A Pseudo-Marginal Metropolis-Hastings Algorithm for Estimating Generalized Linear Models in the Presence of Missing Data
Pith reviewed 2026-05-24 18:27 UTC · model grok-4.3
The pith
A pseudo-marginal Metropolis-Hastings algorithm estimates generalized linear models with missing data by jointly modeling all relevant parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The pseudo-marginal Metropolis-Hastings algorithm is an effective strategy for parameter estimation in generalized linear models with missing data. This approach requires fewer assumptions, provides joint inferences on the parameters in the likelihood, the covariate model, and the parameters of the missingness-mechanism, and there is no logical inconsistency of assuming that there are multiple posterior distributions. Moreover, this approach is asymptotically exact, just like most other Markov chain Monte Carlo techniques.
What carries the argument
Pseudo-marginal Metropolis-Hastings algorithm using an unbiased estimator of the marginal likelihood
If this is right
- Joint inferences on likelihood, covariate, and missingness parameters.
- Fewer assumptions required compared to alternatives.
- Avoids logical inconsistency of multiple posterior distributions.
- Asymptotically exact like standard MCMC.
- Standard errors vary with percent missingness in predictable ways.
Where Pith is reading between the lines
- This joint modeling approach might improve handling of missing data in other statistical models.
- Users must select and validate an appropriate model for the missingness process.
- The simulation results imply that uncertainty grows with higher missingness rates.
Load-bearing premise
That the missingness mechanism can be explicitly modeled and that the pseudo-marginal likelihood estimator remains stable enough for the Metropolis-Hastings chain to mix in realistic sample sizes.
What would settle it
Observing that posterior samples from the algorithm do not converge to the known true parameters in a simulation study with artificially introduced missing data.
Figures
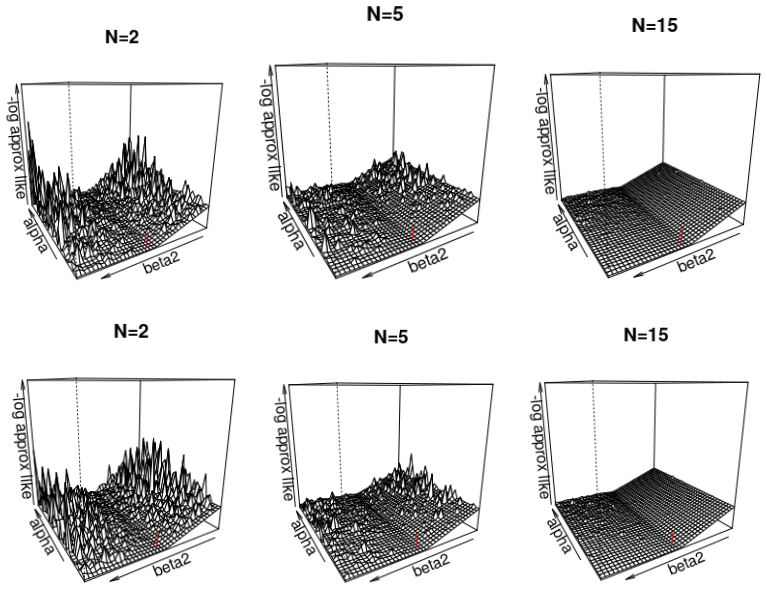
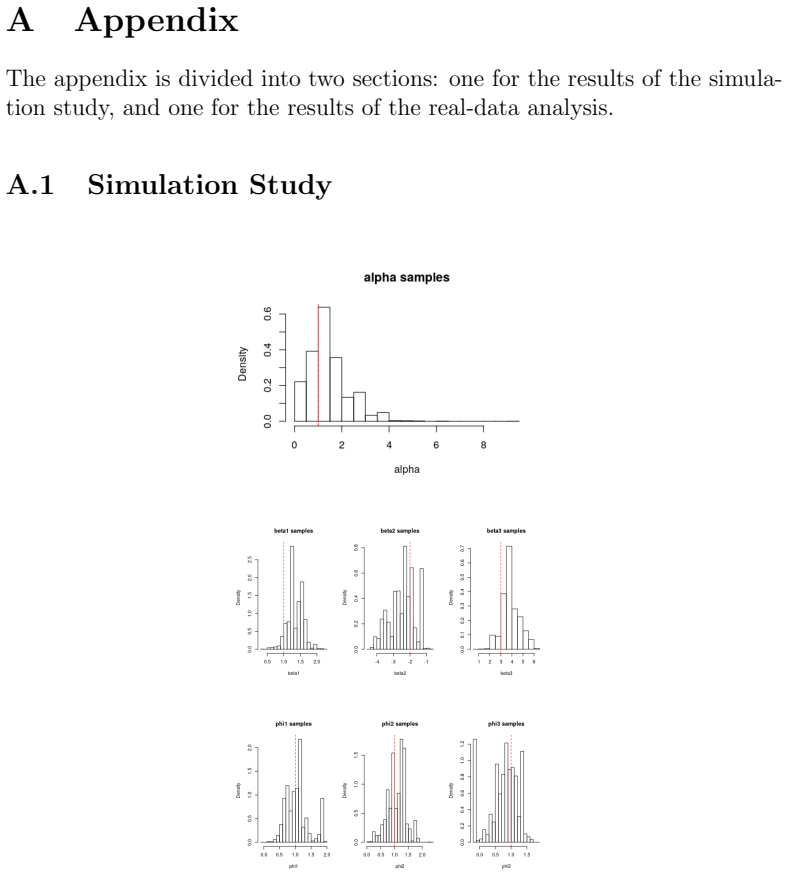
read the original abstract
The missing data issue often complicates the task of estimating generalized linear models (GLMs). We describe why the pseudo-marginal Metropolis-Hastings algorithm, used in this setting, is an effective strategy for parameter estimation. This approach requires fewer assumptions, it provides joint inferences on the parameters in the likelihood, the covariate model, and the parameters of the missingness-mechanism, and there is no logical inconsistency of assuming that there are multiple posterior distributions. Moreover, this approach is asymptotically exact, just like most other Markov chain Monte Carlo techniques. We discuss computing strategies, conduct a simulation study demonstrating how standard errors change as a function of percent missingness, and we use our approach on a "real-world" data set to describe how a collection of variables influences the car crash outcomes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes using a pseudo-marginal Metropolis-Hastings algorithm to estimate generalized linear models in the presence of missing data. It claims this strategy requires fewer assumptions than alternatives, delivers joint posterior inference on the GLM parameters, the covariate model, and the missingness mechanism parameters, avoids logical inconsistencies around multiple posteriors, and is asymptotically exact like standard MCMC. The work outlines computing strategies, presents a simulation showing how standard errors vary with percent missingness, and applies the method to a real dataset on car crash outcomes.
Significance. If the central claims hold and the pseudo-marginal estimator remains stable, the approach would offer a coherent Bayesian framework for joint modeling of the outcome, covariates, and missingness process without strong MAR assumptions or separate imputation steps. The simulation and real-data example provide initial empirical grounding, though the absence of mixing diagnostics limits assessment of practical utility.
major comments (2)
- [Abstract] Abstract: the claim that the method 'is asymptotically exact' is asserted at a high level without specifying the unbiased estimator for the marginal likelihood (integrating over missing covariates and the missingness mechanism) or sketching why the pseudo-marginal MH targets the correct joint posterior; this detail is load-bearing for the exactness guarantee.
- [Simulation study] Simulation study (described in abstract): only changes in standard errors with percent missingness are reported; no effective sample sizes, acceptance rates, or autocorrelation times are mentioned, leaving open whether the variance of the pseudo-marginal estimator grows uncontrollably with missingness fraction and undermines mixing in realistic settings.
minor comments (2)
- The abstract refers to 'computing strategies' but provides no concrete details on implementation (e.g., choice of proposal distributions or handling of the missingness model); a dedicated methods subsection would improve clarity.
- No comparison is drawn to existing missing-data methods (multiple imputation, EM, or full-data augmentation); adding even a brief literature contrast would help situate the contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and indicate planned revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'is asymptotically exact' is asserted at a high level without specifying the unbiased estimator for the marginal likelihood (integrating over missing covariates and the missingness mechanism) or sketching why the pseudo-marginal MH targets the correct joint posterior; this detail is load-bearing for the exactness guarantee.
Authors: We agree that the abstract would benefit from additional detail on this point. The pseudo-marginal MH algorithm relies on an unbiased Monte Carlo estimator of the marginal likelihood obtained by integrating the complete-data likelihood over the missing covariates (drawn from their conditional distribution given observed data) and the missingness indicators. This unbiasedness ensures the chain targets the correct joint posterior on the GLM parameters, covariate model parameters, and missingness mechanism parameters. In the revised version we will expand the abstract to include a concise description of this estimator and its role in guaranteeing asymptotic exactness. revision: yes
-
Referee: [Simulation study] Simulation study (described in abstract): only changes in standard errors with percent missingness are reported; no effective sample sizes, acceptance rates, or autocorrelation times are mentioned, leaving open whether the variance of the pseudo-marginal estimator grows uncontrollably with missingness fraction and undermines mixing in realistic settings.
Authors: The simulation was designed to demonstrate the effect of increasing missingness on posterior standard errors under the joint model. We acknowledge that reporting effective sample sizes, acceptance rates, and autocorrelation times would allow readers to assess mixing and estimator stability directly. In the revision we will augment the simulation section with these diagnostics across the range of missingness fractions examined. revision: yes
Circularity Check
No significant circularity; derivation is self-contained standard MCMC application
full rationale
The paper describes a pseudo-marginal Metropolis-Hastings algorithm for GLMs with missing data. The provided abstract and context contain no equations, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems. The asymptotic exactness claim is the standard property of pseudo-marginal MH (unbiased likelihood estimator yields exact target) and does not reduce to any input by construction within this work. No self-definitional, ansatz-smuggling, or renaming patterns appear. This is the common honest non-finding for methodological papers that apply established techniques without internal circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard convergence properties of pseudo-marginal Metropolis-Hastings and MCMC
Reference graph
Works this paper leans on
-
[1]
Andrieu, C. and G. O. Roberts (2009, 04). The pseudo-marginal approach for efficient monte carlo computations. Ann. Statist. 37 (2), 697–725
work page 2009
-
[2]
Andrieu, C. and M. Vihola (2016, 10). Establishing some order amongst exact approximations of mcmcs. Ann. Appl. Probab. 26 (5), 2661–2696
work page 2016
-
[3]
Beaumont, M. A. (2003). Estimation of population growth or decline in genetically monitored populations. Genetics 164 (3), 1139–1160
work page 2003
-
[4]
Deligiannidis, G., A. Doucet, and M. K. Pitt (2015). The correlated pseudo-marginal method
work page 2015
-
[5]
Doucet, A., M. K. Pitt, G. Deligiannidis, and R. Kohn (2015). Efficient implementation of markov chain monte carlo when using an unbiased like- lihood estimator. Biometrika 102 (2), 295–313
work page 2015
-
[6]
Forman, J. L. and T. L. McMurry (2018). Nonlinear models of injury risk and implications in intervention targeting for thoracic injury mitigation. Traffic Injury Prevention 19 (sup2), S103–S108. PMID: 30624079
work page 2018
- [7]
-
[8]
Gennarelli, T. A. and E. Wodzin (2006, Dec). ¡em¿ais 2005¡/em¿: A contemporary injury scale. Injury 37 (12), 1083–1091
work page 2006
-
[9]
Hastings, W. K. (1970). Monte carlo sampling methods using markov chains and their applications. Biometrika 57 (1), 97–109
work page 1970
-
[10]
Overview of the crashworthiness data system
Highway National Traffic Safety Administration (2016). Overview of the crashworthiness data system. [Online; accessed 16-May-2019]
work page 2016
-
[11]
Honaker, J., G. King, and M. Blackwell (2011). Amelia II: A program for missing data. Journal of Statistical Software 45 (7), 1–47
work page 2011
- [12]
-
[13]
Kahn, H. and T. E. Harris (1951). Estimation of particle transmission by random sampling. National Bureau of Standards Applied Mathematical Series 12 , 27–30
work page 1951
-
[14]
Lee, K. J. and J. B. Carlin (2010, 01). Multiple Imputation for Missing Data: Fully Conditional Specification Versus Multivariate Normal Impu- tation. American Journal of Epidemiology 171 (5), 624–632
work page 2010
-
[15]
Little, R. J. and D. B. Rubin (2019). Statistical analysis with missing data, Volume 793. Wiley
work page 2019
-
[16]
Owen, A. B. (2013). Monte Carlo theory, methods and examples
work page 2013
-
[17]
R: A Language and Environment for Statistical Computing
R Core Team (2019). R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing
work page 2019
-
[18]
Raghunathan, T. E., J. M. Lepkowski, J. V. Hoewyk, and P. Solenberger (2001). A multivariate technique for multiply imputing missing values using a sequence of regression models. survey methodology 27
work page 2001
-
[19]
Rubin, D. B. (1978). Multiple imputations in sample surveys-a phe- nomenological bayesian approach to nonresponse. In Proceedings of the survey research methods section of the American Statistical Association , Volume 1, pp. 20–34. American Statistical Association
work page 1978
-
[20]
Rubin, D. B. (1987). Multiple Imputation for Nonresponse in Surveys . Wiley. 20
work page 1987
-
[21]
Schafer, J. (1997). Analysis of Incomplete Multivariate Data . London: Chapman and Hall
work page 1997
-
[22]
Sherlock, C., A. H. Thiery, G. O. Roberts, and J. S. Rosenthal (2015, 02). On the efficiency of pseudo-marginal random walk metropolis algo- rithms. Ann. Statist. 43 (1), 238–275
work page 2015
- [23]
-
[24]
van Buuren, S. and K. Groothuis-Oudshoorn (2011). mice: Multivariate imputation by chained equations in r.Journal of Statistical Software 45(3), 1–67. 21
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.