Scalable Gaussian Process Regression Via Median Posterior Inference for Estimating Multi-Pollutant Mixture Health Effects
Pith reviewed 2026-05-23 17:09 UTC · model grok-4.3
The pith
A divide-and-conquer strategy using the generalized median of subset posteriors scales Gaussian process regression to datasets with hundreds of thousands of observations while preserving convergence to the full posterior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
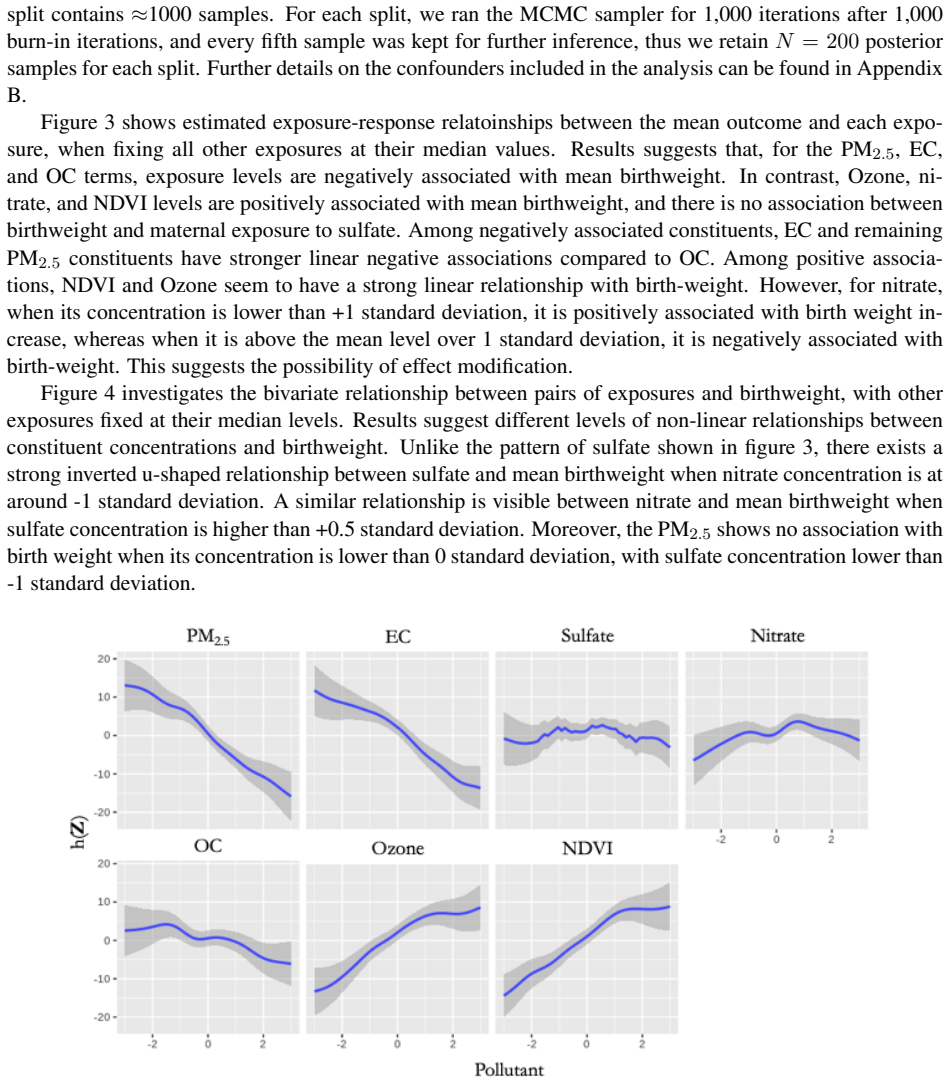
The authors propose partitioning large datasets, computing subset posteriors in parallel for a Gaussian process regression model with feature selection, and aggregating them via the generalized median; they prove that the resulting posterior converges to the full-sample posterior under the high-dimensional exposure conditions typical of environmental mixtures analyses.
What carries the argument
The generalized median of subset posteriors, which aggregates independent posterior distributions computed on data partitions to approximate the full-data posterior for Gaussian process models.
If this is right
- The method permits fitting of the original Coull et al. Gaussian process framework to cohorts of size 650,000 or larger.
- It yields the same qualitative pollutant associations (negative for elemental and organic carbon and PM2.5, positive for ozone and greenness) as a full-sample analysis would.
- The distributed strategy applies to any Bayesian model whose full-sample MCMC is prohibitive.
- Feature selection within the Gaussian process remains feasible after partitioning.
Where Pith is reading between the lines
- The same median aggregation could be tested for convergence speed on synthetic data generated from known Gaussian process functions before real-data application.
- If subset size is chosen adaptively, the method might allow incremental updating when new observations arrive without recomputing all previous subsets.
- The approach may extend to other semi-parametric mixture models that currently rely on full-data MCMC.
Load-bearing premise
The generalized median of subset posteriors converges to the full posterior for the Gaussian process model with feature selection under high-dimensional exposure conditions.
What would settle it
A simulation study in which the full-data posterior is known exactly; if the median-of-subsets posterior deviates by more than a small, pre-specified distance as the number of partitions grows, the convergence claim fails.
Figures



read the original abstract
Humans are exposed to complex mixtures of environmental pollutants rather than single chemicals, necessitating methods to quantify the health effects of such mixtures. Research on environmental mixtures provides insights into realistic exposure scenarios, informing regulatory policies that better protect public health. However, statistical challenges, including complex correlations among pollutants and nonlinear multivariate exposure-response relationships, complicate such analyses. A popular Bayesian semi-parametric Gaussian process regression framework (Coull et al., 2015) addresses these challenges by modeling exposure-response functions with Gaussian processes and performing feature selection to manage high-dimensional exposures while accounting for confounders. Originally designed for small to moderate-sized cohort studies, this framework does not scale well to massive datasets. To address this, we propose a divide-and-conquer strategy, partitioning data, computing posterior distributions in parallel, and combining results using the generalized median. While we focus on Gaussian process models for environmental mixtures, the proposed distributed computing strategy is broadly applicable to other Bayesian models with computationally prohibitive full-sample Markov Chain Monte Carlo fitting. We provide theoretical guarantees for the convergence of the proposed posterior distributions to those derived from the full sample. We apply this method to estimate associations between a mixture of ambient air pollutants and ~650,000 birthweights recorded in Massachusetts during 2001-2012. Our results reveal negative associations between birthweight and traffic pollution markers, including elemental and organic carbon and PM2.5, and positive associations with ozone and vegetation greenness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a divide-and-conquer strategy for scalable Bayesian semi-parametric Gaussian process regression (following Coull et al. 2015) to estimate health effects of high-dimensional pollutant mixtures. Large datasets are partitioned, subset posteriors are computed in parallel via MCMC, and results are combined using the generalized median; theoretical convergence guarantees to the full-sample posterior are claimed, with an application to ~650k Massachusetts birthweight records and air pollution exposures.
Significance. If the convergence guarantees hold for the target GP model with feature selection, the method would enable routine Bayesian mixture analysis on massive environmental health datasets that currently exceed the reach of full-sample MCMC, directly addressing a key scalability barrier in the field.
major comments (2)
- [Theoretical guarantees] Theoretical guarantees section: the claim that the generalized median of subset posteriors converges to the full posterior requires explicit verification that the Coull et al. (2015) model satisfies the necessary posterior concentration rates and moment conditions; feature selection in high-dimensional exposure space can induce multimodality, and the manuscript does not appear to check whether subset sizes remain large enough relative to the number of pollutants to inherit these conditions.
- [Application results] Application and results: the reported associations with traffic pollutants on the 650k-record dataset are presented without error bars on the combined posterior, without validation against full-sample inference on a held-out subset, and without sensitivity checks on partition number or subset size, leaving the practical accuracy of the median combination unquantified.
minor comments (2)
- [Abstract] Abstract: the statement of theoretical guarantees could specify the model class and conditions under which convergence is proved.
- [Methods] Notation: the definition and properties of the generalized median should be stated explicitly (or referenced) when first introduced to aid readers unfamiliar with the combination step.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and outline planned revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Theoretical guarantees] Theoretical guarantees section: the claim that the generalized median of subset posteriors converges to the full posterior requires explicit verification that the Coull et al. (2015) model satisfies the necessary posterior concentration rates and moment conditions; feature selection in high-dimensional exposure space can induce multimodality, and the manuscript does not appear to check whether subset sizes remain large enough relative to the number of pollutants to inherit these conditions.
Authors: We agree that an explicit verification of the posterior concentration rates and moment conditions for the Coull et al. (2015) model would strengthen the theoretical section. Our guarantees rely on general results for median posterior inference, which the manuscript invokes for the target model. However, we did not include a dedicated check for multimodality induced by feature selection or confirm subset-size requirements relative to pollutant dimension. We will revise the theoretical guarantees section (and add an appendix if needed) to provide this explicit verification and discussion of the relevant conditions. revision: yes
-
Referee: [Application results] Application and results: the reported associations with traffic pollutants on the 650k-record dataset are presented without error bars on the combined posterior, without validation against full-sample inference on a held-out subset, and without sensitivity checks on partition number or subset size, leaving the practical accuracy of the median combination unquantified.
Authors: We acknowledge that the current application lacks reported credible intervals from the combined posterior, validation against full-sample results (infeasible at full scale), and sensitivity analyses on partition number or subset size. We will add credible intervals to the reported associations, include sensitivity checks on the number of partitions and subset sizes (using the full dataset where possible), and provide validation results on smaller held-out subsets or simulated data where full MCMC is tractable. These additions will be incorporated in the revised manuscript to better quantify the method's practical accuracy. revision: yes
Circularity Check
No significant circularity; derivation is self-contained with independent theoretical claims
full rationale
The paper introduces a divide-and-conquer strategy that partitions data, computes subset posteriors in parallel for a Gaussian process model, and combines them via generalized median, claiming new theoretical guarantees that these combined posteriors converge to the full-sample posterior. No quoted equations or steps reduce the convergence result to a fitted parameter, self-definition, or load-bearing self-citation chain by construction. The base model is cited from Coull et al. (2015), but the scalability method and its guarantees are presented as novel contributions with independent support. This aligns with the absence of any reduction of predictions to inputs, yielding a normal non-finding of circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gaussian process priors appropriately model the nonlinear exposure-response relationships and feature selection handles high-dimensional exposures.
- ad hoc to paper The generalized median of subset posteriors converges to the full posterior under the model's conditions.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION format.url url empty "" url if FUNCTION article output.bibitem format.authors "author" output.check author format.key output output.year.check new.block format.title "title" output.check new.block crossref missing format.jour.vol output format.article.crossref output.nonnull format.pages output if ne...
-
[2]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type url volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence := ...
-
[3]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[4]
Billionnet, C. , Sherrill, D. and Annesi-Maesano, I. (2012). Estimating the health effects of exposure to multi-pollutant mixture. Annals of epidemiology 22 126--141
work page 2012
-
[5]
Bobb, J. F. , Valeri, L. , Claus Henn, B. , Christiani, D. C. , Wright, R. O. , Mazumdar, M. , Godleski, J. J. and Coull, B. A. (2015). Bayesian kernel machine regression for estimating the health effects of multi-pollutant mixtures. Biostatistics 16 493--508
work page 2015
-
[6]
Carlier, G. , Oberman, A. and Oudet, E. (2015). Numerical methods for matching for teams and wasserstein barycenters. ESAIM: Mathematical Modelling and Numerical Analysis 49 1621--1642
work page 2015
-
[7]
Coull, B. A. , Bobb, J. F. , Wellenius, G. A. , Kioumourtzoglou, M.-A. , Mittleman, M. A. , Koutrakis, P. and Godleski, J. J. (2015). Part 1. statistical learning methods for the effects of multiple air pollution constituents. Research report - Health Effects Institute 5
work page 2015
-
[8]
Cuturi, M. and Doucet, A. (2014). Fast computation of wasserstein barycenters. Proceedings of the 31st International Conference on Machine Learning 32 685--693
work page 2014
-
[9]
Di, Q. , Koutrakis, P. and Schwartz, J. (2016). A hybrid prediction model for pm _ 2.5 mass and components using a chemical transport model and land use regression. Atmospheric environment 131 390--399
work page 2016
-
[10]
Fong, K. C. , Di, Q. , Kloog, I. , Laden, F. , Coull, B. A. , Koutrakis, P. and Schwartz, J. D. (2019 a ). Relative toxicities of major particulate matter constituents on birthweight in massachusetts. Environmental epidemiology 3 e047
work page 2019
-
[11]
Fong, K. C. , Kosheleva, A. , Kloog, I. , Koutrakis, P. , Laden, F. , Coull, B. A. and Schwartz, J. D. (2019 b ). Fine particulate air pollution and birthweight: Differences in associations along the birthweight distribution. Epidemiology (Cambridge, Mass.) 30 617--623
work page 2019
-
[12]
Gaskins, A. J. , Mínguez-Alarcón, L. , Fong, K. C. , Abu Awad, Y. , Di, Q. , Chavarro, J. E. , Ford, J. B. , Coull, B. A. , Schwartz, J. , Kloog, I. , Attaman, J. , Hauser, R. and Laden, F. (2019). Supplemental folate and the relationship between traffic-related air pollution and livebirth among women undergoing assisted reproduction. American journal of ...
work page 2019
-
[13]
Hoffmann, T. and Onnela, J.-P. (2023). Scalable gaussian process inference with stan. arXiv preprint arXiv:2301.08836
- [14]
- [15]
-
[16]
Minsker, S. (2015). Geometric median and robust estimation in banach spaces. Bernoulli : official journal of the Bernoulli Society for Mathematical Statistics and Probability 21 2308--2335
work page 2015
-
[17]
Minsker, S. , Srivastava, S. , Lin, L. and Dunson, D. (2017). Robust and scalable bayes via a median of subset posterior measures. Journal Of Machine Learning Research 18
work page 2017
-
[18]
Schmidhuber, J. (2015). Deep learning in neural networks: An overview. Neural networks 61 85--117
work page 2015
- [19]
-
[20]
Srivastava, S. , Cevher, V. , Tran Dinh, Q. and Dunson, D. B. (2015). Wasp: Scalable bayes via barycenters of subset posteriors. Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics 38 912 -- 920
work page 2015
-
[21]
Srivastava, S. , Li, C. and Dunson, D. B. (2018). Scalable bayes via barycenter in wasserstein space. J. Mach. Learn. Res. 19 312–346
work page 2018
-
[22]
Stieb, D. M. , Chen, L. , Eshoul, M. and Judek, S. (2012). Ambient air pollution, birth weight and preterm birth: A systematic review and meta-analysis. Environmental research 117 100--111
work page 2012
-
[23]
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. Series B, Methodological 58 267--288
work page 1996
-
[24]
Rates of contraction of posterior distributions based on gaussian process priors
Vaart, A., van der and Zanten, J., van (2008). Rates of contraction of posterior distributions based on gaussian process priors. Annals of Statistics
work page 2008
-
[25]
Vaart, A. W. (1996). Weak Convergence and Empirical Processes : With Applications to Statistics. Springer Series in Statistics, Springer New York : Imprint: Springer, New York, NY
work page 1996
-
[26]
van der Vaart, A. W. and van Zanten, J. H. (2009). Adaptive bayesian estimation using a gaussian random field with inverse gamma bandwidth. The Annals of Statistics 37 2655–2675
work page 2009
-
[27]
Williams, C. K. I. and Rasmussen, C. E. (2019). Gaussian Processes for Machine Learning. Adaptive Computation and Machine Learning series, The MIT Press
work page 2019
-
[28]
Zhu, Y. , Peruzzi, M. , Li, C. and Dunson, D. B. (2024). Radial neighbours for provably accurate scalable approximations of gaussian processes. Biometrika asae029
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.