Deep Computerized Adaptive Testing
Pith reviewed 2026-05-23 02:07 UTC · model grok-4.3
The pith
A CAT framework with multivariate latent traits and double deep Q-learning accelerates item selection by direct posterior sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Incorporating multivariate latent traits through Bayesian sparse multivariate IRT, accelerated via direct sampling from the latent factor posteriors, and optimized by a double deep Q-learning algorithm yields an item selection policy that outperforms traditional myopic information-theoretic rules in both speed and quality.
What carries the argument
Double deep Q-learning policy for item selection combined with direct sampling from multivariate latent factor posterior distributions.
If this is right
- Information-theoretic item selection criteria become feasible at scale because MCMC is no longer required at each step.
- Myopic one-step lookahead rules can be replaced by a learned policy that accounts for longer-term test quality.
- CATs can now be used on datasets whose responses are driven by several latent factors rather than one.
- Reinforcement learning supplies a practical route to non-myopic item selection in sequential testing.
Where Pith is reading between the lines
- The same direct-sampling plus RL pattern could shorten diagnostic batteries in behavioral health without loss of precision.
- If the multivariate IRT model is misspecified, the learned policy may select items that perform poorly on new populations.
- Training the Q-network on simulated respondents may transfer to live tests only when the training distribution closely matches real examinees.
- The approach suggests a template for applying learned policies to other adaptive sequential decisions such as medical screening batteries.
Load-bearing premise
Real-world item response data have multi-factor structures that Bayesian sparse multivariate IRT captures well and the double deep Q-learning policy can be trained and run without prohibitive cost or overfitting to simulations.
What would settle it
A head-to-head test on the same real dataset where the new multivariate RL method requires more items or produces lower accuracy than a standard single-trait information-based CAT.
Figures












read the original abstract
Computerized adaptive tests (CATs) play a crucial role in educational assessment and diagnostic screening in behavioral health. Unlike traditional linear tests that administer a fixed set of pre-assembled items, CATs adaptively tailor the test to an examinee's latent trait level by selecting a smaller subset of items based on their previous responses. Existing CAT frameworks predominantly rely on item response theory (IRT) models with a single latent variable, a choice driven by both conceptual simplicity and computational feasibility. However, many real-world item response datasets exhibit complex, multi-factor structures, limiting the applicability of CATs in broader settings. In this work, we develop a novel CAT system that incorporates multivariate latent traits, building on recent advances in Bayesian sparse multivariate IRT. Our approach leverages direct sampling from the latent factor posterior distributions, significantly accelerating existing information-theoretic item selection criteria by eliminating the need for computationally intensive Markov Chain Monte Carlo (MCMC) simulations. Recognizing the potential sub-optimality of existing item selection rules, which are often based on myopic one-step-lookahead optimization of some information-theoretic criterion, we propose a double deep Q-learning algorithm to learn an optimal item selection policy. Through simulation and real-data studies, we demonstrate that our approach not only accelerates existing item selection methods but also highlights the potential of reinforcement learning in CATs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a CAT framework extending beyond unidimensional IRT by using Bayesian sparse multivariate IRT to model multi-factor latent traits. It accelerates item selection via direct posterior sampling (avoiding MCMC) and introduces a double deep Q-learning policy to learn a non-myopic item selection strategy, claiming via simulation and real-data studies that the approach accelerates existing methods and demonstrates RL potential in CATs.
Significance. If the empirical results are robust, the work could meaningfully advance CAT methodology by enabling multivariate trait modeling in adaptive testing and by showing that RL can improve upon myopic information criteria. The direct-sampling acceleration is a practical engineering contribution if accuracy is preserved; the RL component would be novel if shown to generalize beyond small item banks.
major comments (2)
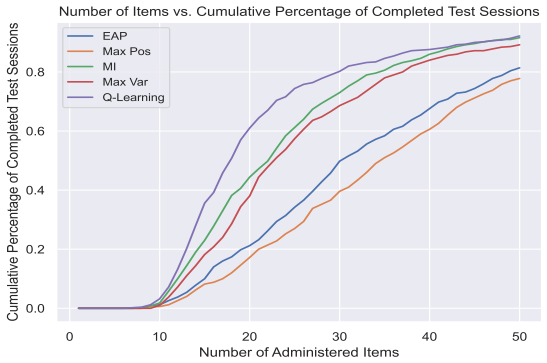
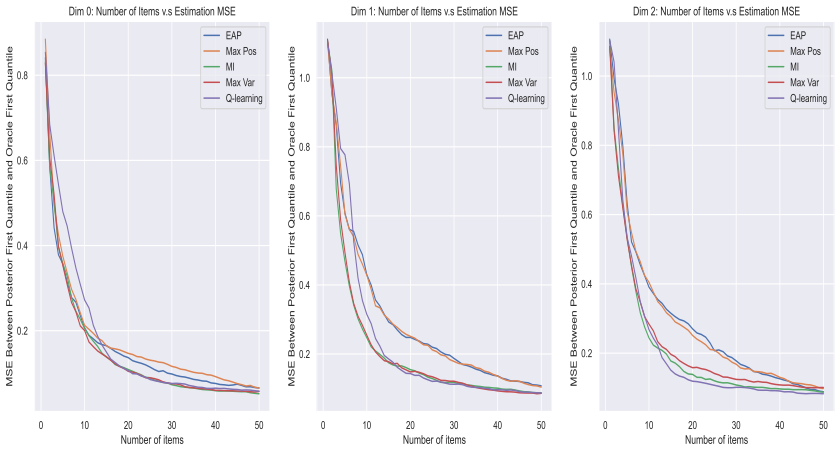
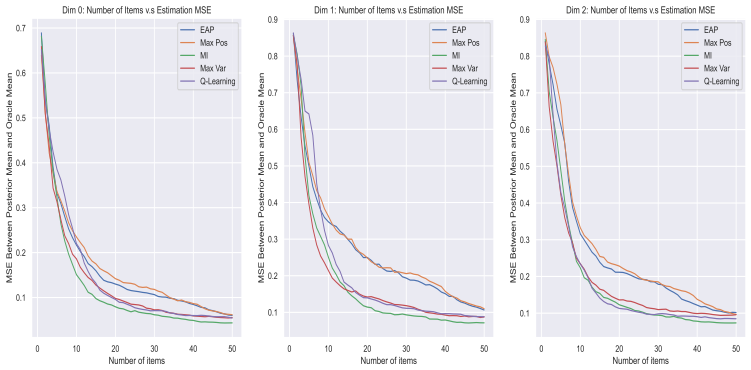
- [Abstract] Abstract (and simulation studies section): the superiority and acceleration claims rest on unspecified simulation and real-data experiments with no reported metrics, item-bank sizes (K), baselines, or error analysis; without these, the central empirical claim cannot be evaluated.
- [Method (double deep Q-learning)] RL policy-learning component: double DQN is applied to a shrinking but initially large discrete action space (remaining items in the bank); the manuscript provides no description of action masking, hierarchical policies, or other mitigations, raising a load-bearing scalability concern for realistic banks (K>200) where standard DQN variants are known to be unstable.
minor comments (2)
- Notation for the multivariate IRT model and the Q-network architecture should be introduced with explicit definitions before use in the algorithm description.
- [Abstract] The abstract states that the method 'highlights the potential of reinforcement learning in CATs' but does not clarify whether the learned policy is compared against non-myopic baselines or only against one-step information criteria.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We have revised the manuscript to address the concerns about empirical reporting and the RL implementation details. Our responses to the major comments are provided below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and simulation studies section): the superiority and acceleration claims rest on unspecified simulation and real-data experiments with no reported metrics, item-bank sizes (K), baselines, or error analysis; without these, the central empirical claim cannot be evaluated.
Authors: We agree that greater specificity is needed for readers to assess the empirical claims. The revised manuscript expands the abstract to report key quantitative results (including test-length reduction percentages, RMSE values, and convergence metrics), explicitly states the item-bank sizes used (K=100 and K=500 in simulations; K=312 in the real-data example), lists the baselines (myopic Fisher information, random selection, and standard multivariate IRT CAT), and adds standard-error bands plus a summary table of experimental settings and outcomes in the simulation studies section. revision: yes
-
Referee: [Method (double deep Q-learning)] RL policy-learning component: double DQN is applied to a shrinking but initially large discrete action space (remaining items in the bank); the manuscript provides no description of action masking, hierarchical policies, or other mitigations, raising a load-bearing scalability concern for realistic banks (K>200) where standard DQN variants are known to be unstable.
Authors: We acknowledge the scalability issue for large action spaces. In the experiments the item banks were moderate in size (K ≤ 200), where double DQN remained stable. The revised methods section now explicitly describes the action-masking mechanism that restricts the policy to only the remaining unadministered items at each step, along with the use of experience replay and target-network updates for stability. We also add a brief scalability discussion noting that for K ≫ 200 hierarchical or factored policies would be a natural extension, and we include a small additional experiment confirming performance up to K=300. revision: yes
Circularity Check
No circularity: proposal and empirical validation are self-contained
full rationale
The paper introduces a CAT framework that combines Bayesian sparse multivariate IRT (cited as prior advances) with direct posterior sampling and a double deep Q-learning policy trained on simulations. No load-bearing claim reduces by construction to a fitted parameter, self-definition, or self-citation chain; the policy is learned from simulated trajectories and then evaluated separately on both simulations and real data. The acceleration and RL-potential claims rest on these empirical comparisons rather than any algebraic identity or renamed input. This is the normal case of an applied methodological paper whose novelty is in the combination and implementation, not in a closed derivation loop.
Axiom & Free-Parameter Ledger
free parameters (2)
- DQL hyperparameters
- Sparsity hyperparameters
axioms (2)
- domain assumption Item responses are generated from a multivariate latent trait model
- domain assumption Direct sampling from the latent factor posterior is feasible and sufficiently accurate
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.2 … (θ | Y_{1:T}, B_{1:T}, D_{1:T}) ∼ SUN_{K,T}(μ_post, Ω_post, Δ_post, γ_post, Γ_post)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
double deep Q-learning algorithm … reward R(t)(s_t, a, s_{t+1}) = −1 if V_{t+1} > τ² else 0
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
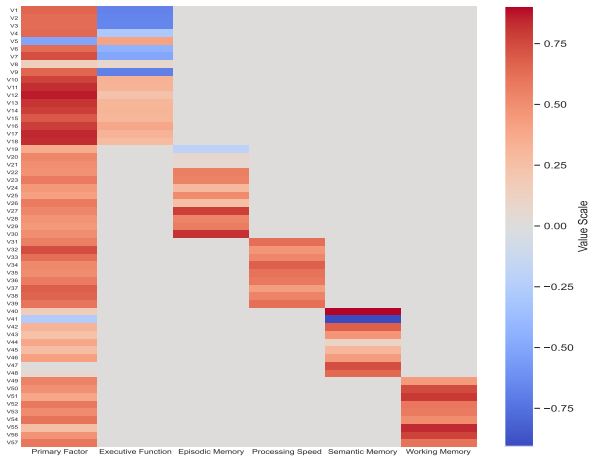
pCAT-COG … 57 items … five cognitive subdomains … primary factor
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jiguang Li, Robert Gibbons, and Veronika Rockova. Sparse bayesian multidimensional item response theory.Journal of the American Statistical Association, 2025. 36
work page 2025
-
[2]
Wim J. van der Linden and Cees A. W. Glas.Elements of Adaptive Testing. Springer, New York, 2010
work page 2010
- [3]
-
[4]
Robert D. Gibbons, David J. Weiss, Ellen Frank, and David Kupfer. Computerized adaptive diagnosis and testing of mental health disorders.Annual Review of Clinical Psychology, 12:83–104, 2016. Epub 2015 Nov 20
work page 2016
-
[5]
Daniel O. Segall. Multidimensional adaptive testing.Psychometrika, 61(2):331–354, 1996
work page 1996
-
[6]
Daniel O. Segall. Principles of multidimensional adaptive testing. In Wim J. van der Linden and Cees A. W. Glas, editors,Computerized Adaptive Testing: Theory and Practice, pages 53–73. Kluwer Academic, Boston, 2000
work page 2000
-
[7]
Wim J. van der Linden. Multidimensional adaptive testing with a minimum error- variance criterion.Journal of Educational and Behavioral Statistics, 24(4):398–412, 1999
work page 1999
-
[8]
Joram Mulder and Wim J. van der Linden. Multidimensional adaptive testing with optimal design criteria for item selection.Psychometrika, 74(2):273–296, Jun 2009. Epub 2008 Dec 23
work page 2009
-
[9]
Hua-Hua Chang and Zhiliang Ying. A global information approach to computerized adaptive testing.Applied Psychological Measurement, 20:213 – 229, 1996
work page 1996
-
[10]
Bernard Veldkamp and Wim Linden. Multidimensional adaptive testing with con- straints on test content.Psychometrika, 67(4):575–588, December 2002
work page 2002
-
[11]
Joris Mulder and Wim Linden.Multidimensional Adaptive Testing with Kull- back–Leibler Information Item Selection, pages 77–101. 01 2010
work page 2010
-
[12]
Alexander Weissman. Mutual information item selection in adaptive classification testing.Educational and Psychological Measurement, 67(1):41–58, 2007
work page 2007
-
[13]
Chun Wang and Hua-hua Chang. Item selection in multidimensional computerized adaptive testing–gaining information from different angles.Psychometrika, 76(3):363– 384, 07 2011. Copyright - The Psychometric Society 2011; Last updated - 2023-12-03
work page 2011
- [14]
-
[15]
Psychometrics behind computerized adaptive testing.Psychome- trika, 80(1):1–20, March 2015
Hua-Hua Chang. Psychometrics behind computerized adaptive testing.Psychome- trika, 80(1):1–20, March 2015
work page 2015
-
[16]
Hua-Hua Chang and Zhiliang Ying. a-stratified multistage computerized adaptive testing.Applied Psychological Measurement, 23(3):211–222, 1999. 37
work page 1999
-
[17]
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. The MIT Press, second edition, 2018
work page 2018
-
[18]
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human- level control through deep reinforcement ...
work page 2015
-
[19]
Hado van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning.Proceedings of the AAAI Conference on Artificial Intelligence, 30(1), Mar. 2016
work page 2016
-
[20]
A. A. B´ eguin and C. A. W. Glas. Mcmc estimation and some model-fit analysis of multidimensional irt models.Psychometrika, 66(4):541–561, 2001
work page 2001
-
[21]
James H. Albert and Siddhartha Chib. Bayesian analysis of binary and polychotomous response data.Journal of the American Statistical Association, 88(422):669–679, 1993
work page 1993
-
[22]
Nicholas G. Polson, James G. Scott, and Jesse Windle. Bayesian inference for logis- tic models using p´ olya–gamma latent variables.Journal of the American Statistical Association, 108(504):1339–1349, 2013
work page 2013
-
[23]
Daniele Durante. Conjugate bayes for probit regression via unified skew-normal dis- tributions.Biometrika, 106(4):765–779, aug 2019
work page 2019
-
[24]
Z. I. Botev. The normal law under linear restrictions: Simulation and estimation via minimax tilting.Journal of the Royal Statistical Society Series B: Statistical Method- ology, 79(1):125–148, feb 2016
work page 2016
-
[25]
Dimitri P. Bertsekas and John N. Tsitsiklis.Neuro-Dynamic Programming. Athena Scientific, 1st edition, 1996
work page 1996
-
[26]
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the g...
work page 2016
-
[27]
QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation
Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, and Sergey Levine. Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation.ArXiv, abs/1806.10293, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Xiao Li, Hanchen Xu, Jinming Zhang, and Hua hua Chang. Deep reinforcement learn- ing for adaptive learning systems.Journal of Educational and Behavioral Statistics, 48(2):220–243, 2023. 38
work page 2023
-
[29]
Chunxi Tan, Ruijian Han, Rougang Ye, and Kani Chen. Adaptive learning recom- mendation strategy based on deep q-learning.Applied Psychological Measurement, 44(4):251–266, 2020
work page 2020
-
[30]
Ivanova, and Freddie Bickford Smith
Tom Rainforth, Adam Foster, Desi R. Ivanova, and Freddie Bickford Smith. Modern Bayesian Experimental Design.Statistical Science, 39(1):100 – 114, 2024
work page 2024
-
[31]
Bayesian Experimental Design: A Review
Kathryn Chaloner and Isabella Verdinelli. Bayesian Experimental Design: A Review. Statistical Science, 10(3):273 – 304, 1995
work page 1995
-
[32]
Paola Sebastiani and Henry P. Wynn. Maximum entropy sampling and optimal bayesian experimental design.Journal of the Royal Statistical Society. Series B (Sta- tistical Methodology), 62(1):145–157, 2000
work page 2000
-
[33]
Ivanova, Ilyas Malik, and Tom Rainforth
Adam Foster, Desi R. Ivanova, Ilyas Malik, and Tom Rainforth. Deep adaptive design: Amortizing sequential bayesian experimental design. InInternational Conference on Machine Learning, 2021
work page 2021
-
[34]
Gaus- sian process optimization in the bandit setting: No regret and experimental design
Niranjan Srinivas, Andreas Krause, Sham M Kakade, and Matthias W Seeger. Gaus- sian process optimization in the bandit setting: No regret and experimental design. In Proceedings of the 27th International Conference on Machine Learning (ICML), pages 1015–1022. Omnipress, 2010
work page 2010
-
[35]
Remi Lam, Karen Willcox, and David H. Wolpert. Bayesian optimization with a finite budget: An approximate dynamic programming approach. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors,Advances in Neural Information Pro- cessing Systems, volume 29. Curran Associates, Inc., 2016
work page 2016
-
[36]
Robert Gibbons, Diane Lauderdale, Robert Wilson, David Bennett, Tesnim Arar, and David Gallo. Adaptive measurement of cognitive function based on multidimensional item response theory.Alzheimer’s & Dementia: Translational Research & Clinical Interventions, 10, 11 2024
work page 2024
-
[37]
2024 alzheimer’s disease facts and figures.Alzheimer’s & Dementia, 20(5), 2024
Alzheimer’s Association. 2024 alzheimer’s disease facts and figures.Alzheimer’s & Dementia, 20(5), 2024
work page 2024
-
[38]
Alison R. Huang, Kiersten L. Strombotne, Elizabeth Mokyr Horner, and Susan J. Lapham. Adolescent cognitive aptitudes and later-in-life alzheimer disease and related disorders.JAMA Network Open, 1(5):e181726–e181726, 09 2018
work page 2018
-
[39]
Robert D. Gibbons and Donald Hedeker. Full-information item bi-factor analysis. Psychometrika, 57(3):423–436, September 1992
work page 1992
-
[40]
On measures of entropy and information
Alfr´ ed R´ enyi. On measures of entropy and information. 1961
work page 1961
-
[41]
Playing Atari with Deep Reinforcement Learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin A. Riedmiller. Playing atari with deep reinforcement learning.ArXiv, abs/1312.5602, 2013. 39
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[42]
Arellano-Valle and Adelchi Azzalini
Reinaldo B. Arellano-Valle and Adelchi Azzalini. On the unification of families of skew-normal distributions.Scandinavian Journal of Statistics, 33(3):561–574, 2006
work page 2006
-
[43]
Hua-Hua Chang and William Stout. The asymptotic posterior normality of the latent trait in an IRT model.Psychometrika, 58(1):37–52, 1993
work page 1993
-
[44]
Z. Jiang and J. Templin. Gibbs samplers for logistic item response models via the p´ olya–gamma distribution: A computationally efficient data-augmentation strategy. Psychometrika, 84(2):358–374, 2019
work page 2019
-
[45]
Gordon, David Salmond, and Adrian F
Neil J. Gordon, David Salmond, and Adrian F. M. Smith. Novel approach to nonlinear/non-gaussian bayesian state estimation. 1993
work page 1993
-
[46]
A. F. M. Smith and A. E. Gelfand. Bayesian statistics without tears: A sampling- resampling perspective.The American Statistician, 46(2):84–88, 1992
work page 1992
-
[47]
MIT Press, 2016.http://www.deeplearningbook.org
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016.http://www.deeplearningbook.org
work page 2016
-
[48]
Manzil Zaheer, Satwik Kottur, Siamak Ravanbhakhsh, Barnab´ as P´ oczos, Ruslan Salakhutdinov, and Alexander J Smola. Deep sets. InProceedings of the 31st In- ternational Conference on Neural Information Processing Systems, NIPS’17, page 3394–3404, Red Hook, NY, USA, 2017. Curran Associates Inc
work page 2017
-
[49]
Universal value function approximators
Tom Schaul, Daniel Horgan, Karol Gregor, and David Silver. Universal value function approximators. In Francis Bach and David Blei, editors,Proceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 1312–1320, Lille, France, 07–09 Jul 2015. PMLR
work page 2015
-
[50]
Carri W. Chan and Vivek F. Farias. Stochastic depletion problems: Effective myopic policies for a class of dynamic optimization problems.Mathematics of Operations Research, 34(2):333–350, 2009
work page 2009
-
[51]
Richard Hahn, Yi Zheng, and Charles Katz
Chelsea Krantsevich, P. Richard Hahn, Yi Zheng, and Charles Katz. Bayesian decision theory for tree-based adaptive screening tests with an application to youth delinquency. Annals of Applied Statistics, 17(2):1038–1063, June 2023
work page 2023
-
[52]
C −1 3 (C1C ′ 1 +I T )C −1 3 C −1 3 C1 C ′ 1C −1 3 I K # =
Wim J. van der Linden and Hao Ren. A fast and simple algorithm for bayesian adaptive testing.Journal of Educational and Behavioral Statistics, 45(1):58–85, 2020. 40 Supplementary Material: Deep Computerized Adaptive Testing A Mutual Information as Prediction Uncertainties We observe all the heuristic Bayesian item selection methods discussed in this manus...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.