SSDFS: Towards LFS Flash-Friendly File System without GC operation
Pith reviewed 2026-05-24 15:18 UTC · model grok-4.3
The pith
SSDFS combines logical segments, diff-on-write, and specialized b-trees to manage SSD writes without traditional garbage collection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
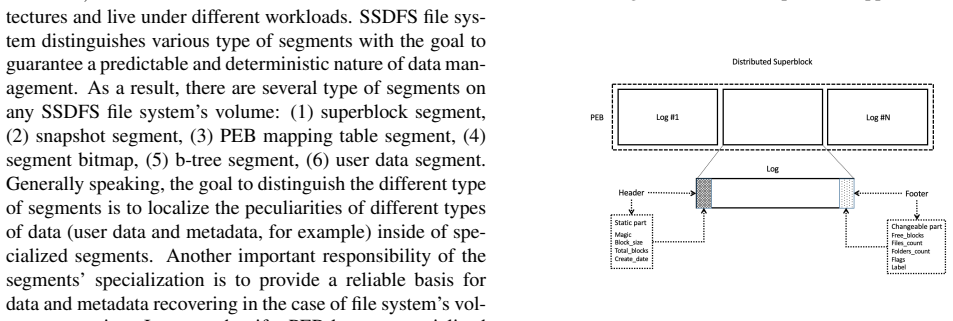
SSDFS file system introduces several authentic concepts and mechanisms: logical segment, logical extent, segment's PEBs pool, Main/Diff/Journal areas in the PEB's log, Diff-On-Write approach, PEBs migration scheme, hot/warm data self-migration, segment bitmap, hybrid b-tree, shared dictionary b-tree, shared extents b-tree. Combination of all suggested concepts are able: (1) manage write amplification in smart way, (2) decrease GC overhead, (3) prolong SSD lifetime, and (4) provide predictable file system's performance.
What carries the argument
The Diff-On-Write approach inside Main/Diff/Journal areas of PEB logs, paired with logical segments, PEB migration, and hybrid/shared b-trees that track extents and dictionaries.
If this is right
- Write amplification is kept low by writing only changed portions of data rather than full blocks.
- GC overhead drops because hot and warm data self-migrate within logical segments.
- SSD lifetime extends because fewer total writes reach the NAND cells.
- File system performance stays predictable because background migration replaces sudden GC bursts.
Where Pith is reading between the lines
- The segment bitmap and PEB pool could be reused in other log-structured systems to simplify extent tracking.
- Shared dictionary and extents b-trees might reduce metadata duplication in large-scale storage setups.
- The migration scheme for hot data could be tested as an add-on to existing flash file systems to measure lifetime gains.
Load-bearing premise
The listed mechanisms can be combined in an actual implementation to deliver the four listed benefits without introducing offsetting overheads or compatibility problems.
What would settle it
A working prototype of SSDFS run on real SSD hardware that exhibits higher write amplification, more frequent GC pauses, or shorter measured endurance than F2FS under identical mixed read-write workloads would falsify the central claim.
Figures


















































read the original abstract
Solid state drives have a number of interesting characteristics. However, there are numerous file system and storage design issues for SSDs that impact the performance and device endurance. Many flash-oriented and flash-friendly file systems introduce significant write amplification issue and GC overhead that results in shorter SSD lifetime and necessity to use the NAND flash overprovisioning. SSDFS file system introduces several authentic concepts and mechanisms: logical segment, logical extent, segment's PEBs pool, Main/Diff/Journal areas in the PEB's log, Diff-On-Write approach, PEBs migration scheme, hot/warm data self-migration, segment bitmap, hybrid b-tree, shared dictionary b-tree, shared extents b-tree. Combination of all suggested concepts are able: (1) manage write amplification in smart way, (2) decrease GC overhead, (3) prolong SSD lifetime, and (4) provide predictable file system's performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SSDFS, a log-structured file system for SSDs, introducing mechanisms including logical segments, logical extents, segment PEBs pools, Main/Diff/Journal areas, Diff-On-Write, PEB migration, hot/warm self-migration, segment bitmaps, hybrid B-trees, shared dictionary B-trees, and shared extents B-trees. It claims that the combination of these concepts manages write amplification, decreases GC overhead, prolongs SSD lifetime, and yields predictable performance without GC operations.
Significance. If the mechanisms can be shown to interact without offsetting costs, the design would address longstanding write-amplification and endurance problems in flash file systems by eliminating GC, potentially improving both device lifetime and I/O predictability over conventional LFS and F2FS-style approaches.
major comments (3)
- [Abstract] Abstract: the central claim that the listed mechanisms 'are able' to deliver the four benefits (write-amplification management, GC elimination, lifetime extension, predictable performance) is presented without any analytical model, cost accounting, or interaction analysis showing that bitmap maintenance, multi-tree lookups, and migration traffic do not re-introduce write amplification or latency variance.
- [Abstract] The manuscript describes each mechanism in isolation but supplies no quantitative evaluation, simulation, or prototype measurements that would validate the claim that their combination avoids offsetting overheads (reader’s weakest assumption).
- [Abstract] No section provides even a high-level accounting of how Diff-On-Write plus PEB migration plus segment bitmap together eliminate GC while preserving the log-structured property; the absence of such reasoning makes the 'without GC operation' title claim unsupported.
minor comments (2)
- [Abstract] Abstract contains a subject-verb agreement error: 'Combination of all suggested concepts are able' should be 'is able'.
- The manuscript would benefit from explicit comparison tables or diagrams contrasting SSDFS mechanisms against existing LFS designs (e.g., F2FS, NILFS) on write-amplification and GC metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments and indicate planned revisions to strengthen the presentation of the design claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the listed mechanisms 'are able' to deliver the four benefits (write-amplification management, GC elimination, lifetime extension, predictable performance) is presented without any analytical model, cost accounting, or interaction analysis showing that bitmap maintenance, multi-tree lookups, and migration traffic do not re-introduce write amplification or latency variance.
Authors: We agree the abstract would benefit from explicit reference to supporting analysis. The manuscript details mechanism interactions in the design sections, but we will revise the abstract to note the cost accounting and add a dedicated subsection on interaction analysis to address potential overheads from bitmaps, lookups, and migrations. revision: yes
-
Referee: [Abstract] The manuscript describes each mechanism in isolation but supplies no quantitative evaluation, simulation, or prototype measurements that would validate the claim that their combination avoids offsetting overheads (reader’s weakest assumption).
Authors: The manuscript is design-focused. We acknowledge the value of validation and will add high-level analytical models plus preliminary simulation results in the revision to demonstrate that the combined mechanisms avoid offsetting overheads. revision: yes
-
Referee: [Abstract] No section provides even a high-level accounting of how Diff-On-Write plus PEB migration plus segment bitmap together eliminate GC while preserving the log-structured property; the absence of such reasoning makes the 'without GC operation' title claim unsupported.
Authors: We will insert a new subsection providing the requested high-level accounting. It will step through the combined operation of Diff-On-Write, PEB migration, and segment bitmaps to show GC elimination while retaining the log-structured property, thereby supporting the title claim. revision: yes
Circularity Check
No significant circularity: high-level design proposal without derivations or equations
full rationale
The manuscript is a high-level design proposal that enumerates mechanisms (logical segment, Diff-On-Write, hybrid b-tree, etc.) and asserts their combination can achieve four benefits. It contains no equations, fitted parameters, mathematical derivations, or load-bearing self-citations. No step reduces a claimed result to its own inputs by construction; the central assertion remains an untested design hypothesis rather than a circular derivation. This matches the default expectation of no circularity for papers lacking quantitative chains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flash memory exhibits write amplification and limited endurance that file-system organization can materially reduce.
invented entities (3)
-
logical segment
no independent evidence
-
Diff-On-Write approach
no independent evidence
-
PEBs migration scheme
no independent evidence
Reference graph
Works this paper leans on
-
[1]
SSDFS Project, [Online]. Available: http://www. ssdfs.org, Accessed on: Jun. 19, 2019
work page 2019
-
[2]
V . A. Dubeyko, C. Guyot, ”Systems and methods for improving flash-oriented file system garbage collec- tion,” U.S. Patent Application US20170017405, pub- lished January 19, 2017
work page 2017
-
[3]
V . A. Dubeyko, C. Guyot, ”Systems and methods for improving flash-oriented file system garbage collec- tion,” U.S. Patent Application US20170017406, pub- lished January 19, 2017
work page 2017
-
[4]
V . A. Dubeyko, C. Guyot, ”Method of decreasing write amplification factor and over-provisioning of NAND flash by means of Diff-On-Write approach,” U.S. Patent Application US20170139616, published May 18, 2017
work page 2017
-
[5]
V . A. Dubeyko, C. Guyot, ”Method of decreasing write amplification of NAND flash using a journal approach,” U.S. Patent 10,013,346, issued March 7, 2018
work page 2018
-
[6]
V . A. Dubeyko, C. Guyot, ”Method of improving garbage collection efficiency of flash-oriented file sys- tems using a journaling approach,” U.S. Patent Appli- cation US20170139825, published May 18, 2017
work page 2017
-
[7]
V . A. Dubeyko, ”Bitmap Processing for Log-Structured Data Store,” U.S. Patent Application US20190018601, published January 17, 2019
work page 2019
-
[8]
V . A. Dubeyko, S. Song, ”Non-volatile storage system that reclaims bad blocks,” U.S. Patent 10,223,216, is- sued March 5, 2019
work page 2019
-
[9]
V . A. Dubeyko, S. Song, ”Non-volatile storage sys- tem that reclaims bad blocks,” U.S. Patent Application US20190155703, published May 23, 2019
work page 2019
-
[10]
Agrawal, et al., ”A Five-Year Study of File-System Metadata,” ACM Transactions on Storage (TOS), vol. 3 Issue 3, Oct. 2007, Article No. 9
work page 2007
-
[11]
Wright, ”A nine year study of file system and storage benchmarking,” Trans
Avishay Traeger, Erez Zadok, Nikolai Joukov, and Charles P. Wright, ”A nine year study of file system and storage benchmarking,” Trans. Storage 4, 2, Arti- cle 5 (May 2008), 56 pages. 45
work page 2008
-
[12]
Douceur, et al., ”A Large-Scale Study of File-System Contents,” SIGMETRICS ’99 Proceedings of the 1999 ACM SIGMETRICS international conference on Mea- surement and modeling of computer systems, pp. 59- 70, May 1-4, 1999
work page 1999
-
[13]
Lucas Tan, Fuyao Zhao, Xu Zhang, ”15712 Advanced Operating and Distributed System Android and iOS Platform Study Final Report,” [Online]. Available: https://pdfs.semanticscholar.org/48f8/ 1b9339ec3fcee1cc8031575e6f7b84c57c84.pdf, Accessed on: Jun. 21, 2019
work page 2019
-
[14]
Tyler Harter, Chris Dragga, Michael Vaughn, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau, ”A file is not a file: understanding the I/O behavior of Apple desktop applications,” In Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles (SOSP ’11). ACM, New York, NY , USA, 71- 83
-
[15]
A. B. Downey, ”The structural cause of file size dis- tributions,” MASCOTS 2001, Proceedings Ninth Inter- national Symposium on Modeling, Analysis and Sim- ulation of Computer and Telecommunication Systems, Cincinnati, OH, USA, 2001, pp. 361-370
work page 2001
-
[16]
M. I. Ullah, F. Ahsan, I. Ahmad and A. F. M. Ishaq, ”Analysis of file system space utilization patterns in UNIX based volumes,” Proceedings of the IEEE Sym- posium on Emerging Technologies, 2005, Islamabad, 2005, pp. 542-546
work page 2005
-
[17]
Tim Gibson, Ethan L. Miller, Darrell D. E. Long, ”Long-term File Activity and Inter-Reference Pat- terns,” [Online]. Available: https://www.ssrc. ucsc.edu/papers/CMG-Gibson-1998.pdf, Ac- cessed on: Jun. 25, 2019
work page 1998
-
[18]
Available: https://www.pdl.cmu
Yifan Wang, ”A Statistical Study for File Sys- tem Meta Data On High Performance Computing Sites,” [Online]. Available: https://www.pdl.cmu. edu/PDL-FTP/HECStorage/Yifan_Final.pdf, Accessed on: Jun. 25, 2019
work page 2019
-
[19]
A. Wildani, I. F. Adams and E. L. Miller, ”Single- Snapshot File System Analysis,” 2013 IEEE 21st Inter- national Symposium on Modelling, Analysis and Sim- ulation of Computer and Telecommunication Systems, San Francisco, CA, 2013, pp. 338-341
work page 2013
-
[20]
S. Hui, Z. Rui, C. Jin, L. Lei, W. Fei and X. C. Sheng, ”Analysis of the File System and Block IO Scheduler for SSD in Performance and Energy Consumption,” 2011 IEEE Asia-Pacific Services Computing Confer- ence, Jeju Island, 2011, pp. 48-55
work page 2011
-
[21]
D. Parthey and R. Baumgartl, ”Analyzing Access Timing of Removable Flash Media,” 13th IEEE In- ternational Conference on Embedded and Real-Time Computing Systems and Applications (RTCSA 2007), Daegu, 2007, pp. 510-515
work page 2007
-
[22]
Y . Son, H. Kang, H. Han and H. Y . Yeom, ”An Empir- ical Evaluation of NVM Express SSD,” 2015 Interna- tional Conference on Cloud and Autonomic Comput- ing, Boston, MA, 2015, pp. 275-282
work page 2015
-
[23]
K. Zhou, P. Huang, C. Li and H. Wang, ”An Empirical Study on the Interplay between Filesystems and SSD,” 2012 IEEE Seventh International Conference on Net- working, Architecture, and Storage, Xiamen, Fujian, 2012, pp. 124-133
work page 2012
-
[24]
P. Olivier, J. Boukhobza and E. Senn, ”Micro- benchmarking Flash Memory File-System Wear Level- ing and Garbage Collection: A Focus on Initial State Impact,” 2012 IEEE 15th International Conference on Computational Science and Engineering, Nicosia, 2012, pp. 437-444
work page 2012
-
[25]
P. Olivier, J. Boukhobza and E. Senn, ”Modeling driver level NAND flash memory I/O performance and power consumption for embedded Linux,” 2013 11th Inter- national Symposium on Programming and Systems (ISPS), Algiers, 2013, pp. 143-152
work page 2013
- [26]
- [27]
-
[28]
S. Park and K. Shen, ”A performance evaluation of scientific I/O workloads on Flash-based SSDs,” 2009 IEEE International Conference on Cluster Computing and Workshops, New Orleans, LA, 2009, pp. 1-5
work page 2009
-
[29]
B. Gu, J. Lee, B. M. Jung, J. Seo and H. Shin, ”Uti- lization analysis of trim-enabled NAND flash mem- ory,” 2013 IEEE International Conference on Con- sumer Electronics (ICCE), Las Vegas, NV , 2013, pp. 645-646
work page 2013
-
[30]
Y . Wang, K. Goda, M. Nakano and M. Kitsuregawa, ”Early Experience and Evaluation of File Systems on SSD with Database Applications,” 2010 IEEE Fifth In- ternational Conference on Networking, Architecture, and Storage, Macau, 2010, pp. 467-476. 46
work page 2010
-
[31]
S. S. Rizvi and T. Chung, ”Flash memory SSD based DBMS for high performance computing embedded and multimedia systems,” The 2010 International Con- ference on Computer Engineering & Systems, Cairo, 2010, pp. 183-188
work page 2010
- [32]
-
[33]
J. Chen, J. Wang, Z. Tan and C. Xie, ”Effects of Recursive Update in Copy-on-Write File Systems: A BTRFS Case Study,” in Canadian Journal of Electrical and Computer Engineering, vol. 37, no. 2, pp. 113-122, Spring 2014
work page 2014
-
[34]
Ousterhout, ”The de- sign and implementation of a log-structured file sys- tem,” ACM Trans
Mendel Rosenblum and John K. Ousterhout, ”The de- sign and implementation of a log-structured file sys- tem,” ACM Trans. Comput. Syst. 10, 1 (February 1992), 26-52
work page 1992
-
[35]
Available: http: //citeseerx.ist.psu.edu/viewdoc/summary? doi=10.1.1.630.3461, Accessed on: Jun
David Woodhouse, ”JFFS: the journalling flash file system,” [Online]. Available: http: //citeseerx.ist.psu.edu/viewdoc/summary? doi=10.1.1.630.3461, Accessed on: Jun. 20, 2019
work page 2019
-
[36]
Bityutskiy, ”JFFS3 design issues,” [On- line]
Artem B. Bityutskiy, ”JFFS3 design issues,” [On- line]. Available: http://citeseerx.ist.psu. edu/viewdoc/summary?doi=10.1.1.107.9834, Accessed on: Jun. 20, 2019
work page 2019
-
[37]
Available: http://www.linux-mtd.infradead.org/doc/ ubifs_whitepaper.pdf, Accessed on: Jun
Adrian Hunter, ”A Brief Introduction to the Design of UBIFS,” [Online]. Available: http://www.linux-mtd.infradead.org/doc/ ubifs_whitepaper.pdf, Accessed on: Jun. 20, 2019
work page 2019
-
[38]
Bityutskiy, ”UBIFS file sys- tem,” [Online]
Adrian Hunter, Artem B. Bityutskiy, ”UBIFS file sys- tem,” [Online]. Available: http://www.linux-mtd. infradead.org/doc/ubifs.pdf, Accessed on: Jun. 20, 2019
work page 2019
-
[39]
Available: https://yaffs.net/sites/yaffs
Charles Manning, ”How Y AFFS Works,” [Online]. Available: https://yaffs.net/sites/yaffs. net/files/HowYaffsWorks.pdf, Accessed on: Jun. 20, 2019
work page 2019
-
[40]
Technical note, the Nilfs version 1: overview. [On- line]. Available: https://nilfs.sourceforge.io/ papers/overview-v1.pdf, Accessed on: Jun. 20, 2019
work page 2019
- [41]
-
[42]
J ¨orn Engel, Robert Mertens, ”LogFS-finally a scalable flash file system,” [Online]. Available: https://www.researchgate.net/publication/ 228865441_LogFS-finally_a_scalable_flash_ file_system, Accessed on: Jun. 21, 2019
work page 2019
-
[43]
USENIX Association, Berkeley, CA, USA, 273-286
Changman Lee, Dongho Sim, Joo-Young Hwang, and Sangyeun Cho, ”F2FS: a new file system for flash stor- age,” In Proceedings of the 13th USENIX Conference on File and Storage Technologies (FAST’15). USENIX Association, Berkeley, CA, USA, 273-286
-
[44]
TaeHoon Kim, KwangMu Shin, TaeHoon Lee, KiDong Jung, ”Design of a Reliable NAND Flash Software for Mobile Device,” [Online]. Available: http: //citeseerx.ist.psu.edu/viewdoc/download? doi=10.1.1.554.8864&rep=rep1&type=pdf, Accessed on: Jun. 24, 2019
work page 2019
- [45]
-
[46]
S. O. Park and S. J. Kim, ”An Efficient Array File Sys- tem for Multiple Small-Capacity NAND Flash Memo- ries,” 2011 14th International Conference on Network- Based Information Systems, Tirana, 2011, pp. 569-572
work page 2011
-
[47]
J. Kim, H. Jo, H. Shim, J. Kim and S. Maeng, ”Effi- cient Metadata Management for Flash File Systems,” 2008 11th IEEE International Symposium on Object and Component-Oriented Real-Time Distributed Com- puting (ISORC), Orlando, FL, 2008, pp. 535-540
work page 2008
-
[48]
S. O. Park and S. J. Kim, ”An efficient multimedia file system for NAND flash memory storage,” in IEEE Transactions on Consumer Electronics, vol. 55, no. 1, pp. 139-145, February 2009
work page 2009
-
[49]
Seung-Ho Lim and Kyu-Ho Park, ”An efficient NAND flash file system for flash memory storage,” in IEEE Transactions on Computers, vol. 55, no. 7, pp. 906-912, July 2006
work page 2006
-
[50]
H. Kim, Y . Won and S. Kang, ”Embedded NAND flash file system for mobile multimedia devices,” in IEEE Transactions on Consumer Electronics, vol. 55, no. 2, pp. 545-552, May 2009
work page 2009
-
[51]
C. T. Chen, C. H. Chen and W. T. Huang, ”Energy- aware management of NAND type flash file system,” in Electronics Letters, vol. 42, no. 14, pp. 795-796, 6 July 2006. 47
work page 2006
-
[52]
A. S. Ramasamy and P. Karantharaj, ”File system and storage array design challenges for flash mem- ory,” 2014 International Conference on Green Comput- ing Communication and Electrical Engineering (ICGC- CEE), Coimbatore, 2014, pp. 1-8
work page 2014
-
[53]
B. Nahill and Z. Zilic, ”FLogFS: A lightweight flash log file system,” 2015 IEEE 12th International Confer- ence on Wearable and Implantable Body Sensor Net- works (BSN), Cambridge, MA, 2015, pp. 1-6
work page 2015
-
[54]
Yang Ou, Xiaoquan Wu, Nong Xiao, Fang Liu and Wei Chen, ”HIFFS: A Hybrid Index for Flash File System,” 2015 IEEE International Conference on Networking, Architecture and Storage (NAS), Boston, MA, 2015, pp. 363-364
work page 2015
- [55]
-
[56]
S. Yang and C. Wu, ”A Low-Memory Management for Log-Based File Systems on Flash Memory,” 2009 15th IEEE International Conference on Embedded and Real- Time Computing Systems and Applications, Beijing, 2009, pp. 219-227
work page 2009
-
[57]
W. Qiu, X. Chen, N. Xiao, F. Liu and Z. Chen, ”A New Exploration to Build Flash-Based Storage Sys- tems by Co-designing File System and FTL,” 2013 IEEE 16th International Conference on Computational Science and Engineering, Sydney, NSW, 2013, pp. 925-932
work page 2013
-
[58]
T. Chen, X. Wang, W. Hu and W. Duan, ”A New Type of NAND Flash-Based File System: Design and Imple- mentation,” 2006 International Conference on Wireless Communications, Networking and Mobile Computing, Wuhan, 2006, pp. 1-4
work page 2006
-
[59]
S. Lee, J. Kim and A. Mithal, ”Refactored Design of I/O Architecture for Flash Storage,” in IEEE Computer Architecture Letters, vol. 14, no. 1, pp. 70-74, 1 Jan.- June 2015
work page 2015
-
[60]
Junkil Ryu and C. Park, ”A technique to enhance per- formance of log-based file systems for flash memory in embedded systems,” 2007 2nd International Confer- ence on Digital Information Management, Lyon, 2007, pp. 580-582
work page 2007
-
[61]
Byungjo Kim, Dong Hyun Kang, Changwoo Min and Young Ik Eom, ”Understanding implications of trim, discard, and background command for eMMC storage device,” 2014 IEEE 3rd Global Conference on Con- sumer Electronics (GCCE), Tokyo, 2014, pp. 709-710
work page 2014
-
[62]
C. Min, S. Lee and Y . I. Eom, ”Design and Implemen- tation of a Log-Structured File System for Flash-Based Solid State Drives,” in IEEE Transactions on Comput- ers, vol. 63, no. 9, pp. 2215-2227, Sept. 2014
work page 2014
-
[63]
Jun Wang and Yiming Hu, ”A novel reordering write buffer to improve write performance of log-structured file systems,” in IEEE Transactions on Computers, vol. 52, no. 12, pp. 1559-1572, Dec. 2003
work page 2003
-
[64]
Jun Wang and Yiming Hu, ”PROFS-performance- oriented data reorganization for log-structured file sys- tem on multi-zone disks,” MASCOTS 2001, Proceed- ings Ninth International Symposium on Modeling, Analysis and Simulation of Computer and Telecommu- nication Systems, Cincinnati, OH, USA, 2001, pp. 285- 292
work page 2001
-
[65]
R. Agarwal and M. Marrow, ”A closed-form expression for write amplification in NAND Flash,” 2010 IEEE Globecom Workshops, Miami, FL, 2010, pp. 1846- 1850
work page 2010
-
[66]
A. Jagmohan, M. Franceschini and L. Lastras, ”Write amplification reduction in NAND Flash through multi- write coding,” 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV , 2010, pp. 1-6
work page 2010
-
[67]
Y . Chang and T. Kuo, ”A commitment-based man- agement strategy for the performance and reliability enhancement of flash-memory storage systems,” 2009 46th ACM/IEEE Design Automation Conference, San Francisco, CA, 2009, pp. 858-863
work page 2009
-
[68]
Tei-Wei Kuo, Jen-Wei Hsieh, Li-Pin Chang and Yuan- Hao Chang, ”Configurability of performance and over- heads in flash management,” Asia and South Pacific Conference on Design Automation, 2006., Yokohama, 2006, p. 8
work page 2006
- [69]
-
[70]
C. Park, W. Cheon, Y . Lee, M. Jung, W. Cho and H. Yoon, ”A Re-configurable FTL (Flash Translation Layer) Architecture for NAND Flash based Appli- cations,” 18th IEEE/IFIP International Workshop on Rapid System Prototyping (RSP ’07), Porto Alegre, 2007, pp. 202-208
work page 2007
-
[71]
J. Lee, H. Kim, H. Kim, J. Park and M. Ryu, ”A se- quentializing device driver for optimizing random write 48 performance of eSSD,” 2014 IEEE International Con- ference on Consumer Electronics (ICCE), Las Vegas, NV , 2014, pp. 432-433
work page 2014
-
[72]
Y . He, S. Wan, N. Xiong and J. H. Park, ”A New Prefetching Strategy Based on Access Density in Linux,” International Symposium on Computer Sci- ence and its Applications, Hobart, ACT, 2008, pp. 22- 27
work page 2008
-
[73]
Dingqing Hu, Changsheng Xie and C. CaiBin, ”A Study of Parallel Prefetching Algorithms Using Trace- Driven Simulation,” Sixth International Conference on Parallel and Distributed Computing Applications and Technologies (PDCAT’05), Dalian, China, 2005, pp. 476-478
work page 2005
-
[74]
Y . Kang, J. Yang and E. L. Miller, ”Efficient Storage Management for Object-based Flash Memory,” 2010 IEEE International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems, Miami Beach, FL, 2010, pp. 407-409
work page 2010
-
[75]
Q. Xie et al, ”Research on the Framework of NAND FLASH Based Object-Based-Storage-Device,” 2012 Second International Conference on Intelligent System Design and Engineering Application, Sanya, Hainan, 2012, pp. 1298-1301
work page 2012
-
[76]
Goetz Graefe, ”Modern B-Tree Techniques,” [Online]. Available: http://citeseerx.ist.psu.edu/ viewdoc/download?doi=10.1.1.219.7269&rep= rep1&type=pdf, Accessed on: Jun. 21, 2019
work page 2019
-
[77]
J. Ahn, D. Kang, D. Jung, J. Kim and S. Maeng, ” μ* -Tree: An Ordered Index Structure for NAND Flash Memory with Adaptive Page Layout Scheme,” in IEEE Transactions on Computers, vol. 62, no. 4, pp. 784-797, April 2013
work page 2013
- [78]
-
[79]
J. He et al., ”Discovering Structure in Unstructured I/O,” 2012 SC Companion: High Performance Com- puting, Networking Storage and Analysis, Salt Lake City, UT, 2012, pp. 1-6
work page 2012
-
[80]
Tsozen Yeh, J. Arul, Jia-Shian Wu, I. -. Chen and Kuo- Hsin Tan, ”Using File Grouping to Improve the Disk Performance (Extended Abstract),” 2006 15th IEEE International Conference on High Performance Dis- tributed Computing, Paris, 2006, pp. 365-366
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.