Personality Without Persons? A Psychometric Critique of Big Five Testing in Large Language Models
Pith reviewed 2026-07-03 05:57 UTC · model grok-4.3
The pith
Big Five personality inventories do not measure an equivalent construct in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
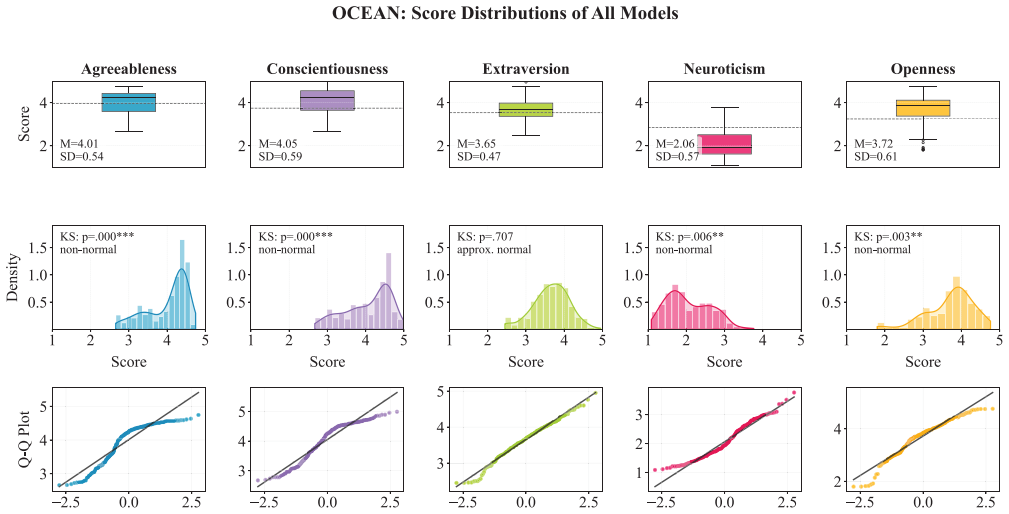
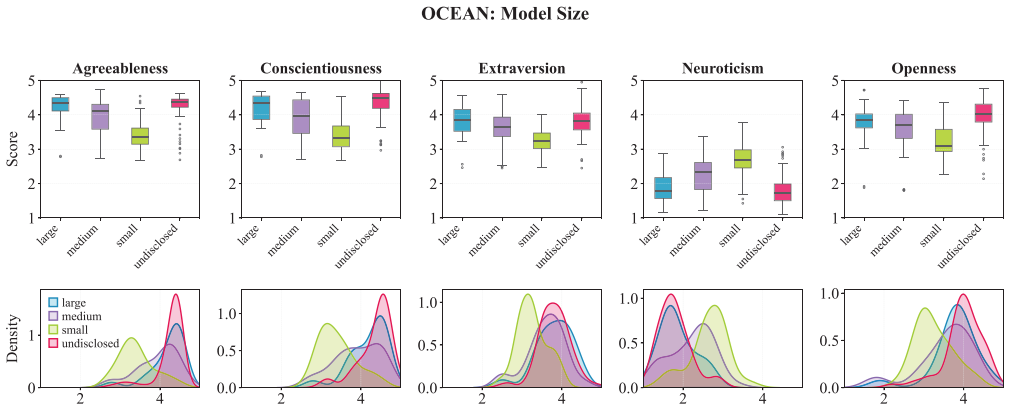
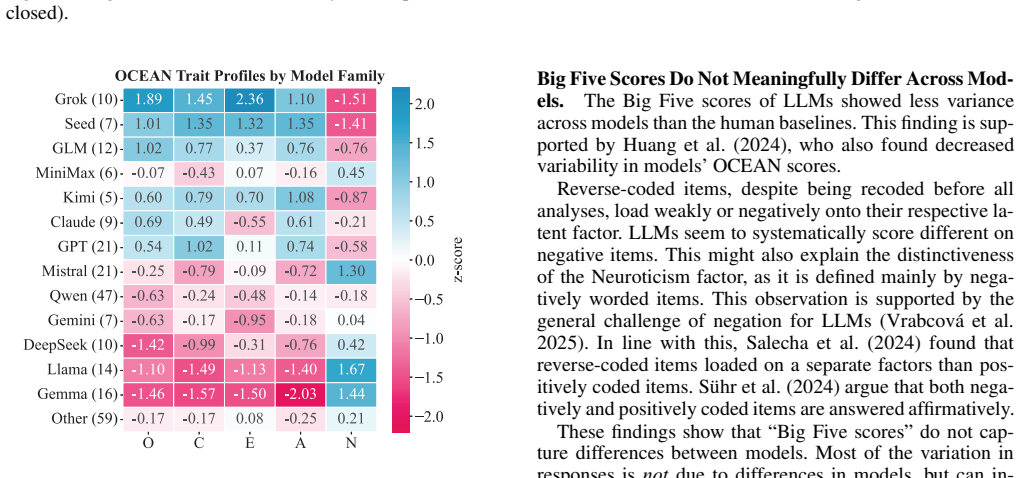
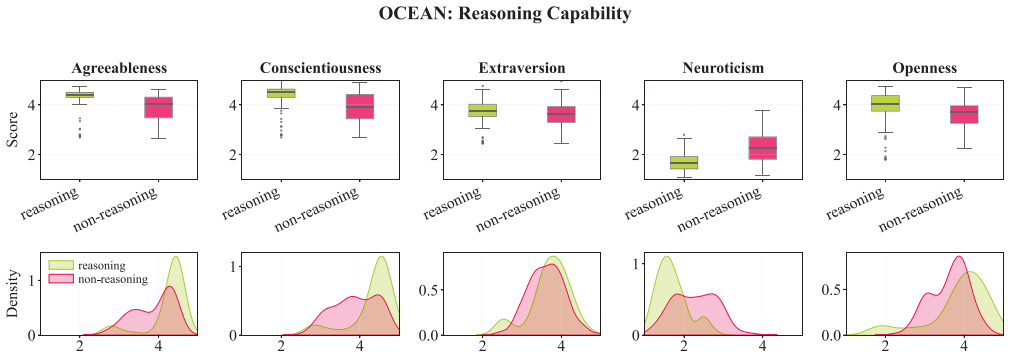
Big Five inventories adapted for LLMs reach sufficient content validity, but when administered to 244 models they capture only 3 percent of total score variance between models and fail to recover the five-factor structure, with four of the five facets collapsing into a single dimension at r greater than or equal to .92; direct base-versus-instruction-tuned comparisons show alignment training systematically moves scores toward socially desirable traits.
What carries the argument
Psychometric evaluation of content validity followed by administration of the highest-validity inventory and confirmatory factor analysis on LLM response patterns.
If this is right
- Big Five scores cannot be used to benchmark or compare LLMs because they explain almost none of the between-model differences.
- Four of the five Big Five facets behave as a single dimension in LLM responses.
- Alignment training produces consistent shifts in measured traits toward socially desirable responses.
- Governance or safety claims based on Big Five LLM profiles rest on an unvalidated human construct.
Where Pith is reading between the lines
- New trait inventories built from LLM response distributions rather than human item pools would be required before personality-like constructs can support cross-model comparisons.
- The collapse of facets may reflect the statistical regularities of next-token prediction rather than any internal motivational structure.
- Repeated use of human inventories risks entrenching anthropomorphic assumptions in AI evaluation standards.
Load-bearing premise
That content-valid adapted items plus standard factor analysis on LLM responses suffice to conclude the inventories do not measure a human-equivalent personality construct.
What would settle it
Administering a new set of LLM-native items that recover five orthogonal factors with high inter-model variance and no collapse under the same 244-model sample would falsify the claim.
Figures



read the original abstract
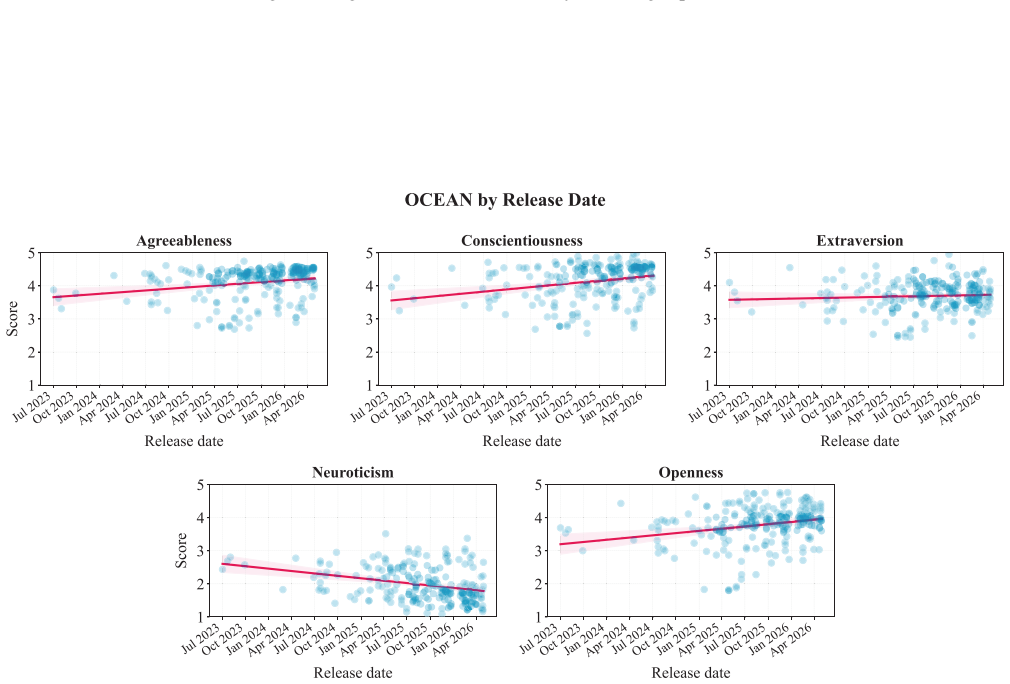
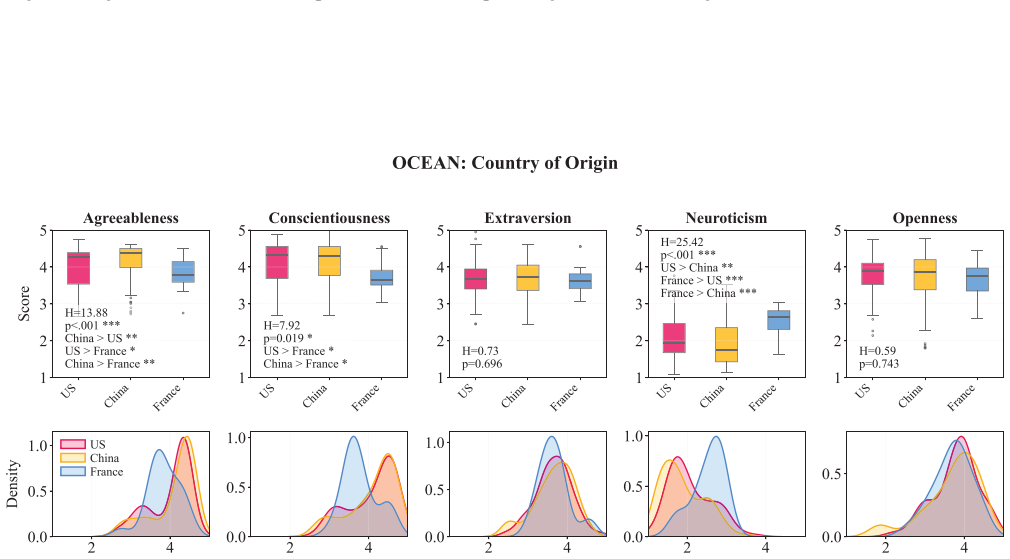
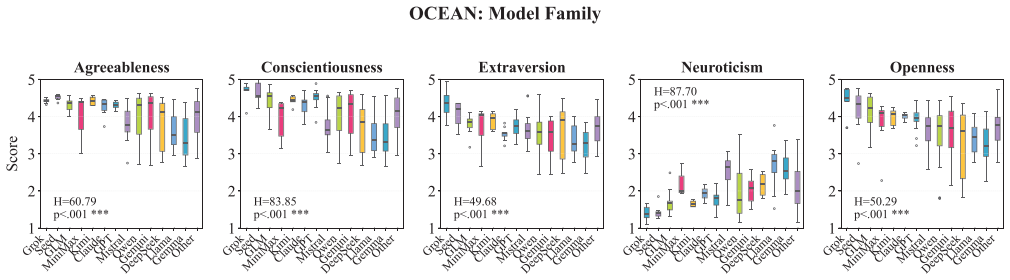
Human personality inventories are increasingly used to characterize large language models (LLMs), compare systems, and inform downstream governance claims. Yet, these inventories were developed and validated for humans, and it remains unclear whether they apply to LLMs. We present a systematic psychometric evaluation of Big Five personality measurements in LLMs. We ask three research questions: Do Big Five inventories a) appropriately describe LLMs, b) capture inter-individual differences across models, and c) reflect internal factors consistent with human personality. We assess content validity of five candidate Big Five inventories and administer the winning inventory to N = 244 different models spanning 49 model families. First, we found that Big Five items adapted for LLMs can reach sufficient content validity, while original human-developed items did not. Second, Big Five inventories did not capture meaningful differences between LLMs: We found low variability between models, accounting for only 3% of total score variance. Third, LLMs responses did not recover the Big Five five-factor structure with four of the Big Five facets collapsing into one (r >= .92). Direct comparisons between base and instruction-tuned model variants suggested that alignment training systematically shifted Big Five scores toward socially desirable traits. These findings demonstrate that Big Five scores do not measure a construct equivalent to human personality in LLMs. Applying human personality frameworks to LLMs produces misleading characterizations used to benchmark, compare, and govern LLMs. We highlight the need for evaluation frameworks that are developed for LLMs, rather than adopting human constructs without validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a psychometric evaluation of Big Five inventories on LLMs, addressing three questions on content validity, inter-model differences, and internal factor structure. Using N=244 models across 49 families, it reports that adapted items achieve content validity but original items do not; between-model variance accounts for only 3% of total score variance; LLM responses fail to recover the five-factor structure (four facets collapse with r >= .92); and alignment training shifts scores toward socially desirable traits. The authors conclude that Big Five scores do not measure an equivalent construct to human personality in LLMs and should not be used for benchmarking or governance without LLM-specific validation.
Significance. If the central empirical findings hold after addressing methodological concerns, the work provides a valuable cautionary demonstration against uncritical transfer of human psychometric tools to LLMs. The broad sampling across model families and direct comparison of base vs. instruction-tuned variants strengthen the case for reevaluating current practices in AI personality assessment. The study is a direct measurement effort without circular derivations, and its emphasis on developing LLM-native evaluation frameworks addresses a timely gap in the field.
major comments (2)
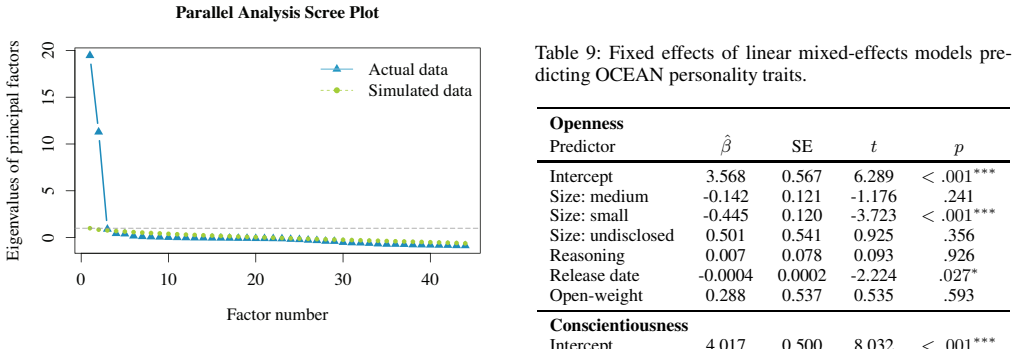
- [Abstract / Results (research question c)] Abstract and results on research question (c): the claim that non-recovery of the five-factor structure demonstrates absence of an equivalent construct is undermined by the reported low between-model variance (only 3% of total score variance). Treating the 244 models as 'individuals' for factor analysis in a sample with such restricted range makes high inter-facet correlations (r >= .92) and facet collapse the statistically expected outcome even if the items tap distinct latent dimensions; the non-recovery cannot be unambiguously attributed to lack of the human-like construct rather than homogeneity of the model sample.
- [Methods] Methods: the manuscript lacks full reporting of statistical procedures for the factor analysis, details on model sampling and selection criteria for the N=244 models, and error-bar or uncertainty quantification on the reported variance percentages and correlations. These omissions limit evaluation of whether the 3% between-model variance and factor results are robust.
minor comments (1)
- [Abstract] Abstract: the phrasing 'LLMs responses did not recover' should be 'LLM responses did not recover' for grammatical consistency.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Results (research question c)] Abstract and results on research question (c): the claim that non-recovery of the five-factor structure demonstrates absence of an equivalent construct is undermined by the reported low between-model variance (only 3% of total score variance). Treating the 244 models as 'individuals' for factor analysis in a sample with such restricted range makes high inter-facet correlations (r >= .92) and facet collapse the statistically expected outcome even if the items tap distinct latent dimensions; the non-recovery cannot be unambiguously attributed to lack of the human-like construct rather than homogeneity of the model sample.
Authors: We agree that range restriction is a relevant statistical consideration when interpreting the factor-analytic results. The 3% between-model variance is itself a primary empirical result demonstrating that the inventories fail to capture meaningful differences across LLMs. We will revise the abstract and the discussion of research question (c) to explicitly note the potential contribution of restricted range to the observed facet collapse (r >= .92) while maintaining that the combination of negligible inter-model variance and failure to recover the expected structure constitutes evidence against construct equivalence. We will add a dedicated limitations paragraph addressing range restriction and its implications for factor recovery. This is a partial revision, as we refine the framing but do not alter the core conclusions. revision: partial
-
Referee: [Methods] Methods: the manuscript lacks full reporting of statistical procedures for the factor analysis, details on model sampling and selection criteria for the N=244 models, and error-bar or uncertainty quantification on the reported variance percentages and correlations. These omissions limit evaluation of whether the 3% between-model variance and factor results are robust.
Authors: We thank the referee for identifying these reporting omissions. In the revised manuscript we will expand the Methods section to provide: (1) complete specification of the factor analysis (extraction method, rotation, and factor-retention criteria); (2) explicit sampling criteria, sources, and inclusion rules for the 244 models across 49 families; and (3) uncertainty estimates (e.g., bootstrap confidence intervals) for the variance-component percentages and inter-facet correlations. These additions will enable readers to evaluate the robustness of the reported results. revision: yes
Circularity Check
Empirical measurement study with no circular derivations or self-referential reductions
full rationale
The paper performs direct empirical measurements: content validity assessment of inventories, administration to N=244 models, variance decomposition (reporting 3% between-model variance), and standard factor analysis on item responses. No equations, predictions, or fitted parameters are presented as independent results; all reported quantities are computed directly from the LLM response data. No self-citations are load-bearing for the central claims, and no uniqueness theorems or ansatzes are imported. The analysis is self-contained against external psychometric benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard psychometric procedures (content validity assessment and exploratory factor analysis) remain valid when applied to LLM-generated responses.
Reference graph
Works this paper leans on
-
[1]
West , title =
Sandra Peter and Kai Riemer and Jevin D. West , title =. Proceedings of the National Academy of Sciences , volume =. 2025 , doi =
2025
-
[2]
and Whiteman, Martha C
Matthews, Gerald and Deary, Ian J. and Whiteman, Martha C. , year =. Applications of personality assessment , booktitle =
-
[3]
Personality stability and its implications for clinical psychology , journal =. 1986 , note =. doi:https://doi.org/10.1016/0272-7358(86)90029-2 , url =
-
[4]
Computational Linguistics , volume =
Zheng, Jingyao and Wang, Xian and Hosio, Simo and Xu, Xiaoxian and Lee, Lik-Hang , title =. Computational Linguistics , volume =. 2025 , month =. doi:10.1162/coli_a_00550 , url =
-
[5]
2023 , eprint =
Evaluating and Inducing Personality in Pre-trained Language Models , author =. 2023 , eprint =
2023
-
[6]
Salecha, Aadesh and Ireland, Molly E and Subrahmanya, Shashanka and Sedoc, João and Ungar, Lyle H and Eichstaedt, Johannes C , title =. PNAS Nexus , volume =. 2024 , month =. doi:10.1093/pnasnexus/pgae533 , url =
-
[7]
2025 , eprint =
Designing AI-Agents with Personalities: A Psychometric Approach , author =. 2025 , eprint =
2025
-
[8]
2025 , eprint =
Exploring the Potential of Large Language Models to Simulate Personality , author =. 2025 , eprint =
2025
-
[9]
2023 , eprint =
Estimating the Personality of White-Box Language Models , author =. 2023 , eprint =
2023
-
[10]
2025 , eprint =
Scaling Law in LLM Simulated Personality: More Detailed and Realistic Persona Profile Is All You Need , author =. 2025 , eprint =
2025
-
[11]
2025 , eprint =
Do LLMs Have Distinct and Consistent Personality? TRAIT: Personality Testset designed for LLMs with Psychometrics , author =. 2025 , eprint =
2025
-
[12]
Large Language Models for Scientific and Societal Advances , year =
Evaluating Large Language Models with Psychometrics , author =. Large Language Models for Scientific and Societal Advances , year =
-
[13]
2024 , eprint =
Challenging the Validity of Personality Tests for Large Language Models , author =. 2024 , eprint =
2024
-
[14]
Romero, Peter and Fitz, Stephen and Nakatsuma, Teruo , year =. Do GPT Language Models Suffer From Split Personality Disorder? The Advent Of Substrate-Free Psychometrics , url =. doi:10.21203/rs.3.rs-2717108/v1 , publisher =
-
[15]
2025 , eprint =
Persistent Instability in LLM's Personality Measurements: Effects of Scale, Reasoning, and Conversation History , author =. 2025 , eprint =
2025
-
[16]
2025 , eprint =
Beyond Self-Reports: Multi-Observer Agents for Personality Assessment in Large Language Models , author =. 2025 , eprint =
2025
-
[17]
Journal of Personality , author =
An. Journal of Personality , author =. 1992 , pages =. doi:10.1111/j.1467-6494.1992.tb00970.x , language =
-
[18]
, year =
McAdams, Dan P. , year =. The emergence of personality , isbn =. Handbook of personality development , publisher =
-
[19]
Ben-Porath, Yossef S. and Butcher, James N. , editor =. The Historical Development of Personality Assessment , bookTitle =. 1991 , publisher =. doi:10.1007/978-1-4757-9715-2_5 , url =
-
[20]
2017 , publisher =
Personality Psychology: Domains of Knowledge about Human Nature , author =. 2017 , publisher =
2017
-
[21]
2003 , publisher =
Personality Traits , author =. 2003 , publisher =
2003
-
[22]
Human Behavior and Emerging Technologies , volume =
Rutinowski, Jérôme and Franke, Sven and Endendyk, Jan and Dormuth, Ina and Roidl, Moritz and Pauly, Markus , title =. Human Behavior and Emerging Technologies , volume =. doi:https://doi.org/10.1155/2024/7115633 , url =
-
[23]
2024 , eprint =
Revisiting the Reliability of Psychological Scales on Large Language Models , author =. 2024 , eprint =
2024
-
[24]
and Bojić, Ljubiša , title =
Bodroža, Bojana and Dinić, Bojana M. and Bojić, Ljubiša , title =. Royal Society Open Science , volume =. 2024 , doi =
2024
-
[25]
2024 , eprint =
LLMs Simulate Big Five Personality Traits: Further Evidence , author =. 2024 , eprint =
2024
-
[26]
2022 , eprint =
Discovering Language Model Behaviors with Model-Written Evaluations , author =. 2022 , eprint =
2022
-
[27]
2024 , eprint =
Eliciting Personality Traits in Large Language Models , author =. 2024 , eprint =
2024
-
[28]
Hartley, John and Hamill, Conor Brian and Seddon, Dale and Batra, Devesh and Okhrati, Ramin and Khraishi, Raad , editor =. How Personality Traits Shape. Findings of the Association for Computational Linguistics: ACL 2025 , month = jul, year =. doi:10.18653/v1/2025.findings-acl.1085 , pages =
-
[29]
Lechner and Claudia Wagner and Beatrice Rammstedt and Markus Strohmaier , title =
Max Pellert and Clemens M. Lechner and Claudia Wagner and Beatrice Rammstedt and Markus Strohmaier , title =. Perspectives on Psychological Science , volume =. 2024 , doi =
2024
-
[30]
2025 , eprint =
AIPsychoBench: Understanding the Psychometric Differences between LLMs and Humans , author =. 2025 , eprint =
2025
-
[31]
Shu, Bangzhao and Zhang, Lechen and Choi, Minje and Dunagan, Lavinia and Logeswaran, Lajanugen and Lee, Moontae and Card, Dallas and Jurgens, David , editor =. You don. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , month = jun, year =...
-
[32]
Völkel, Sarah Theres and Schödel, Ramona and Buschek, Daniel and Stachl, Clemens and Winterhalter, Verena and Bühner, Markus and Hussmann, Heinrich , year =. Developing a Personality Model for Speech-based Conversational Agents Using the Psycholexical Approach , url =. doi:10.1145/3313831.3376210 , booktitle =
-
[33]
The Personality Dimensions GPT-3 Expresses During Human-Chatbot Interactions , year =
Kova. The Personality Dimensions GPT-3 Expresses During Human-Chatbot Interactions , year =. doi:10.1145/3659626 , journal =
-
[34]
Goldberg, Lewis R. , title =. Psychological Assessment , year =. doi:10.1037/1040-3590.4.1.26 , publisher =
-
[35]
2025 , eprint =
Personality Traits in Large Language Models , author =. 2025 , eprint =
2025
-
[36]
Proceedings of the 1st Workshop on Personalization of Generative AI Systems (PERSONALIZE 2024) , month = mar, year =
"LLM" Agents in Interaction: Measuring Personality Consistency and Linguistic Alignment in Interacting Populations of Large Language Models , author =. Proceedings of the 1st Workshop on Personalization of Generative AI Systems (PERSONALIZE 2024) , month = mar, year =
2024
-
[37]
2025 , eprint =
The Personality Illusion: Revealing Dissociation Between Self-Reports & Behavior in LLMs , author =. 2025 , eprint =
2025
-
[38]
2024 , eprint =
Is Self-knowledge and Action Consistent or Not: Investigating Large Language Model's Personality , author =. 2024 , eprint =
2024
-
[39]
Self-report
Can LLM "Self-report"?: Evaluating the Validity of Self-report Scales in Measuring Personality Design in LLM-based Chatbots , author =. 2025 , eprint =
2025
-
[40]
2024 , eprint =
PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits , author =. 2024 , eprint =
2024
-
[41]
2024 , eprint =
Neuron-based Personality Trait Induction in Large Language Models , author =. 2024 , eprint =
2024
-
[42]
2023 , eprint =
Large Language Models as Superpositions of Cultural Perspectives , author =. 2023 , eprint =
2023
-
[43]
Xing, Jane and Niu, Tianyi and Srivastava, Shashank , editor =. Chameleon. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2025.emnlp-main.875 , pages =
-
[44]
Goldberg, Lewis R. , year =. An alternative "description of personality":. Journal of Personality and Social Psychology , publisher =. doi:10.1037/0022-3514.59.6.1216 , number =
-
[45]
2025 , eprint =
PsyPlay: Personality-Infused Role-Playing Conversational Agents , author =. 2025 , eprint =
2025
-
[46]
2025 , eprint =
BIG5-CHAT: Shaping LLM Personalities Through Training on Human-Grounded Data , author =. 2025 , eprint =
2025
-
[47]
2025 , eprint =
PersLLM: A Personified Training Approach for Large Language Models , author =. 2025 , eprint =
2025
-
[48]
2024 , eprint =
PersonalityChat: Conversation Distillation for Personalized Dialog Modeling with Facts and Traits , author =. 2024 , eprint =
2024
-
[49]
Frontiers in Psychology , VOLUME =
Sartori, Giuseppe and Orrù, Graziella , TITLE =. Frontiers in Psychology , VOLUME =. 2023 , URL =. doi:10.3389/fpsyg.2023.1279317 , ISSN =
-
[50]
Assessing the Impact of Chatbot-Human Personality Congruence on User Behavior: A Chatbot-Based Advising System Case , year =
Kuhail, Mohammad Amin and Bahja, Mohamed and Al-Shamaileh, Ons and Thomas, Justin and Alkazemi, Amina and Negreiros, Joao , journal =. Assessing the Impact of Chatbot-Human Personality Congruence on User Behavior: A Chatbot-Based Advising System Case , year =
-
[51]
2024 , eprint =
The Effects of Embodiment and Personality Expression on Learning in LLM-based Educational Agents , author =. 2024 , eprint =
2024
-
[52]
Chatbots With Attitude: Enhancing Chatbot Interactions Through Dynamic Personality Infusion , year =
Kova. Chatbots With Attitude: Enhancing Chatbot Interactions Through Dynamic Personality Infusion , year =. doi:10.1145/3640794.3665543 , booktitle =
-
[53]
Moilanen, Joonas and Visuri, Aku and Suryanarayana, Sharadhi Alape and Alorwu, Andy and Yatani, Koji and Hosio, Simo , title =. 2022 , isbn =. doi:10.1145/3568444.3568464 , booktitle =
-
[54]
Lee, Jungjae and Choi, Yubin and Song, Minhyuk and Park, Sanghyun , title =. 2024 , isbn =. doi:10.1145/3640794.3665572 , booktitle =
-
[55]
Personality-Matched AI Chatbots: Measuring User Experience Based on Extraversion Scores , year =
S. Personality-Matched AI Chatbots: Measuring User Experience Based on Extraversion Scores , year =
-
[56]
2026 , eprint=
Bowling with ChatGPT: On the Evolving User Interactions with Conversational AI Systems , author=. 2026 , eprint=
2026
-
[57]
Journal of social issues , volume=
Machines and mindlessness: Social responses to computers , author=. Journal of social issues , volume=. 2000 , publisher=
2000
-
[58]
INTERACT'93 and CHI'93 conference companion on Human factors in computing systems , pages=
Anthropomorphism, agency, and ethopoeia: computers as social actors , author=. INTERACT'93 and CHI'93 conference companion on Human factors in computing systems , pages=
-
[59]
Ai & Society , volume=
The quest for appropriate models of human-likeness: anthropomorphism in media equation research , author=. Ai & Society , volume=. 2018 , publisher=
2018
-
[60]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
From" AI" to Probabilistic Automation: How Does Anthropomorphization of Technical Systems Descriptions Influence Trust? , author=. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
2024
-
[61]
, author=
The development of markers for the Big-Five factor structure. , author=. Psychological assessment , volume=. 1992 , publisher=
1992
-
[62]
Proceedings of the National Academy of Sciences , volume=
The benefits and dangers of anthropomorphic conversational agents , author=. Proceedings of the National Academy of Sciences , volume=. 2025 , publisher=
2025
-
[63]
Published as , year=
The Big-Five trait taxonomy: History, measurement, and theoretical perspectives , author=. Published as , year=
-
[64]
description of personality
An alternative “description of personality”: The Big-Five factor structure , author=. Personality and personality disorders , pages=. 2013 , publisher=
2013
-
[65]
, author=
Universal features of personality traits from the observer's perspective: data from 50 cultures. , author=. Journal of personality and social psychology , volume=. 2005 , publisher=
2005
-
[66]
Chapter 5 - Computers as persuasive social actors , booktitle =. 2003 , series =. doi:https://doi.org/10.1016/B978-155860643-2/50007-X , url =
-
[67]
2024 , eprint =
Evaluating Psychological Safety of Large Language Models , author =. 2024 , eprint =
2024
-
[68]
2024 , url =
Python Language Reference , version =. 2024 , url =
2024
-
[69]
van Rossum, Guido , title =
-
[70]
and Srivastava, Sanjay , title =
John, Oliver P. and Srivastava, Sanjay , title =. Handbook of Personality: Theory and Research , editor =. 1999 , publisher =
1999
-
[71]
Nursing research , volume=
Determination and quantification of content validity , author=. Nursing research , volume=. 1986 , publisher=
1986
-
[72]
Research in Nursing & Health , author =
Is the. Research in Nursing & Health , author =. 2007 , pages =. doi:10.1002/nur.20199 , language =
-
[73]
2014 , publisher =
Gwet, Kilem Li , title =. 2014 , publisher =
2014
-
[74]
Richard Landis and Gary G
J. Richard Landis and Gary G. Koch , journal =. The Measurement of Observer Agreement for Categorical Data , urldate =
-
[75]
Schumacker, R. E. and Lomax, R. G. , title =
-
[76]
Fitting Linear Mixed-Effects Models Using
Douglas Bates and Martin M. Fitting Linear Mixed-Effects Models Using. Journal of Statistical Software , year =
-
[77]
2021 , url =
R: A Language and Environment for Statistical Computing , author =. 2021 , url =
2021
-
[78]
McConochie , title =
William A. McConochie , title =. 2007 , note =
2007
-
[79]
John A. Johnson , keywords =. Measuring thirty facets of the Five Factor Model with a 120-item public domain inventory: Development of the IPIP-NEO-120 , journal =. 2014 , issn =. doi:https://doi.org/10.1016/j.jrp.2014.05.003 , url =
-
[80]
Gorsuch , title =
Richard L. Gorsuch , title =. 1983 , publisher =
1983
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.