Enabling Data Dependency-based Query Optimization
Pith reviewed 2026-05-24 00:24 UTC · model grok-4.3
The pith
An automated system discovers and validates additional data dependencies to optimize queries without manual declarations or SQL rewrites.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
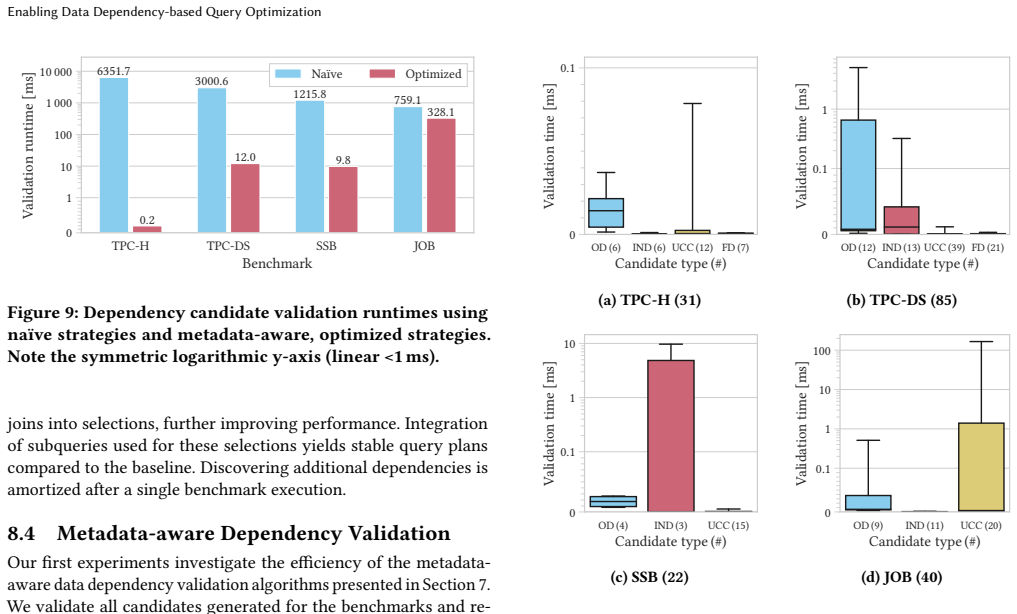
The paper claims that an integrated system can recognize dependency candidates, validate them for optimization use, and apply them in query plans, matching the performance of dedicated SQL rewrites. Compared to PKs and FKs alone, it reports geometric mean speedups of 35% on TPC-DS and 29% on JOB, with some queries improving more than 90%, and discovery costs far below the gains from one workload run.
What carries the argument
The automated pipeline that recognizes dependency candidates, validates their applicability to queries, and integrates them into existing query optimizers without manual input.
If this is right
- Queries achieve geometric mean speedups of 35% on TPC-DS and 29% on JOB over PK/FK-only optimization.
- Individual query latencies can drop by more than 90% when valid dependencies are applied.
- Dependency discovery overhead remains orders of magnitude smaller than the improvement from executing a workload once.
- The gains appear across a range of analytical database systems when dependencies are used without SQL rewrites.
Where Pith is reading between the lines
- The low overhead suggests the approach remains practical even when queries run repeatedly on the same data.
- Because no manual declaration is needed, the technique could extend to environments where schema changes frequently.
- If validation scales with data size, similar automation might apply to larger analytical workloads beyond the tested benchmarks.
Load-bearing premise
Target datasets contain additional data dependencies that can be found and checked efficiently enough for the performance gains to outweigh the discovery cost.
What would settle it
Running the system on datasets that lack extra dependencies beyond PKs and FKs, or where validation time exceeds the latency savings on a workload, would show no net benefit.
Figures





read the original abstract
Primary key (PK) and foreign key (FK) constraints are widely used for query optimization. Knowledge about additional data dependencies, such as order dependencies, enables further substantial performance improvements. However, such dependencies are not maintained by database systems or are even unknown to the user. Identifying and validating relevant dependencies automatically and efficiently remains an unsolved problem. This paper presents a system that (i) recognizes dependency candidates for optimization, (ii) efficiently validates their applicability, and (iii) optimizes query plans using valid dependencies. First, we demonstrate the performance impact of optimization techniques using data dependencies additional to PKs and FKs. Using rewritten SQL queries, we empirically show that data dependencies improve performance for a wide range of analytical database systems and benchmarks. Second, we present how to integrate data dependencies into a system to use them without (i) manual declaration and maintenance or (ii) SQL rewrites. Our integrated and fully automated system matches the performance of dedicated SQL rewrites: compared to using only PKs and FKs, queries improve with geometric mean speedups of 35 % for TPC-DS and 29 % for JOB. Individual query latencies drop by more than 90 %. The dependency discovery overhead is orders of magnitude lower than the latency improvement of a single workload execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a system for automatically recognizing, validating, and integrating data dependencies (beyond PK/FK constraints, including order dependencies) into query optimizers for analytical workloads. It first empirically demonstrates performance gains from such dependencies via hand-written SQL rewrites across database systems and benchmarks, then claims an integrated automated pipeline that matches those gains without manual declaration or rewrites, reporting geometric-mean speedups of 35% on TPC-DS and 29% on JOB (with some queries improving >90%) and discovery overhead orders of magnitude below query latency savings.
Significance. If the automated recognition+validation+integration pipeline is shown to surface the same dependencies and produce equivalent plan changes as the manual rewrites, the result would be significant: it would make dependency-based optimizations practical at scale without user intervention. The low-overhead claim and cross-system empirical gains (if reproducible) would strengthen the case for extending optimizers beyond PK/FK.
major comments (2)
- [Abstract] Abstract: the central claim that the 'integrated and fully automated system matches the performance of dedicated SQL rewrites' is load-bearing yet unsupported; no evidence is supplied that the discovery pipeline surfaces exactly the dependencies exploited by the rewrites or that the optimizer integration reproduces the same plan deltas.
- [Abstract] Abstract / experimental evaluation: the reported geometric-mean speedups (35% TPC-DS, 29% JOB) and individual >90% latency drops are presented without any description of experimental controls, statistical significance testing, workload selection criteria, or safeguards against post-hoc dependency selection, limiting verification of the performance claims.
minor comments (1)
- [Abstract] The abstract mentions 'order dependencies' as an example but does not enumerate the full set of dependency types handled by the system; a brief enumeration would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript where the concerns identify opportunities for clarification or additional evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the 'integrated and fully automated system matches the performance of dedicated SQL rewrites' is load-bearing yet unsupported; no evidence is supplied that the discovery pipeline surfaces exactly the dependencies exploited by the rewrites or that the optimizer integration reproduces the same plan deltas.
Authors: The manuscript reports that the automated pipeline produces the same geometric-mean speedups as the hand-written rewrites (35% on TPC-DS, 29% on JOB). We agree, however, that an explicit side-by-side comparison of discovered dependencies and resulting plan deltas would make the equivalence claim more direct. We will add such a comparison (e.g., a table listing dependencies used in the manual rewrites versus those surfaced by the pipeline, together with optimizer plan differences) to the revised evaluation section. revision: yes
-
Referee: [Abstract] Abstract / experimental evaluation: the reported geometric-mean speedups (35% TPC-DS, 29% JOB) and individual >90% latency drops are presented without any description of experimental controls, statistical significance testing, workload selection criteria, or safeguards against post-hoc dependency selection, limiting verification of the performance claims.
Authors: The abstract is intentionally concise; the full experimental section describes the TPC-DS and JOB workloads, query selection, and the automated discovery/validation pipeline. We will nevertheless revise the abstract to include a short statement of the benchmarks used and a pointer to the detailed methodology. We will also add any missing statistical significance results and an explicit description of how the candidate-generation step avoids post-hoc selection (candidates are enumerated from schema and data statistics independently of the query workload). revision: partial
Circularity Check
No circularity: empirical system benchmarks with direct measurements
full rationale
The paper describes a practical system for auto-discovering, validating, and integrating data dependencies into query optimizers, evaluated via direct runtime benchmarks on TPC-DS and JOB workloads. Speedups (geometric means 35% and 29%) and latency reductions are reported as measured outcomes from the implemented pipeline, not as quantities derived from equations, fitted parameters, or self-referential definitions. No load-bearing derivations, uniqueness theorems, or ansatzes appear; the central claims rest on experimental comparison to PK/FK baselines and hand-written rewrites rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Database query optimizers can exploit data dependencies beyond primary and foreign keys when they are known and valid.
Reference graph
Works this paper leans on
-
[1]
Abadi, Samuel Madden, and Nabil Hachem
Daniel J. Abadi, Samuel Madden, and Nabil Hachem. 2008. Column-stores vs. row-stores: how different are they really?. In Proceedings of the International Conference on Management of Data (SIGMOD) . 967–980
work page 2008
-
[2]
Ziawasch Abedjan, Lukasz Golab, and Felix Naumann. 2015. Profiling relational data: a survey. The VLDB Journal 24, 4 (2015), 557–581
work page 2015
-
[3]
Lee, Andrew Witkowski, Dinesh Das, Hong Su, Mohamed Zaït, and Thierry Cruanes
Rafi Ahmed, Allison W. Lee, Andrew Witkowski, Dinesh Das, Hong Su, Mohamed Zaït, and Thierry Cruanes. 2006. Cost-Based Query Transformation in Oracle. In Proceedings of the International Conference on Very Large Databases (VLDB) . 1026–1036
work page 2006
-
[4]
RJ Atwal, Peter Boncz, Ryan Boyd, Antony Courtney, Till Döhmen, Florian Ger- linghoff, Jeff Huang, Joseph Hwang, Raphael Hyde, Elena Felder, Jacob Lacouture, Yves LeMaout, Boaz Leskes, Yao Liu, Alex Monahan, Dan Perkins, Tino Tereshko, Jordan Tigani, Nick Ursa, Stephanie Wang, and Yannick Welsch. 2024. Mother- Duck: DuckDB in the cloud and in the client. ...
work page 2024
-
[5]
Maximilian Bandle, Jana Giceva, and Thomas Neumann. 2021. To Partition, or Not to Partition, That is the Join Question in a Real System. In Proceedings of the International Conference on Management of Data (SIGMOD) . 168–180
work page 2021
-
[6]
Yuanzhe Bei, Thao Pham, Akshay Aggarwal, Nga Tran, Jaimin Dave, Chuck Bear, and Michael Leuchtenburg. 2019. Vertica Flattened Tables and Live Aggregate Projections: A Column-based Alternative to Materialized Views for Analytics. In Proceedings of the International Conference on Big Data (BigData) . 1749–1758
work page 2019
-
[7]
Siegfried Bell. 1997. Dependency Mining in Relational Databases. In Proceedings of the International Joint Conference on Qualitative and Quantitative Practical Reasoning (ECSQARU-FAPR). 16–29
work page 1997
-
[8]
Siegfried Bell and Peter Brockhausen. 1995. Discovery of Data Dependencies in Relational Databases. Technical Report. University Dortmund. 6 pages
work page 1995
-
[9]
Srikanth Bellamkonda, Rafi Ahmed, Andrew Witkowski, Angela Amor, Mohamed Zaït, and Chun Chieh Lin. 2009. Enhanced Subquery Optimizations in Oracle. Proceedings of the VLDB Endowment (PVLDB) 2, 2 (2009), 1366–1377
work page 2009
-
[10]
Carsten Binnig, Stefan Hildenbrand, and Franz Färber. 2009. Dictionary-based order-preserving string compression for main memory column stores. InProceed- ings of the International Conference on Management of Data (SIGMOD) . 283–296
work page 2009
-
[11]
Johann Birnick, Thomas Bläsius, Tobias Friedrich, Felix Naumann, Thorsten Papenbrock, and Martin Schirneck. 2020. Hitting Set Enumeration with Partial Information for Unique Column Combination Discovery. Proceedings of the VLDB Endowment (PVLDB) 13, 11 (2020), 2270–2283
work page 2020
-
[12]
Boncz, Thomas Neumann, and Orri Erling
Peter A. Boncz, Thomas Neumann, and Orri Erling. 2013. TPC-H Analyzed: Hid- den Messages and Lessons Learned from an Influential Benchmark. InProceedings of the TPC Technology Conference (TPCTC) . 61–76
work page 2013
-
[13]
Casanova, Luiz Tucherman, and Antonio L
Marco A. Casanova, Luiz Tucherman, and Antonio L. Furtado. 1988. Enforcing Inclusion Dependencies and Referencial Integrity. In VLDB. 38–49
work page 1988
-
[14]
Edgar F. Codd. 1971. Further Normalization of the Data Base Relational Model . Research Report RJ909. IBM. 33 pages
work page 1971
-
[15]
C. J. Date and Hugh Darwen. 1992. Relational Database Writings 1989-1991 . Addison-Wesley, Chapter The Role of functional Dependence in Query Decom- position, 133–150
work page 1992
-
[16]
Markus Dreseler, Martin Boissier, Tilmann Rabl, and Matthias Uflacker. 2020. Quantifying TPC-H Choke Points and Their Optimizations. Proceedings of the VLDB Endowment (PVLDB) 13, 8 (2020), 1206–1220
work page 2020
-
[17]
Markus Dreseler, Jan Kossmann, Martin Boissier, Stefan Klauck, Matthias Uflacker, and Hasso Plattner. 2019. Hyrise Re-engineered: An Extensible Database System for Research in Relational In-Memory Data Management. In Proceed- ings of the International Conference on Extending Database Technology (EDBT) . 313–324
work page 2019
-
[18]
Falco Dürsch, Axel Stebner, Fabian Windheuser, Maxi Fischer, Tim Friedrich, Nils Strelow, Tobias Bleifuß, Hazar Harmouch, Lan Jiang, Thorsten Papenbrock, and Felix Naumann. 2019. Inclusion Dependency Discovery: An Experimental Evaluation of Thirteen Algorithms. In Proceedings of the International Conference on Information and Knowledge Management (CIKM) . 219–228
work page 2019
-
[19]
Ronald Fagin and Moshe Y. Vardi. 1984. The Theory of Data Dependencies - An Overview. In Proceedings of the International Colloquium on Automata, Languages and Programming (ICALP). 1–22
work page 1984
-
[20]
Wenfei Fan, Floris Geerts, and Xibei Jia. 2008. Semandaq: a data quality sys- tem based on conditional functional dependencies. Proceedings of the VLDB Endowment (PVLDB) 1, 2 (2008), 1460–1463
work page 2008
-
[21]
Franz Färber, Sang Kyun Cha, Jürgen Primsch, Christof Bornhövd, Stefan Sigg, and Wolfgang Lehner. 2011. SAP HANA database: data management for modern business applications. SIGMOD Record 40, 4 (2011), 45–51
work page 2011
-
[22]
Franz Färber, Norman May, Wolfgang Lehner, Philipp Große, Ingo Müller, Hannes Rauhe, and Jonathan Dees. 2012. The SAP HANA Database – An Architecture Overview. IEEE Data Engineering Bulletin 35, 1 (2012), 28–33
work page 2012
-
[23]
Richard A. Ganski and Harry K. T. Wong. 1987. Optimization of Nested SQL Queries Revisited. In Proceedings of the International Conference on Management of Data (SIGMOD). 23–33
work page 1987
-
[24]
Goetz Graefe, Ross Bunker, and Shaun Cooper. 1998. Hash Joins and Hash Teams in Microsoft SQL Server. In Proceedings of the International Conference on Very Large Databases (VLDB). 86–97
work page 1998
-
[25]
Haas, Johann Christoph Freytag, Guy M
Laura M. Haas, Johann Christoph Freytag, Guy M. Lohman, and Hamid Pirahesh
-
[26]
InProceedings of the International Conference on Management of Data (SIGMOD)
Extensible Query Processing in Starburst. InProceedings of the International Conference on Management of Data (SIGMOD) . 377–388
- [27]
-
[28]
Ykä Huhtala, Juha Kärkkäinen, Pasi Porkka, and Hannu Toivonen. 1999. TANE: An Efficient Algorithm for Discovering Functional and Approximate Dependen- cies. Comput. J. 42, 2 (1999), 100–111
work page 1999
-
[29]
Sjoerd Mullender, and Martin L
Stratos Idreos, Fabian Groffen, Niels Nes, Stefan Manegold, K. Sjoerd Mullender, and Martin L. Kersten. 2012. MonetDB: Two Decades of Research in Column- oriented Database Architectures. IEEE Data Engineering Bulletin 35, 1 (2012), 40–45
work page 2012
-
[30]
International Organization for Standardization. 2023. Information technology – Database languages SQL – Part 2: Foundation (SQL/Foundation) . Standard Specification ISO/IEC 9075-2:2023(E)
work page 2023
- [31]
-
[32]
Won Kim. 1982. On Optimizing an SQL-like Nested Query. ACM Transactions on Database Systems (TODS) 7, 3 (1982), 443–469
work page 1982
-
[33]
Jonathan J. King. 1980. Modelling Concepts for Reasoning About Access to Knowledge. In Proceedings of the Workshop on Data Abstraction, Databases and Conceptual Modelling. 138–140
work page 1980
-
[34]
Jan Kossmann, Daniel Lindner, Felix Naumann, and Thorsten Papenbrock. 2022. Workload-driven, Lazy Discovery of Data Dependencies for Query Optimization. In Proceedings of the Conference on Innovative Data Systems Research (CIDR) . 7 pages
work page 2022
-
[35]
Jan Kossmann, Thorsten Papenbrock, and Felix Naumann. 2022. Data dependen- cies for query optimization: a survey. The VLDB Journal 31, 1 (2022), 1–22
work page 2022
-
[36]
Hanson, Weiyun Huang, Michal Nowakiewicz, and Vassilis Papadimos
Per-Åke Larson, Adrian Birka, Eric N. Hanson, Weiyun Huang, Michal Nowakiewicz, and Vassilis Papadimos. 2015. Real-Time Analytical Process- ing with SQL Server. Proceedings of the VLDB Endowment (PVLDB) 8, 12 (2015), 1740–1751
work page 2015
-
[37]
Per-Åke Larson, Spyros Blanas, Cristian Diaconu, Craig Freedman, Jignesh M. Patel, and Mike Zwilling. 2011. High-Performance Concurrency Control Mecha- nisms for Main-Memory Databases. Proceedings of the VLDB Endowment (PVLDB) 5, 4 (2011), 298–309
work page 2011
-
[38]
Boncz, Alfons Kem- per, and Thomas Neumann
Viktor Leis, Andrey Gubichev, Atanas Mirchev, Peter A. Boncz, Alfons Kem- per, and Thomas Neumann. 2015. How Good Are Query Optimizers, Really? Proceedings of the VLDB Endowment (PVLDB) 9, 3 (2015), 204–215
work page 2015
-
[39]
Maurizio Lenzerini. 2002. Data Integration: A Theoretical Perspective. In Pro- ceedings of the Symposium on Principles of Database Systems (PODS) . 233–246
work page 2002
-
[40]
Mark Levene and George Loizou. 2003. Why is the snowflake schema a good data warehouse design? Information Systems (IS) 28, 3 (2003), 225–240
work page 2003
-
[41]
Xiaoxuan Liu, Shuxian Wang, Mengzhu Sun, Sicheng Pan, Ge Li, Siddharth Jha, Cong Yan, Junwen Yang, Shan Lu, and Alvin Cheung. 2023. Leveraging Application Data Constraints to Optimize Database-Backed Web Applications. Proceedings of the VLDB Endowment (PVLDB) 16, 6 (2023), 1208–1221
work page 2023
-
[42]
Claudio L. Lucchesi and Sylvia L. Osborn. 1978. Candidate Keys for Relations. J. Comput. System Sci. 17, 2 (1978), 270–279
work page 1978
-
[43]
Zhenghua Lyu, Huan Hubert Zhang, Gang Xiong, Gang Guo, Haozhou Wang, Jinbao Chen, Asim Praveen, Yu Yang, Xiaoming Gao, Alexandra Wang, Wen Lin, Ashwin Agrawal, Junfeng Yang, Hao Wu, Xiaoliang Li, Feng Guo, Jiang Wu, Jesse Zhang, and Venkatesh Raghavan. 2021. Greenplum: A Hybrid Database for Transactional and Analytical Workloads. In Proceedings of the Int...
work page 2021
-
[44]
Jayant Madhavan, Philip A. Bernstein, and Erhard Rahm. 2001. Generic Schema Matching with Cupid. InProceedings of the International Conference on Very Large Databases (VLDB). 49–58
work page 2001
-
[45]
Norman May, Alexander Böhm, and Wolfgang Lehner. 2017. SAP HANA - The Evolution of an In-Memory DBMS from Pure OLAP Processing Towards Mixed Workloads. In Proceedings of the Conference Datenbanksysteme in Business, Technologie und Web Technik (BTW). 545–563
work page 2017
-
[46]
Niloy Mukherjee, Shasank Chavan, Maria Colgan, Dinesh Das, Mike Gleeson, Sanket Hase, Allison Holloway, Hui Jin, Jesse Kamp, Kartik Kulkarni, Tirthankar Lahiri, Juan Loaiza, Neil MacNaughton, Vineet Marwah, Atrayee Mullick, Andy Witkowski, Jiaqi Yan, and Mohamed Zaït. 2015. Distributed Architecture of Oracle Database In-memory. Proceedings of the VLDB End...
work page 2015
-
[47]
Thomas Neumann. 2014. Engineering High-Performance Database Engines. Proceedings of the VLDB Endowment (PVLDB) 7, 13 (2014), 1734–1741
work page 2014
-
[48]
Thomas Neumann and Michael J. Freitag. 2020. Umbra: A Disk-Based System with In-Memory Performance. In Proceedings of the Conference on Innovative Data Systems Research (CIDR) . 7 pages
work page 2020
-
[49]
Anisoara Nica, Reza Sherkat, Mihnea Andrei, Xun Chen, Martin Heidel, Christian Bensberg, and Heiko Gerwens. 2017. Statisticum: Data Statistics Management in SAP HANA. Proceedings of the VLDB Endowment (PVLDB) 10, 12 (2017), Daniel Lindner, Daniel Ritter, and Felix Naumann 1658–1669
work page 2017
-
[50]
Patrick E. O’Neil, Elizabeth J. O’Neil, and Xuedong Chen. 2009. Star Schema Benchmark. Standard Specification Revision 3. https://www.cs.umb.edu/~poneil/ StarSchemaB.PDF (accessed April 9, 2024)
work page 2009
-
[51]
Patrick E. O’Neil, Elizabeth J. O’Neil, Xuedong Chen, and Stephen Revilak. 2009. The Star Schema Benchmark and Augmented Fact Table Indexing. InProceedings of the TPC Technology Conference (TPCTC) . 237–252
work page 2009
-
[52]
Oracle. [n. d.]. MySQL 8.0 Reference Manual – Optimizing IN and EXISTS Subquery Predicates with Semijoin Transformations . https://dev.mysql.com/doc/refman/8. 0/en/semijoins.html (accessed April 9, 2024)
work page 2024
-
[53]
Orr, Srikanth Kandula, and Surajit Chaudhuri
Laurel J. Orr, Srikanth Kandula, and Surajit Chaudhuri. 2019. Pushing Data- Induced Predicates Through Joins in Big-Data Clusters. Proceedings of the VLDB Endowment (PVLDB) 13, 3 (2019), 252–265
work page 2019
-
[54]
Thorsten Papenbrock, Jens Ehrlich, Jannik Marten, Tommy Neubert, Jan-Peer Rudolph, Martin Schönberg, Jakob Zwiener, and Felix Naumann. 2015. Func- tional Dependency Discovery: An Experimental Evaluation of Seven Algorithms. Proceedings of the VLDB Endowment (PVLDB) 8, 10 (2015), 1082–1093
work page 2015
-
[55]
Thorsten Papenbrock and Felix Naumann. 2017. A Hybrid Approach for Effi- cient Unique Column Combination Discovery. In Proceedings of the Conference Datenbanksysteme in Business, Technologie und Web Technik (BTW) . 195–204
work page 2017
-
[56]
Andrew Pavlo, Gustavo Angulo, Joy Arulraj, Haibin Lin, Jiexi Lin, Lin Ma, Prashanth Menon, Todd C. Mowry, Matthew Perron, Ian Quah, Siddharth San- turkar, Anthony Tomasic, Skye Toor, Dana Van Aken, Ziqi Wang, Yingjun Wu, Ran Xian, and Tieying Zhang. 2017. Self-Driving Database Management Sys- tems. In Proceedings of the Conference on Innovative Data Syste...
work page 2017
-
[57]
Eduardo H. M. Pena, Erik Falk, Jorge Augusto Meira, and Eduardo Cunha de Almeida. 2018. Mind Your Dependencies for Semantic Query Optimization. J. Inf. Data Manag. 9, 1 (2018), 3–19
work page 2018
-
[58]
Mark Raasveldt and Hannes Mühleisen. 2019. DuckDB: an Embeddable Analytical Database. In Proceedings of the International Conference on Management of Data (SIGMOD). 1981–1984
work page 2019
-
[59]
Vijayshankar Raman, Gopi K. Attaluri, Ronald Barber, Naresh Chainani, David Kalmuk, Vincent KulandaiSamy, Jens Leenstra, Sam Lightstone, Shaorong Liu, Guy M. Lohman, Tim Malkemus, René Müller, Ippokratis Pandis, Berni Schiefer, David Sharpe, Richard Sidle, Adam J. Storm, and Liping Zhang. 2013. DB2 with BLU Acceleration: So Much More than Just a Column St...
work page 2013
-
[60]
El Kindi Rezig, Mourad Ouzzani, Walid G. Aref, Ahmed K. Elmagarmid, Ahmed R. Mahmood, and Michael Stonebraker. 2021. Horizon: Scalable Dependency-driven Data Cleaning. Proceedings of the VLDB Endowment (PVLDB) 14, 11 (2021), 2546– 2554
work page 2021
-
[61]
Philipp Schirmer, Thorsten Papenbrock, Sebastian Kruse, Felix Naumann, Dennis Hempfing, Torben Mayer, and Daniel Neuschäfer-Rube. 2019. DynFD: Functional Dependency Discovery in Dynamic Datasets. In Proceedings of the International Conference on Extending Database Technology (EDBT) . 253–264
work page 2019
-
[62]
Shashi Shekhar, Babak Hamidzadeh, Ashim Kohli, and Mark Coyle. 1993. Learn- ing Transformation Rules for Semantic Query Optimization: A Data-Driven Approach. IEEE Transactions on Knowledge and Data Engineering (TKDE) 5, 6 (1993), 950–964
work page 1993
-
[63]
Siegel, Edward Sciore, and Sharon C
Michael D. Siegel, Edward Sciore, and Sharon C. Salveter. 1992. A Method for Automatic Rule Derivation to Support Semantic Query Optimization. ACM Transactions on Database Systems (TODS) 17, 4 (1992), 563–600
work page 1992
-
[64]
Soliman, Lyublena Antova, Venkatesh Raghavan, Amr El-Helw, Zhongxian Gu, Entong Shen, George C
Mohamed A. Soliman, Lyublena Antova, Venkatesh Raghavan, Amr El-Helw, Zhongxian Gu, Entong Shen, George C. Caragea, Carlos Garcia-Alvarado, Foyzur Rahman, Michalis Petropoulos, Florian Waas, Sivaramakrishnan Narayanan, Konstantinos Krikellas, and Rhonda Baldwin. 2014. Orca: a modular query optimizer architecture for big data. In Proceedings of the Interna...
work page 2014
-
[65]
Jaroslaw Szlichta, Parke Godfrey, and Jarek Gryz. 2012. Fundamentals of Order Dependencies. Proceedings of the VLDB Endowment (PVLDB) 5, 11 (2012), 1220– 1231
work page 2012
-
[66]
Jaroslaw Szlichta, Parke Godfrey, Jarek Gryz, Wenbin Ma, Przemyslaw Pawluk, and Calisto Zuzarte. 2011. Queries on dates: fast yet not blind. In Proceedings of the International Conference on Extending Database Technology (EDBT) . 497–502
work page 2011
-
[67]
Transaction Processing Performance Council. 2021.TPC Benchmark DS. Standard Specification Version 3.2.0. http://tpc.org/tpc_documents_current_versions/pdf/ tpc-ds_v3.2.0.pdf (accessed April 9, 2024)
work page 2021
-
[68]
Transaction Processing Performance Council. 2022. TPC Benchmark H. Standard Specification Revision 3.0.1. http://tpc.org/tpc_documents_current_versions/ pdf/tpc-h_v3.0.1.pdf (accessed April 9, 2024)
work page 2022
-
[69]
Jeffrey D. Ullman. 1988. Principles of Database and Knowledge-Base Systems, Volume I. Principles of computer science series, Vol. 14. Computer Science Press
work page 1988
-
[70]
J. Beau W. Webber. 2013. A bi-symmetric log transformation for wide-range data. Measurement Science and Technology 24, 2 (2013), 3 pages
work page 2013
-
[71]
Clement T. Yu and Wei Sun. 1989. Automatic Knowledge Acquisition and Main- tenance for Semantic Query Optimization. IEEE Transactions on Knowledge and Data Engineering (TKDE) 1, 3 (1989), 362–375
work page 1989
-
[72]
Xinyu Zeng, Yulong Hui, Jiahong Shen, Andrew Pavlo, Wes McKinney, and Huanchen Zhang. 2023. An Empirical Evaluation of Columnar Storage Formats. Proceedings of the VLDB Endowment (PVLDB) 17, 2 (2023), 148–161
work page 2023
-
[73]
Mohamed Ziauddin, Andrew Witkowski, You Jung Kim, Janaki Lahorani, Dmitry Potapov, and Murali Krishna. 2017. Dimensions Based Data Clustering and Zone Maps. Proceedings of the VLDB Endowment (PVLDB) 10, 12 (2017), 1622–1633
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.