A Layered Aggregate Engine for Analytics Workloads
Pith reviewed 2026-05-25 18:49 UTC · model grok-4.3
The pith
LMFAO computes batches of aggregates over database joins orders of magnitude faster than commercial databases and ML systems by applying layered optimizations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
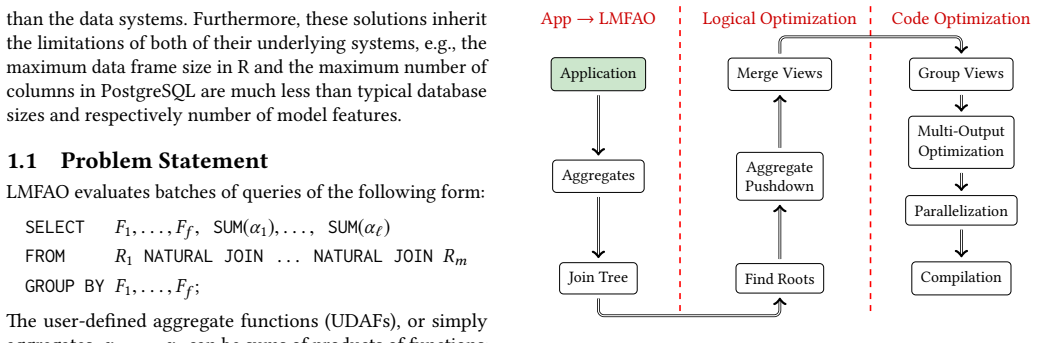
LMFAO is a layered engine whose logical and code optimizations systematically share computation, parallelism, and specialization when evaluating batches of aggregates over joins; this decomposition covers ridge linear regression, classification and regression trees, Chow-Liu trees for Bayesian networks, and data cubes, and produces orders-of-magnitude speedups over both database systems and machine-learning frameworks on the tested workloads.
What carries the argument
LMFAO's layers of logical and code optimizations that exploit sharing of computation, parallelism, and code specialization for aggregate batches.
If this is right
- Model training for linear regression, trees, and Bayesian networks can be performed directly over database joins without data export.
- Data-cube exploration in warehousing becomes feasible at larger scales due to shared aggregate computation.
- Multiple aggregate queries in a batch benefit from common subexpression elimination across the join.
- In-memory execution with code specialization reduces per-aggregate overhead compared with general-purpose query engines.
- The same layered approach applies uniformly to both relational analytics and statistical model learning.
Where Pith is reading between the lines
- Workloads outside the four examples might still gain if their heavy steps fit the aggregate-over-join pattern.
- Embedding LMFAO inside existing database servers could let users invoke it via standard SQL extensions.
- The performance edge might allow interactive model selection loops that were previously too slow.
- Similar layering of sharing and specialization could be applied to other batch query problems such as frequent itemset mining.
Load-bearing premise
The data-intensive parts of the listed analytics workloads can be decomposed into group-by aggregates over the join of the input relations.
What would settle it
A workload whose main computation cannot be expressed as group-by aggregates over joins, or a new dataset on which LMFAO shows no substantial speedup over the compared systems.
Figures






read the original abstract
This paper introduces LMFAO (Layered Multiple Functional Aggregate Optimization), an in-memory optimization and execution engine for batches of aggregates over the input database. The primary motivation for this work stems from the observation that for a variety of analytics over databases, their data-intensive tasks can be decomposed into group-by aggregates over the join of the input database relations. We exemplify the versatility and competitiveness of LMFAO for a handful of widely used analytics: learning ridge linear regression, classification trees, regression trees, and the structure of Bayesian networks using Chow-Liu trees; and data cubes used for exploration in data warehousing. LMFAO consists of several layers of logical and code optimizations that systematically exploit sharing of computation, parallelism, and code specialization. We conducted two types of performance benchmarks. In experiments with four datasets, LMFAO outperforms by several orders of magnitude on one hand, a commercial database system and MonetDB for computing batches of aggregates, and on the other hand, TensorFlow, Scikit, R, and AC/DC for learning a variety of models over databases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LMFAO, an in-memory engine for batches of group-by aggregates over database joins. It claims that analytics workloads including ridge regression, decision/regression trees, Chow-Liu trees for Bayesian networks, and data cubes can be decomposed into such aggregates, allowing layered logical and code optimizations (sharing, parallelism, specialization) to deliver orders-of-magnitude speedups over commercial DBMSs, MonetDB, TensorFlow, Scikit-learn, R, and AC/DC on four datasets.
Significance. If the workload decompositions are complete and the experimental claims are substantiated, the work would offer a unified, highly optimized aggregate engine that bridges OLAP and ML over relational data, with potential for broad impact in analytics systems.
major comments (2)
- [Abstract] Abstract: the central claim that ridge regression, decision trees, Chow-Liu trees, and data cubes reduce exactly to batches of group-by aggregates over the input join (with no material extra work) is presented as an observation but supplies no explicit reductions, complexity arguments, or completeness proofs; this decomposition is load-bearing for the TensorFlow/Scikit/R comparisons.
- [Experiments] Experiments section (implied by abstract claims): the abstract reports orders-of-magnitude gains but provides no details on experimental setup, exact queries, hardware, statistical significance, or how the ML workloads were mapped to aggregates; without these, the performance claims against external baselines cannot be verified.
minor comments (1)
- [Abstract] Abstract: the phrasing 'on one hand ... and on the other hand' is slightly awkward and could be clarified for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and experimental presentation. We address each major comment below and will revise the manuscript accordingly where the points identify areas for improved clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that ridge regression, decision trees, Chow-Liu trees, and data cubes reduce exactly to batches of group-by aggregates over the input join (with no material extra work) is presented as an observation but supplies no explicit reductions, complexity arguments, or completeness proofs; this decomposition is load-bearing for the TensorFlow/Scikit/R comparisons.
Authors: The full manuscript provides explicit reductions for each workload in dedicated sections (ridge regression in Section 4 via the normal equations reducing to aggregates such as SUM(x_i * x_j) and SUM(x_i * y) over the join; decision/regression trees in Section 5 via sufficient statistics for splits; Chow-Liu trees in Section 6 via mutual information aggregates; data cubes in Section 7). These are presented as direct mappings with no additional materialization beyond the aggregates. We agree the abstract presents this too concisely without referencing the sections and will revise it to briefly note the reductions and point readers to the relevant sections. Complexity arguments follow from the fact that the number of aggregates is polynomial in the number of features (independent of join size after factorization), but we will add a short summary paragraph. Full completeness proofs are not included because the reductions follow from standard statistical formulations of these models; the paper's focus is the aggregate engine rather than re-deriving ML theory. We will add a clarifying sentence in the abstract and introduction. revision: partial
-
Referee: [Experiments] Experiments section (implied by abstract claims): the abstract reports orders-of-magnitude gains but provides no details on experimental setup, exact queries, hardware, statistical significance, or how the ML workloads were mapped to aggregates; without these, the performance claims against external baselines cannot be verified.
Authors: The experiments section of the full manuscript describes the four datasets, the two benchmark types (aggregate batches vs. ML libraries), and reports wall-clock times. However, we acknowledge that explicit mappings from each ML workload to the precise aggregate queries, hardware specifications, and measures of statistical significance (e.g., standard deviation across runs) are not presented with sufficient granularity. We will revise the experiments section to include (1) a table listing the exact aggregate queries generated for each model on each dataset, (2) hardware details (processor, memory, OS), and (3) run-time variance where multiple executions were performed. The abstract itself is intentionally high-level per convention and will remain so, but the experiments section will be made self-contained. revision: yes
Circularity Check
No circularity; claims rest on external benchmarks and stated observation
full rationale
The paper presents LMFAO as a new engine with layered optimizations for batches of aggregates over joins, motivated by the observation that analytics workloads decompose into such aggregates. Performance claims are supported by direct comparisons to external systems (MonetDB, TensorFlow, Scikit, R, AC/DC) on four datasets rather than any internal fitted parameters or self-referential derivations. No equations, predictions, or load-bearing self-citations are shown that reduce results to inputs by construction; the decomposition is presented as a motivating observation without being derived within the paper itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mart´ın Abadi, Paul Barham, Jianmin Chen, and et al. 2016. TensorFlow: A System for Large-Scale Machine Learning. In OSDI. 265–283
work page 2016
-
[2]
Aberger, Susan Tu, Kunle Olukotun, and Christopher R´e
Christopher R. Aberger, Susan Tu, Kunle Olukotun, and Christopher R´e. 2016. EmptyHeaded: A Relational Engine for Graph Processing. In SIGMOD. 431–446
work page 2016
-
[3]
S. Abiteboul, R. Hull, and V. Vianu. 1995. Foundations of Databases . Addison-Wesley. 14
work page 1995
-
[4]
Ngo, XuanLong Nguyen, Dan Olteanu, and Maximilian Schleich
Mahmoud Abo Khamis, Hung Q. Ngo, XuanLong Nguyen, Dan Olteanu, and Maximilian Schleich. 2018. AC/DC: In-Database Learning /T_hunderstruck. InDEEM. 8:1–8:10
work page 2018
-
[5]
Ngo, XuanLong Nguyen, Dan Olteanu, and Maximilian Schleich
Mahmoud Abo Khamis, Hung Q. Ngo, XuanLong Nguyen, Dan Olteanu, and Maximilian Schleich. 2018. In-Database Learning with Sparse Tensors. In PODS. 325–340
work page 2018
-
[6]
Mahmoud Abo Khamis, Hung Q. Ngo, and Atri Rudra. 2016. FAQ: /Q_uestions Asked Frequently. InPODS. 13–28
work page 2016
-
[7]
S. M. Aji and R. J. McEliece. 2006. /T_he Generalized Distributive Law. IEEE Trans. Inf. /T_heor.46, 2 (2006), 325–343
work page 2006
-
[8]
Nurzhan Bakibayev, Tom´as Kocisk´y, Dan Olteanu, and Jakub Z´avodn´y
-
[9]
Aggregation and Ordering in Factorised Databases. PVLDB 6, 14 (2013), 1990–2001
work page 2013
-
[10]
Nurzhan Bakibayev, Dan Olteanu, and Jakub Z´avodn´y. 2012. FDB: A /Q_uery Engine for Factorised Relational Databases.PVLDB 5, 11 (2012), 1232–1243
work page 2012
-
[11]
Ma/t_thias Boehm et al. 2016. SystemML: Declarative Machine Learning on Spark. PVLDB 9, 13 (2016), 1425–1436
work page 2016
-
[12]
L. Breiman, J. Friedman, R. Olshen, and C. Stone. 1984. Classi/f_ication and Regression Trees. Wadsworth and Brooks, Monterey, CA
work page 1984
-
[13]
Surajit Chaudhuri. 1998. Data Mining and Database Systems: Where is the Intersection? IEEE Data Eng. Bull. 21, 1 (1998), 4–8
work page 1998
-
[14]
Surajit Chaudhuri, Usama M. Fayyad, and Jeff Bernhardt. 1999. Scal- able Classi/f_ication over SQL Databases. InICDE. 470–479
work page 1999
-
[15]
Lingjiao Chen, Arun Kumar, Jeffrey F. Naughton, and Jignesh M. Patel
-
[16]
PVLDB 10, 11 (2017), 1214–1225
Towards Linear Algebra over Normalized Data. PVLDB 10, 11 (2017), 1214–1225
work page 2017
-
[17]
Tianqi Chen and Carlos Guestrin. 2016. XGBoost: A Scalable Tree Boosting System. In KDD. 785–794
work page 2016
-
[18]
C. Chow and C. Liu. 2006. Approximating Discrete Probability Distri- butions with Dependence Trees. IEEE Trans. Inf. /T_heor.14, 3 (2006), 462–467
work page 2006
-
[19]
Ev- /f_imievski, Shirish Tatikonda, Berthold Reinwald, and Prithviraj Sen
Tarek Elgamal, Shangyu Luo, Ma/t_thias Boehm, Alexandre V. Ev- /f_imievski, Shirish Tatikonda, Berthold Reinwald, and Prithviraj Sen
-
[20]
SPOOF: Sum-Product Optimization and Operator Fusion for Large-Scale Machine Learning. In CIDR
-
[21]
Corporacion Favorita. 2017. Corp. Favorita Grocery Sales Forecasting: Can you accurately predict sales for a large grocery chain? (2017). h/t_tps://www.kaggle.com/c/favorita-grocery-sales-forecasting/
work page 2017
-
[22]
Xixuan Feng, Arun Kumar, Benjamin Recht, and Christopher R´e. 2012. Towards a uni/f_ied architecture for in-RDBMS analytics. InSIGMOD. 325–336
work page 2012
-
[23]
Gao, Shangyu Luo, Luis Leopoldo Perez, and Chris Jermaine
Zekai J. Gao, Shangyu Luo, Luis Leopoldo Perez, and Chris Jermaine
- [24]
-
[25]
Georgios Giannikis, Darko Makreshanski, Gustavo Alonso, and Don- ald Kossmann. 2014. Shared Workload Optimization. PVLDB 7, 6 (2014), 429–440
work page 2014
-
[26]
Jim Gray, Adam Bosworth, Andrew Layman, and Hamid Pirahesh
-
[27]
Data Cube: A Relational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub-Total. InICDE. 152–159
-
[28]
Ga¨el Guennebaud, Benoˆıt Jacob, et al. 2010. Eigen v3. (2010). h/t_tp: //eigen.tuxfamily.org
work page 2010
-
[29]
Venky Harinarayan, Anand Rajaraman, and Jeffrey D. Ullman. 1996. Implementing Data Cubes Efficiently. In SIGMOD. 205–216
work page 1996
-
[30]
Joseph M. Hellerstein, Christopher R´e, Florian Schoppmann, Daisy Zhe Wang, Eugene Fratkin, Aleksander Gorajek, Kee Siong Ng, Caleb Welton, Xixuan Feng, Kun Li, and Arun Kumar. 2012. /T_he MADlib Analytics Library or MAD Skills, the SQL. PVLDB 5, 12 (2012), 1700– 1711
work page 2012
-
[31]
Sjoerd Mullender, and Martin L
Stratos Idreos, Fabian Groffen, Niels Nes, Stefan Manegold, K. Sjoerd Mullender, and Martin L. Kersten. 2012. MonetDB: Two Decades of Research in Column-oriented Database Architectures. IEEE Data Eng. Bull. 35, 1 (2012), 40–45
work page 2012
-
[32]
Kaggle. 2018. Kaggle ML & DB Survey. (2018). h/t_tps://www.kaggle. com/kaggle/kaggle-survey-2018
work page 2018
-
[33]
Timo Kersten, Viktor Leis, Alfons Kemper, /T_homas Neumann, Andrew Pavlo, and Peter Boncz. 2018. Everything You Always Wanted to Know About Compiled and Vectorized /Q_ueries but Were Afraid to Ask. PVLDB 11, 13 (2018), 2209–2222
work page 2018
-
[34]
Fredrik Kjolstad, Shoaib Kamil, Stephen Chou, David Lugato, and Saman Amarasinghe. 2017. /T_he Tensor Algebra Compiler.OOPSLA 1, Article 77 (2017), 77:1–77:29 pages
work page 2017
-
[35]
Arun Kumar, Jeffrey F. Naughton, and Jignesh M. Patel. 2015. Learning Generalized Linear Models Over Normalized Data. In SIGMOD. 1969– 1984
work page 2015
- [36]
- [37]
-
[38]
Shangyu Luo, Zekai J. Gao, Michael N. Gubanov, Luis Leopoldo Perez, and Christopher M. Jermaine. 2018. Scalable Linear Algebra on a Relational Database System. SIGMOD Rec. 47, 1 (2018), 24–31
work page 2018
-
[39]
D´aniel Marx. 2010. Approximating Fractional Hypertree Width. ACM Trans. Algorithms 6, 2, Article 29 (April 2010), 17 pages
work page 2010
-
[40]
H. Brendan McMahan and et al. 2013. Ad Click Prediction: A View from the Trenches. In KDD. 1222–1230
work page 2013
-
[41]
Xiangrui Meng, Joseph Bradley, et al. 2016. MLlib: Machine Learning in Apache Spark. J. Mach. Learn. Res. 17, 1 (2016), 1235–1241
work page 2016
- [42]
-
[43]
Inderpal Singh Mumick, Dallan /Q_uass, and Barinderpal Singh Mumick
- [44]
-
[45]
Raghunath Othayoth Nambiar and Meikel Poess. 2006. /T_he Making of TPC-DS. In PVLDB. 1049–1058
work page 2006
-
[46]
/T_homas Neumann. 2011. Efficiently Compiling Efficient /Q_uery Plans for Modern Hardware. PVLDB 4, 9 (2011), 539–550
work page 2011
-
[47]
Dan Olteanu and Maximilian Schleich. 2016. Factorized Databases. SIGMOD Rec. 45, 2 (2016), 5–16
work page 2016
-
[48]
Judea Pearl. 1982. Reverend Bayes on Inference Engines: A Distributed Hierarchical Approach. In AAAI. 133–136
work page 1982
-
[49]
Fabian Pedregosa, Ga ¨el Varoquaux, Alexandre Gramfort, and et al
-
[50]
Scikit-learn: Machine Learning in Python. J. Machine Learning Research 12 (2011), 2825–2830
work page 2011
-
[51]
Holger Pirk, Oscar Moll, Matei Zaharia, and Samuel Madden. 2016. Voodoo - A Vector Algebra for Portable Database Performance on Modern Hardware. PVLDB 9 (2016), 1707–1718
work page 2016
-
[52]
Chengjie Qin and Florin Rusu. 2015. Speculative Approximations for Terascale Distributed Gradient Descent Optimization. In DanaC. 1:1–1:10
work page 2015
-
[53]
R Core Team. 2013. R: A Language and Environment for Statistical Computing. R Foundation for Stat. Comp., www.r-project.org
work page 2013
-
[54]
Maximilian Schleich, Dan Olteanu, and Radu Ciucanu. 2016. Learning Linear Regression Models over Factorized Joins. In SIGMOD. 3–18
work page 2016
-
[55]
Timos K. Sellis. 1988. Multiple-query Optimization. ACM Trans. Database Syst. 13, 1 (1988), 23–52
work page 1988
-
[56]
Amir Shaikhha, Yannis Klonatos, and Christoph Koch. 2018. Build- ing Efficient /Q_uery Engines in a High-Level Language.ACM Trans. Database Syst. 43, 1, Article 4 (2018), 45 pages
work page 2018
-
[57]
Amir Shaikhha, Yannis Klonatos, Lionel Parreaux, Lewis Brown, Mo- hammad Dashti, and Christoph Koch. 2016. How to Architect a /Q_uery Compiler. In SIGMOD. 1907–1922
work page 2016
-
[58]
Spampinato and Markus P ¨uschel
Daniele G. Spampinato and Markus P ¨uschel. 2016. A basic linear algebra compiler for structured matrices. In CGO. 117–127. 15
work page 2016
-
[59]
Ruby Y. Tahboub, Gr´egory M. Essertel, and Tiark Rompf. 2018. How to Architect a /Q_uery Compiler, Revisited. InSIGMOD. 307–322
work page 2018
-
[60]
/T_he StatsModels development team. 2012. StatsModels: Statistics in Python, h/t_tp://statsmodels.sourceforge.net. (2012)
work page 2012
-
[61]
Todd L. Veldhuizen. 2014. Triejoin: A Simple, Worst-Case Optimal Join Algorithm. In ICDT. 96–106
work page 2014
-
[62]
Abdul Wasay, Xinding Wei, Niv Dayan, and Stratos Idreos. 2017. Data Canopy: Accelerating Exploratory Statistical Analysis. In SIGMOD. 557–572
work page 2017
-
[63]
Weipeng P. Yan and Per-˚Ake Larson. 1995. Eager Aggregation and Lazy Aggregation. In VLDB. 345–357
work page 1995
-
[64]
Yelp. 2017. Yelp Dataset Challenge. (2017). h/t_tps://www.yelp.com/ dataset/challenge/
work page 2017
-
[65]
Matei Zaharia, Mosharaf Chowdhury, et al. 2012. Resilient Distributed Datasets: A Fault-tolerant Abstraction for In-memory Cluster Com- puting. In NSDI. 2–2
work page 2012
-
[66]
Marcin Zukowski, Mark van de Wiel, and Peter Boncz. 2012. Vector- wise: A Vectorized Analytical DBMS. In ICDE. 1349–1350. A DATASETS Figure 6 gives the join trees for the four datasets used in the experiments in Section 4. Retailer has /f_ive relations:Inventory stores the number of inventory units for each date, store, and stock keeping unit (sku); Locat...
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.