Script2Screen: Supporting Dialogue Scriptwriting with Interactive Audiovisual Generation
Pith reviewed 2026-05-22 19:32 UTC · model grok-4.3
The pith
Script2Screen links text dialogue scripts to AI-generated audiovisual scenes so writers can see and adjust emotional speech, gestures, and camera angles during iteration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
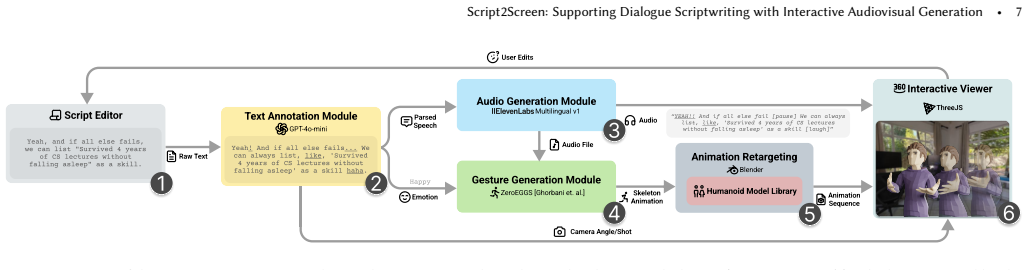
Script2Screen integrates scriptwriting with audiovisual scene creation through a novel text-to-audiovisual-scene pipeline that generates expressive scenes featuring emotional speeches and animated characters; the interface supplies fine-grained controls over character gestures, speech emotions, and camera angles, and a user study with novice and professional writers from various domains shows the approach enhances the scriptwriting process by enabling iterative refinement while complementing creative efforts.
What carries the argument
The text-to-audiovisual-scene pipeline that converts dialogue text into synchronized scenes with emotional speech and animated characters, paired with an interface for direct adjustment of gestures, emotions, and camera angles.
If this is right
- Writers gain the ability to iterate on dialogue by immediately viewing and tweaking the corresponding audiovisual elements rather than relying on imagination alone.
- The interactive controls allow fine adjustments to emotional tone and visual framing without leaving the scriptwriting environment.
- Both novice and experienced writers can use the system to explore scene ideas while retaining full creative control over the final text.
- The workflow treats audiovisual generation as a feedback aid that supports refinement cycles instead of an automated replacement for human authorship.
Where Pith is reading between the lines
- Extending the same synchronized pipeline to non-dialogue elements like action descriptions or scene transitions could broaden the tool's reach beyond its current dialogue focus.
- Embedding the controls into existing professional screenwriting software might reduce the learning curve and increase adoption among working writers.
- Collecting logged failure cases from actual use sessions would let developers target specific improvements in generation quality that the current formative study left unspecified.
Load-bearing premise
The generated audiovisual outputs for speech emotion, gestures, and camera angles are accurate and controllable enough to give useful feedback instead of misleading or distracting the writer.
What would settle it
A controlled study in which writers using the tool report that inaccurate or uncontrollable generations led to more wasted time or poorer final scripts than text-only writing would show the central claim is false.
Figures







read the original abstract
Scriptwriting has traditionally been text-centric, a modality that only partially conveys the produced audiovisual experience. A formative study with professional writers informed us that connecting textual and audiovisual modalities can aid ideation and iteration, especially for writing dialogues. In this work, we present Script2Screen, an AI-assisted tool that integrates scriptwriting with audiovisual scene creation in a unified, synchronized workflow. Focusing on dialogues in scripts, Script2Screen generates expressive scenes with emotional speeches and animated characters through a novel text-to-audiovisual-scene pipeline. The user interface provides fine-grained controls, allowing writers to fine-tune audiovisual elements such as character gestures, speech emotions, and camera angles. A user study with both novice and professional writers from various domains demonstrated that Script2Screen's interactive audiovisual generation enhances the scriptwriting process, facilitating iterative refinement while complementing, rather than replacing, their creative efforts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Script2Screen, an AI-assisted tool that integrates textual scriptwriting with a text-to-audiovisual-scene pipeline to generate expressive dialogue scenes featuring emotional speech, animated characters, gestures, and camera angles. Fine-grained UI controls allow writers to adjust these elements. A formative study with professional writers informed the design, and a subsequent user study with both novice and professional writers from various domains is claimed to demonstrate that the interactive audiovisual generation enhances the scriptwriting process, supports iterative refinement, and complements rather than replaces creative efforts.
Significance. If the empirical claims hold under closer scrutiny, the work could contribute to HCI by showing how synchronized multimodal AI generation can support creative workflows in scriptwriting, a domain traditionally limited to text. The emphasis on user-controllable elements like gestures and emotions represents a practical strength that could generalize to other narrative tools.
major comments (2)
- [User Study] User Study section: The abstract and available description state that the user study demonstrated enhancement of the scriptwriting process, but provide no sample size, quantitative metrics, study design details (e.g., within- or between-subjects control condition such as text-only baseline), objective measures (e.g., expert-rated dialogue quality, revision counts, or completion time), or statistical tests. This leaves the central claim dependent on unblinded self-report and vulnerable to novelty or demand effects.
- [Abstract and System Description] Abstract and System Description: The claim that AI-generated audiovisual outputs (emotional speech, gestures, camera angles) provide useful feedback rests on an assumption of sufficient accuracy and controllability, informed by a formative study. However, no details on generation quality, failure cases, or validation of the pipeline's reliability are supplied, which is load-bearing for whether the interactive loop aids rather than misleads writers.
minor comments (2)
- [Related Work] Consider expanding the related work section to include more citations on prior multimodal creative tools or dialogue generation systems to better contextualize the novelty of the synchronized workflow.
- [Figures] Ensure that any figures depicting the UI or pipeline include detailed captions that label all interactive controls and generation stages for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and indicate planned revisions to improve the clarity, rigor, and transparency of the work.
read point-by-point responses
-
Referee: [User Study] User Study section: The abstract and available description state that the user study demonstrated enhancement of the scriptwriting process, but provide no sample size, quantitative metrics, study design details (e.g., within- or between-subjects control condition such as text-only baseline), objective measures (e.g., expert-rated dialogue quality, revision counts, or completion time), or statistical tests. This leaves the central claim dependent on unblinded self-report and vulnerable to novelty or demand effects.
Authors: We agree that the user study presentation would benefit from greater detail and explicit discussion of its limitations. The study was exploratory and qualitative in focus, involving both novice and professional writers who completed dialogue writing tasks with the tool to observe iterative refinement. Data were gathered primarily through interviews, think-aloud protocols, and session observations rather than through controlled quantitative metrics or statistical testing. We will revise the User Study section to specify the participant count and backgrounds, clarify the within-subjects structure with opportunities for comparison to text-only writing, report any observable patterns (such as iteration frequency), and add an explicit discussion of reliance on self-reports along with potential biases including novelty and demand effects. This will better contextualize the claims without overstating the evidence. revision: partial
-
Referee: [Abstract and System Description] Abstract and System Description: The claim that AI-generated audiovisual outputs (emotional speech, gestures, camera angles) provide useful feedback rests on an assumption of sufficient accuracy and controllability, informed by a formative study. However, no details on generation quality, failure cases, or validation of the pipeline's reliability are supplied, which is load-bearing for whether the interactive loop aids rather than misleads writers.
Authors: The formative study with professional writers directly shaped the choice of controllable parameters in the text-to-audiovisual pipeline. Subsequent user study participants reported that the generated outputs supported their creative iteration despite imperfections. We acknowledge that the manuscript currently lacks explicit discussion of generation quality, failure modes, and pipeline validation. We will add a dedicated subsection (likely within System Description or Limitations) that describes the underlying models, reports observed quality characteristics from the studies, and enumerates common failure cases such as emotion-speech mismatches or gesture desynchronization, along with how the fine-grained UI controls allow users to correct or work around them. This will make the assumptions more transparent and demonstrate how the interactive loop remains useful even when outputs are imperfect. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
This is an applied HCI system paper describing an interactive tool (Script2Screen) and its evaluation via a user study with novice and professional writers. The abstract and available text contain no equations, mathematical derivations, fitted parameters, predictions, or first-principles results. Central claims rest on empirical user feedback about process enhancement and iterative refinement rather than any derivational chain. No self-citation load-bearing steps, ansatz smuggling, or reductions of outputs to inputs by construction are present. The paper is self-contained against external benchmarks (user study results) and receives a normal non-finding for circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Connecting textual and audiovisual modalities aids ideation and iteration in dialogue scriptwriting
Reference graph
Works this paper leans on
-
[1]
Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz
Saleema Amershi, Dan Weld, Mihaela Vorvoreanu, Adam Fourney, Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul N. Bennett, Kori Inkpen, Jaime Tee- van, Ruth Kikin-Gil, and Eric Horvitz. 2019. Guidelines for Human-AI Interaction. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems (Glasgow, Scotland Uk)(CHI ’19). Assoc...
-
[2]
Tenglong Ao, Qingzhe Gao, Yuke Lou, Baoquan Chen, and Libin Liu. 2022. Rhyth- mic Gesticulator: Rhythm-Aware Co-Speech Gesture Synthesis with Hierarchical Neural Embeddings.ACM Trans. Graph.41, 6, Article 209 (nov 2022), 19 pages. https://doi.org/10.1145/3550454.3555435
-
[3]
Bernstein, Greg Little, Robert C
Michael S. Bernstein, Greg Little, Robert C. Miller, Björn Hartmann, Mark S. Ackerman, David R. Karger, David Crowell, and Katrina Panovich. 2015. Soylent: a word processor with a crowd inside.Commun. ACM58, 8 (July 2015), 85–94. https://doi.org/10.1145/2791285
-
[4]
Stephen Brade, Bryan Wang, Mauricio Sousa, Sageev Oore, and Tovi Grossman
-
[5]
Promptify: Text-to-Image Generation through Interactive Prompt Explo- ration with Large Language Models. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology(San Francisco, CA, USA) (UIST ’23). Association for Computing Machinery, New York, NY, USA, Article 96, 14 pages. https://doi.org/10.1145/3586183.3606725
-
[6]
2010.Sketching user experiences: getting the design right and the right design
Bill Buxton. 2010.Sketching user experiences: getting the design right and the right design. Morgan kaufmann
work page 2010
-
[7]
Michelle Cavaleri and Saib Dianati. 2016. You want me to check your grammar again?: The usefulness of an online grammar checker as perceived by students. Journal of Academic Language and Learning10, 1 (2016), A223–A236
work page 2016
-
[8]
Kang Chen, Zhipeng Tan, Jin Lei, Song-Hai Zhang, Yuan-Chen Guo, Weidong Zhang, and Shi-Min Hu. 2021. ChoreoMaster: choreography-oriented music- driven dance synthesis.ACM Trans. Graph.40, 4, Article 145 (July 2021), 13 pages. https://doi.org/10.1145/3450626.3459932
-
[9]
Erin Cherry and Celine Latulipe. 2014. Quantifying the Creativity Support of Digital Tools through the Creativity Support Index.ACM Trans. Comput.-Hum. Interact.21, 4, Article 21 (June 2014), 25 pages. https://doi.org/10.1145/2617588
-
[10]
Jean-Peïc Chou, Alexa Fay Siu, Nedim Lipka, Ryan Rossi, Franck Dernoncourt, and Maneesh Agrawala. 2023. TaleStream: Supporting Story Ideation with Trope Knowledge. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. 1–12
work page 2023
-
[11]
John Joon Young Chung, Wooseok Kim, Kang Min Yoo, Hwaran Lee, Eytan Adar, and Minsuk Chang. 2022. TaleBrush: Sketching Stories with Generative Pretrained Language Models. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems(New Orleans, LA, USA)(CHI ’22). Association for Computing Machinery, New York, NY, USA, Article 209, 19 pag...
- [12]
-
[13]
Marc Davis. 2003. Active capture: integrating human-computer interaction and computer vision/audition to automate media capture. In2003 International Conference on Multimedia and Expo. ICME’03. Proceedings (Cat. No. 03TH8698), Vol. 2. IEEE, II–185
work page 2003
-
[14]
Rudresh Dwivedi, Devam Dave, Het Naik, Smiti Singhal, Rana Omer, Pankesh Patel, Bin Qian, Zhenyu Wen, Tejal Shah, Graham Morgan, et al. 2023. Explainable AI (XAI): Core ideas, techniques, and solutions.Comput. Surveys55, 9 (2023), 1–33
work page 2023
-
[15]
ElevenLabs. 2024. ElevenLabs. https://elevenlabs.io TTS generation web service
work page 2024
-
[16]
Michael L Epstein, Amber D Lazarus, Tammy B Calvano, Kelly A Matthews, Rachel A Hendel, Beth B Epstein, and Gary M Brosvic. 2002. Immediate feedback assessment technique promotes learning and corrects inaccurate first responses. The Psychological Record52 (2002), 187–201
work page 2002
-
[17]
2005.Screenplay: The foundations of screenwriting
Syd Field. 2005.Screenplay: The foundations of screenwriting. Delta
work page 2005
-
[18]
Troje, and Marc-André Carbonneau
Saeed Ghorbani, Ylva Ferstl, Daniel Holden, Nikolaus F. Troje, and Marc-André Carbonneau. 2023. ZeroEGGS: Zero-shot Example-based Gesture Generation from Speech.Computer Graphics Forum42, 1 (2023), 206–216. https://doi.org/10. 1111/cgf.14734 arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1111/cgf.14734
-
[19]
Chieh-Yang Huang, Shih-Hong Huang, and Ting-Hao Kenneth Huang. 2020. Heteroglossia: In-situ story ideation with the crowd. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems. 1–12
work page 2020
-
[20]
Qingqiu Huang, Yu Xiong, Anyi Rao, Jiaze Wang, and Dahua Lin. 2020. MovieNet: A Holistic Dataset for Movie Understanding. InComputer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IV(Glasgow, United Kingdom). Springer-Verlag, Berlin, Heidelberg, 709–727. https://doi.org/10.1007/978-3-030-58548-8_41
-
[21]
Paul Huffman and James Hutson. 2024. Enhancing History Education with Google NotebookLM: Case Study of Mary Easton Sibley’s Diary for Multimedia Content and Podcast Creation.ISRG Journal of Arts, Humanities and Social Sciences2, 5 (2024)
work page 2024
-
[22]
Maurice Jakesch, Advait Bhat, Daniel Buschek, Lior Zalmanson, and Mor Naaman
-
[23]
In Proceedings of the 2023 CHI conference on human factors in computing systems
Co-writing with opinionated language models affects users’ views. In Proceedings of the 2023 CHI conference on human factors in computing systems. 1–15
work page 2023
-
[24]
Zeyu Jin, Gautham J Mysore, Stephen Diverdi, Jingwan Lu, and Adam Finkelstein
-
[25]
Voco: Text-based insertion and replacement in audio narration.ACM Transactions on Graphics (TOG)36, 4 (2017), 1–13
work page 2017
-
[26]
Hye-Young Jo, Ryo Suzuki, and Yoonji Kim. 2024. CollageVis: Rapid Previsualiza- tion Tool for Indie Filmmaking using Video Collages. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA) (CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 164, 16 pages. https://doi.org/10.1145/3613904.3642575
-
[27]
Jun Kato, Kenta Hara, and Nao Hirasawa. 2024. Griffith: A Storyboarding Tool Designed with Japanese Animation Professionals. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 233, 14 pages. https://doi.org/10.1145/3613904.3642121
-
[28]
Script2Screen: Supporting Dialogue Scriptwriting with Interactive Audiovisual Generation•15
Eugene Kharitonov, Damien Vincent, Zalán Borsos, Raphaël Marinier, Sertan Girgin, Olivier Pietquin, Matt Sharifi, Marco Tagliasacchi, and Neil Zeghidour. Script2Screen: Supporting Dialogue Scriptwriting with Interactive Audiovisual Generation•15
-
[29]
Speak, read and prompt: High-fidelity text-to-speech with minimal super- vision.Transactions of the Association for Computational Linguistics11 (2023), 1703–1718
work page 2023
-
[30]
Han-Jong Kim, Chang Min Kim, and Tek-Jin Nam. 2018. SketchStudio: Experience Prototyping with 2.5-Dimensional Animated Design Scenarios. InProceedings of the 2018 Designing Interactive Systems Conference(Hong Kong, China)(DIS ’18). Association for Computing Machinery, New York, NY, USA, 831–843. https: //doi.org/10.1145/3196709.3196736
-
[31]
Philippe Laban, Elicia Ye, Srujay Korlakunta, John Canny, and Marti Hearst. 2022. Newspod: Automatic and interactive news podcasts. InProceedings of the 27th International Conference on Intelligent User Interfaces. 691–706
work page 2022
-
[32]
Stefan Larsson and Fredrik Heintz. 2020. Transparency in artificial intelligence. Internet policy review9, 2 (2020)
work page 2020
-
[33]
Mackenzie Leake, Abe Davis, Anh Truong, and Maneesh Agrawala. 2017. Com- putational video editing for dialogue-driven scenes.ACM Trans. Graph.36, 4, Article 130 (July 2017), 14 pages. https://doi.org/10.1145/3072959.3073653
-
[34]
Mackenzie Leake, Hijung Valentina Shin, Joy O. Kim, and Maneesh Agrawala. 2020. Generating Audio-Visual Slideshows from Text Articles Using Word Concreteness. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA)(CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–11. https://doi.org/10.1145/331...
-
[35]
Mina Lee, Percy Liang, and Qian Yang. 2022. CoAuthor: Designing a Human-AI Collaborative Writing Dataset for Exploring Language Model Capabilities. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems (New Orleans, LA, USA)(CHI ’22). Association for Computing Machinery, New York, NY, USA, Article 388, 19 pages. https://doi.org/1...
-
[36]
Susan Lin, Jeremy Warner, JD Zamfirescu-Pereira, Matthew G Lee, Sauhard Jain, Shanqing Cai, Piyawat Lertvittayakumjorn, Michael Xuelin Huang, Shumin Zhai, Björn Hartmann, et al . 2024. Rambler: Supporting Writing With Speech via LLM-Assisted Gist Manipulation. InProceedings of the CHI Conference on Human Factors in Computing Systems. 1–19
work page 2024
- [37]
-
[38]
Jiaju Ma, Li-Yi Wei, and Rubaiat Habib Kazi. 2022. A Layered Authoring Tool for Stylized 3D animations. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems(New Orleans, LA, USA)(CHI ’22). Association for Computing Machinery, New York, NY, USA, Article 383, 14 pages. https: //doi.org/10.1145/3491102.3501894
-
[39]
Marcel Marti, Jodok Vieli, Wojciech Witoń, Rushit Sanghrajka, Daniel Inversini, Diana Wotruba, Isabel Simo, Sasha Schriber, Mubbasir Kapadia, and Markus Gross
-
[40]
CARDINAL: Computer Assisted Authoring of Movie Scripts. InProceedings of the 23rd International Conference on Intelligent User Interfaces(Tokyo, Japan) (IUI ’18). Association for Computing Machinery, New York, NY, USA, 509–519. https://doi.org/10.1145/3172944.3172972
-
[41]
Justin Matejka, Michael Glueck, Erin Bradner, Ali Hashemi, Tovi Grossman, and George Fitzmaurice. 2018. Dream Lens: Exploration and Visualization of Large-Scale Generative Design Datasets. InProceedings of the 2018 CHI Conference on Human Factors in Computing Systems(Montreal QC, Canada) (CHI ’18). Association for Computing Machinery, New York, NY, USA, 1...
-
[42]
Robert McKee. 1997. Substance, structure, style, and the principles of screenwrit- ing.Alba Editorial(1997)
work page 1997
-
[43]
There’s so much responsibility on users right now:
Piotr Mirowski, Kory W. Mathewson, Jaylen Pittman, and Richard Evans. 2023. Co-Writing Screenplays and Theatre Scripts with Language Models: Evaluation by Industry Professionals. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 355, 34...
-
[44]
Bryan, Juan-Pablo Caceres, and Bryan Pardo
Max Morrison, Lucas Rencker, Zeyu Jin, Nicholas J. Bryan, Juan-Pablo Caceres, and Bryan Pardo. 2021. Context-Aware Prosody Correction for Text-Based Speech Editing. arXiv:2102.08328 [eess.AS] https://arxiv.org/abs/2102.08328
-
[45]
Daniel Naber et al. 2003. A rule-based style and grammar checker. (2003)
work page 2003
-
[46]
OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Amy Pavel, Gabriel Reyes, and Jeffrey P Bigham. 2020. Rescribe: Authoring and automatically editing audio descriptions. InProceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology. 747–759
work page 2020
- [48]
-
[49]
Anyi Rao, Jean-Peïc Chou, and Maneesh Agrawala. 2024. ScriptViz: A Visualiza- tion Tool to Aid Scriptwriting based on a Large Movie Database. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology
work page 2024
-
[50]
Anyi Rao, Xuekun Jiang, Yuwei Guo, Linning Xu, Lei Yang, Libiao Jin, Dahua Lin, and Bo Dai. 2023. Dynamic Storyboard Generation in an Engine-based Virtual Environment for Video Production. InACM SIGGRAPH 2023 Posters(Los Angeles, CA, USA)(SIGGRAPH ’23). Association for Computing Machinery, New York, NY, USA, Article 40, 2 pages. https://doi.org/10.1145/35...
-
[51]
Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. 2019. Fastspeech: Fast, robust and controllable text to speech.Advances in neural information processing systems32 (2019)
work page 2019
-
[52]
Mohi Reza, Nathan M Laundry, Ilya Musabirov, Peter Dushniku, Zhi Yuan “Michael” Yu, Kashish Mittal, Tovi Grossman, Michael Liut, Anastasia Kuzminykh, and Joseph Jay Williams. 2024. ABScribe: Rapid Exploration & Organization of Multiple Writing Variations in Human-AI Co-Writing Tasks using Large Language Models. InProceedings of the 2024 CHI Conference on ...
-
[53]
Steve Rubin and Maneesh Agrawala. 2014. Generating emotionally relevant musical scores for audio stories. InProceedings of the 27th annual ACM symposium on User interface software and technology. 439–448
work page 2014
-
[54]
Steve Rubin, Floraine Berthouzoz, Gautham J Mysore, and Maneesh Agrawala
-
[55]
InProceedings of the 28th Annual ACM Symposium on User Interface Software & Technology
Capture-time feedback for recording scripted narration. InProceedings of the 28th Annual ACM Symposium on User Interface Software & Technology. 191–199
-
[56]
Steve Rubin, Floraine Berthouzoz, Gautham J Mysore, Wilmot Li, and Maneesh Agrawala. 2013. Content-based tools for editing audio stories. InProceedings of the 26th annual ACM symposium on User interface software and technology. 113–122
work page 2013
-
[57]
Prem Seetharaman, Gautham Mysore, Bryan Pardo, Paris Smaragdis, and Celso Gomes. 2019. Voiceassist: Guiding users to high-quality voice recordings. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems. 1–6
work page 2019
-
[58]
Hijung Valentina Shin, Wilmot Li, and Frédo Durand. 2016. Dynamic authoring of audio with linked scripts. InProceedings of the 29th Annual Symposium on User Interface Software and Technology. 509–516
work page 2016
-
[59]
Daxin Tan, Liqun Deng, Yu Ting Yeung, Xin Jiang, Xiao Chen, and Tan Lee
-
[60]
In2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU)
Editspeech: A text based speech editing system using partial inference and bidirectional fusion. In2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 626–633
-
[61]
Shrikant Venkataramani, Paris Smaragdis, and Gautham Mysore. 2017. AutoDub: Automatic Redubbing for Voiceover Editing. InProceedings of the 30th Annual ACM Symposium on User Interface Software and Technology. 533–538
work page 2017
-
[62]
Bryan Wang, Zeyu Jin, and Gautham Mysore. 2022. Record Once, Post Every- where: Automatic Shortening of Audio Stories for Social Media. InProceedings of the 35th Annual ACM Symposium on User Interface Software and Technology. 1–11
work page 2022
-
[63]
Bryan Wang, Yuliang Li, Zhaoyang Lv, Haijun Xia, Yan Xu, and Raj Sodhi. 2024. LAVE: LLM-Powered Agent Assistance and Language Augmentation for Video Editing. InProceedings of the 29th International Conference on Intelligent User Interfaces(Greenville, SC, USA)(IUI ’24). Association for Computing Machinery, New York, NY, USA, 699–714. https://doi.org/10.11...
-
[64]
Bryan Wang, Meng Yu Yang, and Tovi Grossman. 2021. Soloist: Generating mixed-initiative tutorials from existing guitar instructional videos through au- dio processing. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 1–14
work page 2021
-
[65]
Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, et al . 2017. Tacotron: Towards end-to-end speech synthesis.arXiv preprint arXiv:1703.10135 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[66]
Zhijie Wang, Yuheng Huang, Da Song, Lei Ma, and Tianyi Zhang. 2024. PromptCharm: Text-to-Image Generation through Multi-modal Prompting and Refinement. InProceedings of the 2024 CHI Conference on Human Factors in Com- puting Systems
work page 2024
-
[67]
Haijun Xia. 2020. Crosspower: Bridging Graphics and Linguistics. InProceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology. 722–734
work page 2020
-
[68]
Haijun Xia, Jennifer Jacobs, and Maneesh Agrawala. 2020. Crosscast: Adding Visuals to Audio Travel Podcasts. InProceedings of the 33rd Annual ACM Sympo- sium on User Interface Software and Technology(Virtual Event, USA)(UIST ’20). Association for Computing Machinery, New York, NY, USA, 735–746. https: //doi.org/10.1145/3379337.3415882
-
[69]
Ann Yuan, Andy Coenen, Emily Reif, and Daphne Ippolito. 2022. Wordcraft: story writing with large language models. InProceedings of the 27th International Conference on Intelligent User Interfaces. 841–852
work page 2022
-
[70]
Yeshuang Zhu, Shichao Yue, Chun Yu, and Yuanchun Shi. 2017. CEPT: Collabora- tive editing tool for non-native authors. InProceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing. 273–285. 16•Wang, et al. A PROMPT DESIGN AND EXAMPLES In this appendix, we present the detailed prompts and examples used for suggesting...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.