ActPlane: Programmable OS-Level Policy Enforcement for Agent Harnesses
Pith reviewed 2026-06-25 21:12 UTC · model grok-4.3
The pith
ActPlane lets AI agents declare policies in a simple DSL that the OS kernel enforces on all execution paths with semantic feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
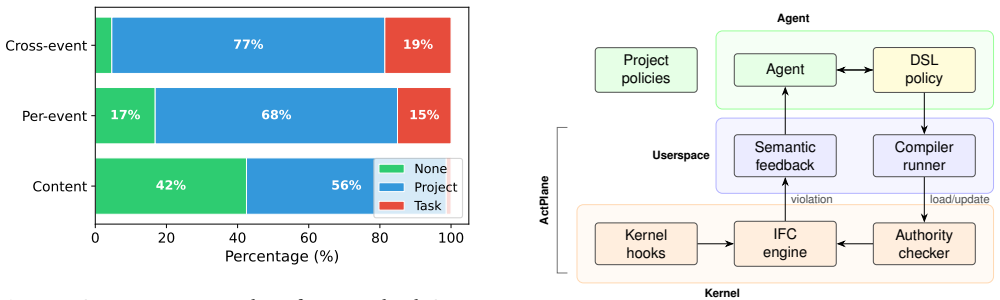
ActPlane is a policy engine that accepts agent-declared policies written in a simple information-flow control DSL and enforces them inside the OS kernel, supplying semantic feedback and maintaining isolation so that cross-event constraints are respected on every execution path, including those invisible to tool-call interception.
What carries the argument
ActPlane policy engine, which uses an information-flow control DSL to express cross-event policies and eBPF for kernel-level observation and control.
If this is right
- Tool-call guardrails alone become insufficient once indirect paths exist.
- Agents can receive actionable semantic feedback rather than opaque sandbox denials.
- Cross-event constraints such as ordering and data-flow rules can be checked at the kernel.
- Policy compliance improves on benchmarks that include indirect execution.
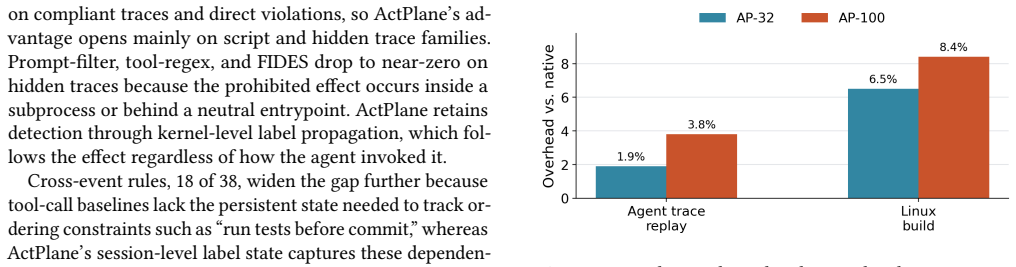
- Overhead remains between 1.9 and 8.4 percent under the evaluated workloads.
Where Pith is reading between the lines
- If the DSL proves limited in expressiveness, future work could extend it while retaining the kernel enforcement layer.
- The same architecture could apply to non-AI processes that need high-level policy intent mapped to low-level actions.
- Isolation guarantees might allow multiple agents to share a kernel without policy leakage if the DSL correctly tracks flows.
Load-bearing premise
A simple information-flow control DSL is expressive enough for the policies agents actually need and that kernel instrumentation can observe every relevant action without breaking compatibility.
What would settle it
A documented agent policy from the empirical study that cannot be written in the DSL or an execution trace where an indirect path violates the policy yet eBPF reports no violation.
Figures







read the original abstract
AI agents increasingly run in production through harnesses, the software around the LLM, including an engine that enforces safety and effectiveness policies, e.g., 'run tests before committing.' Enforcing these policies requires bridging a semantic gap: policy intent is expressed in underspecified natural language, while enforcement must act on concrete system actions, e.g., which test to run. Many policies also define event ordering or data flow actions. Yet existing approaches fall short. Tool-call guardrails miss system actions that bypass the tool layer, while OS sandboxes control resource access instead of actions, returning opaque errors that confuse the agent. Our key insight is that policy context lives within the agent closest to the task, while enforcement must happen at the OS to cover all execution paths. We introduce ActPlane, a policy engine that lets agents declare policies and enforces them in the OS kernel with semantic feedback and isolation. ActPlane uses a simple information-flow control (IFC) DSL to support cross-event policies. We implement ActPlane with eBPF and evaluate it on policies from the empirical study, coding-task benchmarks, and safety benchmarks. ActPlane improves policy compliance, including on indirect execution paths that tool-call interception cannot observe, with 1.9%-8.4% overhead. ActPlane is at https://github.com/eunomia-bpf/ActPlane
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ActPlane, a policy engine that lets agents declare policies via a simple information-flow control (IFC) DSL and enforces them in the OS kernel using eBPF, providing semantic feedback and isolation. It claims to improve policy compliance (including on indirect execution paths missed by tool-call interception) on policies drawn from an empirical study, coding-task benchmarks, and safety benchmarks, at 1.9%-8.4% overhead.
Significance. If the implementation and evaluation details support the claims, the work would provide a practical bridge between high-level agent policy intent and comprehensive OS-level enforcement, addressing gaps in both tool-call guardrails and traditional sandboxes while supplying actionable feedback to agents.
major comments (2)
- [Abstract and §3] Abstract and §3 (DSL design): the central claim that the simple IFC DSL can express the cross-event ordering and data-flow policies needed for the cited empirical study and benchmarks is load-bearing, yet the manuscript supplies neither the DSL grammar nor concrete policy encodings that would allow verification of expressiveness.
- [§4] §4 (eBPF implementation): the assertion that eBPF attachment points observe every relevant syscall, exec, and file operation without gaps or bypasses is load-bearing for the indirect-path improvement claim, but the text provides no enumeration of hooked events, no compatibility matrix across kernel versions, and no negative results for missed actions.
minor comments (1)
- [Evaluation] Evaluation section: the abstract states compliance gains but the provided text lacks methods, data tables, exclusion criteria, or error analysis, making it impossible to assess whether the reported numbers support the headline claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The two major comments identify important gaps in the presentation of the DSL and eBPF implementation. We will revise the manuscript to supply the requested details while preserving the core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (DSL design): the central claim that the simple IFC DSL can express the cross-event ordering and data-flow policies needed for the cited empirical study and benchmarks is load-bearing, yet the manuscript supplies neither the DSL grammar nor concrete policy encodings that would allow verification of expressiveness.
Authors: We agree that the absence of an explicit grammar and concrete encodings makes it difficult to verify expressiveness. In the revised version we will add the complete DSL grammar (including productions for event ordering and data-flow constraints) to §3 and include an appendix with policy encodings for the representative policies drawn from the empirical study, coding-task benchmarks, and safety benchmarks. These additions will directly substantiate the claim that the DSL is sufficient for the evaluated policies. revision: yes
-
Referee: [§4] §4 (eBPF implementation): the assertion that eBPF attachment points observe every relevant syscall, exec, and file operation without gaps or bypasses is load-bearing for the indirect-path improvement claim, but the text provides no enumeration of hooked events, no compatibility matrix across kernel versions, and no negative results for missed actions.
Authors: We accept that a systematic enumeration of attachment points and compatibility information is required to support the indirect-path coverage claim. The revised §4 will contain (1) a complete table of hooked syscalls and events, (2) a compatibility matrix covering Linux kernel versions 5.10–6.8, and (3) any observed limitations or negative results regarding actions that could bypass the hooks. This material will clarify the scope of enforcement and any remaining gaps. revision: yes
Circularity Check
No circularity; claims rest on implementation and benchmarks
full rationale
The paper presents a systems artifact (ActPlane) implemented with eBPF, a simple IFC DSL for policies, and reports compliance/overhead numbers from evaluation on empirical-study policies, coding benchmarks, and safety benchmarks. No equations, first-principles derivations, fitted parameters, or predictions appear in the provided text. No self-citation chains are invoked to justify uniqueness or load-bearing premises. The central claims are empirical outcomes of the described implementation rather than quantities that reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2025. Claude Code.https://code.claude.com/docs
2025
-
[2]
Anthropic. 2026. Claude Code Hooks.https://code.claude.com/docs/ en/hooks
2026
-
[3]
Aqua Security. 2026. Tracee: Linux Runtime Security and Forensics using eBPF.https://github.com/aquasecurity/tracee
2026
-
[4]
Adam Bates, Dave Tian, Kevin R. B. Butler, and Thomas Moyer. 2015. Trustworthy Whole-System Provenance for the Linux Kernel. In24th 12 USENIX Security Symposium (USENIX Security 15). USENIX Associa- tion, Washington, DC, 319–334.https://www.usenix.org/conference/ usenixsecurity15/technical-sessions/presentation/bates
2015
-
[5]
Birgitta Böckeler. 2026. Harness Engineering for Coding Agent Users. https://martinfowler.com/articles/harness-engineering.html. Pub- lished April 2, 2026
2026
-
[6]
Canonical Ltd. 2024. AppArmor Security Profiles.https://apparmor. net/
2024
-
[7]
Worawalan Chatlatanagulchai, Hao Li, Yutaro Kashiwa, Brittany Reid, Kundjanasith Thonglek, Pattara Leelaprute, Arnon Rungsawang, Bun- dit Manaskasemsak, Bram Adams, Ahmed E. Hassan, and Hajimu Iida. 2025. Agent READMEs: An Empirical Study of Context Files for Agentic Coding. arXiv:2511.12884.https://arxiv.org/abs/2511.12884
arXiv 2025
-
[8]
Worawalan Chatlatanagulchai, Kundjanasith Thonglek, Brittany Reid, Yutaro Kashiwa, Pattara Leelaprute, Arnon Rungsawang, Bundit Man- askasemsak, and Hajimu Iida. 2026. On the Use of Agentic Coding Manifests: An Empirical Study of Claude Code. InProduct-Focused Software Process Improvement. Springer Nature Switzerland, 543–551. doi:10.1007/978-3-032-12089-2_40
-
[9]
Zhaorun Chen, Mintong Kang, and Bo Li. 2025. ShieldAgent: Shielding Agents via Verifiable Safety Policy Reasoning. InProceedings of the 42nd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 267). PMLR, 8313–8344.https://proceedings. mlr.press/v267/chen25ae.html
2025
-
[10]
Sahana Chennabasappa, Cyrus Nikolaidis, Daniel Song, David Molnar, Stephanie Ding, Shengye Wan, Spencer Whitman, Lauren Deason, Nicholas Doucette, Abraham Montilla, Alekhya Gampa, Beto de Paola, Dominik Gabi, James Crnkovich, Jean-Christophe Testud, Kat He, Rashnil Chaturvedi, Wu Zhou, and Joshua Saxe. 2025. LlamaFirewall: An Open Source Guardrail System ...
arXiv 2025
-
[11]
Cilium Project. 2026. Tetragon: eBPF-based Security Observability and Runtime Enforcement.https://tetragon.io/
2026
-
[12]
James Clause, Wanchun Li, and Alessandro Orso. 2007. Dytan: A Generic Dynamic Taint Analysis Framework. InProceedings of the 2007 International Symposium on Software Testing and Analysis. Association for Computing Machinery, London, United Kingdom, 196–206. doi:10. 1145/1273463.1273490
arXiv 2007
-
[13]
Manuel Costa, Boris Köpf, Aashish Kolluri, Andrew Paverd, Mark Russinovich, Ahmed Salem, Shruti Tople, Lukas Wutschitz, and Santi- ago Zanella-Béguelin. 2025. Securing AI Agents with Information-Flow Control. arXiv:2505.23643.https://arxiv.org/abs/2505.23643
Pith/arXiv arXiv 2025
-
[14]
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, An- dreas Terzis, and Florian Tramèr. 2025. Defeating Prompt Injections by Design. arXiv:2503.18813.https://arxiv.org/abs/2503.18813
Pith/arXiv arXiv 2025
-
[15]
Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer- Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dy- namic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents. InAdvances in Neural Information Processing Systems, Vol. 37. Curran Associates, Inc., Vancouver, Canada, 82895–82920. doi:10.52202/079017-2636
-
[16]
DeepSeek-AI. 2026. DeepSeek-V4: Towards Highly Efficient Million- Token Context Intelligence. Technical report.https://huggingface.co/ deepseek-ai/DeepSeek-V4-Pro/resolve/main/DeepSeek_V4.pdf
2026
-
[17]
Deming Ding, Shichun Liu, Enhui Yang, Jiahang Lin, Ziying Chen, Shihan Dou, Honglin Guo, Weiyu Cheng, Pengyu Zhao, Chengjun Xiao, Qunhong Zeng, Qi Zhang, Xuanjing Huang, Qidi Xu, and Tao Gui. 2026. OctoBench: Benchmarking Scaffold-Aware Instruction Following in Repository-Grounded Agentic Coding. arXiv:2601.10343. https://arxiv.org/abs/2601.10343
arXiv 2026
-
[18]
Jake Edge. 2015. A seccomp overview.https://lwn.net/Articles/ 656307/
2015
-
[19]
Cox, Jaeyeon Jung, Patrick McDaniel, and Anmol N
William Enck, Peter Gilbert, Byung-Gon Chun, Landon P. Cox, Jaeyeon Jung, Patrick McDaniel, and Anmol N. Sheth. 2010. TaintDroid: An Information-Flow Tracking System for Re- altime Privacy Monitoring on Smartphones. In9th USENIX Symposium on Operating Systems Design and Implementation (OSDI 10). USENIX Association, Vancouver, Canada, 393–407. https://www....
2010
-
[20]
Matthias Galster, Seyedmoein Mohsenimofidi, Jai Lal Lulla, Muham- mad Auwal Abubakar, Christoph Treude, and Sebastian Baltes. 2026. Configuring Agentic AI Coding Tools: An Exploratory Study. In ACM AIware 2026. Association for Computing Machinery.https: //openreview.net/forum?id=cqmx1MLZCq
2026
-
[21]
Sangam Ghimire, Nirjal Bhurtel, Roshan Sahani, and Sudan Jha. 2025. eBPF-PATROL: Protective Agent for Threat Recognition and Over- reach Limitation using eBPF in Containerized and Virtualized En- vironments. InProceedings of the National Conference on Computer Innovations (NCCI 2025). Kathmandu University Computer Club, Dhu- likhel, Nepal.https://arxiv.or...
arXiv 2025
-
[22]
Google. 2018. gVisor: Application Kernel for Containers.https:// github.com/google/gvisor.https://gvisor.dev/
2018
-
[23]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection. InProceedings of the 16th ACM Workshop on Artifi- cial Intelligence and Security. Association for Computing Machinery, Copenhagen, Denmark...
-
[24]
Invariant Labs. 2025. Invariant Guardrails Documentation.https: //github.com/invariantlabs-ai/invariant
2025
-
[25]
Xiaojun Jia, Jie Liao, Simeng Qin, Jindong Gu, Wenqi Ren, Xi- aochun Cao, Yang Liu, and Philip Torr. 2026. SkillJect: Effectively Automating Skill-Based Prompt Injection for Skill-Enabled Agents. arXiv:2602.14211https://arxiv.org/abs/2602.14211
Pith/arXiv arXiv 2026
-
[26]
Yuxin Jiang, Yufei Wang, Xingshan Zeng, Wanjun Zhong, Liangyou Li, Fei Mi, Lifeng Shang, Xin Jiang, Qun Liu, and Wei Wang. 2024. Follow- Bench: A Multi-level Fine-grained Constraints Following Benchmark for Large Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers). Associatio...
-
[27]
Kemerlis, Georgios Portokalidis, Kangkook Jee, and An- gelos D
Vasileios P. Kemerlis, Georgios Portokalidis, Kangkook Jee, and An- gelos D. Keromytis. 2012. libdft: Practical Dynamic Data Flow Track- ing for Commodity Systems. InProceedings of the 8th ACM SIG- PLAN/SIGOPS Conference on Virtual Execution Environments. Asso- ciation for Computing Machinery, London, United Kingdom, 121–132. doi:10.1145/2151024.2151042
-
[28]
Frans Kaashoek, Eddie Kohler, and Robert Morris
Maxwell Krohn, Alexander Yip, Micah Brodsky, Natan Cliffer, M. Frans Kaashoek, Eddie Kohler, and Robert Morris. 2007. Information Flow Control for Standard OS Abstractions. InProceedings of the 21st ACM SIGOPS Symposium on Operating Systems Principles (SOSP ’07). Association for Computing Machinery, Stevenson, WA, 321–334. doi:10.1145/1294261.1294293
-
[29]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Asso- ciation for Computational Linguistics12 (2024), 157–173. doi:10.1162/ tacl_a_00638
2024
-
[30]
Zhang, Sebastian Baltes, and Christoph Treude
Jai Lal Lulla, Seyedmoein Mohsenimofidi, Matthias Galster, Jie M. Zhang, Sebastian Baltes, and Christoph Treude. 2026. On the Impact of AGENTS.md Files on the Efficiency of AI Coding Agents. In Proceedings of the 1st Journal Ahead Workshop at the International Conference on Software Engineering. Association for Computing 13 Machinery.https://conf.research...
2026
-
[31]
Narek Maloyan and Dmitry Namiot. 2026. Prompt Injection Attacks on Agentic Coding Assistants: A Systematic Analysis of Vulnerabilities in Skills, Tools, and Protocol Ecosystems. arXiv:2601.17548https: //arxiv.org/abs/2601.17548
arXiv 2026
-
[32]
Max McGuinness, Mikaela Grace, Jiri De Jonghe, Jake Eaton, and Abel Ribbink. 2026. How We Contain Claude Across Products.https:// www.anthropic.com/engineering/how-we-contain-claude. Anthropic Engineering Blog, May 25, 2026
2026
-
[33]
Yutao Mou, Zhangchi Xue, Lijun Li, Peiyang Liu, Shikun Zhang, Wei Ye, and Jing Shao. 2026. ToolSafe: Enhancing Tool Invocation Safety of LLM-based Agents via Proactive Step-Level Guardrail and Feed- back. arXiv:2601.10156https://arxiv.org/abs/2601.10156Accepted to Findings of the Association for Computational Linguistics: ACL 2026
arXiv 2026
-
[34]
Holland, Uri Braun, and Margo Seltzer
Kiran-Kumar Muniswamy-Reddy, David A. Holland, Uri Braun, and Margo Seltzer. 2006. Provenance-Aware Stor- age Systems. In2006 USENIX Annual Technical Conference (USENIX ATC 06). USENIX Association, Boston, MA, 43–56. https://www.usenix.org/conference/2006-usenix-annual-technical- conference/provenance-aware-storage-systems
2006
-
[35]
Andrew C. Myers. 1999. JFlow: Practical Mostly-Static Informa- tion Flow Control. InProceedings of the 26th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (POPL ’99). As- sociation for Computing Machinery, New York, NY, USA, 228–241. doi:10.1145/292540.292561
-
[36]
OpenAI. 2025. Codex CLI.https://github.com/openai/codex
2025
-
[37]
OpenAI. 2026. GPT-5.5 System Card.https://openai.com/index/gpt-5- 5-system-card/. Published April 23, 2026; updated April 24, 2026
2026
-
[38]
Thomas F. J.-M. Pasquier, Xueyuan Han, Thomas Moyer, Adam Bates, Olivier Hermant, David Eyers, Jean Bacon, and Margo Seltzer. 2018. Runtime Analysis of Whole-System Provenance. InProceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security. Association for Computing Machinery, Toronto, Canada, 1601–1616. doi:10.1145/3243734.3243776
-
[39]
Thomas F. J.-M. Pasquier, Jatinder Singh, David Eyers, and Jean Bacon
-
[40]
CamFlow: Managed Data-Sharing for Cloud Services.IEEE Transactions on Cloud Computing5, 3 (2017), 472–484. doi:10.1109/ TCC.2015.2489211
arXiv 2017
-
[41]
Pohly, Stephen McLaughlin, Patrick McDaniel, and Kevin But- ler
Devin J. Pohly, Stephen McLaughlin, Patrick McDaniel, and Kevin But- ler. 2012. Hi-Fi: Collecting High-Fidelity Whole-System Provenance. InProceedings of the 28th Annual Computer Security Applications Con- ference. Association for Computing Machinery, Orlando, FL, 259–268. doi:10.1145/2420950.2420989
-
[42]
Yunjia Qi, Hao Peng, Xiaozhi Wang, Amy Xin, Youfeng Liu, Bin Xu, Lei Hou, and Juanzi Li. 2025. AGENTIF: Benchmarking Large Language Models Instruction Following Ability in Agentic Scenarios. InAdvances in Neural Information Processing Systems, Vol. 38. Curran Associates, Inc.https://proceedings.neurips.cc/paper_files/ paper/2025/hash/51bb3a8a33610a25aae07...
2025
-
[43]
Traian Rebedea, Razvan Dinu, Makesh Narsimhan Sreedhar, Christo- pher Parisien, and Jonathan Cohen. 2023. NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Association for Compu- tational Linguistics...
-
[44]
Santos, Vitor Costa, Joao Eduardo Montandon, and Marco Tulio Valente
Helio Victor F. Santos, Vitor Costa, Joao Eduardo Montandon, and Marco Tulio Valente. 2026. Decoding the Configuration of AI Coding Agents: Insights from Claude Code Projects. InProceedings of the 2026 International Workshop on Agentic Engineering. Association for Computing Machinery, Rio de Janeiro, Brazil, 63–67. doi:10.1145/ 3786167.3788412
arXiv 2026
-
[45]
Tianneng Shi, Jingxuan He, Zhun Wang, Hongwei Li, Linyu Wu, Wenbo Guo, and Dawn Song. 2025. Progent: Securing AI Agents with Privilege Control. arXiv:2504.11703.https://arxiv.org/abs/2504.11703
Pith/arXiv arXiv 2025
-
[46]
The Linux Kernel Documentation. 2025. Landlock: Unprivileged Access Control.https://www.kernel.org/doc/html/latest/userspace- api/landlock.html
2025
-
[47]
Vivek Trivedy. 2026. The Anatomy of an Agent Harness.https://www. langchain.com/blog/the-anatomy-of-an-agent-harness. Published March 10, 2026
2026
-
[48]
Sanidhya Vijayvargiya, Aditya Bharat Soni, Xuhui Zhou, Zora Zhiruo Wang, Nouha Dziri, Graham Neubig, and Maarten Sap. 2026. OpenA- gentSafety: A Comprehensive Framework for Evaluating Real-World AI Agent Safety. InThe Fourteenth International Conference on Learning Representations. OpenReview.net.https://openreview.net/forum?id= xggSxCFQbA
2026
-
[49]
Haoyu Wang, Christopher M. Poskitt, and Jun Sun. 2026. AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents. In2026 IEEE/ACM 48th International Conference on Software Engi- neering (ICSE). Association for Computing Machinery, New York, NY, USA, 12 pages.https://conf.researchr.org/track/icse-2026/icse- 2026-research-trackResearch Tr...
Pith/arXiv arXiv 2026
-
[50]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Jun- yang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neu- big. 2025. OpenHands: An Open Platform f...
2025
-
[51]
Robert N. M. Watson, Jonathan Anderson, Ben Laurie, and Kris Ken- naway. 2010. Capsicum: Practical Capabilities for UNIX. In19th USENIX Security Symposium (USENIX Security 10). USENIX Associa- tion, Washington, DC, 29–46.https://www.usenix.org/conference/ usenixsecurity10/capsicum-practical-capabilities-unix
2010
-
[52]
Tianyuan Wu, Chaokun Chang, Lunxi Cao, Wei Gao, and Wei Wang
-
[53]
arXiv:2604.28138 [cs.OS]https://arxiv.org/abs/2604
Crab: A Semantics-Aware Checkpoint/Restore Runtime for Agent Sandboxes. arXiv:2604.28138 [cs.OS]https://arxiv.org/abs/2604. 28138
-
[54]
Zhen Xiang, Linzhi Zheng, Yanjie Li, Junyuan Hong, Qinbin Li, Han Xie, Jiawei Zhang, Zidi Xiong, Chulin Xie, Carl Yang, Dawn Song, and Bo Li. 2025. GuardAgent: Safeguard LLM Agents via Knowledge- Enabled Reasoning. InProceedings of the 42nd International Con- ference on Machine Learning (Proceedings of Machine Learning Re- search, Vol. 267). PMLR, Vancouv...
2025
-
[55]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, et al
-
[56]
arXiv:2505.09388.https://arxiv.org/ abs/2505.09388
Qwen3 Technical Report. arXiv:2505.09388.https://arxiv.org/ abs/2505.09388
-
[57]
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent- Computer Interfaces Enable Automated Software Engineering. InAd- vances in Neural Information Processing Systems, Vol. 37. Curran As- sociates, Inc., Vancouver, Canada, 50528–50652. doi:10.52202/079017- 1601
-
[58]
Heng Yin, Dawn Song, Manuel Egele, Christopher Kruegel, and Engin Kirda. 2007. Panorama: Capturing System-wide Information Flow for Malware Detection and Analysis. InProceedings of the 14th ACM Conference on Computer and Communications Security. Association for Computing Machinery, Alexandria, VA, 116–127. doi:10.1145/1315245. 14 1315261
-
[59]
Nickolai Zeldovich, Silas Boyd-Wickizer, Eddie Kohler, and David Mazières. 2006. Making Information Flow Explicit in HiStar. InPro- ceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’06). USENIX Association, Seattle, WA, 263– 278.https://www.usenix.org/conference/osdi-06/making-information- flow-explicit-histar
2006
-
[60]
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. 2024. In- jecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents. InFindings of the Association for Compu- tational Linguistics: ACL 2024. Association for Computational Linguis- tics, Bangkok, Thailand, 10471–10506. doi:10.18653/v1/2024.findings- acl.624
-
[61]
Xing Zhang, Guanghui Wang, Yanwei Cui, Wei Qiu, Ziyuan Li, Bing Zhu, and Peiyang He. 2026. Guardrails Beat Guidance: A Large-Scale Study of Rules, Skills, and Persistent Configuration for Coding Agents. arXiv:2604.11088 [cs.SE]
Pith/arXiv arXiv 2026
-
[62]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhang- hao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 36. Curran Asso- ciates, Inc., New Orleans, L...
-
[63]
Yusheng Zheng, Yanpeng Hu, Tong Yu, and Andi Quinn. 2025. AgentSight: System-Level Observability for AI Agents Using eBPF. In Proceedings of the 4th Workshop on Practical Adoption Challenges of ML for Systems. Association for Computing Machinery, Seoul, Republic of Korea, 110–115. doi:10.1145/3766882.3767169 A Policy Language Grammar This appendix gives t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.