HEATS: Heterogeneity- and Energy-Aware Task-based Scheduling
Pith reviewed 2026-05-25 14:50 UTC · model grok-4.3
The pith
HEATS shows that learning host energy and performance features allows an orchestrator to migrate tasks opportunistically and achieve up to 8.5 percent energy savings with at most 7 percent runtime increase in heterogeneous clusters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HEATS learns the performance and energy features of the physical hosts. Then, it monitors the execution of tasks on the hosts and opportunistically migrates them onto different cluster nodes to match the customer-required deployment trade-offs. The prototype is implemented within Kubernetes. Evaluation with synthetic traces indicates energy savings up to 8.5% and runtime impact at most 7%.
What carries the argument
Opportunistic migration of tasks based on learned host performance and energy profiles to meet specified trade-offs.
Load-bearing premise
The learned performance and energy features of hosts stay accurate enough over time that migrations reliably deliver the intended trade-offs without unaccounted costs.
What would settle it
Running HEATS on a cluster where host energy use changes unpredictably during task execution due to factors like thermal effects and checking whether the energy savings still appear.
Figures




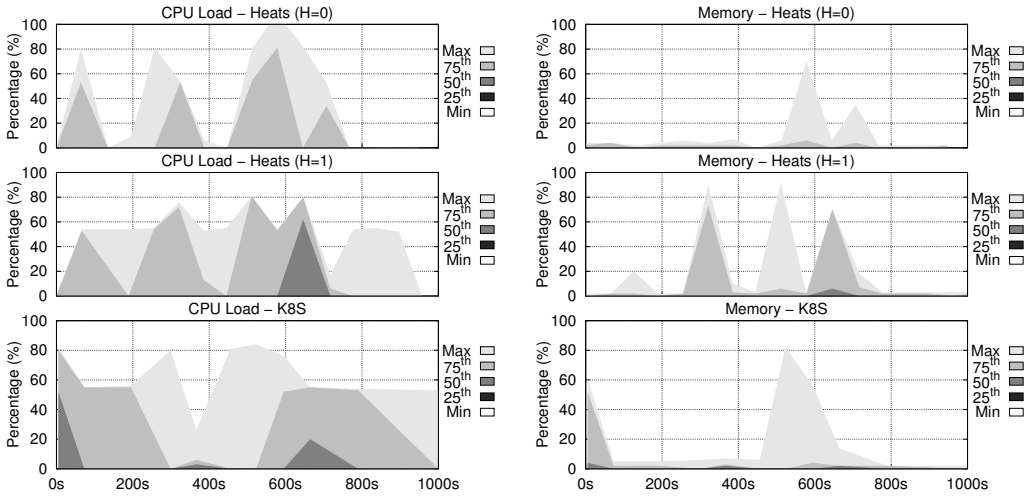
read the original abstract
Cloud providers usually offer diverse types of hardware for their users. Customers exploit this option to deploy cloud instances featuring GPUs, FPGAs, architectures other than x86 (e.g., ARM, IBM Power8), or featuring certain specific extensions (e.g, Intel SGX). We consider in this work the instances used by customers to deploy containers, nowadays the de facto standard for micro-services, or to execute computing tasks. In doing so, the underlying container orchestrator (e.g., Kubernetes) should be designed so as to take into account and exploit this hardware diversity. In addition, besides the feature range provided by different machines, there is an often overlooked diversity in the energy requirements introduced by hardware heterogeneity, which is simply ignored by default container orchestrator's placement strategies. We introduce HEATS, a new task-oriented and energy-aware orchestrator for containerized applications targeting heterogeneous clusters. HEATS allows customers to trade performance vs. energy requirements. Our system first learns the performance and energy features of the physical hosts. Then, it monitors the execution of tasks on the hosts and opportunistically migrates them onto different cluster nodes to match the customer-required deployment trade-offs. Our HEATS prototype is implemented within Google's Kubernetes. The evaluation with synthetic traces in our cluster indicate that our approach can yield considerable energy savings (up to 8.5%) and only marginally affect the overall runtime of deployed tasks (by at most 7%). HEATS is released as open-source.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HEATS, a Kubernetes-based orchestrator for containerized tasks on heterogeneous hardware clusters. It learns per-host performance and energy models, then uses opportunistic task migration to enforce user-specified performance-energy trade-offs. Evaluation on synthetic traces reports up to 8.5% energy savings with at most 7% runtime impact; the prototype is released as open source.
Significance. If the quantitative claims hold after proper validation, the work addresses a practical gap in energy-aware scheduling for heterogeneous clusters and the open-source release supports reproducibility. The combination of model learning with migration-based adaptation is a reasonable direction for cloud orchestration.
major comments (3)
- [Evaluation] Evaluation section: the headline claims of 8.5% energy savings and ≤7% runtime impact are presented without any baseline comparison to the default Kubernetes scheduler, without error bars, and without a description of how the synthetic traces were constructed or how they exercise model drift or bursty load changes.
- [Evaluation] Evaluation section: the 7% runtime bound is stated without evidence that migration costs (container checkpoint/restore, network transfer, cache warm-up) have been subtracted; if these costs are omitted, the net runtime impact could exceed the reported figure while still satisfying the abstract wording.
- [System description] System description: no mechanism is described for re-validating the accuracy of the learned performance/energy models after initial training or for detecting when model drift would invalidate the migration decisions that produce the reported savings.
minor comments (1)
- [Abstract] The abstract and evaluation paragraphs would benefit from explicit workload parameters (task sizes, arrival rates, heterogeneity mix) to allow readers to judge representativeness.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and will revise the paper accordingly to improve clarity and completeness of the evaluation and system description.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the headline claims of 8.5% energy savings and ≤7% runtime impact are presented without any baseline comparison to the default Kubernetes scheduler, without error bars, and without a description of how the synthetic traces were constructed or how they exercise model drift or bursty load changes.
Authors: We agree that a direct comparison to the default Kubernetes scheduler provides important context. We will add this baseline to the evaluation, include error bars on all reported metrics, and expand the trace construction details (including generation method and coverage of load variations) in the revised manuscript. revision: yes
-
Referee: [Evaluation] Evaluation section: the 7% runtime bound is stated without evidence that migration costs (container checkpoint/restore, network transfer, cache warm-up) have been subtracted; if these costs are omitted, the net runtime impact could exceed the reported figure while still satisfying the abstract wording.
Authors: Our runtime figures are measured end-to-end and therefore already incorporate migration overhead. We will add explicit clarification and supporting measurements in the revised evaluation section to demonstrate that these costs were included. revision: yes
-
Referee: [System description] System description: no mechanism is described for re-validating the accuracy of the learned performance/energy models after initial training or for detecting when model drift would invalidate the migration decisions that produce the reported savings.
Authors: The current design uses initial profiling with runtime monitoring to trigger migrations. We acknowledge that explicit drift detection would strengthen robustness. We will add a discussion of this limitation together with a proposed lightweight re-validation mechanism in the revised system description. revision: yes
Circularity Check
No circularity: empirical evaluation results stand independently of any derivation chain
full rationale
The paper presents an implemented Kubernetes-based scheduler that first learns per-host performance/energy features and then applies opportunistic migration to meet trade-offs. The headline claims (up to 8.5% energy savings, at most 7% runtime impact) are reported as direct outcomes of running the system on synthetic traces in a physical cluster. No equations, fitted parameters renamed as predictions, self-citations that justify uniqueness or ansatzes, or any derivation steps appear in the abstract or described approach. The evaluation measurements are therefore self-contained and not reducible to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Performance and energy characteristics of heterogeneous hosts can be learned from observation and used to guide migration decisions.
Reference graph
Works this paper leans on
-
[1]
Docker: Lightweight linux containers for consis- tent development and deployment,
D. Merkel, “Docker: Lightweight linux containers for consis- tent development and deployment,” Linux Journal, vol. 2014, no. 239, p. 2, 2014
work page 2014
-
[2]
Modelling performance & resource management in kubernetes,
Medel et al., “Modelling performance & resource management in kubernetes,” in UCC, IEEE, 2016, pp. 257–262
work page 2016
-
[3]
Amazon Web Services, Inc., Amazon EC2 Instance Types , Available: https://aws.amazon.com/ec2/instance-types, 2018
work page 2018
-
[4]
Microsoft Corporation, Pricing - Linux Virtual Machines , Available: https://azure.microsoft.com/en-us/pricing/details/ virtual-machines/linux, 2018
work page 2018
-
[5]
Google LLC, Google Compute Engine Pricing , Available: https://cloud.google.com/compute/pricing, 2018
work page 2018
-
[6]
IBM, Bare metal servers , Available: https://www.ibm.com/ cloud/bare-metal-servers, 2018
work page 2018
-
[7]
Oracle Corporation, Bare Metal Cloud Computing , Available: https://cloud.oracle.com/compute/bare-metal/features, 2018
work page 2018
-
[8]
Scaleway, BareMetal SSD Cloud Servers , Available: https:// www.scaleway.com/baremetal-cloud-servers, 2018
work page 2018
-
[9]
Compute Resource Usage Analysis , Available: https://github. com/kubernetes/heapster, 2018
work page 2018
-
[10]
Dynamic voltage and frequency scaling: The laws of diminishing returns,
Sueur et al., “Dynamic voltage and frequency scaling: The laws of diminishing returns,” in PACS, 2010, pp. 1–8
work page 2010
-
[11]
Brodowski, Linux cpu governors , Available: https://www
D. Brodowski, Linux cpu governors , Available: https://www. kernel.org/doc/Documentation/cpu-freq/governors.txt, 2018
work page 2018
-
[12]
Duxbury press Belmont, CA, 1990, vol
Myers et al., Classical and modern regression with applica- tions. Duxbury press Belmont, CA, 1990, vol. 2
work page 1990
-
[13]
Tensorflow: A system for large-scale machine learning.,
Abadi et al., “Tensorflow: A system for large-scale machine learning.,” in OSDI, vol. 16, 2016, pp. 265–283
work page 2016
-
[14]
cAdvisor, Available: https://github.com/google/cadvisor, 2018
work page 2018
-
[15]
io / docs / reference / command-line-tools-reference/kubelet, 2018
Kubelet, Available: https : / / kubernetes . io / docs / reference / command-line-tools-reference/kubelet, 2018
work page 2018
-
[16]
Heapster, Available: https://github.com/kubernetes/heapster, 2018
work page 2018
-
[17]
Grafana, Available: https://grafana.com, 2018
work page 2018
-
[18]
InfluxDB, Available: https://www.influxdata.com/time-series- platform/influxdb, 2018
work page 2018
-
[19]
com / kubernetes - incubator/metrics-server, 2018
Metrics server , Available: https : / / github . com / kubernetes - incubator/metrics-server, 2018
work page 2018
-
[20]
com / kubernetes / kubernetes, 2018
Kubernetes, Available: https : / / github . com / kubernetes / kubernetes, 2018
work page 2018
-
[21]
Kubernetes Scheduler API , Available: https://kubernetes.io/ docs/reference/command-line-tools-reference/kube-scheduler, 2018
work page 2018
-
[22]
com / kubernetes-client/python, 2018
Kubernetes Client Python , Available: https : / / github . com / kubernetes-client/python, 2018
work page 2018
-
[23]
io / docs / concepts/overview/kubernetes-api, 2018
Kubernetes API , Available: https : / / kubernetes . io / docs / concepts/overview/kubernetes-api, 2018
work page 2018
-
[24]
Powerspy: Fine-grained software energy profiling for mobile devices,
Banerjee et al., “Powerspy: Fine-grained software energy profiling for mobile devices,” in WiMob, IEEE, vol. 2, 2005, pp. 1136–1141
work page 2005
-
[25]
Alpine linux, Available: https://www.alpinelinux.org, 2018
work page 2018
-
[26]
P. Kurp, “Green computing,” Commun. ACM, vol. 51, no. 10, pp. 11–13, Oct. 2008
work page 2008
-
[27]
Power and performance management for parallel computations in clouds and data centers,
K. Li, “Power and performance management for parallel computations in clouds and data centers,” JCSS, vol. 82, no. 2, pp. 174 –190, 2016
work page 2016
-
[28]
Wang et al., “Energy-Aware Data Allocation and Task Scheduling on Heterogeneous Multiprocessor Systems With Time Constraints,” TETC, vol. 2, no. 2, pp. 134–148, 2014
work page 2014
-
[29]
Genpack: A generational scheduler for cloud data centers,
Havet et al., “Genpack: A generational scheduler for cloud data centers,” in 2017 IC2E, IEEE, 2017, pp. 95–104
work page 2017
-
[30]
Enhanced energy-efficient scheduling for parallel tasks using partial optimal slacking,
Su et al., “Enhanced energy-efficient scheduling for parallel tasks using partial optimal slacking,” The Computer Journal , vol. 58, no. 2, pp. 246–257, 2015
work page 2015
-
[31]
Energy aware scheduling for dag structured applications on heterogeneous and dvs enabled processors,
Shekar et al., “Energy aware scheduling for dag structured applications on heterogeneous and dvs enabled processors,” in IGSC, IEEE, 2010, pp. 495–502
work page 2010
-
[32]
J. Wilkes, More Google cluster data , Available: http : / / googleresearch.blogspot.com/2011/11/more- google- cluster- data, 2018
work page 2011
-
[33]
Cortez et al., “Resource central: Understanding and predicting workloads for improved resource management in large cloud platforms,” in SOSP, ACM, 2017, pp. 153–167
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.