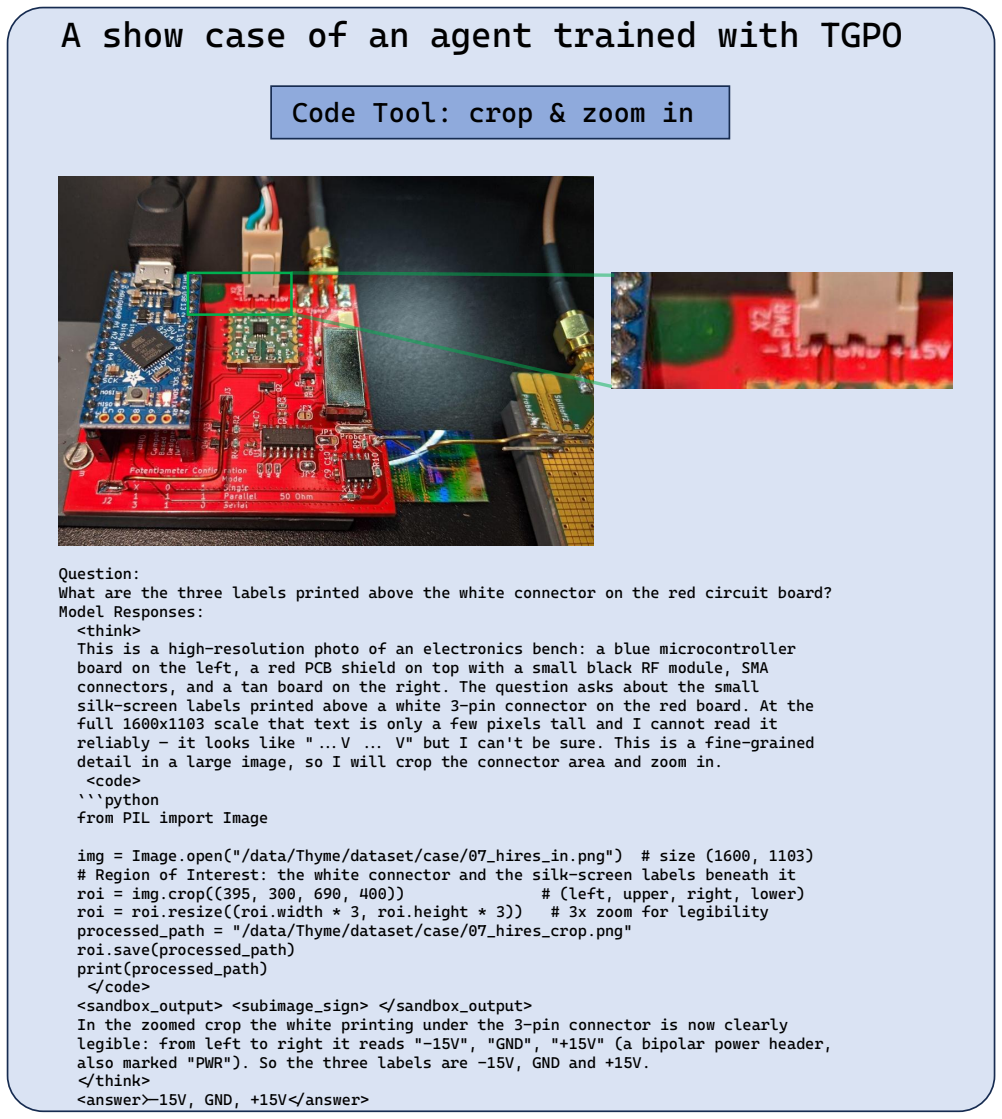
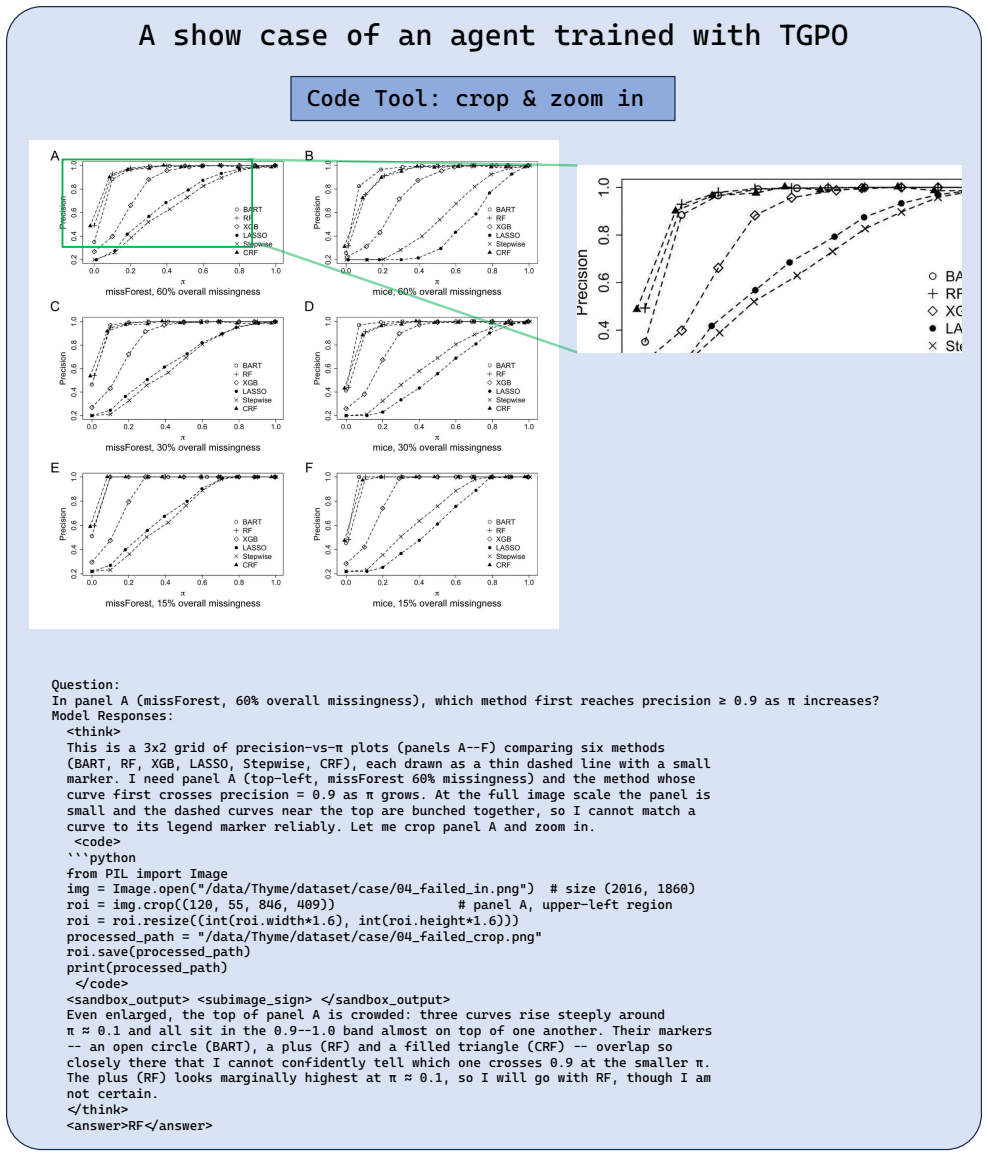
- Agents learn to invoke tools only when the calls improve the final answer.
- Credit assignment requires no auxiliary judge model or added parameters.
- Training proceeds through a two-stage SFT followed by RL pipeline.
Where Pith is reading between the lines
- The same probe-difference idea could be tested on non-code tools if an outcome checker is available.
- Selective tool invocation may lower average compute cost per query in deployed agent systems.
- The approach suggests a general route for self-supervised credit assignment in any agent that produces intermediate actions with measurable outcome effects.
Load-bearing premise
The difference in outcome reward produced by probe tokens accurately isolates each tool call's contribution and stays robust to any attempt to manipulate the probes.
What would settle it
An experiment in which accuracy gains disappear once probe tokens are removed from training or in which the model begins receiving positive credit for calls that demonstrably lower answer quality.
Figures



read the original abstract
Agentic multimodal models perform diverse operations on an image via code and reason over the returned view, an effective paradigm for fine-grained visual question answering. However, code operations can be useful, redundant, or misleading. Outcome-only rewards cannot precisely distinguish these cases, and existing process rewards either fail to attribute final correctness to individual tool calls, or require an external judge model. To address this, we introduce Tool-Augmented Credit Optimization (TACO), a GRPO variant for code-tool agents built on two coupled advantage channels. The first, Differential Answer-Probe Reward (DAPR), is a self-supervised, judge-free tool-contribution advantage that credits each tool call by its own effect on answering correctly. Probe tokens inserted into the model's reasoning elicit its predictions with and without the tool, and the difference in outcome reward is taken as the call's value: positive for a useful call, negative for a misleading one, and zero for one that changes nothing. This reuses the existing answer checker with no auxiliary judge, and, being a difference rather than an absolute probe score, is naturally robust to probe-hacking. The second is the outcome advantage from the final answer, distributed by Outcome-Gated Advantage Routing (OGAR): a parameter-free rule that, conditioned on the call's outcome, delivers this credit only to the responsible segments, suppressing wasted tool calls without any cost term. We train TACO through a two-stage SFT+RL pipeline. Extensive experiments across perception, reasoning, and general multimodal benchmarks show that it yields consistent accuracy gains and learns to invoke its tools only when they help.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TACO, a GRPO variant for training agentic multimodal models that use code tools on images. It defines two coupled advantage channels: DAPR, a self-supervised tool-contribution signal computed as the difference in outcome reward between probe-elicited predictions with and without each tool call, and OGAR, a parameter-free rule that routes final-answer outcome advantage only to responsible reasoning segments. A two-stage SFT+RL pipeline is used, with claims of consistent accuracy gains and selective tool invocation across perception, reasoning, and multimodal benchmarks.
Significance. If the central claims hold, TACO would offer a judge-free and parameter-free mechanism for precise credit assignment to individual tool calls, addressing a key limitation in outcome-only or external-judge process rewards for tool-augmented agents. The reuse of the existing answer checker and the differencing approach for robustness are notable strengths that could improve efficiency in agentic multimodal systems.
major comments (2)
- [DAPR component] DAPR description: the claim that probe insertion yields a clean marginal contribution via differencing assumes that the probe tokens do not independently alter attention patterns, token probabilities, or subsequent reasoning dynamics even in the counterfactual (no-tool) case. If insertion itself changes the trajectory, the reward difference no longer isolates the tool call's effect; this assumption is load-bearing for the tool-value estimation and requires explicit justification or controls.
- [OGAR component] OGAR description: the exact conditioning rule and segment-identification logic for routing outcome advantage to 'responsible segments' are unspecified, making it impossible to verify whether the method avoids crediting unrelated reasoning or introduces hidden biases while remaining parameter-free. This is central to the claim of suppressing wasted tool calls.
minor comments (1)
- The abstract would benefit from a brief statement of the base GRPO objective and how the two advantage channels are combined in the policy gradient.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [DAPR component] DAPR description: the claim that probe insertion yields a clean marginal contribution via differencing assumes that the probe tokens do not independently alter attention patterns, token probabilities, or subsequent reasoning dynamics even in the counterfactual (no-tool) case. If insertion itself changes the trajectory, the reward difference no longer isolates the tool call's effect; this assumption is load-bearing for the tool-value estimation and requires explicit justification or controls.
Authors: We agree this assumption requires explicit support. The manuscript emphasizes robustness via differencing rather than absolute scores, but does not provide dedicated controls for probe-induced trajectory shifts. In revision we will add an analysis subsection with empirical checks (e.g., trajectory divergence metrics and isolated-probe ablations) to quantify and bound any such effects, thereby strengthening the justification for the marginal-contribution claim. revision: partial
-
Referee: [OGAR component] OGAR description: the exact conditioning rule and segment-identification logic for routing outcome advantage to 'responsible segments' are unspecified, making it impossible to verify whether the method avoids crediting unrelated reasoning or introduces hidden biases while remaining parameter-free. This is central to the claim of suppressing wasted tool calls.
Authors: The referee is correct that the current manuscript leaves the precise conditioning rule and segment-identification procedure underspecified. We will revise the methods section to include the full algorithmic description: outcome advantage is routed exclusively to the contiguous reasoning segment immediately preceding a tool call when the final answer is correct and the tool call is the last one before the answer; otherwise the advantage is zeroed for that call. This rule is parameter-free and will be presented with pseudocode to allow verification that unrelated segments receive no credit. revision: yes
Circularity Check
No circularity in TACO derivation chain
full rationale
The paper introduces TACO as a GRPO variant whose two core components (DAPR and OGAR) are explicitly defined as new constructions: DAPR computes tool value via explicit differencing of outcome rewards on probe-inserted trajectories, and OGAR applies a parameter-free routing rule conditioned on call outcome. Neither component is shown to reduce by construction to its own inputs, fitted parameters renamed as predictions, or load-bearing self-citations. The abstract and description treat the answer checker as an external reuse and present robustness via differencing as a direct consequence of the definition, with empirical validation on benchmarks rather than tautological equivalence. No self-citation chains or uniqueness theorems imported from prior author work appear in the load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GRPO provides a suitable base algorithm for tool-augmented credit assignment
invented entities (2)
-
DAPR (Differential Answer-Probe Reward)
no independent evidence
-
OGAR (Outcome-Gated Advantage Routing)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Xiangwei Wang and Wei Wang and Ken Chen and Nanduni Nimalsiri and Saman Halgamuge , journal =
-
[2]
Hasegawa-Johnson and Chang D
Eunseop Yoon and Hee Suk Yoon and Jaehyun Jang and SooHwan Eom and Qi Dai and Chong Luo and Mark A. Hasegawa-Johnson and Chang D. Yoo , journal =
-
[4]
Fei Wu and Zhenrong Zhang and Qikai Chang and Jianshu Zhang and Quan Liu and Jun Du , journal =
-
[5]
Senkang Hu and Yong Dai and Xudong Han and Zhengru Fang and Yuzhi Zhao and Sam Tak Wu Kwong and Yuguang Fang , journal =
-
[6]
Zhicong Lu and Zichuan Lin and Wei Jia and Changyuan Tian and Deheng Ye and Peiguang Li and Li Jin and Nayu Liu and Guangluan Xu and Wei Feng , journal =
-
[7]
Keon Kim and Krish Chelikavada , journal =
-
[8]
2026 , note =
Yan Ma and Weiyu Zhang and Tianle Li and Linge Du and Xuyang Shen and Pengfei Liu , journal =. 2026 , note =
2026
-
[9]
The Fourteenth International Conference on Learning Representations , year=
Thyme: Think Beyond Images , author=. The Fourteenth International Conference on Learning Representations , year=
-
[10]
Shilin Yan and Jintao Tong and Hongwei Xue and Xiaojun Tang and Yangyang Wang and Kunyu Shi and Guannan Zhang and Ruixuan Li and Yixiong Zou , journal =
-
[11]
The Fourteenth International Conference on Learning Representations , year=
DeepEyes: Incentivizing ''Thinking with Images'' via Reinforcement Learning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[12]
The Fourteenth International Conference on Learning Representations , year=
DeepEyesV2: Toward Agentic Multimodal Model , author=. The Fourteenth International Conference on Learning Representations , year=
-
[13]
2025 , eprint=
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning , author=. 2025 , eprint=
2025
-
[14]
The Fourteenth International Conference on Learning Representations , year=
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search , author=. The Fourteenth International Conference on Learning Representations , year=
-
[15]
2026 , eprint=
PyVision-RL: Forging Open Agentic Vision Models via RL , author=. 2026 , eprint=
2026
-
[16]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Mathcoder-vl: Bridging vision and code for enhanced multimodal mathematical reasoning , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[17]
International Conference on Machine Learning , year=
Reliable Thinking with Images , author=. International Conference on Machine Learning , year=
-
[18]
Jiaqi Liu and Kaiwen Xiong and Peng Xia and Yiyang Zhou and Haonian Ji and Lu Feng and Siwei Han and Mingyu Ding and Huaxiu Yao , journal =
-
[19]
Jinyang Wu and Chonghua Liao and Mingkuan Feng and Shuai Zhang and Zhengqi Wen and Haoran Luo and Ling Yang and Huazhe Xu and Jianhua Tao , journal =
-
[20]
2025 , eprint=
Tulu 3: Pushing Frontiers in Open Language Model Post-Training , author=. 2025 , eprint=
2025
-
[24]
2025 , howpublished =
2025
-
[25]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[26]
International Conference on Machine Learning (ICML) , pages =
Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping , author =. International Conference on Machine Learning (ICML) , pages =
-
[27]
Quan Wei and Siliang Zeng and Chenliang Li and William Brown and Oana Frunza and Wei Deng and Anderson Schneider and Yuriy Nevmyvaka and Yang Katie Zhao and Alfredo Garcia and Mingyi Hong , journal =
-
[28]
2026 , eprint=
DeepAgent: A General Reasoning Agent with Scalable Toolsets , author=. 2026 , eprint=
2026
-
[29]
2025 , eprint=
SoTA with Less: MCTS-Guided Sample Selection for Data-Efficient Visual Reasoning Self-Improvement , author=. 2025 , eprint=
2025
-
[30]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[31]
International Conference on Learning Representations , volume=
Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans? , author=. International Conference on Learning Representations , volume=
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
V?: Guided visual search as a core mechanism in multimodal llms , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
Advances in Neural Information Processing Systems , volume=
Measuring multimodal mathematical reasoning with math-vision dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
International Conference on Learning Representations , volume=
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts , author=. International Conference on Learning Representations , volume=
-
[35]
European Conference on Computer Vision , pages=
Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[36]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
We-math: Does your large multimodal model achieve human-like mathematical reasoning? , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[38]
Advances in Neural Information Processing Systems , volume=
Are we on the right way for evaluating large vision-language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Findings of the association for computational linguistics: ACL 2022 , pages=
Chartqa: A benchmark for question answering about charts with visual and logical reasoning , author=. Findings of the association for computational linguistics: ACL 2022 , pages=
2022
-
[40]
European Conference on Computer Vision , pages=
Blink: Multimodal large language models can see but not perceive , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[44]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Xiao Bi and Haowei Zhang and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , journal =
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Codev: Code with images for faithful visual reasoning via tool-aware policy optimization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[46]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[48]
Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Two-stage regularization-based structured pruning for llms , author=. Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[49]
Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Beyond Examples: Towards Automated Thought-level In-Context Reasoning for Large Language Models , author=. Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[51]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Astar: Boosting multimodal reasoning with automated structured thinking , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[52]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Pandora's box or aladdin's lamp: A comprehensive analysis revealing the role of rag noise in large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[55]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Better, stronger, faster: Tackling the trilemma in mllm-based segmentation with simultaneous textual mask prediction , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[56]
Bai, S.; Cai, Y.; Chen, R.; Chen, K.; Chen, X.; Cheng, Z.; Deng, L.; Ding, W.; Gao, C.; Ge, C.; et al. 2025 a . Qwen3-vl technical report. arXiv preprint arXiv:2511.21631
Pith/arXiv arXiv 2025
-
[57]
Bai, S.; Chen, K.; Liu, X.; Wang, J.; Ge, W.; Song, S.; Dang, K.; Wang, P.; Wang, S.; Tang, J.; Zhong, H.; Zhu, Y.; Yang, M.; Li, Z.; Wan, J.; Wang, P.; Ding, W.; Fu, Z.; Xu, Y.; Ye, J.; Zhang, X.; Xie, T.; Cheng, Z.; Zhang, H.; Yang, Z.; Xu, H.; and Lin, J. 2025 b . Qwen2.5-VL Technical Report. arXiv:2502.13923
Pith/arXiv arXiv 2025
-
[58]
Chen, L.; Li, J.; Dong, X.; Zhang, P.; Zang, Y.; Chen, Z.; Duan, H.; Wang, J.; Qiao, Y.; Lin, D.; et al. 2024. Are we on the right way for evaluating large vision-language models? Advances in Neural Information Processing Systems, 37: 27056--27087
2024
-
[59]
Duan, H.; Yang, J.; Qiao, Y.; Fang, X.; Chen, L.; Liu, Y.; Dong, X.; Zang, Y.; Zhang, P.; Wang, J.; Lin, D.; and Chen, K. 2024. VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models. In Proceedings of the 32nd ACM International Conference on Multimedia, 11198--11201
2024
-
[60]
Feng, M.; Wu, J.; Liu, S.; Zhang, S.; Fang, H.; Jin, R.; Che, F.; Shao, P.; Wen, Z.; and Tao, J. 2026. Two-stage regularization-based structured pruning for llms. In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2996--3012
2026
-
[61]
Feng, M.; Wu, J.; Zhang, S.; Shao, P.; Jin, R.; Wen, Z.; Tao, J.; and Che, F. 2025. Dress: Data-driven regularized structured streamlining for large language models. arXiv preprint arXiv:2501.17905
arXiv 2025
-
[62]
A.; Ma, W.-C.; and Krishna, R
Fu, X.; Hu, Y.; Li, B.; Feng, Y.; Wang, H.; Lin, X.; Roth, D.; Smith, N. A.; Ma, W.-C.; and Krishna, R. 2024. Blink: Multimodal large language models can see but not perceive. In European Conference on Computer Vision, 148--166. Springer
2024
-
[63]
Guo, D.; Yang, D.; Zhang, H.; Song, J.; Wang, P.; Zhu, Q.; Xu, R.; Zhang, R.; Ma, S.; Bi, X.; et al. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
Pith/arXiv arXiv 2025
-
[64]
Hong, J.; Zhao, C.; Zhu, C.; Lu, W.; Xu, G.; and XingYu. 2026. DeepEyesV2: Toward Agentic Multimodal Model. In The Fourteenth International Conference on Learning Representations
2026
-
[65]
C.; and Wang, B
Hou, X.; Xu, S.; Biyani, M.; Li, M.; Liu, J.; Hollon, T. C.; and Wang, B. 2026. Codev: Code with images for faithful visual reasoning via tool-aware policy optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 21500--21510
2026
-
[66]
Hu, S.; Dai, Y.; Han, X.; Fang, Z.; Zhao, Y.; Kwong, S. T. W.; and Fang, Y. 2026. Self-Induced Outcome Potential: Turn-Level Credit Assignment for Agents without Verifiers . arXiv preprint arXiv:2605.04984
Pith/arXiv arXiv 2026
-
[67]
Jin, R.; Shao, P.; Wen, Z.; Wu, J.; Feng, M.; Yang, S.; Zhang, C. Y.; and Tao, J. 2026. Exploring Knowledge Purification in Multi-Teacher Knowledge Distillation for LLMs. arXiv preprint arXiv:2602.01064
Pith/arXiv arXiv 2026
-
[68]
Jin, R.; Shao, P.; Wen, Z.; Wu, J.; Feng, M.; Zhang, S.; and Tao, J. 2025. Radialrouter: Structured representation for efficient and robust large language models routing. arXiv preprint arXiv:2506.03880
arXiv 2025
-
[69]
Kim, K.; and Chelikavada, K. 2026. Zoom Consistency: A Free Confidence Signal in Multi-Step Visual Grounding Pipelines . arXiv preprint arXiv:2604.15376
Pith/arXiv arXiv 2026
-
[70]
Lai, X.; Li, J.; Li, W.; Liu, T.; Li, T.; and Zhao, H. 2026. Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search. In The Fourteenth International Conference on Learning Representations
2026
-
[71]
Li, B.; Zhang, Y.; Guo, D.; Zhang, R.; Li, F.; Zhang, H.; Zhang, K.; Zhang, P.; Li, Y.; Liu, Z.; et al. 2024. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326
Pith/arXiv arXiv 2024
-
[72]
Li, H.; Yang, Y.; Lin, Y.; Dai, X.; Yang, M.; and Peng, X. 2026 a . Reliable Thinking with Images. In International Conference on Machine Learning
2026
-
[73]
Li, X.; Jiao, W.; Jin, J.; Dong, G.; Jin, J.; Wang, Y.; Wang, H.; Zhu, Y.; Wen, J.-R.; Lu, Y.; and Dou, Z. 2026 b . DeepAgent: A General Reasoning Agent with Scalable Toolsets. arXiv:2510.21618
arXiv 2026
-
[74]
Liu, J.; Feng, M.; and Chen, L. 2026. Better, stronger, faster: Tackling the trilemma in mllm-based segmentation with simultaneous textual mask prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 33121--33130
2026
-
[75]
Liu, J.; Xiong, K.; Xia, P.; Zhou, Y.; Ji, H.; Feng, L.; Han, S.; Ding, M.; and Yao, H. 2025. Agent0-VL: Exploring Self-Evolving Agent for Tool-Integrated Vision-Language Reasoning . arXiv preprint arXiv:2511.19900
arXiv 2025
-
[76]
Lu, P.; Bansal, H.; Xia, T.; Liu, J.; Li, C.; Hajishirzi, H.; Cheng, H.; Chang, K.-W.; Galley, M.; and Gao, J. 2024. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. In International Conference on Learning Representations, volume 2024, 23439--23554
2024
-
[77]
Lu, Z.; Lin, Z.; Jia, W.; Tian, C.; Ye, D.; Li, P.; Jin, L.; Liu, N.; Xu, G.; and Feng, W. 2026. HISR: Hindsight Information Modulated Segmental Process Rewards for Multi-turn Agentic Reinforcement Learning . arXiv preprint arXiv:2603.18683
arXiv 2026
-
[78]
Ma, Y.; Zhang, W.; Li, T.; Du, L.; Shen, X.; and Liu, P. 2026. What Does Vision Tool-Use Reinforcement Learning Really Learn? Disentangling Tool-Induced and Intrinsic Effects for Crop-and-Zoom . arXiv preprint arXiv:2602.01334. ICML 2026
Pith/arXiv arXiv 2026
-
[79]
L.; Tan, J
Masry, A.; Do, X. L.; Tan, J. Q.; Joty, S.; and Hoque, E. 2022. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In Findings of the association for computational linguistics: ACL 2022, 2263--2279
2022
-
[80]
Y.; Harada, D.; and Russell, S
Ng, A. Y.; Harada, D.; and Russell, S. 1999. Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping. In International Conference on Machine Learning (ICML), 278--287
1999
-
[81]
OpenAI . 2025. Thinking with Images . https://openai.com/index/thinking-with-images/
2025
-
[82]
Qi, Y.; Fu, P.; Li, H.; Liu, Y.; Jiang, C.; Qin, B.; Luo, Z.; and Luan, J. 2026. Patchcue: Enhancing vision-language model reasoning with patch-based visual cues. arXiv preprint arXiv:2603.05869
arXiv 2026
-
[83]
Qiao, R.; Tan, Q.; Dong, G.; MinhuiWu, M.; Sun, C.; Song, X.; Wang, J.; Gongque, Z.; Lei, S.; Zhang, Y.; et al. 2025. We-math: Does your large multimodal model achieve human-like mathematical reasoning? In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 20023--20070
2025
-
[84]
Shao, Z.; Wang, P.; Zhu, Q.; Xu, R.; Song, J.; Bi, X.; Zhang, H.; Zhang, M.; Li, Y. K.; Wu, Y.; and Guo, D. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models . arXiv preprint arXiv:2402.03300
Pith/arXiv arXiv 2024
-
[85]
Team, K.; Bai, T.; Bai, Y.; Bao, Y.; Cai, S.; Cao, Y.; Charles, Y.; Che, H.; Chen, C.; Chen, G.; et al. 2026. Kimi K2. 5: Visual Agentic Intelligence. arXiv preprint arXiv:2602.02276
Pith/arXiv arXiv 2026
-
[86]
Team, K.; Du, A.; Gao, B.; Xing, B.; Jiang, C.; Chen, C.; Li, C.; Xiao, C.; Du, C.; Liao, C.; et al. 2025. Kimi k1. 5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599
Pith/arXiv arXiv 2025
-
[87]
Wang, H.; Su, A.; Ren, W.; Lin, F.; and Chen, W. 2025 a . Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning. arXiv:2505.15966
Pith/arXiv arXiv 2025
-
[88]
Wang, K.; Pan, J.; Shi, W.; Lu, Z.; Ren, H.; Zhou, A.; Zhan, M.; and Li, H. 2024. Measuring multimodal mathematical reasoning with math-vision dataset. Advances in Neural Information Processing Systems, 37: 95095--95169
2024
-
[89]
Wang, K.; Pan, J.; Wei, L.; Zhou, A.; Shi, W.; Lu, Z.; Xiao, H.; Yang, Y.; Ren, H.; Zhan, M.; et al. 2025 b . Mathcoder-vl: Bridging vision and code for enhanced multimodal mathematical reasoning. In Findings of the Association for Computational Linguistics: ACL 2025, 2505--2534
2025
-
[90]
Wang, W.; Ding, L.; Zeng, M.; Zhou, X.; Shen, L.; Luo, Y.; Yu, W.; and Tao, D. 2025 c . Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, 7907--7915
2025
-
[91]
Wang, X.; Wang, W.; Chen, K.; Nimalsiri, N.; and Halgamuge, S. 2026. Discovering Process-Outcome Credit in Multi-Step LLM Reasoning . arXiv preprint arXiv:2602.01034
arXiv 2026
-
[92]
Wei, Q.; Zeng, S.; Li, C.; Brown, W.; Frunza, O.; Deng, W.; Schneider, A.; Nevmyvaka, Y.; Zhao, Y. K.; Garcia, A.; and Hong, M. 2025. Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Reward Design . arXiv preprint arXiv:2505.11821
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.