Energy-Aware Scheduling for Serverless LLM Serving on Shared GPUs
Pith reviewed 2026-06-30 03:38 UTC · model grok-4.3
The pith
Festina reduces energy consumption for serverless LLM serving by up to 56% while keeping SLOs within 2%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
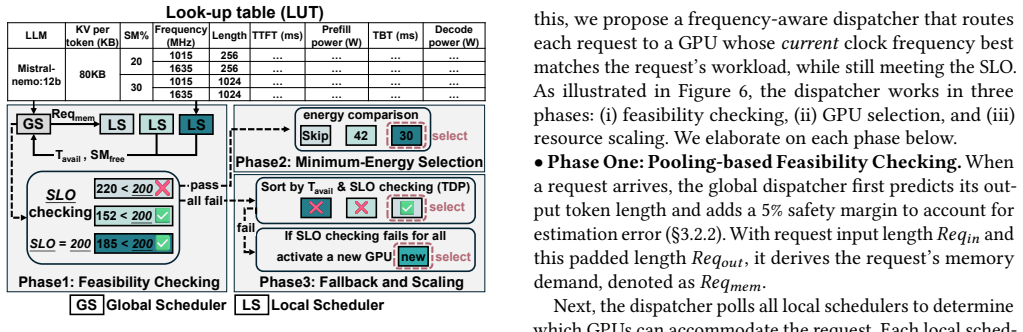
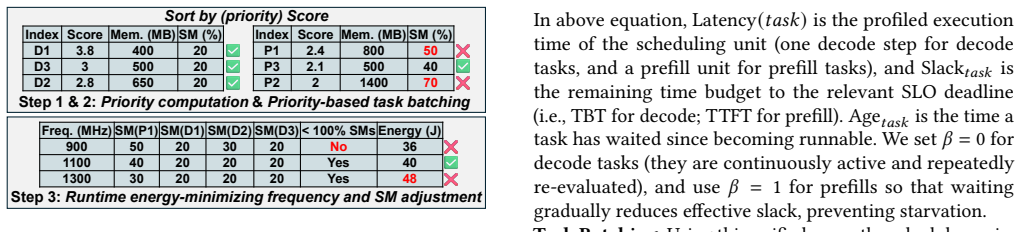
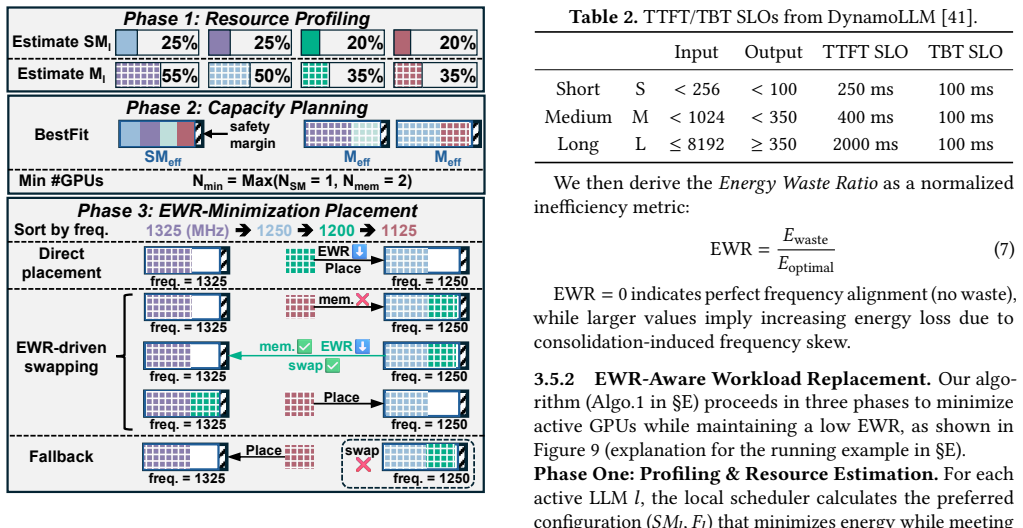
Festina is a system that makes energy-first scheduling decisions by jointly coordinating request placement, runtime resource adaptation, and workload consolidation. A lightweight global scheduler performs fast SLO-safe energy-aware placement using constant-time lookups from offline profiles and GPU state summaries. On each GPU, a phase-aware local scheduler adapts task batching and compute resources to minimize power, and energy-aware consolidation reduces static power via SLO-aware migration.
What carries the argument
The profiling-guided joint coordination of global energy-aware placement, phase-aware local resource adaptation, and SLO-aware workload consolidation.
If this is right
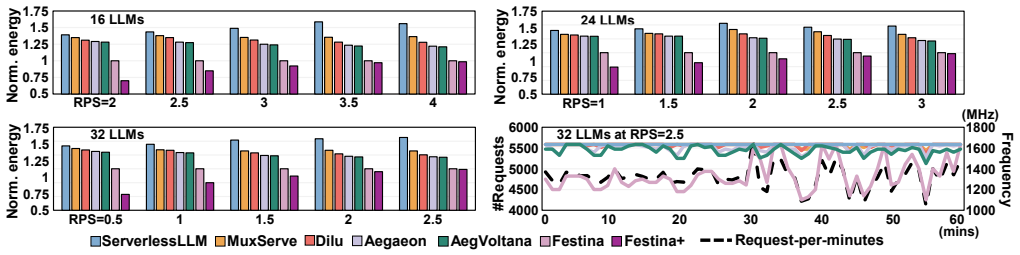
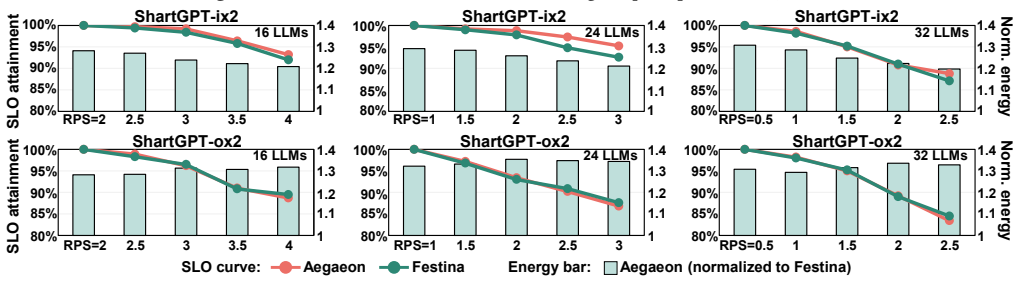
- Festina achieves up to 56% lower energy use compared to four state-of-the-art LLM serving systems.
- It maintains SLO attainment parity within a 2% margin.
- Lightweight global placement decisions remain fast and safe using constant-time lookups.
- Phase-aware local scheduling adapts to execution phases to cut power consumption.
- Workload consolidation via migration lowers static power on underutilized GPUs.
Where Pith is reading between the lines
- If the approach scales, it could influence energy policies in multi-tenant GPU clusters beyond LLMs.
- Hardware designs might incorporate better support for dynamic SM partitioning and DVFS under shared workloads.
- Similar profiling techniques could extend to other elastic serving systems facing energy constraints.
Load-bearing premise
That offline profiles and GPU state summaries enable constant-time placements that stay both SLO-safe and energy-optimal even as request patterns and co-resident model mixes change over time.
What would settle it
Running the system under rapidly varying request rates and model combinations where energy savings fall below 20% or SLO violations exceed the 2% margin.
Figures








read the original abstract
As LLM inference becomes a major cloud workload, its growing energy footprint makes cluster-wide energy optimization increasingly important. Serverless LLM serving helps platforms absorb traffic volatility by elastically sharing GPU resources across models, but this sharing also makes energy optimization difficult. Multiple co-resident models run under one device-wide operating point, while their resource demands and latency slack change across execution phases and load conditions. As a result, minimizing energy requires coordinated scheduling across request placement, runtime resource adaptation, and workload consolidation. We present Festina, a profiling-guided, power-aware control plane to minimize cluster-wide energy for serverless LLM serving. Unlike common global-local schedulers that focus on throughput or tail latency, Festina makes energy-first decisions by jointly coordinating request placement, SM partitioning, and GPU operating points under TTFT/TBT SLOs. In our system, a lightweight global scheduler performs fast, SLO-safe, energy-aware placement using constant-time lookups from offline profiles and GPU state summaries. On each GPU, a phase-aware local scheduler continuously adapts task batching and compute resources to minimize power consumption. Festina further performs energy-aware workload consolidation to reduce GPUs' static power consumption via SLO-aware migration. Comparison with four SOTA LLM serving systems and one DVFS-augmented system demonstrates that Festina reduces energy consumption by up to 56% while maintaining parity in SLO attainment (within a 2% margin)
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Festina, a profiling-guided power-aware control plane for minimizing cluster-wide energy consumption in serverless LLM serving on shared GPUs. It jointly optimizes request placement, SM partitioning, and GPU operating points under TTFT/TBT SLOs via a lightweight global scheduler that uses constant-time lookups from offline profiles and GPU state summaries, a phase-aware local scheduler for batching and resource adaptation, and SLO-aware migration for workload consolidation. The central empirical claim is that Festina reduces energy consumption by up to 56% relative to four SOTA LLM serving systems and one DVFS-augmented baseline while keeping SLO attainment within a 2% margin.
Significance. If the energy savings and SLO parity claims hold under rigorous evaluation, the work addresses an important and timely problem in distributed systems: energy optimization for elastic, multi-tenant LLM inference workloads whose growing footprint motivates cluster-level power management. The energy-first joint scheduling approach and the combination of offline profiling with online adaptation represent a concrete contribution to the intersection of serverless computing and power-aware systems.
major comments (2)
- [Abstract] Abstract: the central claim of up to 56% energy reduction with ≤2% SLO deviation is load-bearing for the paper's contribution, yet the abstract supplies no experimental methodology, workload traces, hardware configuration, statistical analysis, or description of how offline profiles are generated and validated. This directly prevents assessment of whether the result is robust to the unprofiled request patterns and co-resident model mixes identified as the weakest assumption.
- [Abstract] The energy and SLO claims rest on the global scheduler's constant-time lookups from offline profiles remaining both SLO-safe and energy-optimal under changing load and model mixes, but no information is provided on profile coverage, phase/load shift handling, or misprediction rates. This assumption is load-bearing for the 56% figure and requires concrete evidence (e.g., sensitivity analysis or live trace results) to be credible.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract regarding our evaluation methodology and profile assumptions. We will revise the abstract to incorporate the requested details while preserving its conciseness. Below we address each comment.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of up to 56% energy reduction with ≤2% SLO deviation is load-bearing for the paper's contribution, yet the abstract supplies no experimental methodology, workload traces, hardware configuration, statistical analysis, or description of how offline profiles are generated and validated. This directly prevents assessment of whether the result is robust to the unprofiled request patterns and co-resident model mixes identified as the weakest assumption.
Authors: We agree the abstract should briefly convey the evaluation context to support assessment of the claims. In revision we will add concise statements on the hardware platform (NVIDIA A100 GPUs), workload traces (production-derived serverless LLM request patterns), statistical methods (multiple runs with reported means and variance), and offline profile generation/validation process. This directly addresses the concern about robustness to unprofiled patterns. revision: yes
-
Referee: [Abstract] The energy and SLO claims rest on the global scheduler's constant-time lookups from offline profiles remaining both SLO-safe and energy-optimal under changing load and model mixes, but no information is provided on profile coverage, phase/load shift handling, or misprediction rates. This assumption is load-bearing for the 56% figure and requires concrete evidence (e.g., sensitivity analysis or live trace results) to be credible.
Authors: The manuscript body (Sections 4.2 and 5.3) already details profile coverage across model mixes, phase-aware adaptation for load shifts, and misprediction rates with sensitivity results. To make this evident from the abstract alone, we will insert a short clause summarizing profile validation and live-trace robustness. We maintain that the 56% figure is supported by the full evaluation, but accept that the abstract must foreground this evidence. revision: yes
Circularity Check
No circularity: empirical system evaluation with no internal derivations
full rationale
The paper describes a systems artifact (Festina) whose central claims rest on direct comparisons against four external SOTA LLM serving systems plus one DVFS baseline. No equations, fitted parameters, or derivation steps appear in the provided text; energy savings and SLO parity are reported as measured outcomes rather than quantities defined in terms of the paper's own inputs. The offline-profile mechanism is presented as an engineering choice whose correctness is asserted by experiment, not by any self-referential construction. This is the normal case for an empirical systems paper and yields no circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jing Chen, Madhavan Manivannan, Bhavishya Goel, and Miquel Per- icàs. 2023. JOSS: Joint Exploration of CPU-Memory DVFS and Task Scheduling for Energy Efficiency. InProceedings of the 52nd Inter- national Conference on Parallel Processing(Salt Lake City, UT, USA) (ICPP ’23). Association for Computing Machinery, New York, NY, USA, 828–838. doi:10.1145/36055...
-
[2]
Andrew A Chien, Liuzixuan Lin, Hai Nguyen, Varsha Rao, Tristan Sharma, and Rajini Wijayawardana. 2023. Reducing the Carbon Impact of Generative AI Inference (today and in 2035). InProceedings of the 2nd workshop on sustainable computer systems. 1–7
2023
-
[3]
Seungbeom Choi, Jeonghoe Goo, Eunjoo Jeon, Mingyu Yang, and Minsung Jang. 2025. ELIS: Efficient LLM Iterative Scheduling System with Response Length Predictor. arXiv:2505.09142 [cs.DC]https: //arxiv.org/abs/2505.09142
arXiv 2025
-
[4]
Seungbeom Choi, Sunho Lee, Yeonjae Kim, Jongse Park, Youngjin Kwon, and Jaehyuk Huh. 2022. Serving Heterogeneous Machine Learning Models on Multi-GPU Servers with Spatio-Temporal Shar- ing. In2022 USENIX Annual Technical Conference (USENIX ATC 22). USENIX Association, Carlsbad, CA, 199–216.https://www.usenix.org/ conference/atc22/presentation/choi-seungbeom
2022
-
[5]
Tri Dao. 2023. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691(2023)
Pith/arXiv arXiv 2023
-
[6]
Aditya Dhakal, Sameer G Kulkarni, and KK Ramakrishnan. 2020. Gslice: controlled spatial sharing of gpus for a scalable inference plat- form. InProceedings of the 11th ACM Symposium on Cloud Computing. 492–506
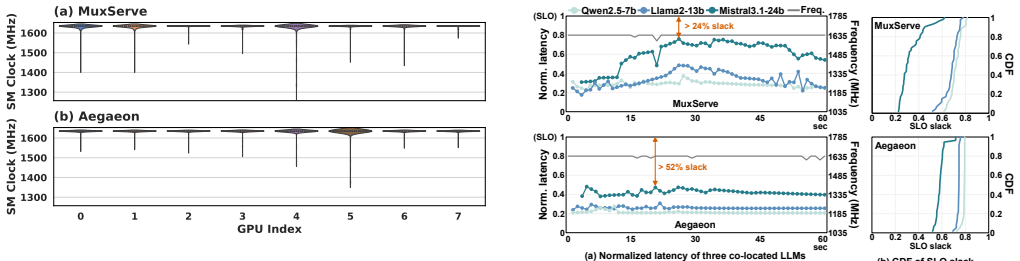
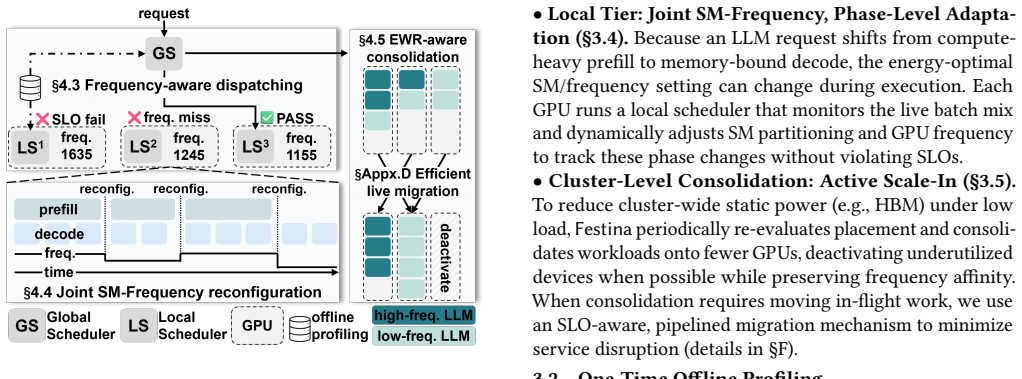
2020
-
[7]
Jiangfei Duan, Runyu Lu, Haojie Duanmu, Xiuhong Li, Xingcheng Zhang, Dahua Lin, Ion Stoica, and Hao Zhang. 2024. MuxServe: flexible spatial-temporal multiplexing for multiple LLM serving. InProceed- ings of the 41st International Conference on Machine Learning(Vienna, Austria)(ICML’24). JMLR.org, Article 473, 13 pages
2024
-
[8]
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. 2024. {ServerlessLLM}:{Low- Latency} serverless inference for large language models. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 135–153
2024
-
[9]
Shiwei Gao, Qing Wang, Shaoxun Zeng, Youyou Lu, and Jiwu Shu. 2025. Weaver: Efficient {Multi-LLM} Serving with Attention Offloading. In 2025 USENIX Annual Technical Conference (USENIX ATC 25). 587–595
2025
-
[10]
Yunchu Han, Zhaojun Nan, Sheng Zhou, and Zhisheng Niu. 2025. Joint Memory Frequency and Computing Frequency Scaling for Energy- efficient DNN Inference.arXiv preprint arXiv:2509.17970(2025)
arXiv 2025
-
[11]
Sarah L Harris and David Harris. 2021. Digital design and RISC- V computer architecture textbook. In2021 ACM/IEEE Workshop on Computer Architecture Education (WCAE). IEEE, 1–5
2021
-
[12]
Zicong Hong, Jian Lin, Song Guo, Sifu Luo, Wuhui Chen, Roger Watten- hofer, and Yue Yu. 2024. Optimus: Warming serverless ml inference via inter-function model transformation. InProceedings of the Nineteenth European Conference on Computer Systems. 1039–1053
2024
-
[13]
Zhengding Hu, Vibha Murthy, Zaifeng Pan, Wanlu Li, Xiaoyi Fang, Yufei Ding, and Yuke Wang. 2025. HedraRAG: Co-Optimizing Gen- eration and Retrieval for Heterogeneous RAG Workflows. InProceed- ings of the ACM SIGOPS 31st Symposium on Operating Systems Prin- ciples(Lotte Hotel World, Seoul, Republic of Korea)(SOSP ’25). As- sociation for Computing Machinery...
-
[14]
Tao Huang, Pengfei Chen, Kyoka Gong, Jocky Hawk, Zachary Bright, Wenxin Xie, Kecheng Huang, and Zhi Ji. 2024. ENOVA: Au- toscaling towards Cost-effective and Stable Serverless LLM Serving. arXiv:2407.09486 [cs.DC]https://arxiv.org/abs/2407.09486
arXiv 2024
-
[15]
Hugging Face. [n. d.].Hugging Face: The AI Community Building the Future. Hugging Face.https://huggingface.co/Accessed: 2026-02-04
2026
-
[16]
Shashwat Jaiswal, Kunal Jain, Yogesh Simmhan, Anjaly Parayil, Ankur Mallick, Rujia Wang, Renee St Amant, Chetan Bansal, Victor Rühle, Anoop Kulkarni, et al. 2025. Serving models, fast and slow: optimizing heterogeneous llm inferencing workloads at scale.arXiv preprint arXiv:2502.14617(2025)
arXiv 2025
-
[17]
2025.Accelerating LLM Serving for Multi-turn Dialogues with Efficient Resource Management
Jinwoo Jeong and Jeongseob Ahn. 2025.Accelerating LLM Serving for Multi-turn Dialogues with Efficient Resource Management. Association for Computing Machinery, New York, NY, USA, 1–15.https://doi.org/ 10.1145/3676641.3716245
-
[18]
Yunho Jin, Chun-Feng Wu, David Brooks, and Gu-Yeon Wei. 2023. S3: increasing GPU utilization during generative inference for higher throughput. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Article 791, 13 pages
2023
-
[19]
Harold W Kuhn. 1955. The Hungarian method for the assignment problem.Naval research logistics quarterly2, 1-2 (1955), 83–97
1955
-
[20]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[21]
InProceedings of the 29th symposium on operating systems principles
Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles. 611–626
-
[22]
Baolin Li, Tirthak Patel, Siddharth Samsi, Vijay Gadepally, and Devesh Tiwari. 2022. MISO: Exploiting Multi-Instance GPU Capability on Multi-Tenant GPU Clusters. InProceedings of the 13th Symposium on Cloud Computing(San Francisco, California)(SoCC ’22). Association for Computing Machinery, New York, NY, USA, 173–189. doi:10.1145/ 3542929.3563510
arXiv 2022
-
[23]
Bingyao Li, Yueqi Wang, Tianyu Wang, Lieven Eeckhout, Jun Yang, Aamer Jaleel, and Xulong Tang. 2024. STAR: Sub-Entry Sharing-Aware TLB for Multi-Instance GPU. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 309–323
2024
-
[24]
Yanying Lin, Shijie Peng, Chengzhi Lu, Chengzhong Xu, and Kejiang Ye. 2025. FlexPipe: Adapting Dynamic LLM Serving Through Inflight Pipeline Refactoring in Fragmented Serverless Clusters.arXiv preprint arXiv:2510.11938(2025)
Pith/arXiv arXiv 2025
-
[25]
Qianli Liu, Zicong Hong, Peng Li, Fahao Chen, and Song Guo. 2025. Mell: Memory-Efficient Large Language Model Serving via Multi-GPU KV Cache Management. InIEEE INFOCOM 2025 - IEEE Conference on Computer Communications. 1–10. doi:10.1109/INFOCOM55648.2025. 11044533 13
-
[26]
Qunyou Liu, Darong Huang, Marina Zapater, and David Atienza
-
[27]
GreenLLM: SLO-Aware Dynamic Frequency Scaling for Energy- Efficient LLM Serving.arXiv preprint arXiv:2508.16449(2025)
arXiv 2025
-
[28]
Chiheng Lou, Sheng Qi, Chao Jin, Dapeng Nie, Haoran Yang, Xuanzhe Liu, and Xin Jin. 2025. Towards Swift Serverless LLM Cold Starts with ParaServe.arXiv preprint arXiv:2502.15524(2025)
arXiv 2025
-
[29]
Cunchi Lv, Xiao Shi, Zhengyu Lei, Jinyue Huang, Wenting Tan, Xiaohui Zheng, and Xiaofang Zhao. 2025. Dilu: Enabling GPU Resourcing- on-Demand for Serverless DL Serving via Introspective Elasticity. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1 (Rotterdam, Netherla...
-
[30]
Xupeng Miao, Chunan Shi, Jiangfei Duan, Xiaoli Xi, Dahua Lin, Bin Cui, and Zhihao Jia. 2024. Spotserve: Serving generative large lan- guage models on preemptible instances. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Lan- guages and Operating Systems, Volume 2. 1112–1127
2024
-
[31]
Microsoft. [n. d.].Microsoft Azure: Cloud Computing Services. Microsoft. https://azure.microsoft.com/en-usAccessed: 2026-02-04
2026
-
[32]
2026.We did the math on AI’s energy footprint
MIT Technology Review. 2026.We did the math on AI’s energy footprint. Here’s the story you haven’t heard.https://www.technologyreview.com/ 2025/05/20/1116327/ai-energy-usage-climate-footprint-big-tech/Ac- cessed: 2026-01-26
2026
-
[33]
Salman Mohamadi, Ghulam Mujtaba, Ngan Le, Gianfranco Doretto, and Donald A Adjeroh. 2023. ChatGPT in the age of generative AI and large language models: a concise survey.arXiv preprint arXiv:2307.04251(2023)
arXiv 2023
-
[34]
2013.Applications of queueing theory
C Newell. 2013.Applications of queueing theory. Vol. 4. Springer Science & Business Media
2013
-
[35]
NVIDIA. 2022. NVIDIA H100 Tensor Core GPU Architec- ture.https://resources.nvidia.com/en-us-hopper-architecture/nvidia- h100-tensor-cWhitepaper
2022
-
[36]
NVIDIA. 2026. NVIDIA GPU Management and Deployment - Multi- Process Service.https://docs.nvidia.com/deploy/mps/index.html
2026
-
[37]
NVIDIA. 2026. NVIDIA Multi-Instance GPU User Guide.https: //docs.nvidia.com/datacenter/tesla/mig-user-guide/
2026
-
[38]
Archit Patke, Dhemath Reddy, Saurabh Jha, Haoran Qiu, Christian Pinto, Chandra Narayanaswami, Zbigniew Kalbarczyk, and Ravis- hankar Iyer. 2025. Queue management for slo-oriented large language model serving. arXiv:2407.00047 [cs.DC] doi:10.1145/3698038.369852
-
[39]
Qiangyu Pei, Yongjie Yuan, Haichuan Hu, Qiong Chen, and Fangming Liu. 2023. Asyfunc: A high-performance and resource-efficient server- less inference system via asymmetric functions. InProceedings of the 2023 ACM Symposium on Cloud Computing. 324–340
2023
-
[40]
PyPI Contributors. [n. d.]. nvidia-ml-py: Python Bindings to the NVIDIA Management Library (NVML).https://pypi.org/project/ nvidia-ml-py/. Accessed: 2026-02-04
2026
-
[41]
Python Software Foundation. [n. d.]. asyncio — Asynchronous I/O. https://docs.python.org/3/library/asyncio.html. Accessed: 2026-02-04
2026
-
[42]
Haoran Qiu, Weichao Mao, Archit Patke, Shengkun Cui, Saurabh Jha, Chen Wang, Hubertus Franke, Zbigniew T Kalbarczyk, Tamer Başar, and Ravishankar K Iyer. 2024. Efficient interactive llm serving with proxy model-based sequence length prediction.arXiv preprint arXiv:2404.08509(2024)
arXiv 2024
-
[43]
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. 2025. DynamoLLM: Designing LLM Inference Clusters for Performance and Energy Efficiency. In2025 IEEE International Sympo- sium on High Performance Computer Architecture (HPCA). 1348–1362. doi:10.1109/HPCA61900.2025.00102
-
[44]
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. 2024. Llumnix: Dynamic Scheduling for Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 173–191.https://www.usenix.org/conference/osdi24/ presentation/sun-biao
2024
-
[45]
Cheng Tan, Zhichao Li, Jian Zhang, Yu Cao, Sikai Qi, Zherui Liu, Yibo Zhu, and Chuanxiong Guo. 2021. Serving DNN models with multi-instance gpus: A case of the reconfigurable machine scheduling problem.arXiv preprint arXiv:2109.11067(2021)
arXiv 2021
-
[46]
Gemini Team, R Anil, S Borgeaud, Y Wu, JB Alayrac, J Yu, R Soricut, J Schalkwyk, AM Dai, A Hauth, et al. 2024. Gemini: A family of highly capable multimodal models, 2024.arXiv preprint arXiv:2312.1180510 (2024)
Pith/arXiv arXiv 2024
-
[47]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie- Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
Pith/arXiv arXiv 2023
-
[48]
vLLM Project. 2026. vLLM Documentation.https://docs.vllm.ai/en/ latest/. Accessed: 2026-02-04
2026
-
[49]
Tianyu Wang, Sheng Li, Bingyao Li, Yue Dai, Ao Li, Geng Yuan, Yufei Ding, Youtao Zhang, and Xulong Tang. 2024. Improving GPU Multi-Tenancy Through Dynamic Multi-Instance GPU Reconfigura- tion.arXiv preprint arXiv:2407.13126(2024)
arXiv 2024
-
[50]
Yuxin Wang, Yuhan Chen, Zeyu Li, Xueze Kang, Yuchu Fang, Yeju Zhou, Yang Zheng, Zhenheng Tang, Xin He, Rui Guo, et al . 2025. Burstgpt: A real-world workload dataset to optimize llm serving sys- tems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5831–5841
2025
-
[51]
Zibo Wang, Yijia Zhang, Fuchun Wei, Bingqiang Wang, Yanlin Liu, Zhiheng Hu, Jingyi Zhang, Xiaoxin Xu, Jian He, Xiaoliang Wang, Wanchun Dou, Guihai Chen, and Chen Tian. 2025. Using Analytical Performance/Power Model and Fine-Grained DVFS to Enhance AI Accelerator Energy Efficiency. InProceedings of the 30th ACM Inter- national Conference on Architectural S...
-
[52]
Adam Wierman, Lachlan LH Andrew, and Antony Tang. 2009. Power- aware speed scaling in processor sharing systems. InIEEE INFOCOM
2009
-
[53]
Tian Xia, Ziming Mao, Jamison Kerney, Ethan J Jackson, Zhifei Li, Jiarong Xing, Scott Shenker, and Ion Stoica. 2025. SkyLB: A Locality- Aware Cross-Region Load Balancer for LLM Inference.arXiv preprint arXiv:2505.24095(2025)
arXiv 2025
-
[54]
Yuxing Xiang, Xue Li, Kun Qian, Yufan Yang, Diwen Zhu, Wenyuan Yu, Ennan Zhai, Xuanzhe Liu, Xin Jin, and Jingren Zhou. 2025. Aegaeon: Effective GPU Pooling for Concurrent LLM Serving on the Market. In Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles(Lotte Hotel World, Seoul, Republic of Korea)(SOSP ’25). Association for Computi...
-
[55]
Yuxing Xiang, Xue Li, Kun Qian, Wenyuan Yu, Ennan Zhai, and Xin Jin
-
[56]
arXiv:2505.09999 [cs.DC] https://arxiv.org/abs/2505.09999
ServeGen: Workload Characterization and Generation of Large Language Model Serving in Production. arXiv:2505.09999 [cs.DC] https://arxiv.org/abs/2505.09999
-
[57]
Kaiqiang Xu, Decang Sun, Han Tian, Junxue Zhang, and Kai Chen
-
[58]
In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25)
{GREEN}: Carbon-efficient Resource Scheduling for Machine Learning Clusters. In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25). 999–1014
-
[59]
Yanan Yang, Laiping Zhao, Yiming Li, Huanyu Zhang, Jie Li, Mingyang Zhao, Xingzhen Chen, and Keqiu Li. 2022. Infless: a native serverless system for low-latency, high-throughput inference. InProceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems. 768–781
2022
-
[60]
Jie You, Jae-Won Chung, and Mosharaf Chowdhury. 2023. Zeus: Un- derstanding and optimizing {GPU } energy consumption of {DNN} training. In20th USENIX Symposium on Networked Systems Design and 14 Implementation (NSDI 23). 119–139
2023
-
[61]
Jiahuan Yu, Aryan Taneja, Junfeng Lin, and Minjia Zhang. 2025. VoltanaLLM: Feedback-Driven Frequency Control and State-Space Routing for Energy-Efficient LLM Serving.arXiv preprint arXiv:2509.04827(2025)
Pith/arXiv arXiv 2025
-
[62]
Shan Yu, Jiarong Xing, Yifan Qiao, Mingyuan Ma, Yangmin Li, Yang Wang, Shuo Yang, Zhiqiang Xie, Shiyi Cao, Ke Bao, et al. 2025. Prism: Unleashing GPU Sharing for Cost-Efficient Multi-LLM Serving.arXiv preprint arXiv:2505.04021(2025)
Pith/arXiv arXiv 2025
-
[63]
Anna Yue, Pen-Chung Yew, and Sanyam Mehta. 2025. EVeREST: An Effective and Versatile Runtime Energy Saving Tool for GPUs. In Proceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming(Las Vegas, NV, USA)(PPoPP ’25). Association for Computing Machinery, New York, NY, USA, 57–69. doi:10.1145/3710848.3710875
-
[64]
Shaoxun Zeng, Minhui Xie, Shiwei Gao, Youmin Chen, and Youyou Lu. 2025. Medusa: Accelerating serverless LLM inference with ma- terialization. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. 653–668
2025
-
[65]
Huaizheng Zhang, Yuanming Li, Wencong Xiao, Yizheng Huang, Xing Di, Jianxiong Yin, Simon See, Yong Luo, Chiew Tong Lau, and Yang You. 2023. MIGPerf: A Comprehensive Benchmark for Deep Learning Training and Inference Workloads on Multi-Instance GPUs.arXiv preprint arXiv:2301.00407(2023)
arXiv 2023
-
[66]
Wei Zhang, Weihao Cui, Kaihua Fu, Quan Chen, Daniel Edward Mawhirter, Bo Wu, Chao Li, and Minyi Guo. 2019. Laius: Towards Latency Awareness and Improved Utilization of Spatial multitask- ing accelerators in datacenters. InProceedings of the ACM Interna- tional Conference on Supercomputing(Phoenix, Arizona)(ICS ’19). Association for Computing Machinery, Ne...
-
[67]
Yijia Zhang, Qiang Wang, Zhe Lin, Pengxiang Xu, and Bingqiang Wang. 2024. Improving GPU Energy Efficiency through an Application- transparent Frequency Scaling Policy with Performance Assurance. In Proceedings of the Nineteenth European Conference on Computer Systems (Athens, Greece)(EuroSys ’24). Association for Computing Machinery, New York, NY, USA, 76...
-
[68]
Gonzalez, Ion Stoica, and Hao Zhang
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric Xing, Joseph E. Gonzalez, Ion Stoica, and Hao Zhang. 2024. LMSYS-Chat- 1M: A Large-Scale Real-World LLM Conversation Dataset. InThe Twelfth International Conference on Learning Representations.https: //openreview.net/forum?id=BOfDKxfwt0
2024
-
[69]
Zangwei Zheng, Xiaozhe Ren, Fuzhao Xue, Yang Luo, Xin Jiang, and Yang You. 2023. Response length perception and sequence schedul- ing: An llm-empowered llm inference pipeline.Advances in Neural Information Processing Systems36 (2023), 65517–65530. A Background A.1 LLM Inference Contemporary LLMs [31, 44, 45] are predominantly decoder- only Transformers co...
2023
-
[70]
They lack the dynamic auto-scaling capabilities required for serverless serving
Lack of Auto-scaling:GreenLLM and VoltanaLLM rely on static node partitioning for prefill and decode phases in disaggregated setups. They lack the dynamic auto-scaling capabilities required for serverless serving. Without scale- out support, meeting SLOs under high load is difficult; con- versely, without scale-in support, GPUs remain under-utilized durin...
-
[71]
Dedicating a single high-performance GPU (e.g., NVIDIA H100) to one LLM often results in severe under-utilization [7, 18 27, 52]
Absence of Spatial Multiplexing:These systems do not support spatial multiplexing for co-located multi-tenancy. Dedicating a single high-performance GPU (e.g., NVIDIA H100) to one LLM often results in severe under-utilization [7, 18 27, 52]. However, naïve sharing without dedicated resource management (e.g., SM partitioning, frequency control) leads to si...
-
[72]
No Shared-Frequency Conflict Resolution:Prior systems assume each frequency setting governs a single workload. Under co-location, all tenants on a GPU share one device-wide clock, so the most demanding co-tenant pins the frequency and forces models that prefer lower frequencies to over-clock, eroding DVFS savings. None of these systems provide a dispatchi...
-
[73]
Inflexible Phase Management:DynamoLLM applies a single static frequency for both prefill and decode phases, neglecting their distinct computational intensities. While GreenLLM and VoltanaLLM provide phase-specific adjust- ments, they are tailored for disaggregated setups and do not support prefill-decode mixed scenarios, where PD-aggregated serving is com...
-
[74]
In a shared GPU, SM partitioning and frequency are coupled—the SM allocation shifts each tenant’s latency/energy-optimal frequency—so optimizing either in isolation is sub-optimal
Decoupled, Not Joint, Control:These systems treat frequency as the sole energy knob. In a shared GPU, SM partitioning and frequency are coupled—the SM allocation shifts each tenant’s latency/energy-optimal frequency—so optimizing either in isolation is sub-optimal. Prior controllers offer no mechanism for the joint SM/frequency adaptation that co-located ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.