Positive-Incentive Noise Predictor for Adversarial Purification in Speaker Verification
Pith reviewed 2026-07-02 05:10 UTC · model grok-4.3
The pith
A learned noise predictor defends speaker verification systems by adding input-specific positive-incentive noise instead of running full diffusion denoising.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
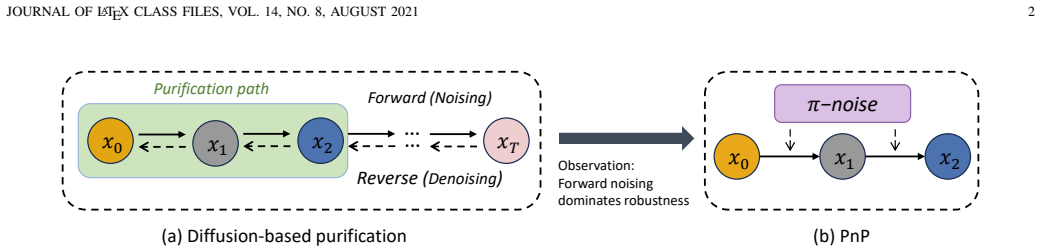
Reformulating adversarial purification as a learnable noising problem yields the Positive-Incentive Noise Predictor, which explicitly introduces input-adaptive π-noise into the input signal; this mixture disrupts adversarial perturbations for downstream ASV systems more efficiently than iterative denoising while preserving natural speech performance.
What carries the argument
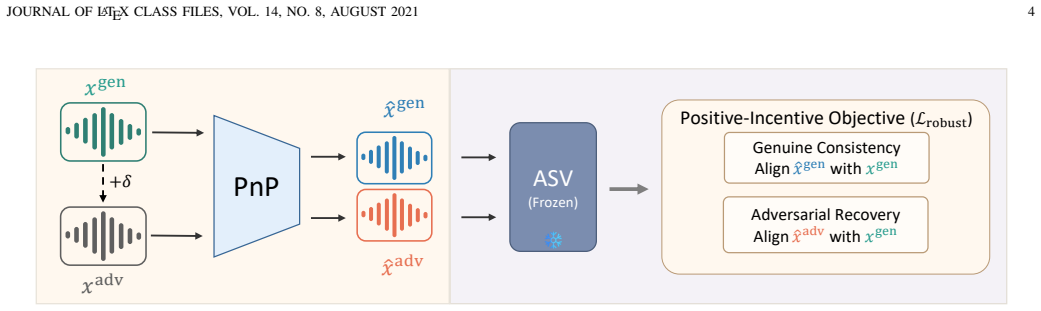
The Positive-Incentive Noise Predictor (PnP), a module that learns input-adaptive π-noise and mixes it with the input speech signal to perform purification.
If this is right
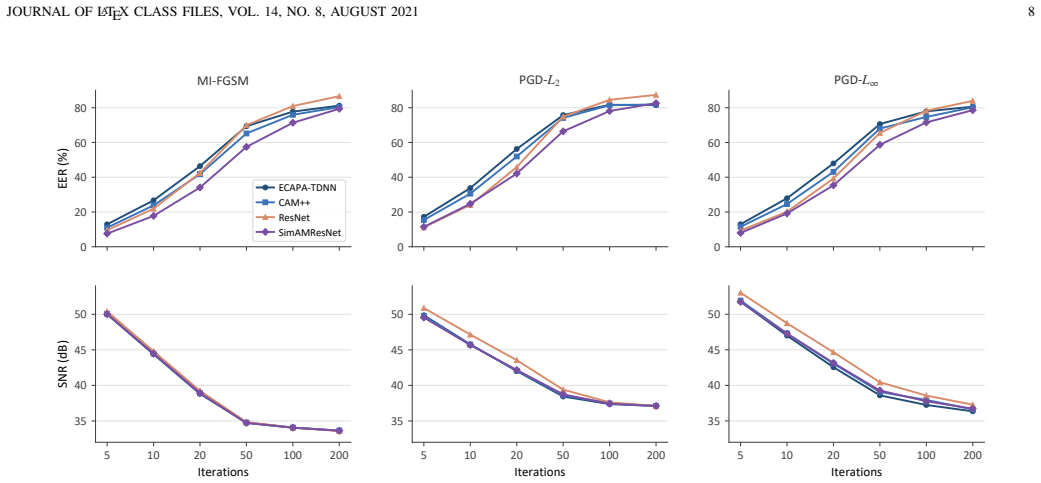
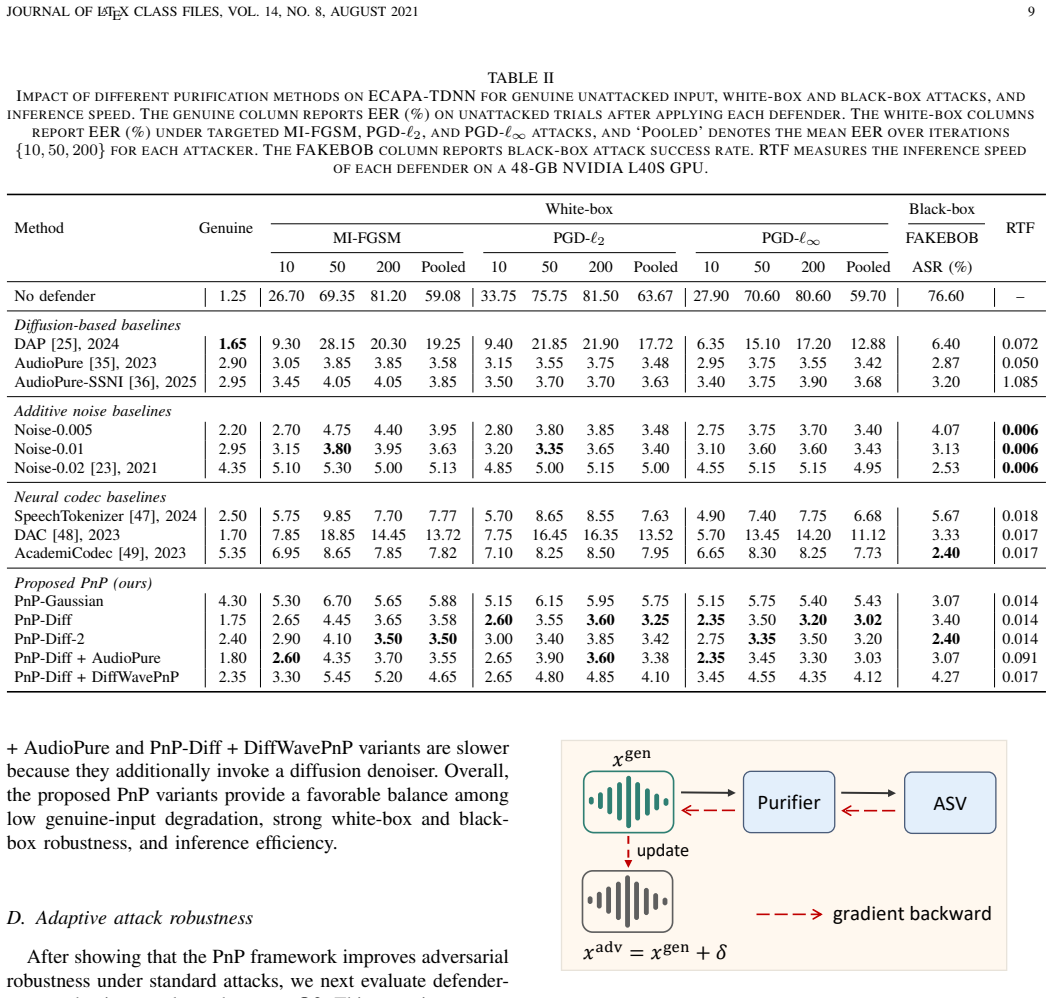
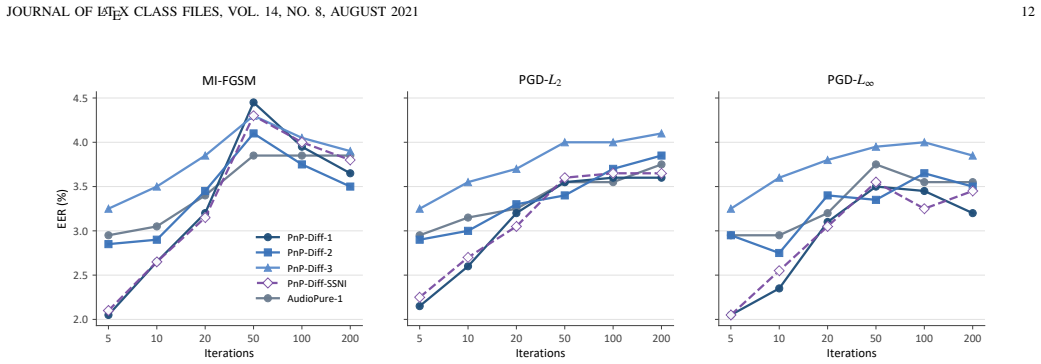
- PnP defends four advanced ASV backbones against white-box, black-box, and defender-aware adaptive attacks.
- Clean-speech verification accuracy remains largely intact after purification.
- Inference cost drops to a real-time factor of 0.014.
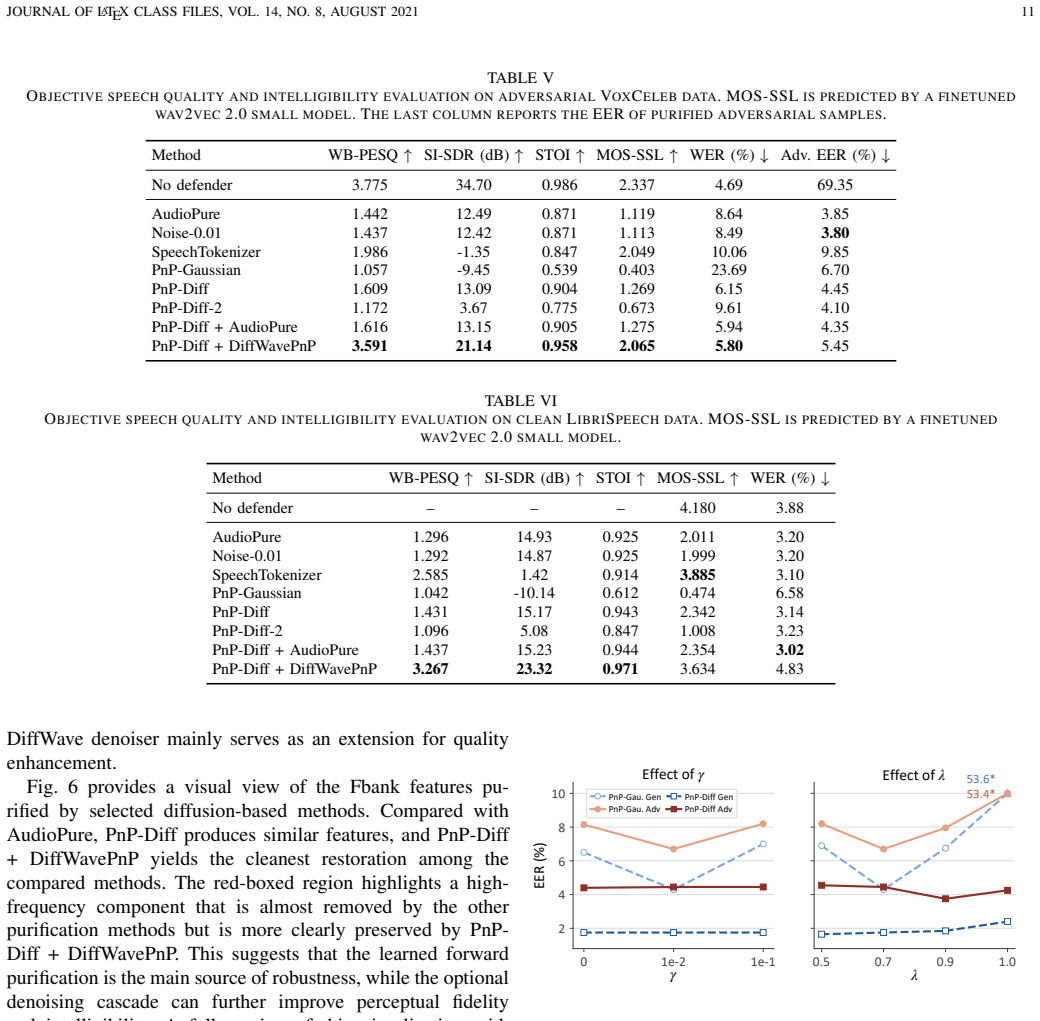
- Cascading PnP with a diffusion denoiser further raises perceptual quality of the output.
Where Pith is reading between the lines
- The same input-adaptive noise prediction approach could be tested on other audio tasks such as automatic speech recognition under attack.
- If forward noising dominates, simpler non-generative noise predictors may suffice for many defense settings.
- The π-noise distribution itself may reveal structure in the adversarial perturbation manifold for speaker verification.
Load-bearing premise
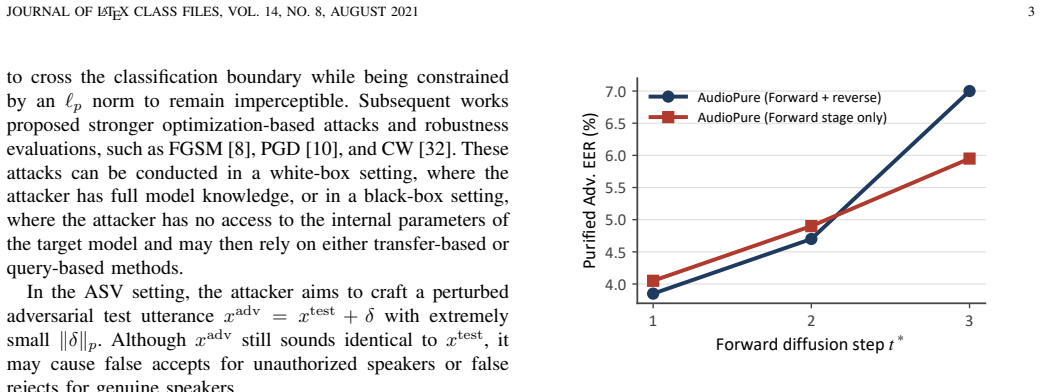
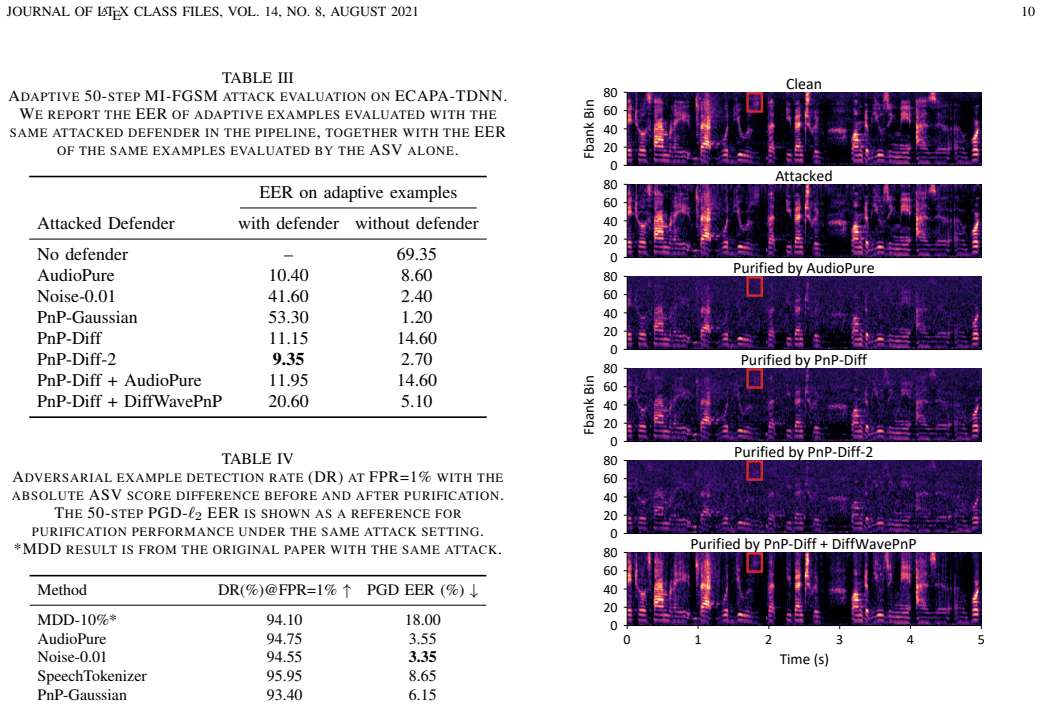
The forward noising process supplies most of the robustness gain against adversarial perturbations.
What would settle it
An ablation that applies only the forward noising step versus the full diffusion pipeline on identical ASV models and attack sets, measuring whether robustness drops sharply without the learned noising predictor.
Figures
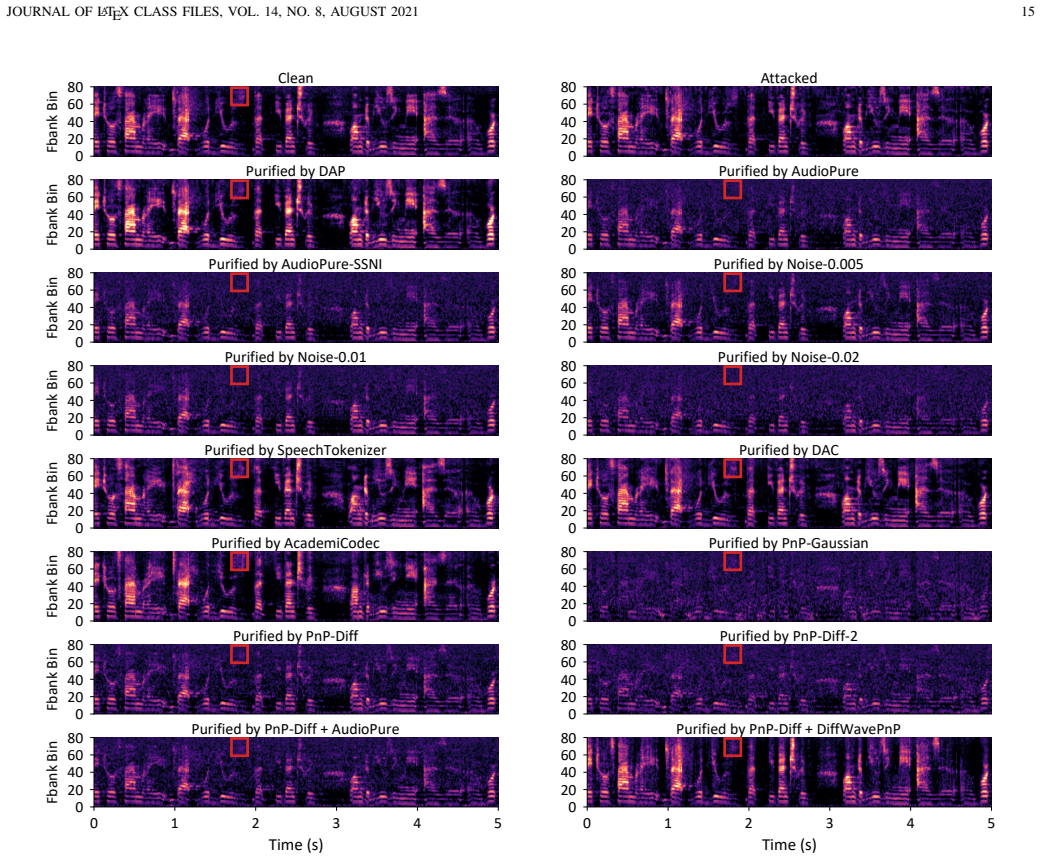
read the original abstract
Modern automatic speaker verification (ASV) systems are vulnerable to adversarial perturbations. Diffusion-based purification has recently shown strong effectiveness against such perturbations, but its reverse denoising process requires iterative sampling and leads to high inference latency. We find that the forward noising process provides most of the robustness gain. Motivated by this observation, we reformulate adversarial purification as a learnable noising problem, and propose the Positive-Incentive Noise Predictor (PnP), the first framework that explicitly introduces positive-incentive noise ({\pi}-noise) into the purification task. PnP learns input-adaptive {\pi}-noise and mixes it with the input to improve the robustness of downstream ASV systems. Experiments on four advanced ASV backbones show that PnP effectively defends against adversarial attacks while preserving performance on natural speech. Compared with representative purification baselines, the proposed framework provides a competitive balance among defense effectiveness, impact on genuine utterances, and inference efficiency under white-box, black-box, and defender-aware adaptive attacks, with a real-time factor as low as 0.014. Moreover, PnP can be cascaded with a diffusion denoiser to further improve the perceptual quality of purified utterances. Code and purified audio examples are available at https://eurecom-asp.github.io/pnp/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Positive-Incentive Noise Predictor (PnP), a framework that reformulates adversarial purification for automatic speaker verification (ASV) as a learnable noising task. Motivated by the observation that the forward noising process supplies most robustness gains in diffusion models, PnP trains a network to predict and add input-adaptive positive-incentive noise (π-noise) to inputs before feeding them to downstream ASV backbones. Experiments across four ASV models report effective defense under white-box, black-box, and adaptive attacks while preserving clean-speech performance and achieving real-time factors down to 0.014; the method can also be cascaded with a diffusion denoiser. Code and purified audio examples are released.
Significance. If the central claim holds, PnP supplies a low-latency, trainable alternative to iterative diffusion purification for ASV robustness, with a favorable trade-off among defense strength, clean accuracy, and efficiency. The public release of code and audio examples is a clear strength that supports reproducibility and external validation.
major comments (2)
- [Abstract, §1] Abstract and §1 (motivation): The load-bearing observation that 'the forward noising process provides most of the robustness gain' is not isolated from the adaptive predictor itself. The reported experiments compare PnP only against other purification baselines; an ablation replacing the learned PnP with non-adaptive noise whose statistics match the PnP output distribution is required to show that the reformulation (learnable noising rather than full denoising) is justified by the forward process rather than by adaptation alone.
- [§4] §4 (experiments): The central claim of competitive balance among defense, clean performance, and efficiency is supported only by point estimates across four backbones and multiple attack settings. Without reported error bars, statistical significance tests, or details on data splits and training seeds, it is impossible to assess whether the reported gains are robust or could be explained by variance in the ASV backbones.
minor comments (2)
- [§3] Notation for π-noise is introduced in the abstract but its precise mathematical definition (distribution family, positivity constraint, mixing coefficient) should be stated explicitly in the first equation of §3.
- [Figures] Figure captions should include the exact attack parameters (ε, number of iterations) used for each panel so that readers can reproduce the visual results without returning to the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [Abstract, §1] Abstract and §1 (motivation): The load-bearing observation that 'the forward noising process provides most of the robustness gain' is not isolated from the adaptive predictor itself. The reported experiments compare PnP only against other purification baselines; an ablation replacing the learned PnP with non-adaptive noise whose statistics match the PnP output distribution is required to show that the reformulation (learnable noising rather than full denoising) is justified by the forward process rather than by adaptation alone.
Authors: We appreciate this observation. The central motivation is indeed based on the forward process in diffusion models, but to rigorously demonstrate that the learnable aspect is key beyond just the noise distribution, we agree an ablation is necessary. We will add an experiment comparing PnP to a non-adaptive noise predictor that samples from the same distribution as PnP's output in the revised manuscript. revision: yes
-
Referee: [§4] §4 (experiments): The central claim of competitive balance among defense, clean performance, and efficiency is supported only by point estimates across four backbones and multiple attack settings. Without reported error bars, statistical significance tests, or details on data splits and training seeds, it is impossible to assess whether the reported gains are robust or could be explained by variance in the ASV backbones.
Authors: We agree that providing more statistical rigor would strengthen the paper. We will include details on the data splits and the training seeds used in the experiments. For error bars, we will attempt to run a subset of the experiments with multiple seeds and report the standard deviation where possible, though full re-training of all models may be limited by computational resources. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper motivates its reformulation of purification as learnable noising from an empirical observation that forward noising supplies most robustness gain, then introduces PnP as a trainable adaptive noise predictor. No equations or self-citations are shown that reduce the reported defense gains, the choice of noising formulation, or the performance claims back to quantities fitted from the paper's own inputs or prior author work by construction. Experiments compare PnP against external baselines on multiple ASV systems, and the method is presented as an independent trainable component rather than a renaming or self-referential fit. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- weights of the Positive-Incentive Noise Predictor
axioms (1)
- domain assumption Forward noising process provides most of the robustness gain
invented entities (1)
-
positive-incentive noise (π-noise)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Speaker recognition based on deep learning: An overview,
Z. Bai and X.-L. Zhang, “Speaker recognition based on deep learning: An overview,”Neural Networks, vol. 140, pp. 65–99, 2021
2021
-
[2]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449– 12 460, 2020
2020
-
[3]
Wavlm: Large-scale self-supervised pre- training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self-supervised pre- training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[4]
Robust speech recognition via large-scale weak supervi- sion,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervi- sion,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[5]
Asvspoof 5: JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13 crowdsourced speech data, deepfakes, and adversarial attacks at scale,
X. Wang, H. Delgado, H. Tak, J.-w. Jung, H.-j. Shim, M. Todisco, I. Kukanov, X. Liu, M. Sahidullah, T. H. Kinnunenet al., “Asvspoof 5: JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13 crowdsourced speech data, deepfakes, and adversarial attacks at scale,” inProc. ASVspoof 2024, 2024, pp. 1–8
2021
-
[6]
Intriguing properties of neural networks,
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Good- fellow, and R. Fergus, “Intriguing properties of neural networks,” in 2nd International Conference on Learning Representations, ICLR 2014, 2014
2014
-
[7]
x-vectors meet adversarial attacks: Benchmarking adversarial robustness in speaker verification,
J. Villalba, Y . Zhang, and N. Dehak, “x-vectors meet adversarial attacks: Benchmarking adversarial robustness in speaker verification,” inInterspeech, 2020, pp. 4233–4237
2020
-
[8]
Explaining and harnessing adversarial examples,
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” inInternational Conference on Learning Repre- sentations, 2014
2014
-
[9]
Adversarial examples in the physical world,
A. Kurakin, I. J. Goodfellow, and S. Bengio, “Adversarial examples in the physical world,” inArtificial intelligence safety and security. Chapman and Hall/CRC, 2018, pp. 99–112
2018
-
[10]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” inInternational Conference on Learning Representations, 2018
2018
-
[11]
Adversarial attacks on gmm i-vector based speaker verification systems,
X. Li, J. Zhong, X. Wu, J. Yu, X. Liu, and H. Meng, “Adversarial attacks on gmm i-vector based speaker verification systems,” in2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6579–6583
2020
-
[12]
Interpretable spectrum transfor- mation attacks to speaker recognition systems,
J. Yao, H. Luo, J. Qi, and X.-L. Zhang, “Interpretable spectrum transfor- mation attacks to speaker recognition systems,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 1531–1545, 2024
2024
-
[13]
Who is real bob? adversarial attacks on speaker recognition systems,
G. Chen, S. Chenb, L. Fan, X. Du, Z. Zhao, F. Song, and Y . Liu, “Who is real bob? adversarial attacks on speaker recognition systems,” in2021 IEEE symposium on security and privacy (SP). IEEE, 2021, pp. 694– 711
2021
-
[14]
Advpulse: Universal, synchronization-free, and targeted audio adversarial attacks via subsec- ond perturbations,
Z. Li, Y . Wu, J. Liu, Y . Chen, and B. Yuan, “Advpulse: Universal, synchronization-free, and targeted audio adversarial attacks via subsec- ond perturbations,” inProceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, 2020, pp. 1121–1134
2020
-
[15]
Over-the-air adversarial attacks and detection for automatic speaker verification,
L. Wang, X. Lei, H. He, L. Wang, J. Shi, and Z. Wu, “Over-the-air adversarial attacks and detection for automatic speaker verification,” IEEE Transactions on Audio, Speech and Language Processing, 2026
2026
-
[16]
Adversarial attacks on text-dependent speaker verification system,
S. Sankala, V . Parvathala, R. Gundluru, and S. R. M. Kodukula, “Adversarial attacks on text-dependent speaker verification system,” in Proc. Interspeech 2025, 2025, pp. 4558–4562
2025
-
[17]
The defender’s perspective on automatic speaker verification: An overview,
H. Wu, J. Kang, L. Meng, H. Meng, and H.-y. Lee, “The defender’s perspective on automatic speaker verification: An overview,” inDADA@ IJCAI, 2023
2023
-
[18]
Adversarial attacks and defenses in speaker recognition systems: A survey,
J. Lan, R. Zhang, Z. Yan, J. Wang, Y . Chen, and R. Hou, “Adversarial attacks and defenses in speaker recognition systems: A survey,”Journal of Systems Architecture, vol. 127, p. 102526, 2022
2022
-
[19]
Lmd: A learnable mask network to detect adversarial examples for speaker verification,
X. Chen, J. Wang, X.-L. Zhang, W.-Q. Zhang, and K. Yang, “Lmd: A learnable mask network to detect adversarial examples for speaker verification,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2476–2490, 2023
2023
-
[20]
Improving the adversarial robustness for speaker verification by self-supervised learning,
H. Wu, X. Li, A. T. Liu, Z. Wu, H. Meng, and H.-Y . Lee, “Improving the adversarial robustness for speaker verification by self-supervised learning,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 202–217, 2021
2021
-
[21]
Mdd: a mask diffusion detector to protect speaker verification systems from adversarial perturbations,
Y . Bai, S. Chen, M. Panariello, X.-L. Zhang, M. Todisco, and N. Evans, “Mdd: a mask diffusion detector to protect speaker verification systems from adversarial perturbations,” inAPSIPA ASC 2025, 17th Asia Pacific Signal and Information Processing Association Annual Summit and Conference, 2025
2025
-
[22]
Defense against adversarial at- tacks on spoofing countermeasures of asv,
H. Wu, S. Liu, H. Meng, and H.-y. Lee, “Defense against adversarial at- tacks on spoofing countermeasures of asv,” inICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6564–6568
2020
-
[23]
Defending against adversarial attacks in speaker verification systems,
L.-C. Chang, Z. Chen, C. Chen, G. Wang, and Z. Bi, “Defending against adversarial attacks in speaker verification systems,” in2021 IEEE In- ternational Performance, Computing, and Communications Conference (IPCCC). IEEE, 2021, pp. 1–8
2021
-
[24]
Neural codec-based adversarial sample detection for speaker verification,
X. Chen, J. Du, H. Wu, J.-S. R. Jang, and H. yi Lee, “Neural codec-based adversarial sample detection for speaker verification,” inInterspeech 2024, 2024, pp. 522–526
2024
-
[25]
Diffusion-based adversarial purification for speaker verification,
Y . Bai, X.-L. Zhang, and X. Li, “Diffusion-based adversarial purification for speaker verification,”IEEE Signal Processing Letters, 2024
2024
-
[26]
Textual-driven adversarial purification for speaker verification,
S. Chen, Y . Bai, J. Yao, X.-L. Zhang, and X. Li, “Textual-driven adversarial purification for speaker verification,” inProc. Interspeech 2024, 2024, pp. 527–531
2024
-
[27]
Adversarial purification for speaker verification by two-stage diffusion models,
Y . Bai, X.-L. Zhang, and X. Li, “Adversarial purification for speaker verification by two-stage diffusion models,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 1158–1164
2024
-
[28]
X- vectors: Robust dnn embeddings for speaker recognition,
D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudanpur, “X- vectors: Robust dnn embeddings for speaker recognition,” in2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 5329–5333
2018
-
[29]
Ecapa-tdnn: Em- phasized channel attention, propagation and aggregation in tdnn based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “Ecapa-tdnn: Em- phasized channel attention, propagation and aggregation in tdnn based speaker verification,” inINTERSPEECH. ISCA, 2020
2020
-
[30]
But system description to voxceleb speaker recognition chal- lenge 2019,
H. Zeinali, S. Wang, A. Silnova, P. Mat ˇejka, and O. Plchot, “But system description to voxceleb speaker recognition challenge 2019,” arXiv preprint arXiv:1910.12592, 2019
-
[31]
Large-scale self-supervised speech representation learning for automatic speaker verification,
Z. Chen, S. Chen, Y . Wu, Y . Qian, C. Wang, S. Liu, Y . Qian, and M. Zeng, “Large-scale self-supervised speech representation learning for automatic speaker verification,” inICASSP 2022-2022 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6147–6151
2022
-
[32]
Towards evaluating the robustness of neural networks,
N. Carlini and D. Wagner, “Towards evaluating the robustness of neural networks,” in2017 ieee symposium on security and privacy (sp). Ieee, 2017, pp. 39–57
2017
-
[33]
Boosting adversarial attacks with momentum,
Y . Dong, F. Liao, T. Pang, H. Su, J. Zhu, X. Hu, and J. Li, “Boosting adversarial attacks with momentum,” inProceedings of the IEEE confer- ence on computer vision and pattern recognition, 2018, pp. 9185–9193
2018
-
[34]
Diffusion models for adversarial purification,
W. Nie, B. Guo, Y . Huang, C. Xiao, A. Vahdat, and A. Anandkumar, “Diffusion models for adversarial purification,” inInternational Confer- ence on Machine Learning. PMLR, 2022, pp. 16 805–16 827
2022
-
[35]
Defending against adversarial audio via diffusion model,
S. Wu, J. Wang, W. Ping, W. Nie, and C. Xiao, “Defending against adversarial audio via diffusion model,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[36]
Sample-specific noise injection for diffusion-based adversarial purification,
Y . Sun, J. Zhang, Z. Ye, C. Xiao, and F. Liu, “Sample-specific noise injection for diffusion-based adversarial purification,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 57 961–57 983
2025
-
[37]
Positive-incentive noise,
X. Li, “Positive-incentive noise,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 6, pp. 8708–8714, 2022
2022
-
[38]
Variational positive-incentive noise: How noise benefits models,
H. Zhang, S. Huang, Y . Guo, and X. Li, “Variational positive-incentive noise: How noise benefits models,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[39]
V oxceleb: A large-scale speaker identification dataset,
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxceleb: A large-scale speaker identification dataset,” inINTERSPEECH. ISCA, 2017
2017
-
[40]
V oxceleb2: Deep speaker recognition,
J. Chung, A. Nagrani, and A. Zisserman, “V oxceleb2: Deep speaker recognition,” inINTERSPEECH. ISCA, 2018
2018
-
[41]
V oxblink2: A 100k+ speaker recognition corpus and the open-set speaker-identification benchmark,
Y . Lin, M. Cheng, F. Zhang, Y . Gao, S. Zhang, and M. Li, “V oxblink2: A 100k+ speaker recognition corpus and the open-set speaker-identification benchmark,” inProc. Interspeech 2024, 2024, pp. 4263–4267
2024
-
[42]
Librispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: an asr corpus based on public domain audio books,” in2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015, pp. 5206–5210
2015
-
[43]
Cam++: A fast and efficient network for speaker verification using context-aware masking,
H. Wang, S. Zheng, Y . Chen, L. Cheng, and Q. Chen, “Cam++: A fast and efficient network for speaker verification using context-aware masking,” inProc. Interspeech 2023, 2023, pp. 5301–5305
2023
-
[44]
Simple attention mod- ule based speaker verification with iterative noisy label detection,
X. Qin, N. Li, C. Weng, D. Su, and M. Li, “Simple attention mod- ule based speaker verification with iterative noisy label detection,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6722–6726
2022
-
[45]
Wespeaker: A research and production oriented speaker embedding learning toolkit,
H. Wang, C. Liang, S. Wang, Z. Chen, B. Zhang, X. Xiang, Y . Deng, and Y . Qian, “Wespeaker: A research and production oriented speaker embedding learning toolkit,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[46]
Diffwave: A versatile diffusion model for audio synthesis,
Z. Kong, W. Ping, J. Huang, K. Zhao, and B. Catanzaro, “Diffwave: A versatile diffusion model for audio synthesis,” inInternational Confer- ence on Learning Representations, 2020
2020
-
[47]
Speechtokenizer: Unified speech tokenizer for speech language models,
X. Zhang, D. Zhang, S. Li, Y . Zhou, and X. Qiu, “Speechtokenizer: Unified speech tokenizer for speech language models,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[48]
High- fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High- fidelity audio compression with improved rvqgan,”Advances in Neural Information Processing Systems, vol. 36, pp. 27 980–27 993, 2023
2023
-
[49]
Hifi-codec: Group-residual vector quantization for high fidelity audio codec,
D. Yang, S. Liu, R. Huang, J. Tian, C. Weng, and Y . Zou, “Hifi-codec: Group-residual vector quantization for high fidelity audio codec,”arXiv preprint arXiv:2305.02765, 2023
-
[50]
Generalization ability of mos prediction networks,
E. Cooper, W.-C. Huang, T. Toda, and J. Yamagishi, “Generalization ability of mos prediction networks,” inICASSP 2022-2022 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 8442–8446. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14 Supplementary Material Positive-Incentive Noise Predictor for...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.