A Moment-assisted Approach for Improving Subsampling-based MLE with Large-scale data
Pith reviewed 2026-05-24 06:55 UTC · model grok-4.3
The pith
Subsampling-based maximum likelihood estimation can match full-data efficiency by incorporating optimal sample moments from the entire dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
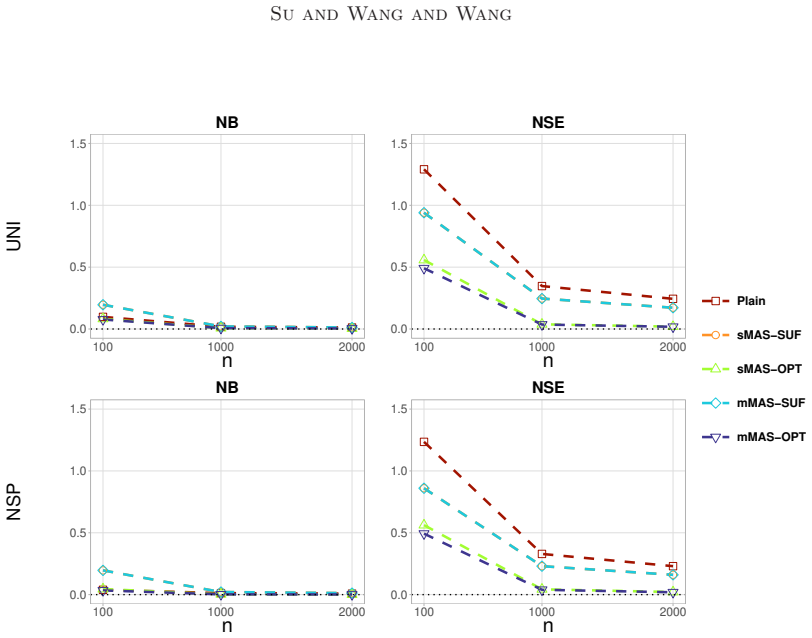
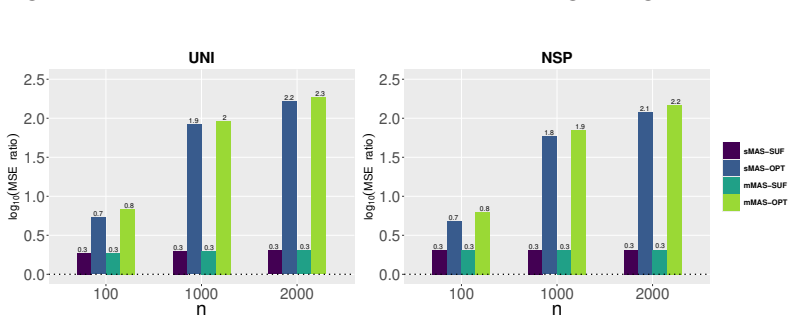
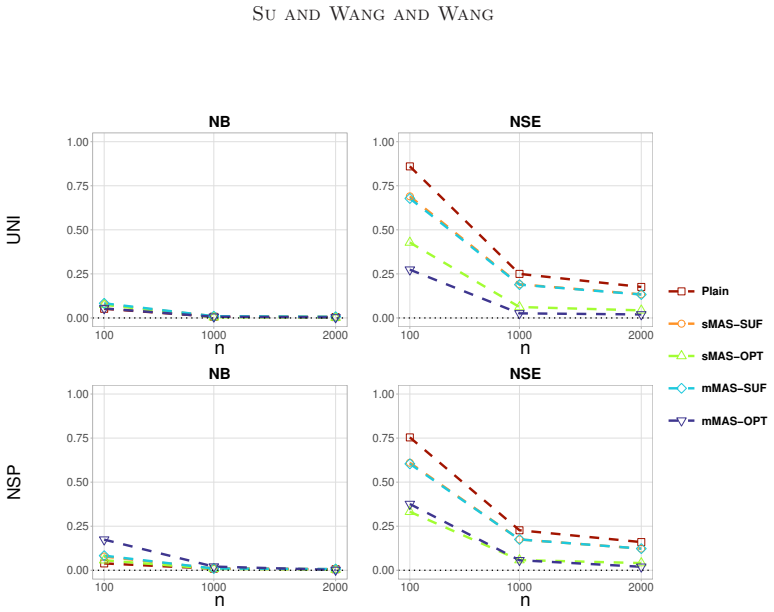
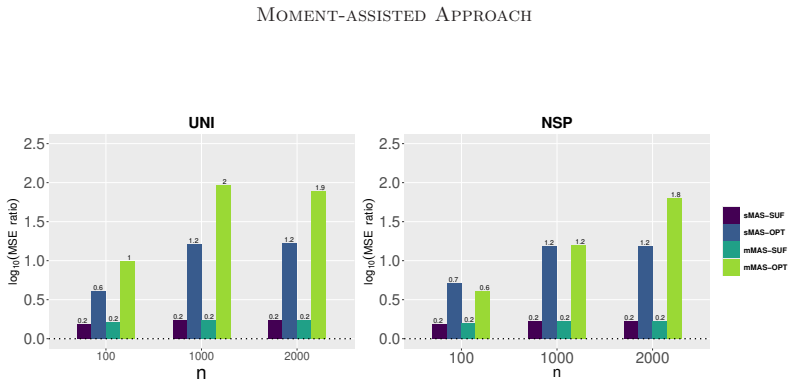
The MAS estimator, formed by combining a subsampled likelihood with GMM constraints from full-data moments, is asymptotically normal with asymptotic variance that is smaller than the subsampled MLE alone and that equals the full-data MLE variance when the optimal moment is incorporated.
What carries the argument
The moment-assisted subsampling (MAS) estimator constructed via generalized method of moments that augments the subsampled likelihood score with whole-data sample moments.
If this is right
- The asymptotic variance of the MAS estimator is strictly smaller than that of the corresponding subsampled MLE without moment augmentation.
- When the optimal moment is used, the MAS estimator achieves the same asymptotic efficiency as the full-data maximum likelihood estimator.
- The method remains computationally fast because the additional moments can be calculated in linear time even for massive datasets.
- The efficiency gain holds for likelihoods that contain intractable integrals where direct full-data MLE is prohibitive.
Where Pith is reading between the lines
- The same moment-augmentation idea could be applied to other computationally intensive estimators such as M-estimators or quasi-likelihood methods.
- In settings where multiple candidate moments exist, a data-driven selection rule would be needed to approximate the optimal moment without knowing the true parameter.
- The approach suggests that pre-computing a small set of low-cost statistics can serve as a general bridge between subsampling and full-data analysis in distributed or streaming environments.
Load-bearing premise
The chosen sample moments are correctly specified under the model and do not introduce bias when combined with the subsampled likelihood.
What would settle it
A simulation with known true parameters in which the asymptotic variance of the MAS estimator using the derived optimal moment exceeds the variance of the full-data MLE would falsify the efficiency claim.
Figures
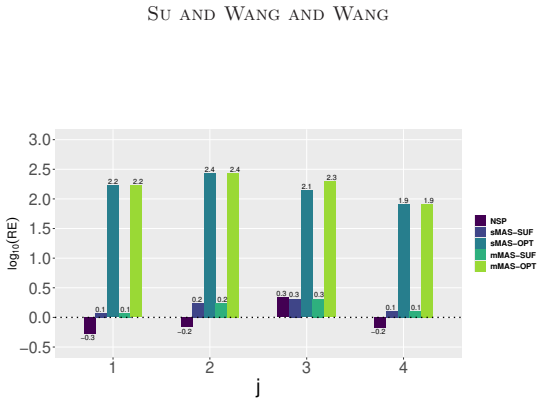
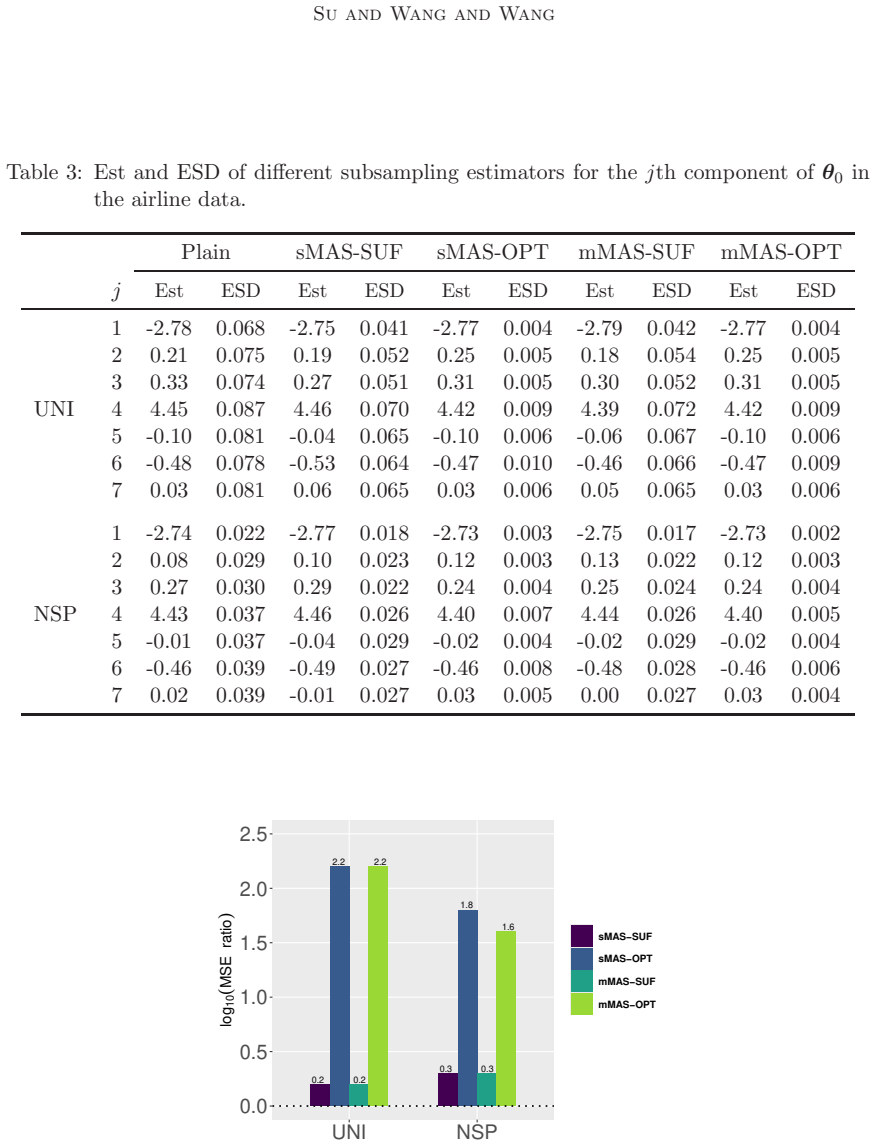
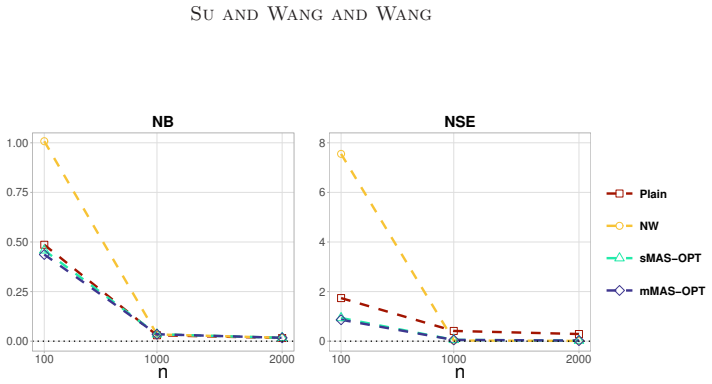
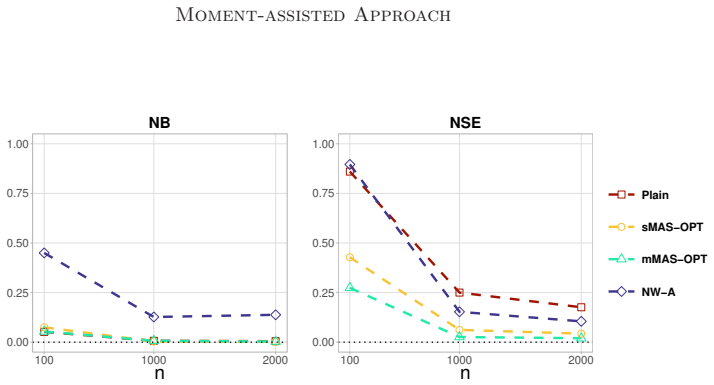
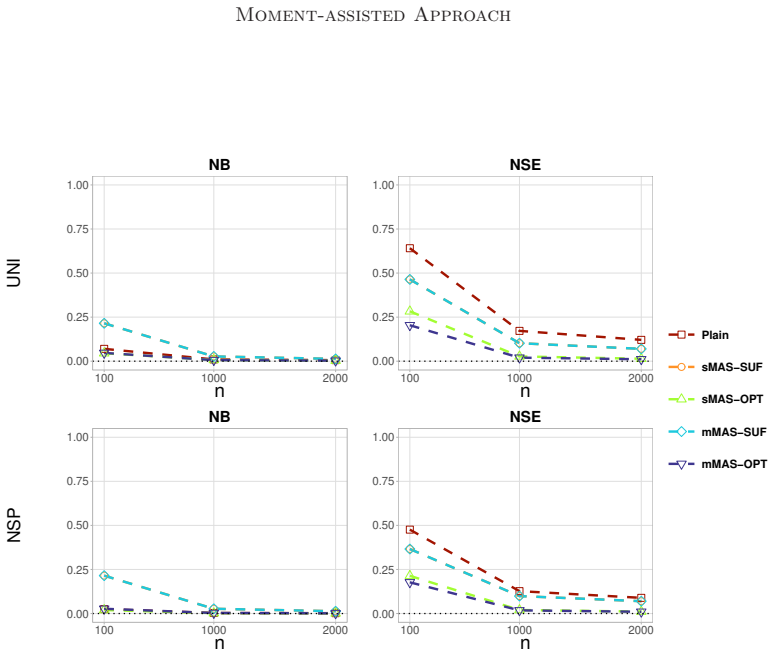
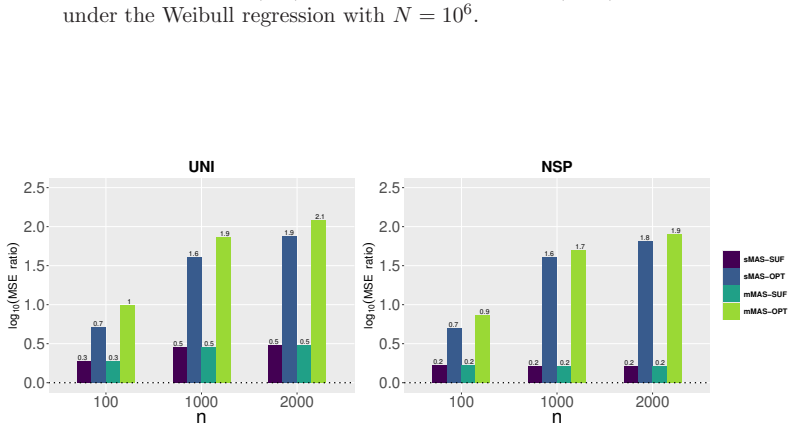
read the original abstract
The maximum likelihood estimation is computationally demanding for large datasets, particularly when the likelihood function includes integrals. Subsampling can reduce the computational burden, but it often results in efficiency loss.This paper proposes a moment-assisted subsampling (MAS) method that can improve the estimation efficiency of existing subsampling-based maximum likelihood estimators.The motivation behind this approach stems from the fact that sample moments can be efficiently computed even if the sample size of the whole data set is huge.Through the generalized method of moments, the proposed method incorporates informative sample moments of the whole data. The MAS estimator can be computed rapidly and is asymptotically normal with a smaller asymptotic variance than the corresponding estimator without incorporating sample moments of the whole data. The asymptotic variance of the proposed estimator depends on the specific sample moments incorporated. We derive the optimal moment that minimizes the resulting asymptotic variance in terms of Loewner order. The proposed MAS estimator can achieve the same estimation efficiency as the whole data-based estimator when the optimal moment is incorporated. Numerical results demonstrate the promising performance of the proposed method in both estimation and computational efficiency compared with existing subsampling methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a moment-assisted subsampling (MAS) estimator that augments a subsampled MLE with full-data sample moments via GMM. It claims the resulting estimator is asymptotically normal, has strictly smaller asymptotic variance than the plain subsampled MLE, and recovers the full-data MLE efficiency when the optimal moment (in the Loewner sense) is used.
Significance. If the joint asymptotics are correctly derived, the method supplies a computationally cheap route to near-full efficiency for expensive MLE problems by exploiting moments that can be computed on the entire data set; this would be a useful addition to the subsampling literature.
major comments (2)
- [Asymptotic theory section] Asymptotic theory section (derivation of the joint CLT and variance formula): the claimed asymptotic variance reduction and the Loewner-order optimality of the optimal moment both rest on the joint limiting distribution of the subsampled score (order 1/n) and the full-data moments (order 1/N). Because the subsample is drawn from the same finite population, the cross-covariance term is nonzero and of order O(n/N). The manuscript must explicitly state whether this term is retained in the sandwich formula; if it is omitted or treated as asymptotically negligible, the stated variance comparison and the recovery of full-data efficiency do not follow.
- [Theorem on optimal moment] Theorem on optimal moment (the result that the MAS estimator attains the full-data efficiency bound): the proof must verify that the chosen moment remains correctly specified and that the GMM augmentation does not introduce bias under the model. The regularity conditions under which the post-selection moment remains informative after subsampling should be stated explicitly.
minor comments (2)
- [Abstract] The abstract states that the MAS estimator 'can achieve the same estimation efficiency as the whole data-based estimator when the optimal moment is incorporated,' but the precise sense in which equality holds (e.g., asymptotic equivalence or equality of asymptotic variances) should be clarified in the main text.
- Notation for the subsample size n versus full size N is used throughout; a single consolidated table or paragraph listing all symbols and their orders would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the asymptotic theory. We address each major comment below and will revise the manuscript accordingly to improve clarity.
read point-by-point responses
-
Referee: [Asymptotic theory section] Asymptotic theory section (derivation of the joint CLT and variance formula): the claimed asymptotic variance reduction and the Loewner-order optimality of the optimal moment both rest on the joint limiting distribution of the subsampled score (order 1/n) and the full-data moments (order 1/N). Because the subsample is drawn from the same finite population, the cross-covariance term is nonzero and of order O(n/N). The manuscript must explicitly state whether this term is retained in the sandwich formula; if it is omitted or treated as asymptotically negligible, the stated variance comparison and the recovery of full-data efficiency do not follow.
Authors: We thank the referee for highlighting this point. The joint CLT derivation in the manuscript retains the cross-covariance term of order O(n/N) in the sandwich variance formula; this term is not omitted or treated as negligible. With the term included, the claimed variance reduction relative to subsampled MLE and the attainment of full-data efficiency under the optimal moment both hold. We will add an explicit statement in the revised asymptotic theory section confirming that the cross-covariance is retained. revision: yes
-
Referee: [Theorem on optimal moment] Theorem on optimal moment (the result that the MAS estimator attains the full-data efficiency bound): the proof must verify that the chosen moment remains correctly specified and that the GMM augmentation does not introduce bias under the model. The regularity conditions under which the post-selection moment remains informative after subsampling should be stated explicitly.
Authors: The full-data sample moments are correctly specified under the model, so the GMM step introduces no bias. We will revise the proof of the optimal-moment theorem to explicitly verify correct specification and lack of bias, and we will add the required regularity conditions (including those ensuring the moments remain informative after subsampling) in the revised manuscript. revision: yes
Circularity Check
Asymptotics derived from standard GMM theory; no reduction to self-defined inputs
full rationale
The MAS estimator is formed by augmenting the subsampled score with full-data moments inside a GMM framework. The claimed asymptotic normality, variance reduction, and Loewner-optimal moment all follow from the standard GMM sandwich formula and the usual joint CLT for estimating equations. These results are external to the paper and do not reduce to any quantity defined by the paper itself. No self-citation is load-bearing for the central claims, and the derivation does not rename a fitted quantity as a prediction or smuggle an ansatz via prior work. The paper is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard regularity conditions ensuring asymptotic normality of MLE and GMM estimators
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence := #2 '...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in " " * FUNCTION format....
-
[3]
(2021 a ), Optimal Subsampling Algorithms for Big Data Regressions, Statistica Sinica, 31, 749--772
Ai, M., Yu, J., Zhang, H., and Wang, H. (2021 a ), Optimal Subsampling Algorithms for Big Data Regressions, Statistica Sinica, 31, 749--772
work page 2021
-
[4]
--- (2021 b ), Optimal subsampling for large-scale quantile regression, Journal of Complexity, 62, 101512
work page 2021
-
[5]
Drineas, P., Mahoney, M. W., and Muthukrishnan, S. (2006), Sampling algorithms for l_2 regression and applications, Proceedings of the seventeenth annual ACM-SIAM symposium on Discrete algorithm, 1127--1136
work page 2006
-
[6]
Fan, Y., Liu, Y., Liu, Y., and Qin, J. (2022), Nearly optimal capture-recapture sampling and empirical likelihood weighting estimation for M-estimation with big data, arXiv
work page 2022
-
[7]
Fithian, W. and Hastie, T. (2014), Local case-control sampling: Efficient subsampling in imbalanced data sets , The Annals of Statistics, 42, 1693 -- 1724
work page 2014
-
[8]
Han, L., Tan, K. M., Yang, T., and Zhang, T. (2020), Local uncertainty sampling for large-scale multiclass logistic regression , The Annals of Statistics, 48, 1770 -- 1788
work page 2020
-
[9]
Hansen, L. P. (1982), Large Sample Properties of Generalized Method of Moments Estimators , Econometrica, 50, 1029--1054
work page 1982
-
[10]
Hoffman, A. J. and Wielandt, H. W. (1953), The variation of the spectrum of a normal matrix , Duke Mathematical Journal, 20, 37 -- 39
work page 1953
-
[11]
Kushilevitz, E. and Nisan, N. (1996), Communication Complexity, Cambridge University Press
work page 1996
-
[12]
Newey, W. K. (1994), The asymptotic variance of semiparametric estimators, Econometrica: Journal of the Econometric Society, 1349--1382
work page 1994
-
[13]
Team, R. C. (2016), A Language and Environment for Statistical Computing, R Foundation for Statistical Computing, Vienna, Austria. URL https://www.R-project.org
work page 2016
-
[14]
van der Vaart, A. W. (2000), Asymptotic Statistics, Cambridge University Press, New York
work page 2000
-
[15]
Wang, H. (2019), More Efficient Estimation for Logistic Regression with Optimal Subsamples, Journal of Machine Learning Research, 20, 1--59
work page 2019
-
[16]
Wang, H. and Kim, J. K. (2022), Maximum sampled conditional likelihood for informative subsampling, Journal of Machine Learning Research, 23, 1--50
work page 2022
- [17]
-
[18]
Wang, H., Yang, M., and Stufken, J. (2019), Information-Based Optimal Subdata Selection for Big Data Linear Regression, Journal of the American Statistical Association, 114, 393--405
work page 2019
-
[19]
Wang, H., Zhu, R., and Ma, P. (2018), Optimal Subsampling for Large Sample Logistic Regression, Journal of the American Statistical Association, 113, 829--844
work page 2018
-
[20]
Wu, C.-F. (1980), On Some Ordering Properties of the Generalized Inverses of Nonnegative Definite Matrices, Linear Algebra and its Applications, 32, 49 -- 60
work page 1980
-
[21]
Yao, Y. and Wang, H. (2019), Optimal subsampling for softmax regression, Statistical Papers, 60, 585--599
work page 2019
-
[22]
Yu, J., Wang, H., Ai, M., and Zhang, H. (2022), Optimal Distributed Subsampling for Maximum Quasi-Likelihood Estimators With Massive Data, Journal of the American Statistical Association, 117, 1--12
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.