MxGLUT: A Reconfigurable LUT-Centric Broadcast Dataflow Accelerator for Mixed-Precision GEMM
Pith reviewed 2026-07-03 04:30 UTC · model grok-4.3
The pith
MxGLUT unifies FP8-INT4 and FP8-FP8 GEMM computation inside one LUT-based accelerator for LLM inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
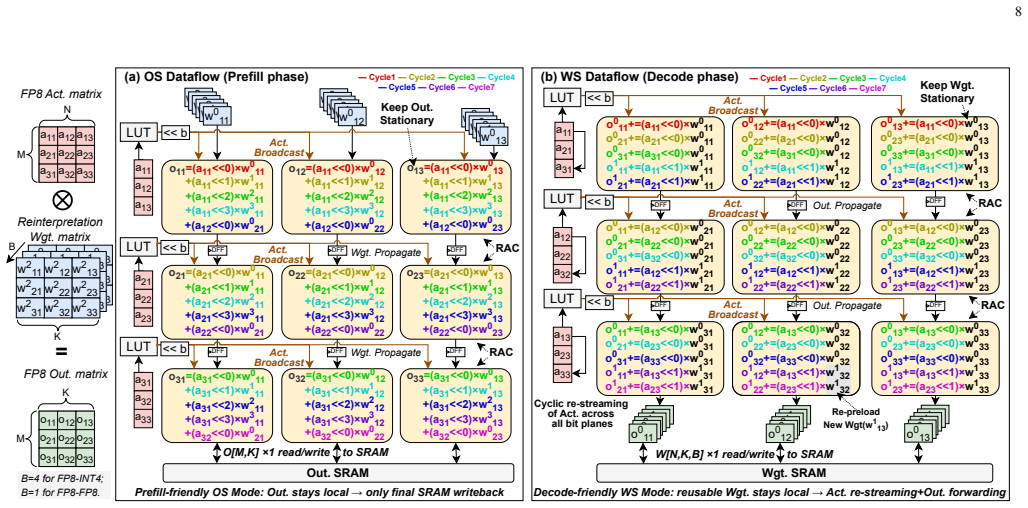
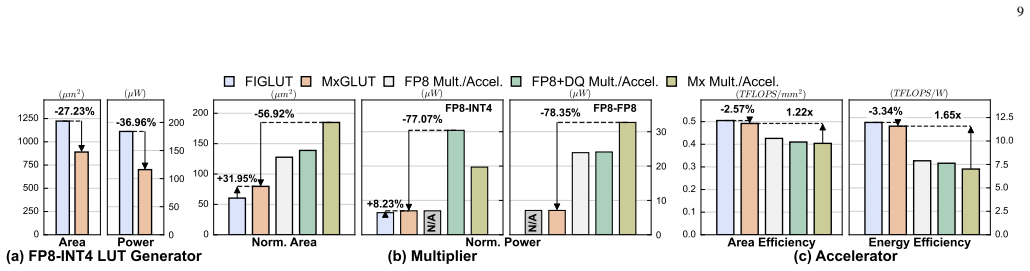
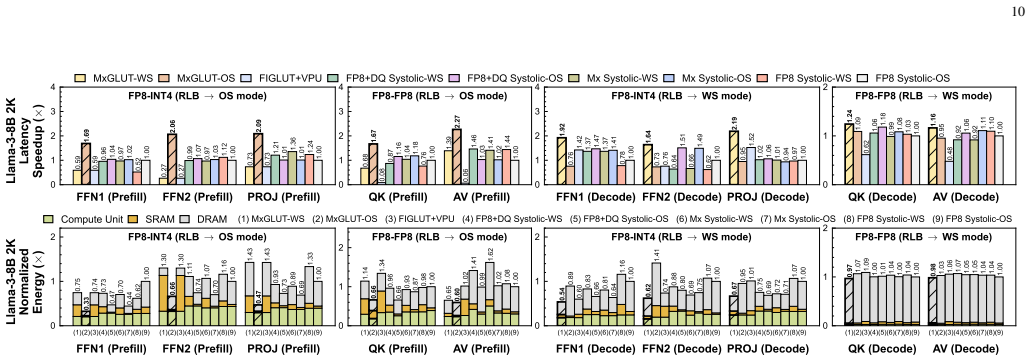
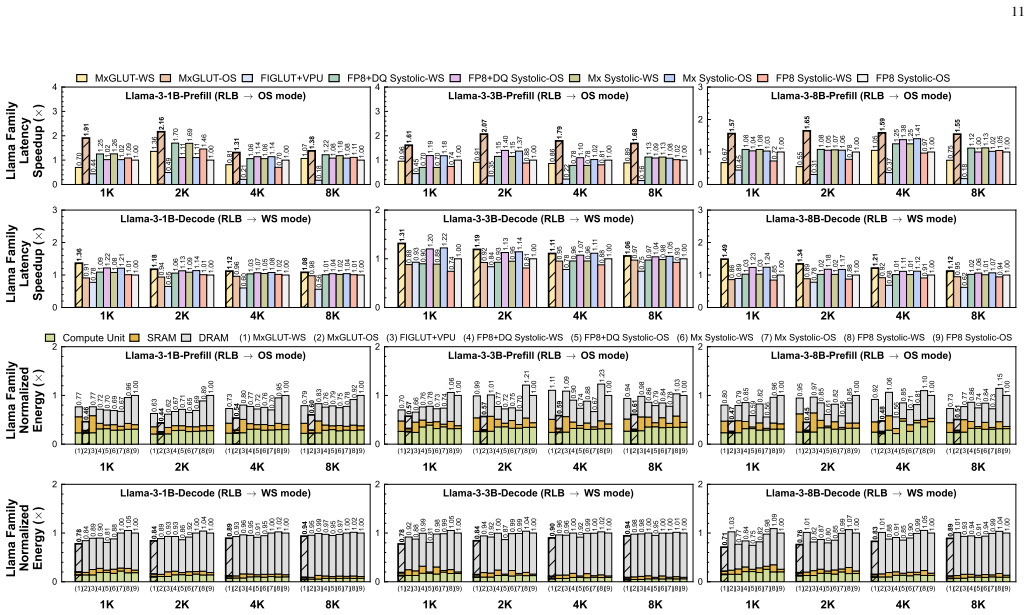
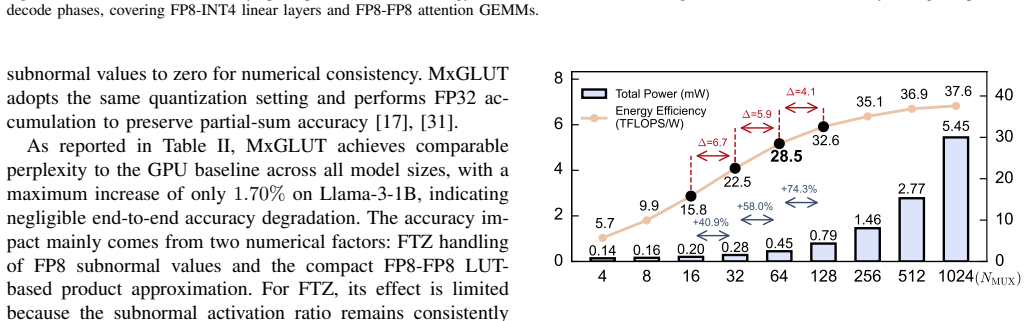
MxGLUT organizes FP8-INT4 and FP8-FP8 GEMM under one LUT-based compute path by means of mixed-precision LUT-based processing elements and a reconfigurable broadcast dataflow that localizes partial-sum accumulation in prefill and reuses weights in decode; synthesis in 28 nm CMOS at 200 MHz shows multiplier area reduced by up to 56.92 percent and power by up to 78.35 percent, with accelerator-level area efficiency of 0.492 TFLOPS/mm² and energy efficiency of 11.58 TFLOPS/W, plus up to 2.16× prefill and 1.49× decode latency gains at no more than 1.70 percent perplexity increase.
What carries the argument
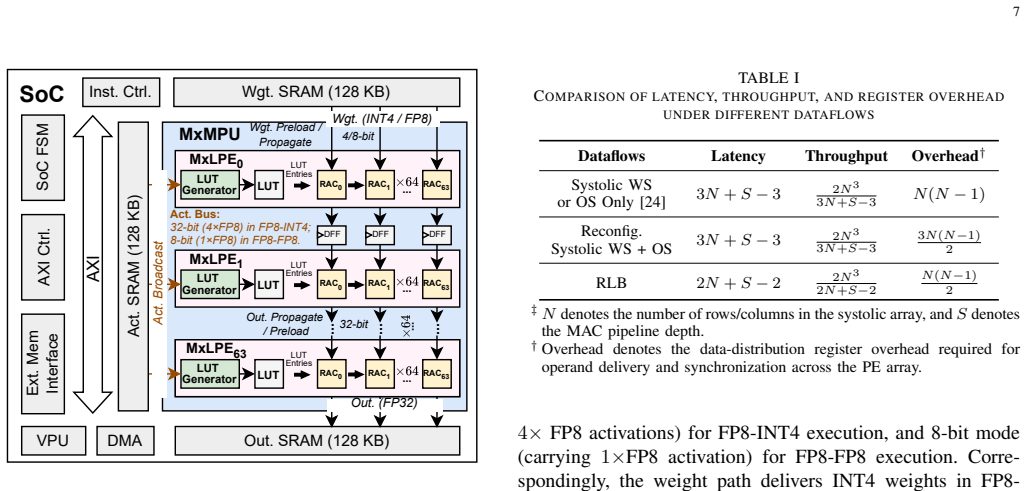
The mixed-precision LUT-based processing element (MxLPE) together with the reconfigurable LUT-centric broadcast (RLB) dataflow, which executes both precision modes without dedicated FP multipliers or extra datapaths.
If this is right
- Multiplier area drops by up to 56.92 percent and power by up to 78.35 percent when FP8-FP8 support is added.
- Adding native FP8-FP8 mode reduces accelerator area efficiency by only 2.57 percent and energy efficiency by only 3.34 percent relative to an FP8-INT4-only baseline.
- Prefill latency improves up to 2.16× and decode latency up to 1.49× across the Llama family while normalized energy falls to 0.44× and 0.71× respectively.
- Perplexity degradation stays within 1.70 percent when the accelerator runs the full inference workload.
Where Pith is reading between the lines
- The same RLB schedule could be retargeted to other attention-heavy workloads such as long-context retrieval if the broadcast widths are scaled accordingly.
- Because the design already collapses two precision modes into one datapath, extending the LUT tables to additional low-bit formats would require only modest additional configuration logic.
- System-level energy savings would increase further if on-chip memory bandwidth is matched to the localized accumulation pattern rather than relying on off-chip DRAM for partial sums.
Load-bearing premise
Post-synthesis area, power, and latency numbers obtained at 200 MHz in 28 nm CMOS will translate directly to real silicon once process variation, interconnect parasitics, and memory-subsystem integration are taken into account.
What would settle it
Fabricate the MxGLUT design in the target 28 nm process and measure actual silicon area, power at 200 MHz, and end-to-end LLM inference energy/latency against the reported synthesis figures; a discrepancy larger than the claimed margins would falsify the performance claims.
Figures
read the original abstract
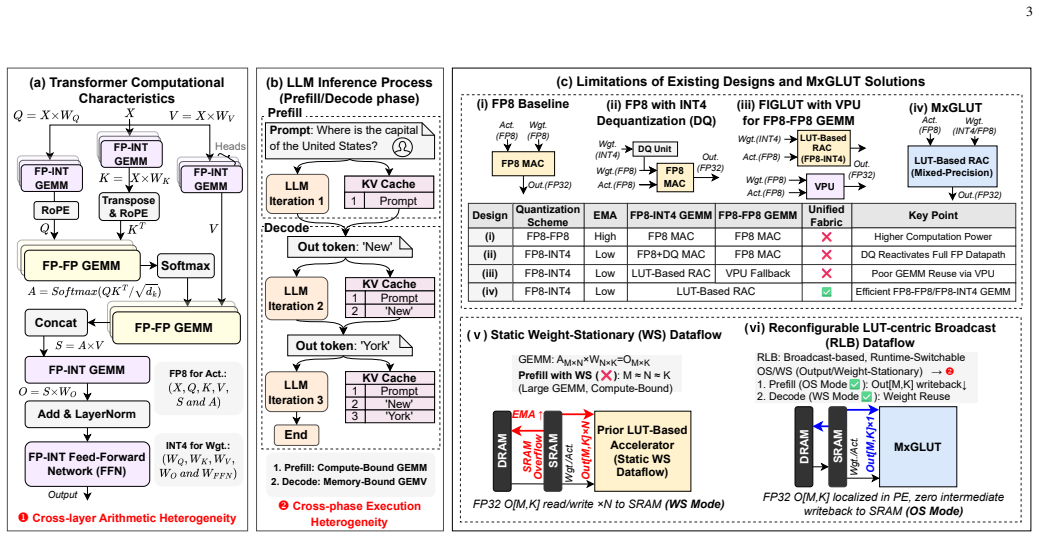
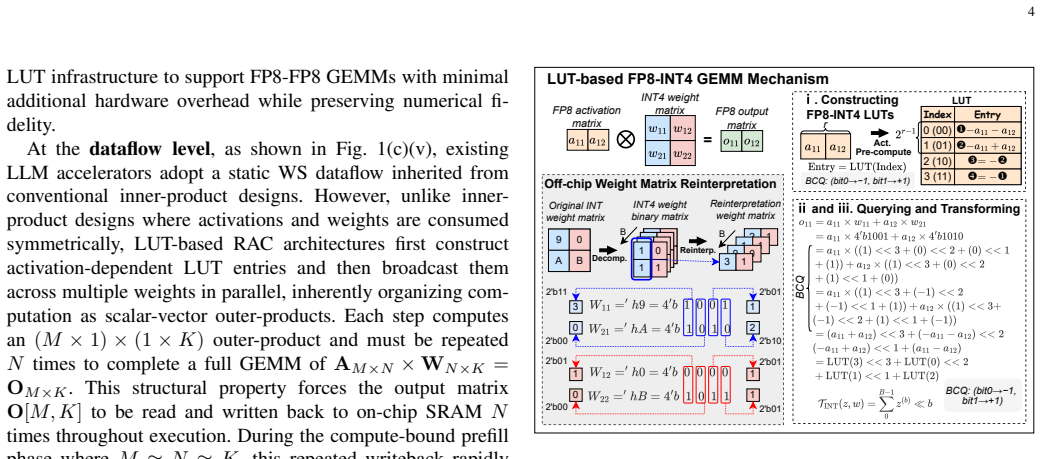
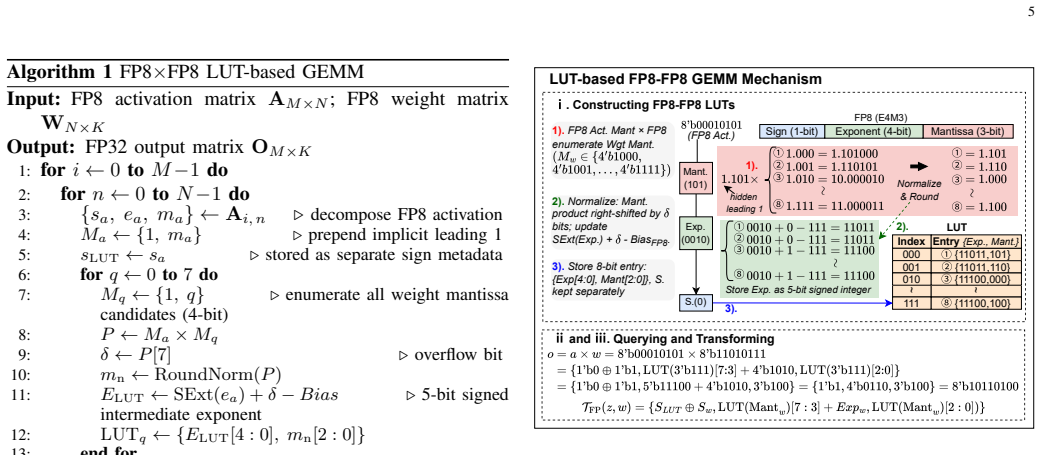
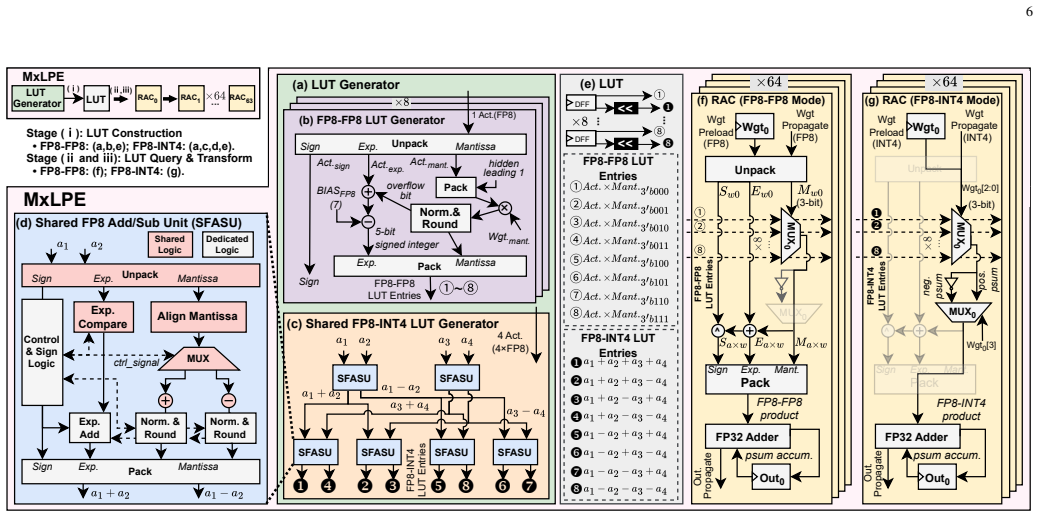
Large language model (LLM) inference suffers from growing inefficiency across the prefill and decode phases, especially under weight-only quantization, where activations remain in FP8 while weights are compressed to low-bit integers. Existing LUT-based accelerators mainly target FP8-INT4 computation and still rely on separate floating-point (FP) datapaths for attention GEMM operations, leading to redundant hardware and non-unified mixed-precision execution. Moreover, their static dataflows are poorly matched to the distinct prefill and decode phases. To address these challenges, we propose MxGLUT, a reconfigurable LUT-centric broadcast (RLB) dataflow accelerator built on mixed-precision LUT-based processing elements (MxLPEs). Guided by a unified LUT-based execution framework, MxGLUT organizes both FP8-INT4 and FP8-FP8 GEMMs under a single LUT-based compute mechanism without dedicated FP multipliers or additional FP datapaths, and further adopts the RLB dataflow that localizes heavy partial-sum accumulation during the prefill phase and exploits weight reuse in the decode phase. Synthesized in UMC $28\,\mathrm{nm}$ CMOS at $200~\mathrm{MHz}$, MxGLUT reduces multiplier area by up to $56.92\%$ and power by up to $77.07\%$ and $78.35\%$ in FP8-INT4 and FP8-FP8 modes, respectively. At the accelerator level, MxGLUT achieves an area efficiency of $0.492~\mathrm{TFLOPS/mm^2}$ and an energy efficiency of $11.58~\mathrm{TFLOPS/W}$, while adding native FP8-FP8 support incurs only $2.57\%$ and $3.34\%$ reductions in area and energy efficiency, respectively, relative to the FP8-INT4-only FIGLUT baseline. Across the Llama family, MxGLUT achieves up to $2.16\times$ and $1.49\times$ latency speedup, and reduces normalized energy to $0.44\times$ and $0.71\times$ in prefill and decode, respectively, with at most $1.70\%$ perplexity increase.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MxGLUT, a reconfigurable LUT-centric broadcast (RLB) dataflow accelerator for mixed-precision GEMM operations in large language model inference. It introduces mixed-precision LUT-based processing elements (MxLPEs) that unify FP8-INT4 and FP8-FP8 computations under a single LUT-based mechanism without dedicated floating-point multipliers or separate datapaths. The RLB dataflow is tailored to localize partial-sum accumulation in the prefill phase and exploit weight reuse in the decode phase. Based on synthesis in UMC 28nm CMOS at 200 MHz, the paper reports multiplier area reductions of up to 56.92%, power reductions of up to 77.07% and 78.35% in the respective modes, accelerator-level efficiencies of 0.492 TFLOPS/mm² and 11.58 TFLOPS/W, and up to 2.16× and 1.49× latency speedups in prefill and decode across Llama models with at most 1.70% perplexity increase compared to the FIGLUT baseline.
Significance. Should the synthesis-based claims prove accurate upon fabrication and integration, MxGLUT would offer a meaningful contribution to hardware acceleration for quantized LLM inference by providing a unified compute mechanism for mixed precisions and a phase-adaptive dataflow, potentially leading to more efficient designs that reduce hardware redundancy in attention and linear layers.
major comments (2)
- Abstract: The central efficiency claims, such as the 56.92% multiplier area reduction, 77.07% and 78.35% power reductions, 0.492 TFLOPS/mm² area efficiency, and 11.58 TFLOPS/W energy efficiency, along with the 2.57% and 3.34% overheads relative to FIGLUT, are presented without any error bars, details on the verification methodology, or discussion of post-synthesis versus post-layout differences; these metrics are load-bearing for the paper's assertions about the benefits of the MxLPE and RLB design.
- Performance claims section: The manuscript does not address how post-synthesis estimates at 200 MHz in 28nm CMOS account for interconnect parasitics, process variation, clock skew, or off-chip memory bandwidth and latency penalties, which the RLB dataflow is said to exploit; this omission directly affects the credibility of the reported system-level latency speedups (up to 2.16× prefill, 1.49× decode) and energy reductions (to 0.44× and 0.71×).
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the presentation of our synthesis results and the assumptions underlying our performance claims. We address each point below and will make targeted revisions to improve transparency without altering the core technical contributions.
read point-by-point responses
-
Referee: Abstract: The central efficiency claims, such as the 56.92% multiplier area reduction, 77.07% and 78.35% power reductions, 0.492 TFLOPS/mm² area efficiency, and 11.58 TFLOPS/W energy efficiency, along with the 2.57% and 3.34% overheads relative to FIGLUT, are presented without any error bars, details on the verification methodology, or discussion of post-synthesis versus post-layout differences; these metrics are load-bearing for the paper's assertions about the benefits of the MxLPE and RLB design.
Authors: The reported figures come from a single deterministic post-synthesis run in Synopsys Design Compiler using the UMC 28 nm library at a 200 MHz target clock period. Because the input netlist, constraints, and library are fixed, repeated synthesis runs produce identical results and statistical error bars are not applicable. We will add a dedicated paragraph in the evaluation section (and a brief note in the abstract if space allows) that (1) describes the exact synthesis flow, tool versions, power analysis settings, and area reporting methodology, and (2) explicitly states that all numbers are post-synthesis estimates that exclude place-and-route parasitics. We will also note that the RLB dataflow was deliberately designed to localize partial-sum traffic precisely to reduce the sensitivity to interconnect delay. revision: partial
-
Referee: Performance claims section: The manuscript does not address how post-synthesis estimates at 200 MHz in 28nm CMOS account for interconnect parasitics, process variation, clock skew, or off-chip memory bandwidth and latency penalties, which the RLB dataflow is said to exploit; this omission directly affects the credibility of the reported system-level latency speedups (up to 2.16× prefill, 1.49× decode) and energy reductions (to 0.44× and 0.71×).
Authors: We agree that post-synthesis results omit several second-order effects. The 200 MHz constraint is applied at the synthesis stage with ideal clock assumptions; process variation and clock skew are not modeled. Off-chip bandwidth is assumed to be non-limiting because the RLB dataflow keeps the majority of partial-sum traffic on-chip during prefill and reuses weights locally during decode. We will expand the evaluation discussion to list these modeling assumptions explicitly and to qualify that the reported speedups and energy ratios are relative to the baseline under identical synthesis conditions. Because the current manuscript contains only synthesis results, we cannot supply quantitative post-layout or silicon-corrected numbers. revision: partial
- Quantitative post-layout or silicon-level corrections for interconnect parasitics, process variation, clock skew, and off-chip memory penalties on the reported latency and energy figures.
Circularity Check
No circularity; all metrics are direct synthesis outputs vs external baselines
full rationale
The paper reports area, power, efficiency, and latency numbers exclusively from post-synthesis results in UMC 28nm at 200 MHz against the FIGLUT baseline and Llama models. No equations, fitted parameters, or self-citations are used to derive the headline claims; the RLB dataflow and MxLPE design choices are presented as engineering decisions whose benefits are measured externally. No self-definitional, fitted-input, or self-citation-load-bearing steps exist in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- Operating frequency =
200 MHz
axioms (2)
- domain assumption Post-synthesis estimates in commercial 28nm process accurately predict fabricated chip metrics without significant deviation from parasitics or variation.
- domain assumption The RLB dataflow incurs no hidden control or routing overheads that would alter the claimed prefill/decode speedups.
Reference graph
Works this paper leans on
-
[1]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “Gptq: Accurate post-training quantization for generative pre-trained transformers,”arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Awq: Activation-aware weight quanti- zation for on-device llm compression and acceleration,
J. Lin, J. Tang, H. Tang, S. Yang, W.-M. Chen, W.-C. Wang, G. Xiao, X. Dang, C. Gan, and S. Han, “Awq: Activation-aware weight quanti- zation for on-device llm compression and acceleration,”Proceedings of machine learning and systems, vol. 6, pp. 87–100, 2024. 13
2024
-
[3]
Mitigating quantization errors due to activation spikes in glu-based llms,
J. Yang, H. Kim, and Y . Kim, “Mitigating quantization errors due to activation spikes in glu-based llms,”arXiv preprint arXiv:2405.14428, 2024
-
[4]
Qqq: Quality quattuor-bit quantization for large language models,
Y . Zhang, P. Zhang, M. Huang, J. Xiang, Y . Wang, C. Wang, Y . Zhang, L. Yu, C. Liu, and W. Lin, “Qqq: Quality quattuor-bit quantization for large language models,”arXiv preprint arXiv:2406.09904, 2024
-
[5]
Qserve: W4a8kv4 quantization and system co-design for efficient llm serving,
Y . Lin, H. Tang, S. Yang, Z. Zhang, G. Xiao, C. Gan, and S. Han, “Qserve: W4a8kv4 quantization and system co-design for efficient llm serving,”arXiv preprint arXiv:2405.04532, 2024
-
[6]
Post-training quantization of openpangu models for efficient deployment on atlas a2,
Y . Luo, H. Zheng, H. Meng, W. Liu, and P. Zhang, “Post-training quantization of openpangu models for efficient deployment on atlas a2,” 2026. [Online]. Available: https://arxiv.org/abs/2512.23367
-
[7]
Zeroquant-fp: A leap forward in llms post- training w4a8 quantization using floating-point formats,
X. Wu, Z. Yao, and Y . He, “Zeroquant-fp: A leap forward in llms post- training w4a8 quantization using floating-point formats,”arXiv preprint arXiv:2307.09782, 2023
-
[8]
A survey of low-bit large language models: Basics, systems, and algorithms,
R. Gong, Y . Ding, Z. Wang, C. Lv, X. Zheng, J. Du, H. Qin, J. Guo, M. Magno, and X. Liu, “A survey of low-bit large language models: Basics, systems, and algorithms,”arXiv preprint arXiv:2409.16694, 2024
-
[9]
G. Park, B. Park, M. Kim, S. Lee, J. Kim, B. Kwon, S. J. Kwon, B. Kim, Y . Lee, and D. Lee, “Lut-gemm: Quantized matrix multiplication based on luts for efficient inference in large-scale generative language models,” arXiv preprint arXiv:2206.09557, 2022
-
[10]
Figlut: An energy-efficient accelerator design for fp-int gemm using look-up tables,
G. Park, H. Kwon, J. Kim, J. Bae, B. Park, D. Lee, and Y . Lee, “Figlut: An energy-efficient accelerator design for fp-int gemm using look-up tables,” in2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2025, pp. 1098–1111
2025
-
[11]
Alternating Multi-bit Quantization for Recurrent Neural Networks
C. Xu, J. Yao, Z. Lin, W. Ou, Y . Cao, Z. Wang, and H. Zha, “Alternating multi-bit quantization for recurrent neural networks,”arXiv preprint arXiv:1802.00150, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Lut tensor core: A software-hardware co-design for lut-based low-bit llm inference,
Z. Mo, L. Wang, J. Wei, Z. Zeng, S. Cao, L. Ma, N. Jing, T. Cao, J. Xue, F. Yanget al., “Lut tensor core: A software-hardware co-design for lut-based low-bit llm inference,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, 2025, pp. 514–528
2025
-
[13]
M. V . Maceiras,Extending Vector Processing Units for Enhanced Linear Algebra Performance. Chalmers Tekniska Hogskola (Sweden), 2024
2024
-
[14]
Gemmini: Enabling systematic deep- learning architecture evaluation via full-stack integration,
H. Genc, S. Kim, A. Amid, A. Haj-Ali, V . Iyer, P. Prakash, J. Zhao, D. Grubb, H. Liew, H. Maoet al., “Gemmini: Enabling systematic deep- learning architecture evaluation via full-stack integration,” in2021 58th ACM/IEEE Design Automation Conference (DAC). IEEE, 2021, pp. 769–774
2021
-
[15]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[17]
A 16-nm soc for noise-robust speech and nlp edge ai inference with bayesian sound source separation and attention-based dnns,
T. Tambe, E.-Y . Yang, G. G. Ko, Y . Chai, C. Hooper, M. Donato, P. N. Whatmough, A. M. Rush, D. Brooks, and G.-Y . Wei, “A 16-nm soc for noise-robust speech and nlp edge ai inference with bayesian sound source separation and attention-based dnns,”IEEE Journal of Solid-State Circuits, vol. 58, no. 2, pp. 569–581, 2022
2022
-
[18]
S. Kim, S. Kim, W. Jo, S. Kim, S. Hong, and H.-J. Yoo, “20.5 c- transformer: A 2.6-18.1µj/token homogeneous dnn-transformer/spiking- transformer processor with big-little network and implicit weight gener- ation for large language models,” in2024 IEEE International Solid-State Circuits Conference (ISSCC), vol. 67. IEEE, 2024, pp. 368–370
2024
-
[19]
A 22nm 54.94tflops/w transformer fine-tuning pro- cessor with exponent-stationary re-computing, aggressive linear fitting, and logarithmic domain multiplicating,
Y . Wang, X. Yang, Y . Qin, Z. Zhao, R. Guo, Z. Yue, H. Han, S. Wei, Y . Hu, and S. Yin, “A 22nm 54.94tflops/w transformer fine-tuning pro- cessor with exponent-stationary re-computing, aggressive linear fitting, and logarithmic domain multiplicating,” in2024 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), 2024, pp. 1–2
2024
-
[20]
Dadiannao: A machine-learning supercomputer,
Y . Chen, T. Luo, S. Liu, S. Zhang, L. He, J. Wang, L. Li, T. Chen, Z. Xu, N. Sunet al., “Dadiannao: A machine-learning supercomputer,” in2014 47th Annual IEEE/ACM international symposium on microarchitecture. IEEE, 2014, pp. 609–622
2014
-
[21]
In-datacenter performance analysis of a tensor processing unit,
N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borcherset al., “In-datacenter performance analysis of a tensor processing unit,” inProceedings of the 44th annual international symposium on computer architecture, 2017, pp. 1–12
2017
-
[22]
Inca: Input-stationary dataflow at outside- the-box thinking about deep learning accelerators,
B. Kim, S. Li, and H. Li, “Inca: Input-stationary dataflow at outside- the-box thinking about deep learning accelerators,” in2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2023, pp. 29–41
2023
-
[23]
Dpima: A dram-based processing-in-memory accelerator for privacy-preserving machine learning,
B. Kim, “Dpima: A dram-based processing-in-memory accelerator for privacy-preserving machine learning,” in2025 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED). IEEE, 2025, pp. 1–7
2025
-
[24]
Dip: A scalable, energy-efficient systolic array for matrix multiplication acceleration,
A. J. Abdelmaksoud, S. Agwa, and T. Prodromakis, “Dip: A scalable, energy-efficient systolic array for matrix multiplication acceleration,” IEEE Transactions on Circuits and Systems I: Regular Papers, 2025
2025
-
[25]
Cacti 7: New tools for interconnect exploration in innovative off-chip memories,
R. Balasubramonian, A. B. Kahng, N. Muralimanohar, A. Shafiee, and V . Srinivas, “Cacti 7: New tools for interconnect exploration in innovative off-chip memories,”ACM Transactions on Architecture and Code Optimization (TACO), vol. 14, no. 2, pp. 1–25, 2017
2017
-
[26]
Timeloop: A systematic approach to dnn accelerator evaluation,
A. Parashar, P. Raina, Y . S. Shao, Y .-H. Chen, V . A. Ying, A. Mukkara, R. Venkatesan, B. Khailany, S. W. Keckler, and J. Emer, “Timeloop: A systematic approach to dnn accelerator evaluation,” in2019 IEEE inter- national symposium on performance analysis of systems and software (ISPASS). IEEE, 2019, pp. 304–315
2019
-
[27]
Winning both the accuracy of floating point activation and the simplicity of integer arithmetic,
Y . Kim, J. Jang, J. Lee, J. Park, J. Kim, B. Kim, S. J. Kwon, D. Lee et al., “Winning both the accuracy of floating point activation and the simplicity of integer arithmetic,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[28]
Desa: Dataflow efficient systolic array for acceleration of transformers,
Z. Wang, H. Fan, and G. He, “Desa: Dataflow efficient systolic array for acceleration of transformers,”IEEE Transactions on Computers, 2025
2025
-
[29]
Pointer sentinel mixture models,
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,” 2016
2016
-
[30]
Shiftaddllm: Accelerating pretrained llms via post-training multiplication-less reparameterization,
H. You, Y . Guo, Y . Fu, W. Zhou, H. Shi, X. Zhang, S. Kundu, A. Yazdanbakhsh, and Y . C. Lin, “Shiftaddllm: Accelerating pretrained llms via post-training multiplication-less reparameterization,”Advances in Neural Information Processing Systems, vol. 37, pp. 24 822–24 848, 2024
2024
-
[31]
22.9 a 12nm 18.1tflops/w sparse transformer processor with entropy-based early exit, mixed-precision predication and fine-grained power management,
T. Tambe, J. Zhang, C. Hooper, T. Jia, P. N. Whatmough, J. Zuckerman, M. C. D. Santos, E. J. Loscalzo, D. Giri, K. Shepard, L. Carloni, A. Rush, D. Brooks, and G.-Y . Wei, “22.9 a 12nm 18.1tflops/w sparse transformer processor with entropy-based early exit, mixed-precision predication and fine-grained power management,” in2023 IEEE Inter- national Solid-S...
2023
-
[32]
A 28nm 27.5 tops/w approximate-computing- based transformer processor with asymptotic sparsity speculating and out-of-order computing,
Y . Wang, Y . Qin, D. Deng, J. Wei, Y . Zhou, Y . Fan, T. Chen, H. Sun, L. Liu, S. Weiet al., “A 28nm 27.5 tops/w approximate-computing- based transformer processor with asymptotic sparsity speculating and out-of-order computing,” in2022 IEEE international solid-state circuits conference (ISSCC), vol. 65. IEEE, 2022, pp. 1–3
2022
-
[33]
T-rex: A 68-to-567µs/token 0.41-to-3.95µj/token transformer accelerator with reduced external memory access and enhanced hardware utilization in 16nm finfet,
S. Moon, M. Li, G. K. Chen, P. C. Knag, R. K. Krishnamurthy, and M. Seok, “T-rex: A 68-to-567µs/token 0.41-to-3.95µj/token transformer accelerator with reduced external memory access and enhanced hardware utilization in 16nm finfet,” in2025 IEEE International Solid-State Circuits Conference (ISSCC), vol. 68. IEEE, 2025, pp. 406–408
2025
-
[34]
A 22nm 25.08 tops/w multi- task transformer accelerator with mixed precision structured sparsity and two-stage task-adaptive power management,
Z. Fan, Q. Zhang, P. Abillama, S. Shoori, J. Lee, C.-W. Tseng, W. Meng, H.-S. Kim, D. Blaauw, and D. Sylvester, “A 22nm 25.08 tops/w multi- task transformer accelerator with mixed precision structured sparsity and two-stage task-adaptive power management,” in2025 Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits). IEEE, 2025, pp. 1–3
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.