Coalesced Matrix-Free Finite Elements in Cell-Wise Storage
Pith reviewed 2026-07-03 07:35 UTC · model grok-4.3
The pith
A preconditioner with continuous image lets the full flexible conjugate gradient run exactly on unassembled cell-wise data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given a preconditioner whose image is continuous, the entire flexible conjugate gradient iteration can be carried out exactly on the unassembled cell-wise representation: a simple primal-dual pairing identity shows that all Krylov scalars computed from local data coincide with those of the assembled solve, so inter-element communication is confined entirely to the preconditioner.
What carries the argument
primal-dual pairing identity that equates all Krylov scalars between cell-wise local data and the assembled global representation
If this is right
- The direct stiffness summation is realized by a dimensionally-split cascade of one-to-one face exchanges that accumulates edge and vertex contributions automatically.
- Unstructured macro-block interfaces and hanging nodes are handled by separate topological kernels without touching the main high-throughput sweeps.
- Memory layout can be chosen independently of mesh topology, allowing benchmarks of blocked arrangements that trade coalescing against element contiguity.
- Operator evaluation and the full solver achieve higher throughput than existing matrix-free codes on modern GPUs.
Where Pith is reading between the lines
- The same storage model and pairing argument could be tested on other Krylov methods that rely on inner products and matrix-vector products.
- Decoupling layout from topology may allow new data arrangements on hardware with non-uniform memory access or on distributed systems where communication cost dominates.
- The sequential face-exchange cascade might extend to other local summation tasks that currently require atomics or coloring.
Load-bearing premise
The preconditioner must produce continuous fields so that the pairing identity holds and local scalars remain identical to assembled ones.
What would settle it
Compute the flexible CG iteration scalars and final solution both from cell-wise unassembled data and from the standard assembled matrix for the same continuous preconditioner, then check whether any scalar or the solution vector differs.
Figures

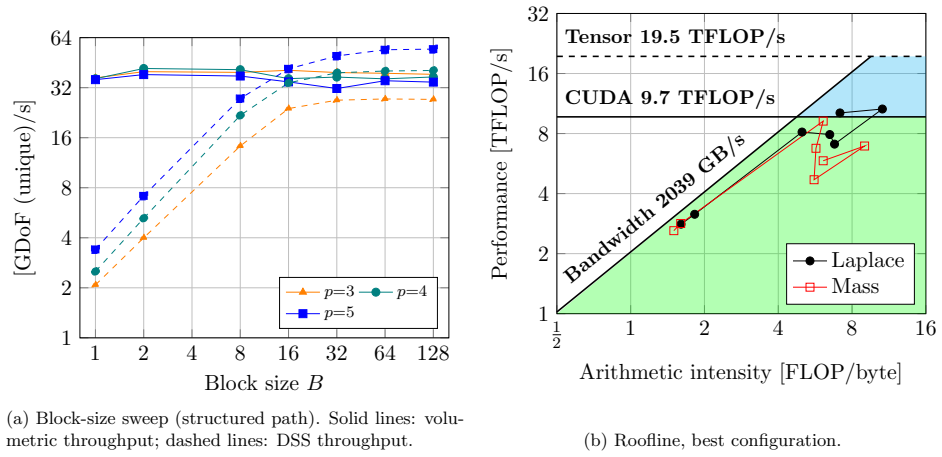
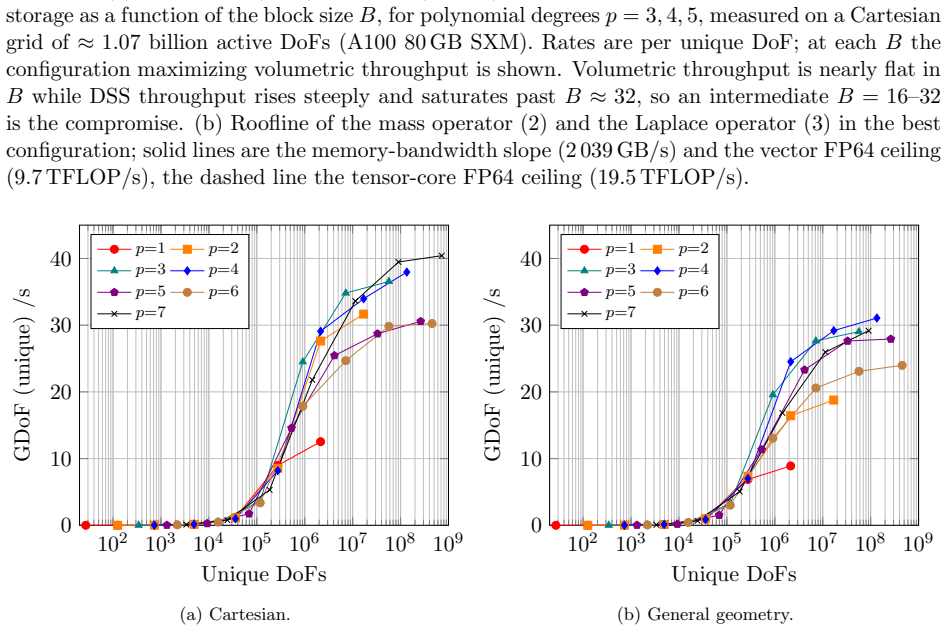
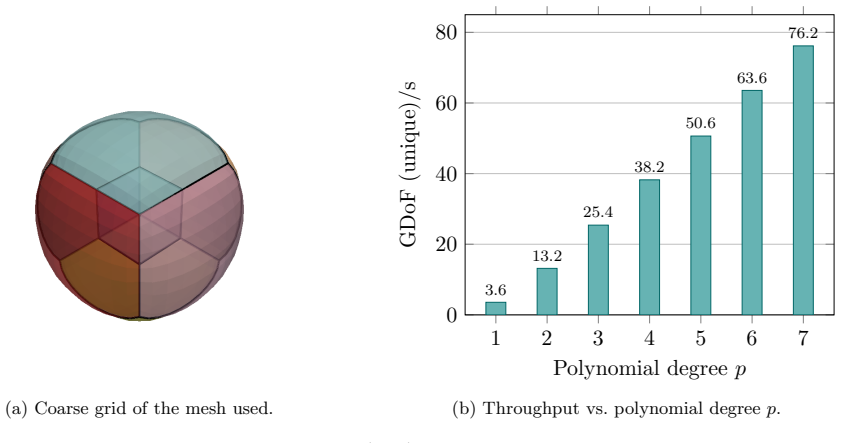

read the original abstract
We present a GPU-oriented formulation of continuous high-order finite elements in which the redundant, cell-wise (element-local) vector is the persistent primary representation of all field data, rather than a transient stage of matrix-free operator evaluation. We prove that, given a preconditioner whose image is continuous, the entire flexible conjugate gradient iteration can be carried out exactly on this unassembled representation: a simple primal-dual pairing identity shows that all Krylov scalars computed from local data coincide with those of the assembled solve, so inter-element communication is confined entirely to the preconditioner. The required direct stiffness summation (DSS) is then realized without indirect gather-scatter, atomics, or coloring, by a dimensionally-split cascade of one-to-one face exchanges that provably accumulates edge and vertex contributions as a byproduct of sequential axis passes; unstructured macro-block interfaces and $h$-adaptive hanging nodes are handled by disjoint topological kernels and a shadow-cell wrapper that leaves the high-throughput sweeps untouched. The cell-wise storage decouples the memory layout from the mesh topology, and we exploit this freedom to benchmark blocked layouts that trade memory coalescing against element contiguity. Numerical experiments on modern GPUs demonstrate that the resulting operator evaluation and solver outperform state-of-the-art matrix-free implementations, signifficantly exceeding throughput of existing implementations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a GPU-oriented formulation of continuous high-order finite elements that uses the redundant cell-wise (unassembled) vector as the persistent primary data representation. It proves that, given a preconditioner whose image lies in the continuous finite-element space, the entire flexible conjugate gradient iteration can be performed exactly on this unassembled representation via a primal-dual pairing identity that makes all Krylov scalars computed from local data identical to the assembled case. Inter-element communication is thereby confined to the preconditioner; direct stiffness summation is realized by a dimensionally-split cascade of one-to-one face exchanges that accumulates edge and vertex contributions without atomics, coloring, or indirect gather-scatter. The approach handles unstructured macro-block interfaces and h-adaptive hanging nodes via disjoint topological kernels and a shadow-cell wrapper, decouples memory layout from mesh topology to enable blocked coalesced layouts, and reports benchmark results showing higher throughput than existing matrix-free implementations.
Significance. If the central identity and implementation details hold, the work offers a mathematically grounded route to reduced communication and topology-independent memory optimization in high-order matrix-free solvers on GPUs. The explicit continuity hypothesis on the preconditioner and the conditional character of the proof are strengths; the dimensionally-split DSS and hanging-node handling are presented as preserving the identity while preserving high-throughput sweeps.
minor comments (1)
- [Abstract] Abstract: 'signifficantly' is a typographical error and should read 'significantly'.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript, the detailed summary of its contributions, and the recommendation of minor revision. No specific major comments are listed in the report.
Circularity Check
No significant circularity identified
full rationale
The central claim is a conditional mathematical identity: given a preconditioner whose image lies in the continuous FE space, a primal-dual pairing makes all Krylov scalars computed from cell-wise data identical to the assembled case. This is presented as an explicit hypothesis plus a standard pairing identity rather than a fitted parameter, self-definition, or self-citation chain. No equations reduce the claimed equivalence to a tautology by construction, no ansatz is smuggled via prior work, and the DSS implementation details are described as preserving the identity without redefining it. The derivation is therefore self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint , year=
Coalesced Matrix-Free Finite Elements in Cell-Wise Storage , author=. arXiv preprint , year=
-
[2]
arXiv preprint , year =
Coalesced Matrix-Free Geometric Multigrid on Persistent Cell-Wise Storage , author =. arXiv preprint , year =
-
[3]
and Falk, Richard S
Arnold, Douglas N. and Falk, Richard S. and Winther, R. , TITLE =. Math. Comput. , VOLUME =. 1997 , NUMBER =
1997
-
[4]
and Falk, Richard S
Arnold, Douglas N. and Falk, Richard S. and Winther, Ragnar , TITLE =. Numer. Math. , FJOURNAL =
-
[5]
Multigrid Methods , author =
-
[6]
p4est: Scalable algorithms for parallel adaptive mesh refinement on forests of octrees , author=. SIAM J. Sci. Comput. , volume=. 2011 , publisher=
2011
-
[7]
ACM Trans
Algorithms and data structures for massively parallel generic adaptive finite element codes , author=. ACM Trans. Math. Softw. , volume=. 2012 , publisher=
2012
-
[8]
Daniel Arndt and Wolfgang Bangerth and Denis Davydov and Timo Heister and Luca Heltai and Martin Kronbichler and Matthias Maier and Jean-Paul Pelteret and Bruno Turcksin and David Wells , journal =. The. 2021 , DOI =
2021
-
[9]
Daniel Arndt and Wolfgang Bangerth and Maximilian Bergbauer and Bruno Blais and Marc Fehling and Rene Gassmöller and Timo Heister and Luca Heltai and Martin Kronbichler and Matthias Maier and Peter Munch and Sam Scheuerman and Bruno Turcksin and Siarhei Uzunbajakau and David Wells and Michał Wichrowski , journal =. The. doi:doi:10.1515/jnma-2025-0115 , year =
-
[10]
and Farrell, Patrick E
Brubeck, Pablo D. and Farrell, Patrick E. , title =. SIAM J. Sci. Comput. , volume =. 2022 , doi =
2022
-
[11]
The Finite Element Method for Elliptic Problems , author =
-
[12]
Multi-grid Methods and Applications , author =
-
[13]
and Kanschat, G
Janssen, B. and Kanschat, G. , title =. SIAM J. Sci. Comput. , year = 2011, volume = 33, number = 4, pages =
2011
-
[14]
, title =
Kanschat, G. , title =. J. Comput. Appl. Math. , year = 2008, volume = 218, pages =
2008
-
[15]
and Mao, Y
Kanschat, G. and Mao, Y. , title =. J. Numer. Math. , year = 2015, volume = 23, number = 1, pages =
2015
-
[16]
2012 , doi =
Kronbichler, Martin and Kormann, Katharina , journal =. 2012 , doi =
2012
-
[17]
ACM Trans
Kronbichler, Martin and Kormann, Katharina , title =. ACM Trans. Math. Softw. , pages =. 2019 , volume =
2019
-
[18]
Enhancing data locality of the conjugate gradient method for high-order matrix-free finite-element implementations , author =. Int. J. High-Performance Computing Appl. , year =
-
[19]
Lucero Lorca, J. P. and G. Kanschat , title =. Electron. Trans. Numer. Anal. , volume =. 2021 , pages =
2021
-
[20]
Lynch, R. E. and Rice, J. R. and Thomas, D. H. , title =. Numer. Math. , volume = 6, pages =
-
[21]
ACM Trans
Multidimensional intratile parallelization for memory-starved stencil computations , author=. ACM Trans. Parallel Comput. , volume=. 2017 , doi=
2017
-
[22]
Markus Melenk and Klaus Gerdes and Christoph Schwab
J. Markus Melenk and Klaus Gerdes and Christoph Schwab. Fully discrete hp-finite elements: fast quadrature. Comp. Meth. Appl. Mech. Engrg. 2001
2001
-
[23]
, journal =
Orszag, Steven A. , journal =. Spectral methods for problems in complex geometries , volume =
-
[24]
W. Trojak and R. Watson and F.D. Witherden , title =. doi:10.1016/j.cpc.2021.108235 , year =
-
[25]
Proceedings of the 7th IEEE International Conference on eScience , year =
Kormann, Katharina and Kronbichler, Martin , title =. Proceedings of the 7th IEEE International Conference on eScience , year =
-
[26]
and Arndt, D
Witte, J. and Arndt, D. and Kanschat, G. , title =. Comput. Meth. Appl. Math. , number =. 2021 , pages =
2021
-
[27]
doi:10.3390/axioms7030063 , year =
Michael Dumbser and Francesco Fambri and Maurizio Tavelli and Michael Bader and Tobias Weinzierl , title =. doi:10.3390/axioms7030063 , year =
-
[28]
Textbook efficiency: massively parallel matrix-free multigrid for the
Kohl, Nils and R\"ude, Ulrich , journal=. Textbook efficiency: massively parallel matrix-free multigrid for the. 2022 , doi=
2022
-
[29]
ACM Trans
Multigrid for matrix-free high-order finite element computations on graphics processors , author=. ACM Trans. Parallel Comput. , volume=. 2019 , doi=
2019
-
[30]
An overlapping
Fischer, Paul F and Miller, Neil I and Tufo, Henry M , journal =. An overlapping. 2000 , publisher=
2000
-
[31]
A massively parallel nonoverlapping additive Schwarz method for discontinuous
Dryja, Maksymilian and Krzy. A massively parallel nonoverlapping additive Schwarz method for discontinuous. Numer. Math. , volume=. 2016 , publisher=
2016
-
[32]
From h to p efficiently: Implementing finite and spectral/hp element methods to achieve optimal performance for low-and high-order discretisations , author=. J. Comput. Phys. , volume=
-
[33]
Implementation of the
Bauer, Petr and Klement, Vladimir and Oberhuber, Tom. Implementation of the. Computer Phys. Comm. , volume=
-
[34]
High-performance Implementation of Matrix-free High-order Discontinuous Galerkin Methods
M. High-performance implementation of matrix-free high-order discontinuous. arXiv preprint arXiv:1711.10885 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Textbook multigrid efficiency for fluid simulations , author=. Annu. Rev. Fluid Mech. , volume=. 2003 , doi=
2003
-
[36]
A matrix-free high-order discontinuous
Fehn, Niklas and Wall, Wolfgang A and Kronbichler, Martin , journal=. A matrix-free high-order discontinuous. 2019 , publisher=
2019
-
[37]
A robust multigrid method for discontinuous
Hong, Qingguo and Kraus, Johannes and Xu, Jinchao and Zikatanov, Ludmil , journal=. A robust multigrid method for discontinuous. 2016 , publisher=
2016
-
[38]
A study of vectorization for matrix-free finite element methods , author=. Int. J. High Perf. Comput. Appl. , volume=. 2020 , publisher=
2020
-
[39]
doi:10.1145/3126908.3126963 , year =
Ken Raffenetti and Abdelhalim Amer and Lena Oden and Charles Archer and Wesley Bland and Hajime Fujita and Yanfei Guo and Tomislav Janjusic and Dmitry Durnov and Michael Blocksome and Min Si and Sangmin Seo and Akhil Langer and Gengbin Zheng and Masamichi Takagi and Paul Coffman and Jithin Jose and Sayantan Sur and Alexander Sannikov and Sergey Oblomov an...
-
[40]
Peter Munch and Martin Kronbichler , title =. Int. J. High Perf. Comput. Appl. , year = 2023, note =
2023
-
[41]
Wall and Martin Kronbichler , title =
Niklas Fehn and Peter Munch and Wolfgang A. Wall and Martin Kronbichler , title =. doi:10.1016/j.jcp.2020.109538 , year =
-
[42]
The International Journal of High Performance Computing Applications , volume=
Enhancing data locality of the conjugate gradient method for high-order matrix-free finite-element implementations , author=. The International Journal of High Performance Computing Applications , volume=. 2023 , publisher=
2023
-
[43]
SIAM Journal on Scientific Computing , volume=
Smoothers with Localized Residual Computations for Geometric Multigrid Methods for Higher-Order Finite Elements , author=. SIAM Journal on Scientific Computing , volume=. 2025 , publisher=
2025
-
[44]
A matrix-free multilevel preconditioner for the generalized
Wichrowski, Micha. A matrix-free multilevel preconditioner for the generalized. Journal of Computational Science , volume=. 2022 , publisher=
2022
-
[45]
An implementation of tensor product patch smoothers on
Cui, Cu and Grosse-Bley, Paul and Kanschat, Guido and Strzodka, Robert , journal=. An implementation of tensor product patch smoothers on. 2025 , publisher=
2025
-
[46]
Computational Methods in Applied Mathematics , number=
Tensor-product vertex patch smoothers for biharmonic problems , author=. Computational Methods in Applied Mathematics , number=. 2025 , publisher=
2025
-
[47]
Matrix-free multigrid block-preconditioners for higher order discontinuous
Bastian, Peter and M. Matrix-free multigrid block-preconditioners for higher order discontinuous. Journal of Computational Physics , volume=. 2019 , publisher=
2019
-
[48]
Numerische Mathematik , volume=
Additive Schwarz methods for the p-version finite element method , author=. Numerische Mathematik , volume=. 1993 , publisher=
1993
-
[49]
Numerical methods for partial differential equations , pages=
Spectral methods for problems in complex geometrics , author=. Numerical methods for partial differential equations , pages=. 1979 , publisher=
1979
-
[50]
Journal of Computational Physics , volume=
Scaling to the stars--a linearly scaling elliptic solver for p-multigrid , author=. Journal of Computational Physics , volume=. 2019 , publisher=
2019
-
[51]
Approximate tensor-product preconditioners for very high order discontinuous
Pazner, Will and Persson, Per-Olof , journal=. Approximate tensor-product preconditioners for very high order discontinuous. 2018 , publisher=
2018
-
[52]
2016 , publisher=
Remacle, J-F and Gandham, Rajesh and Warburton, Tim , journal=. 2016 , publisher=
2016
-
[53]
Efficient low-order refined preconditioners for high-order matrix-free continuous and discontinuous
Pazner, Will , journal=. Efficient low-order refined preconditioners for high-order matrix-free continuous and discontinuous. 2020 , publisher=
2020
-
[54]
SIAM Journal on Scientific Computing , volume=
Scalable low-order finite element preconditioners for high-order spectral element Poisson solvers , author=. SIAM Journal on Scientific Computing , volume=. 2019 , publisher=
2019
-
[55]
An hp multigrid approach for tensor-product space-time finite element discretizations of the
Margenberg, Nils and Bause, Markus and Munch, Peter , journal=. An hp multigrid approach for tensor-product space-time finite element discretizations of the
-
[56]
An efficient smoother for the
Braess, Dietrich and Sarazin, Regina , journal=. An efficient smoother for the. 1997 , publisher=
1997
-
[57]
Matrix-free monolithic multigrid methods for
Jodlbauer, Daniel and Langer, Ulrich and Wick, Thomas and Zulehner, Walter , journal=. Matrix-free monolithic multigrid methods for. 2024 , publisher=
2024
-
[58]
Computing , volume=
A class of smoothers for saddle point problems , author=. Computing , volume=. 2000 , publisher=
2000
-
[59]
Monolithic multigrid preconditioners for high-order discretizations of
Voronin, Alexey and Harper, Graham and MacLachlan, Scott and Olson, Luke N and Tuminaro, Raymond S , journal=. Monolithic multigrid preconditioners for high-order discretizations of. 2025 , publisher=
2025
-
[60]
An energy-efficient
Anselmann, Mathias and Bause, Markus and Margenberg, Nils and Shamko, Pavel , journal=. An energy-efficient. 2024 , publisher=
2024
-
[61]
A Geometric Multigrid Preconditioner for Discontinuous
Wichrowski, Michal , journal=. A Geometric Multigrid Preconditioner for Discontinuous
-
[62]
arXiv preprint arXiv:2507.17053 , year=
Matrix-Free Evaluation of High-Order Shifted Boundary Finite Element Operators , author=. arXiv preprint arXiv:2507.17053 , year=
-
[63]
A multigrid method for
Cui, Cu and Kanschat, Guido , journal=. A multigrid method for
-
[64]
SIAM Journal on Scientific Computing , volume=
High-performance matrix-free unfitted finite element operator evaluation , author=. SIAM Journal on Scientific Computing , volume=. 2025 , publisher=
2025
-
[65]
Differencing of the diffusion equation in
Kershaw, David S , journal=. Differencing of the diffusion equation in. 1981 , publisher=
1981
-
[66]
SIAM Journal on Scientific Computing , volume=
Flexible conjugate gradients , author=. SIAM Journal on Scientific Computing , volume=. 2000 , publisher=
2000
-
[67]
2002 , publisher=
High-Order Methods for Incompressible Fluid Flow , author=. 2002 , publisher=
2002
-
[68]
Journal of Open Source Software , volume=
libCEED: Fast algebra for high-order element-based discretizations , author=. Journal of Open Source Software , volume=
-
[69]
Parallel Computing , volume=
NekRS, a GPU-accelerated spectral element Navier--Stokes solver , author=. Parallel Computing , volume=. 2022 , publisher=
2022
-
[70]
International Journal for Numerical Methods in Engineering , volume=
A method of finite element tearing and interconnecting and its parallel solution algorithm , author=. International Journal for Numerical Methods in Engineering , volume=. 1991 , publisher=
1991
-
[71]
SIAM Journal on Scientific Computing , volume=
A preconditioner for substructuring based on constrained energy minimization , author=. SIAM Journal on Scientific Computing , volume=. 2003 , publisher=
2003
-
[72]
Computers & Mathematics with Applications , volume=
MFEM: A modular finite element methods library , author=. Computers & Mathematics with Applications , volume=. 2021 , publisher=
2021
-
[73]
2020 , institution=
Nek5000 developments in support of industry and the NRC , author=. 2020 , institution=
2020
-
[74]
and Fischer, Paul F
Lottes, James W. and Fischer, Paul F. , title =
-
[75]
Bradbury, James and Frostig, Roy and Hawkins, Peter and Johnson, Matthew James and Leary, Chris and Maclaurin, Dougal and Necula, George and Paszke, Adam and Vander
-
[76]
Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages (MAPL) , pages=
Triton: an intermediate language and compiler for tiled neural network computations , author=. Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages (MAPL) , pages=
-
[77]
arXiv preprint arXiv:2508.00441 , year=
DGEMM without FP64 Arithmetic-Using FP64 Emulation and FP8 Tensor Cores with Ozaki Scheme , author=. arXiv preprint arXiv:2508.00441 , year=
-
[78]
arXiv preprint arXiv:2504.19442 , year=
Triton-distributed: Programming overlapping kernels on distributed ai systems with the triton compiler , author=. arXiv preprint arXiv:2504.19442 , year=
-
[79]
Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1 , pages=
Linear Layouts: Robust Code Generation of Efficient Tensor Computation Using F\_2 , author=. Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1 , pages=
-
[80]
arXiv preprint arXiv:2512.18134 , year=
Optimal Software Pipelining and Warp Specialization for Tensor Core GPUs , author=. arXiv preprint arXiv:2512.18134 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.