Dispatching Odyssey: Exploring Performance in Computing Clusters under Real-world Workloads
Pith reviewed 2026-05-22 20:26 UTC · model grok-4.3
The pith
Real Google traces reveal optimal cluster sizes for JIQ and LWL policies at fixed utilization, while Round Robin worsens with scale and simpler JIQ beats size-aware LWL on task-decomposed jobs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
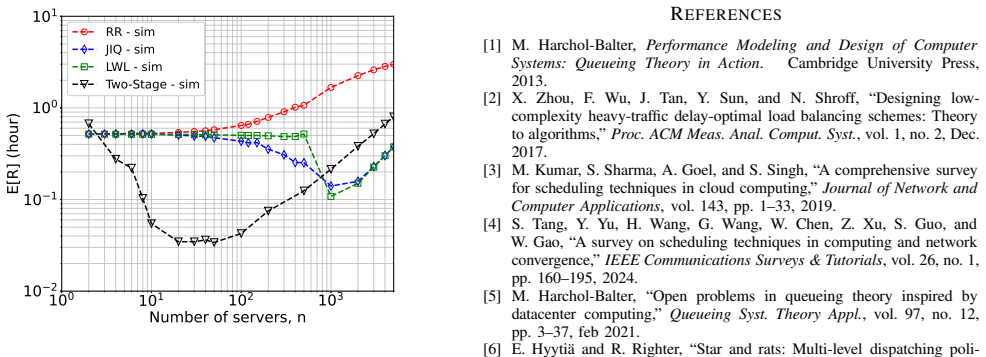
For a fixed utilization coefficient, Join Idle Queue and Least Work Left exhibit an optimal working point as the number of servers varies, while Round Robin shows monotonously worsening performance. When jobs are decomposed into tasks, the simpler non-size-based JIQ policy outperforms the size-based LWL policy. A two-stage scheduling approach that partitions tasks based on service thresholds yields further performance gains under these realistic traces.
What carries the argument
Job-level and task-level dispatching policies (Join Idle Queue, Least Work Left, Round Robin) evaluated through simulations on real workload traces, with cluster size varied at constant utilization.
If this is right
- JIQ and LWL reach minimum response time at specific cluster sizes for any fixed utilization.
- Round Robin response time increases steadily as more servers are added.
- Task decomposition reverses the expected ranking between size-aware and non-size-aware policies.
- A simple two-stage partition of tasks by service threshold improves performance without changing the base dispatching policy.
Where Pith is reading between the lines
- Clusters could be sized deliberately rather than scaled indefinitely to hit the observed optima.
- Task decomposition logic may matter more for policy selection than raw policy complexity.
- G/G queue approximations need workload-specific checks before they can guide real sizing decisions.
- Modest two-stage modifications could be tested on production systems to capture the reported gains.
Load-bearing premise
The Google workload traces together with the simulation rules for task decomposition and lack of network effects are representative enough that the observed optimal points and policy rankings will hold in other clusters.
What would settle it
Applying the same policies and simulation setup to a second independent public workload trace and checking whether the optimal points for JIQ and LWL and the JIQ-over-LWL ranking under task decomposition still appear.
Figures








read the original abstract
Recent workload measurements in Google data centers provide an opportunity to challenge existing models and, more broadly, to enhance the understanding of dispatching policies in computing clusters. Through extensive data-driven simulations, we aim to highlight the key features of workload traffic traces that influence response time performance under simple yet representative dispatching policies. For a given computational power budget, we vary the cluster size, i.e., the number of available servers. A job-level analysis reveals that Join Idle Queue (JIQ) and Least Work Left (LWL) exhibit an optimal working point for a fixed utilization coefficient as the number of servers is varied, whereas Round Robin (RR) demonstrates monotonously worsening performance. Additionally, we explore the accuracy of simple G/G queue approximations. When decomposing jobs into tasks, interesting results emerge; notably, the simpler, non-size-based policy JIQ appears to outperform the more "powerful" size-based LWL policy. Complementing these findings, we present preliminary results on a two-stage scheduling approach that partitions tasks based on service thresholds, illustrating that modest architectural modifications can further enhance performance under realistic workload conditions. We provide insights into these results and suggest promising directions for fully explaining the observed phenomena.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper uses data-driven simulations on Google workload traces to study dispatching policies (JIQ, LWL, RR) in clusters. For fixed utilization coefficient, it reports that JIQ and LWL exhibit an optimal cluster size (number of servers) for response time while RR worsens monotonically; after decomposing jobs into tasks, JIQ outperforms the size-based LWL; it also examines G/G approximations and a preliminary two-stage scheduling approach.
Significance. If the simulation fidelity holds, the results provide empirical evidence that cluster-size scaling under realistic traces can produce non-monotonic behavior for some policies and that task decomposition can reverse expected policy rankings, with modest architectural changes offering further gains. The work is notable for grounding claims in production traces rather than synthetic models.
major comments (2)
- [Simulation methodology] Simulation methodology section: the description of the data-driven simulations provides no details on validation against the Google traces (e.g., goodness-of-fit metrics, reproduction of trace statistics), error bars on reported response times, or sensitivity analysis to modeling choices such as task decomposition rules and the omission of network/overhead effects. These omissions are load-bearing because the central claims about optimal working points and policy ranking rest on unexamined simulation fidelity.
- [Results on job decomposition] Job-decomposition results: the claim that JIQ outperforms LWL after task decomposition is presented without quantitative metrics (specific response-time ratios, confidence intervals, or statistical tests) or ablation on the decomposition rules, making it difficult to assess whether the ranking reversal is robust or an artifact of the modeling assumptions.
minor comments (2)
- [Abstract] The abstract states that 'we explore the accuracy of simple G/G queue approximations' but the manuscript does not report the specific approximation formulas used or quantitative error measures against the simulations.
- [Introduction/Results] Notation for the utilization coefficient and cluster-size scaling should be defined explicitly in the first results section to avoid ambiguity when comparing across policies.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to strengthen the simulation methodology and results sections.
read point-by-point responses
-
Referee: [Simulation methodology] Simulation methodology section: the description of the data-driven simulations provides no details on validation against the Google traces (e.g., goodness-of-fit metrics, reproduction of trace statistics), error bars on reported response times, or sensitivity analysis to modeling choices such as task decomposition rules and the omission of network/overhead effects. These omissions are load-bearing because the central claims about optimal working points and policy ranking rest on unexamined simulation fidelity.
Authors: We agree that the current description lacks explicit validation steps. In the revision we will add goodness-of-fit metrics and reproduction of key trace statistics (e.g., job-size and inter-arrival distributions), report error bars from multiple independent runs, and include a sensitivity analysis on task-decomposition rules. The omission of network and overhead effects is a deliberate modeling choice to isolate dispatching behavior; we will state this limitation explicitly and discuss its implications for the reported trends. revision: yes
-
Referee: [Results on job decomposition] Job-decomposition results: the claim that JIQ outperforms LWL after task decomposition is presented without quantitative metrics (specific response-time ratios, confidence intervals, or statistical tests) or ablation on the decomposition rules, making it difficult to assess whether the ranking reversal is robust or an artifact of the modeling assumptions.
Authors: We accept that quantitative support and robustness checks are needed. The revised manuscript will report concrete response-time ratios together with confidence intervals and appropriate statistical tests. We will also add an ablation study that varies the decomposition rules to confirm that the JIQ-over-LWL ranking reversal holds under different modeling choices. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical simulation study using Google workload traces to compare dispatching policies (JIQ, LWL, RR) under varying cluster sizes at fixed utilization. Central claims report observed performance outcomes, optimal working points, and policy rankings from these simulations, including task decomposition effects. No derivation chain, equations, or predictions are present that reduce by construction to fitted inputs, self-definitions, or self-citation load-bearing premises. The analysis relies on external traces and standard simulation models without internal self-referential forcing of results.
Axiom & Free-Parameter Ledger
free parameters (1)
- utilization coefficient
axioms (1)
- domain assumption Google workload traces are representative of general computing-cluster traffic
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A job-level analysis reveals that Join Idle Queue (JIQ) and Least Work Left (LWL) exhibit an optimal working point for a fixed utilization coefficient as the number of servers is varied
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
When decomposing jobs into tasks, the simpler, non-size-based policy JIQ appears to outperform the more powerful size-based LWL policy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
"Two-Stagification": Job Dispatching in Large-Scale Clusters via a Two-Stage Architecture
A two-stage dispatching architecture with an optimized job-size threshold improves mean response time over single-stage classical policies in large clusters.
Reference graph
Works this paper leans on
-
[1]
Harchol-Balter, Performance Modeling and Design of Computer Systems: Queueing Theory in Action
M. Harchol-Balter, Performance Modeling and Design of Computer Systems: Queueing Theory in Action . Cambridge University Press, 2013
work page 2013
-
[2]
Designing lo w- complexity heavy-traffic delay-optimal load balancing sch emes: Theory to algorithms,
X. Zhou, F. Wu, J. Tan, Y . Sun, and N. Shroff, “Designing lo w- complexity heavy-traffic delay-optimal load balancing sch emes: Theory to algorithms,” Proc. ACM Meas. Anal. Comput. Syst. , vol. 1, no. 2, Dec. 2017
work page 2017
-
[3]
A comprehensi ve survey for scheduling techniques in cloud computing,
M. Kumar, S. Sharma, A. Goel, and S. Singh, “A comprehensi ve survey for scheduling techniques in cloud computing,” Journal of Network and Computer Applications , vol. 143, pp. 1–33, 2019
work page 2019
-
[4]
A survey on scheduling techniques in computing and n etwork convergence,
S. Tang, Y . Y u, H. Wang, G. Wang, W. Chen, Z. Xu, S. Guo, and W. Gao, “A survey on scheduling techniques in computing and n etwork convergence,” IEEE Communications Surveys & Tutorials , vol. 26, no. 1, pp. 160–195, 2024
work page 2024
-
[5]
Open problems in queueing theory in spired by datacenter computing,
M. Harchol-Balter, “Open problems in queueing theory in spired by datacenter computing,” Queueing Syst. Theory Appl. , vol. 97, no. 12, pp. 3–37, feb 2021
work page 2021
-
[6]
Star and rats: Multi-level dis patching poli- cies,
E. Hyytiä and R. Righter, “Star and rats: Multi-level dis patching poli- cies,” in 2020 32nd International Teletraffic Congress (ITC 32) , 2020, pp. 81–89
work page 2020
-
[7]
Job d ispatch- ing policies for queueing systems with unknown service rate s,
T. Choudhury, G. Joshi, W. Wang, and S. Shakkottai, “Job d ispatch- ing policies for queueing systems with unknown service rate s,” in Proceedings of the Twenty-second International Symposium on Theory, Algorithmic F oundations, and Protocol Design for Mobile Ne tworks and Mobile Computing (MobiHoc ’21) , 2021, pp. 181–190
work page 2021
-
[8]
Dispatching to parallel servers,
O. Bilenne, “Dispatching to parallel servers,” Queueing Systems, vol. 99, no. 3, pp. 199–230, 2021
work page 2021
-
[9]
A g eneral ’power-of-d’ dispatching framework for heterogeneous sys tems,
J. A. Jaleel, S. Doroudi, K. Gardner, and A. Wickeham, “A g eneral ’power-of-d’ dispatching framework for heterogeneous sys tems,” Queue- ing Systems , vol. 102, no. 3-4, pp. 431–480, 2022
work page 2022
-
[10]
J. Wilkes, “cluster-data/Clusterdata2019,” https://github.com/google/cluster-data/tree/master, 2019
work page 2019
-
[11]
M. Tirmazi, A. Barker, N. Deng, M. E. Haque, Z. G. Qin, S. H and, M. Harchol-Balter, and J. Wilkes, “Borg: the next generatio n,” in Proceedings of the Fifteenth European Conference on Comput er Systems, ser. EuroSys ’20. New Y ork, NY , USA: Association for Computi ng Machinery, 2020
work page 2020
-
[12]
I. Sfakianakis, E. Kanellou, M. Marazakis, and A. Bilas , Trace-Based W orkload Generation and Execution. Springer International Publishing, 08 2021, pp. 37–54
work page 2021
-
[13]
Data-driven workload gener ation based on google data center measurements,
M. Yildiz and A. Baiocchi, “Data-driven workload gener ation based on google data center measurements,” in 2024 IEEE 25th International Conference on High Performance Switching and Routing (HPSR ), 2024, pp. 143–148
work page 2024
-
[14]
Task ass ignment in a distributed system: Improving performance by unbalancin g load,
M. Crovella, M. Harchol-Balter, and C. Murta, “Task ass ignment in a distributed system: Improving performance by unbalancin g load,” in Proceedings of the ACM SIGMETRICS Joint International Conf erence on Measurement and Modeling of Computer Systems , 1998, pp. 268–269, poster Session
work page 1998
-
[15]
Network analysis without exponen tiality assump- tions,
M. Harchol-Balter, “Network analysis without exponen tiality assump- tions,” Ph.D. dissertation, University of California at Be rkeley, 1996
work page 1996
-
[16]
Exploiting process l ifetime distri- butions for dynamic load balancing,
M. Harchol-Balter and A. Downey, “Exploiting process l ifetime distri- butions for dynamic load balancing,” in Proceedings of ACM SIGMET- RICS, Philadelphia, PA, 1996, pp. 13–24
work page 1996
-
[17]
The effect of heavy-tailed job siz e distributions on computer system design,
M. Harchol-Balter, “The effect of heavy-tailed job siz e distributions on computer system design,” in Proceedings of ASA-IMS Conference on Applications of Heavy Tailed Distributions in Economics, E ngineering and Statistics , Washington, DC, 1999
work page 1999
-
[18]
Size- based scheduling to improve web performance,
M. Harchol-Balter, B. Schroeder, N. Bansal, and M. Agra wal, “Size- based scheduling to improve web performance,” ACM Transactions on Computer Systems (TOCS) , vol. 21, no. 2, pp. 207–233, 2003
work page 2003
-
[19]
The most common queue ing theory questions asked by computer systems practitioners,
M. Harchol-Balter and Z. Scully, “The most common queue ing theory questions asked by computer systems practitioners,” SIGMETRICS Per- form. Eval. Rev. , vol. 49, no. 4, p. 3–7, Jun. 2022
work page 2022
-
[20]
W. Marchal, “Numerical performance of approximate que uing formulae with application to flexible manufacturing systems,” Annals of Opera- tions Research, vol. 3, no. 1, p. 141?152, 1985
work page 1985
-
[21]
The Merit of Simple Policies: Buying Performance With Parallelism and System Architecture
M. Yildiz, A. Rolich, and A. Baiocchi, “The merit of simp le policies: Buying performance with parallelism and system architectu re,” 2025. [Online]. Available: https://arxiv.org/abs/2503.16166
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.