Efficient collaborative learning of the average treatment effect
Pith reviewed 2026-05-23 20:00 UTC · model grok-4.3
The pith
ECO-ATE builds a federated estimator for average treatment effect that reaches the semiparametric efficiency bound while allowing shifts in outcomes, treatments, and covariates across sites.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ECO-ATE operates in a federated manner, using individual-level data from a user-defined target population and summary statistics from other source populations, to construct an efficient estimator for the average treatment effect on the target population of interest. The method achieves the semiparametric efficiency bound under appropriate conditions while allowing distributional shifts in outcomes, treatments, and baseline covariates distributions, without requiring iterative communications between sites.
What carries the argument
The ECO-ATE estimator, which fuses target-site individual records with source-site summary statistics to correct for distributional shifts and attain semiparametric efficiency without iterative site-to-site communication.
If this is right
- Incorporating source summaries yields measurable efficiency gains over target-only estimation.
- The estimator remains consistent and efficient under a range of distributional shifts and degrees of overparameterization.
- The single-pass, non-iterative design fits consortia that lack infrastructure for repeated data exchange.
- The same framework supports real-world evidence studies using electronic health record data from programs such as All of Us.
Where Pith is reading between the lines
- The same summary-statistic correction strategy could be tested on other causal parameters such as conditional average treatment effects if analogous identifying summaries exist.
- Adoption would lower the barrier to multi-site analyses by removing the need for centralized individual-level repositories.
- Sequential addition of new source sites could be examined by updating the summary-based correction term without retraining on prior data.
- Variance reduction relative to target-only estimators can be quantified directly in any simulation that supplies both full target data and partial source summaries.
Load-bearing premise
The summary statistics received from source populations are sufficient to identify and correct for the relevant distributional shifts between sites.
What would settle it
Empirical demonstration that the estimator loses consistency or efficiency when the supplied summaries omit information needed to characterize the outcome, treatment, or covariate shifts between the target and source populations.
Figures


read the original abstract
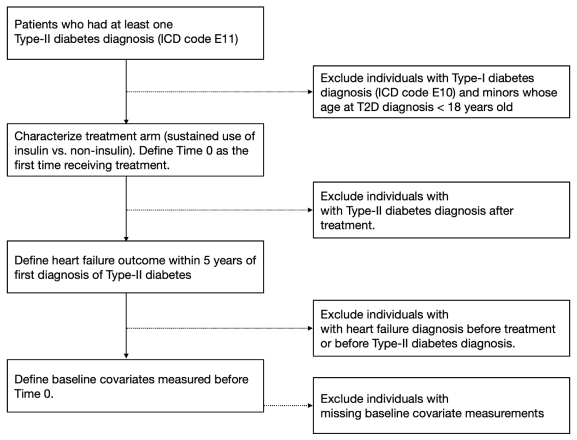
In response to the growing need for generating real-world evidence from multi-site collaborative studies, we introduce an efficient collaborative learning approach to evaluate average treatment effect (ECO-ATE) in a multi-site setting under data sharing constraints. Specifically, ECO-ATE operates in a federated manner, using individual-level data from a user-defined target population and summary statistics from other source populations, to construct efficient estimator for the average treatment effect on the target population of interest. Our federated approach does not require iterative communications between sites, making it particularly suitable for research consortia with limited resources for developing automated data-sharing infrastructures. Compared to existing work data integration methods in causal inference, ECO-ATE allows distributional shifts in outcomes, treatments and baseline covariates distributions, and achieves semiparametric efficiency bound under appropriate conditions. We conduct simulation studies to demonstrate the extent of efficiency gains achieved by incorporating additional data sources, as well as the robustness of our approach against varying levels of distributional shifts and overparameterization, compared to existing benchmarks. We apply ECO-ATE to a case study examining the effect of insulin vs. non-insulin treatments on heart failure for patients with type II diabetes using electronic health record data collected from the All of Us program.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ECO-ATE, a non-iterative federated estimator for the average treatment effect (ATE) on a target population that uses individual-level data from the target site together with summary statistics received from source sites. It claims to accommodate arbitrary distributional shifts in the outcome, treatment, and covariate distributions while attaining the semiparametric efficiency bound under appropriate conditions, with supporting evidence from simulations and an All of Us EHR application on insulin versus non-insulin treatment effects for heart failure.
Significance. If the efficiency bound is attained with only summary statistics under the stated shifts, the method would constitute a practical advance for multi-site causal inference under data-sharing and privacy constraints, offering efficiency gains without requiring iterative communication or full data pooling.
major comments (2)
- [Abstract and §3] Abstract and §3 (method construction): the central claim that finite summary statistics suffice to identify and debias nonparametric shifts in Y, T, and X simultaneously, while still attaining the semiparametric efficiency bound, is load-bearing. Low-dimensional summaries (means, variances, or low-order moments) cannot in general recover the full adjustment functionals needed for arbitrary shifts; the manuscript must explicitly state the summaries employed and provide the identification argument showing they are sufficient for the efficiency result.
- [§4] §4 (simulation design): the reported efficiency gains and robustness to distributional shifts and overparameterization are presented without direct numerical comparison to the semiparametric efficiency bound (e.g., variance ratios or asymptotic relative efficiency with standard errors). Without these quantities it is not possible to verify that the bound is achieved rather than merely improved relative to benchmarks.
minor comments (2)
- [Abstract] The phrase 'under appropriate conditions' in the abstract should be accompanied by a one-sentence pointer to the precise regularity conditions or theorem number in the main text.
- Notation for the target-population ATE and the shift parameters should be introduced once and used consistently; several places appear to reuse symbols for both population quantities and their estimators.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and agree to revisions that clarify the method and strengthen the simulation evidence.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method construction): the central claim that finite summary statistics suffice to identify and debias nonparametric shifts in Y, T, and X simultaneously, while still attaining the semiparametric efficiency bound, is load-bearing. Low-dimensional summaries (means, variances, or low-order moments) cannot in general recover the full adjustment functionals needed for arbitrary shifts; the manuscript must explicitly state the summaries employed and provide the identification argument showing they are sufficient for the efficiency result.
Authors: We appreciate this observation on the load-bearing claim. The ECO-ATE construction in §3 employs specific finite-dimensional summary statistics from source sites, namely the empirical means of the site-specific components of the efficient influence function (including conditional outcome regressions and propensity scores evaluated at target-site covariates). These are sufficient under the paper's semiparametric model for the allowed shifts because the identification of the target ATE relies only on these moments for debiasing, not on recovering the full nonparametric distributions. We will revise the abstract and §3 to state the summaries explicitly and expand the identification argument with the relevant lemmas showing sufficiency for attaining the efficiency bound. revision: yes
-
Referee: [§4] §4 (simulation design): the reported efficiency gains and robustness to distributional shifts and overparameterization are presented without direct numerical comparison to the semiparametric efficiency bound (e.g., variance ratios or asymptotic relative efficiency with standard errors). Without these quantities it is not possible to verify that the bound is achieved rather than merely improved relative to benchmarks.
Authors: We agree that explicit numerical comparison to the semiparametric efficiency bound would allow readers to verify attainment rather than relative improvement. In the revised §4 we will add tables reporting the ratio of empirical variance of ECO-ATE to the estimated efficiency bound (with Monte Carlo standard errors) across all simulation settings, as well as asymptotic relative efficiency where closed-form bounds are available. revision: yes
Circularity Check
No circularity: estimator construction relies on external target data and stated assumptions
full rationale
The paper introduces ECO-ATE as a federated estimator using individual-level target data plus source summary statistics to target the ATE under distributional shifts. No equations, fitting steps, or self-citations are shown that reduce the claimed efficiency bound or the estimator itself to a quantity defined by its own fitted parameters. The semiparametric efficiency claim is conditioned on the summaries being sufficient for shift correction—an external modeling assumption, not a self-referential definition or fitted-input prediction. The derivation chain is therefore self-contained against the stated inputs and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard causal assumptions (consistency, no unmeasured confounding, positivity) required for ATE identification in observational data
Reference graph
Works this paper leans on
-
[1]
Alkhezi, O. S., Alsuhaibani, H. A., Alhadyab, A. A., Alfaifi, M. E., Alomrani, B., Aldossary, A., and Alfayez, O. M. (2021). Heart failure outcomes and glucagon-like peptide-1 receptor agonists: A systematic review of observational studies. Primary Care Diabetes , 15(5):761--771
work page 2021
-
[2]
Athey, S., Chetty, R., Imbens, G. W., and Kang, H. (2019). The surrogate index: Combining short-term proxies to estimate long-term treatment effects more rapidly and precisely. Technical report, National Bureau of Economic Research
work page 2019
-
[3]
Bareinboim, E. and Pearl, J. (2014). Transportability from multiple environments with limited experiments: Completeness results. Advances in neural information processing systems , 27:280--288
work page 2014
-
[4]
Bickel, P. J., Klaassen, C. A., Bickel, P. J., Ritov, Y., Klaassen, J., Wellner, J. A., and Ritov, Y. (1993). Efficient and adaptive estimation for semiparametric models , volume 4. Springer
work page 1993
-
[5]
Brantner, C. L., Chang, T.-H., Nguyen, T. Q., Hong, H., Di Stefano, L., and Stuart, E. A. (2023). Methods for integrating trials and non-experimental data to examine treatment effect heterogeneity. arXiv preprint arXiv:2302.13428
- [6]
-
[7]
Chernozhukov, V., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., Newey, W., and Robins, J. (2018). Double/debiased machine learning for treatment and structural parameters
work page 2018
-
[8]
Dahabreh, I. J. and Hern \'a n, M. A. (2019). Extending inferences from a randomized trial to a target population. Eur. J. Epidemiol. , 34(8):719--722
work page 2019
-
[9]
Dahabreh, I. J., Petito, L. C., Robertson, S. E., Hern \'a n, M. A., and Steingrimsson, J. A. (2019). Towards causally interpretable meta-analysis: transporting inferences from multiple studies to a target population. arXiv preprint arXiv:1903.11455
-
[10]
Donoho, D. L., Johnstone, I. M., Kerkyacharian, G., and Picard, D. (1996). Density estimation by wavelet thresholding. The Annals of statistics , pages 508--539
work page 1996
-
[11]
Echouffo-Tcheugui, J. B., Xu, H., DeVore, A. D., Schulte, P. J., Butler, J., Yancy, C. W., Bhatt, D. L., Hernandez, A. F., Heidenreich, P. A., and Fonarow, G. C. (2016). Temporal trends and factors associated with diabetes mellitus among patients hospitalized with heart failure: Findings from get with the guidelines--heart failure registry. American heart...
work page 2016
-
[12]
Efron, B. (1978). The geometry of exponential families. The Annals of Statistics , pages 362--376
work page 1978
-
[13]
Gilbert, P. B. (2004). Goodness-of-fit tests for semiparametric biased sampling models. Journal of statistical planning and inference , 118(1-2):51--81
work page 2004
-
[14]
Gilbert, P. B., Bosch, R. J., and Hudgens, M. G. (2003). Sensitivity analysis for the assessment of causal vaccine effects on viral load in hiv vaccine trials. Biometrics , 59(3):531--541
work page 2003
-
[15]
Grenander, U. (1981). Abstract inference. (No Title)
work page 1981
-
[16]
L., Ding, P., Wang, Y., and Jordan, M
Guo, W., Wang, S. L., Ding, P., Wang, Y., and Jordan, M. (2022). Multi-source causal inference using control variates under outcome selection bias. Transactions on Machine Learning Research
work page 2022
- [17]
-
[18]
Haendel, M. A., Chute, C. G., Bennett, T. D., Eichmann, D. A., Guinney, J., Kibbe, W. A., Payne, P. R., Pfaff, E. R., Robinson, P. N., Saltz, J. H., et al. (2021). The national covid cohort collaborative (n3c): rationale, design, infrastructure, and deployment. Journal of the American Medical Informatics Association , 28(3):427--443
work page 2021
- [19]
-
[20]
Hastie, T. J. (2017). Generalized additive models. In Statistical models in S , pages 249--307. Routledge
work page 2017
-
[21]
Hayfield, T. and Racine, J. S. (2008). Nonparametric econometrics: The np package. Journal of statistical software , 27:1--32
work page 2008
-
[22]
Herman, M. E., O'Keefe, J. H., Bell, D. S., and Schwartz, S. S. (2017). Insulin therapy increases cardiovascular risk in type 2 diabetes. Progress in cardiovascular diseases , 60(3):422--434
work page 2017
-
[23]
Hippisley-Cox, J. and Coupland, C. (2016). Diabetes treatments and risk of heart failure, cardiovascular disease, and all cause mortality: cohort study in primary care. bmj , 354
work page 2016
-
[24]
Hripcsak, G., Duke, J. D., Shah, N. H., Reich, C. G., Huser, V., Schuemie, M. J., Suchard, M. A., Park, R. W., Wong, I. C. K., Rijnbeek, P. R., et al. (2015). Observational health data sciences and informatics (ohdsi): opportunities for observational researchers. In MEDINFO 2015: eHealth-enabled Health , pages 574--578. IOS Press
work page 2015
-
[25]
Jemiai, Y., Rotnitzky, A., Shepherd, B. E., and Gilbert, P. B. (2007). Semiparametric estimation of treatment effects given base-line covariates on an outcome measured after a post-randomization event occurs. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 69(5):879--901
work page 2007
-
[26]
Jordan, M. I., Lee, J. D., and Yang, Y. (2018). Communication-efficient distributed statistical inference. Journal of the American Statistical Association
work page 2018
- [27]
-
[28]
Kannel, W. B. and McGee, D. L. (1979). Diabetes and cardiovascular disease: the framingham study. Jama , 241(19):2035--2038
work page 1979
-
[29]
Kenny, H. C. and Abel, E. D. (2019). Heart failure in type 2 diabetes mellitus: impact of glucose-lowering agents, heart failure therapies, and novel therapeutic strategies. Circulation research , 124(1):121--141
work page 2019
-
[30]
Lee, D., Yang, S., Dong, L., Wang, X., Zeng, D., and Cai, J. (2023). Improving trial generalizability using observational studies. Biometrics , 79(2):1213--1225
work page 2023
-
[31]
Lehrke, M. and Marx, N. (2017). Diabetes mellitus and heart failure. The American journal of cardiology , 120(1):S37--S47
work page 2017
-
[32]
Li, S., Cai, T., and Duan, R. (2023a). Targeting underrepresented populations in precision medicine: A federated transfer learning approach. The Annals of Applied Statistics , 17(4):2970--2992
-
[33]
Li, S., Cai, T. T., and Li, H. (2022). Transfer learning for high-dimensional linear regression: Prediction, estimation and minimax optimality. Journal of the Royal Statistical Society Series B: Statistical Methodology , 84(1):149--173
work page 2022
-
[34]
Li, S., Gilbert, P. B., and Luedtke, A. (2023b). Data fusion using weakly aligned sources. arXiv preprint arXiv:2308.14836
-
[35]
Li, S. and Luedtke, A. (2023). Efficient estimation under data fusion. Biometrika , 110(4):1041--1054
work page 2023
-
[36]
Liu, Q., Xu, J., Jiang, R., and Wong, W. H. (2021). Density estimation using deep generative neural networks. Proceedings of the National Academy of Sciences , 118(15):e2101344118
work page 2021
-
[37]
Nadaraya, E. A. (1964). On estimating regression. Theory of Probability & Its Applications , 9(1):141--142
work page 1964
-
[38]
K., Klein, K., Maggs, D., and Best, J
Paul, S. K., Klein, K., Maggs, D., and Best, J. H. (2015). The association of the treatment with glucagon-like peptide-1 receptor agonist exenatide or insulin with cardiovascular outcomes in patients with type 2 diabetes: a retrospective observational study. Cardiovascular Diabetology , 14:1--9
work page 2015
-
[39]
Polley, E. C. and Van Der Laan, M. J. (2010). Super learner in prediction
work page 2010
-
[40]
Rosenbaum, P. R. and Rubin, D. B. (1983). The central role of the propensity score in observational studies for causal effects. Biometrika , 70(1):41--55
work page 1983
-
[41]
Rubin, D. B. (1980). Randomization analysis of experimental data: The fisher randomization test comment. Journal of the American statistical association , 75(371):591--593
work page 1980
-
[42]
Rudolph, K. E. and van der Laan, M. J. (2017). Robust estimation of encouragement-design intervention effects transported across sites. J. R. Stat. Soc. , 79(5):1509
work page 2017
-
[43]
Stuart, E. A., Bradshaw, C. P., and Leaf, P. J. (2015). Assessing the generalizability of randomized trial results to target populations. Prevention Science , 16(3):475--485
work page 2015
-
[44]
Van der Vaart, A. W. (2000). Asymptotic statistics , volume 3. Cambridge university press
work page 2000
-
[45]
Vo, T. V., Lee, Y., Hoang, T. N., and Leong, T.-Y. (2022). Bayesian federated estimation of causal effects from observational data. In Uncertainty in Artificial Intelligence , pages 2024--2034. PMLR
work page 2022
-
[46]
Wang, X., Plantinga, A., Xiong, X., Cromer, S., Bonzel, C.-L., Ayakulangara Panickan, V., Duan, R., Hou, J., and Cai, T. (2024). Comparing insulin vs glp-1, dpp-4, sglt-2 on 5-year incident heart failure for patients with type 2 diabetes mellitus: a real-world evidence study using insurance claims (preprint)
work page 2024
-
[47]
Weiss, K., Khoshgoftaar, T. M., and Wang, D. (2016). A survey of transfer learning. Journal of Big data , 3:1--40
work page 2016
-
[48]
Xiong, R., Koenecke, A., Powell, M., Shen, Z., Vogelstein, J. T., and Athey, S. (2023). Federated causal inference in heterogeneous observational data. Statistics in Medicine , 42(24):4418--4439
work page 2023
-
[49]
Yang, S., Gao, C., Zeng, D., and Wang, X. (2023). Elastic integrative analysis of randomised trial and real-world data for treatment heterogeneity estimation. Journal of the Royal Statistical Society Series B: Statistical Methodology , 85(3):575--596
work page 2023
- [50]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.