Generative Adaptation of Dynamics to Environmental Shifts via Weight-space Diffusion
Pith reviewed 2026-05-22 14:53 UTC · model grok-4.3
The pith
DynaDiff adapts dynamics models to environmental shifts by generating weights directly via diffusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
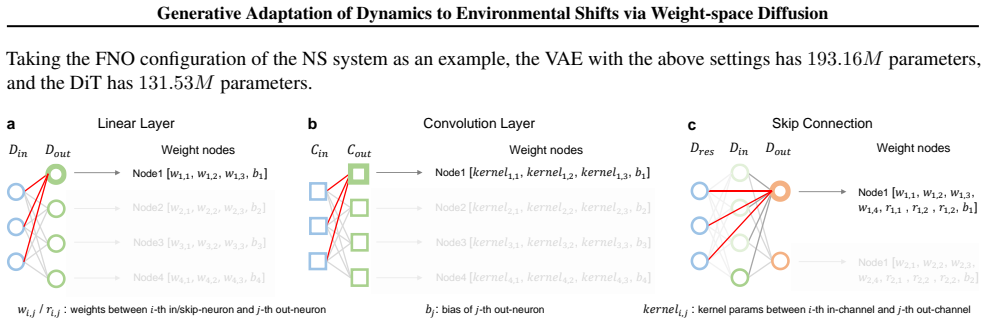
The central discovery is a framework called DynaDiff that first converts expert predictor weights into weight graphs analyzed by multi-head attention to capture topological couplings, then enforces consistency with expert physical behavior through a functional loss, and finally conditions a diffusion model using features extracted by a dynamics-informed prompter from observation sequences to generate adapted models for new environments.
What carries the argument
Weight graphs processed by multi-head attention within a diffusion model conditioned by a dynamics-informed prompter and regularized by a functional loss.
If this is right
- Generated models achieve higher prediction accuracy, with experiments showing an average improvement of 10.78% over baselines.
- Fine-tuning overhead is amortized into a single offline cost for building a model zoo of experts.
- New environments can be handled more efficiently, especially under hardware or data constraints.
- The paradigm shifts from gradient-based adaptation to direct generative creation of models.
Where Pith is reading between the lines
- Similar techniques might help in other areas where models need quick adaptation, such as control systems or forecasting.
- Building larger zoos of diverse experts could improve the quality of generations for a wider range of shifts.
- Integrating this with online learning could allow continuous improvement as more data arrives in the new environment.
Load-bearing premise
That enforcing consistency via the functional loss on physical behavior and capturing couplings via attention on weight graphs is enough for the generated models to perform well in shifted environments.
What would settle it
If a controlled experiment introducing a known environmental shift shows that DynaDiff-generated models have lower accuracy than a model fine-tuned on data from the new environment, the advantage of the generative approach would be questioned.
Figures











read the original abstract
Data-driven dynamics prediction often fails under environmental shifts, while traditional fine-tuning remains computationally prohibitive for hardware-constrained or data-scarce applications. We propose DynaDiff, a generative meta-learning framework that transitions the paradigm from gradient-based tuning or modulation to direct weight-space generation. Specifically, we first abstract expert weights as novel weight graphs, utilizing multi-head attention to explicitly capture topological coupling within weights. Subsequently, we design a functional loss to ensure that the generated models achieve consistency with expert models in physical behavior. Finally, we develop a dynamics-informed prompter that extracts cross-domain physical and spectral features from observation sequences to condition the diffusion model. Experiments demonstrate that DynaDiff boosts average prediction accuracy by 10.78% over competitive baselines. Furthermore, by pre-constructing a model zoo of expert predictors, we amortize the fine-tuning overhead into a one-time offline cost, significantly boosting deployment efficiency in new environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DynaDiff, a generative meta-learning framework for adapting dynamics prediction models to environmental shifts via weight-space diffusion. Expert weights are abstracted as graphs processed by multi-head attention to capture topological couplings; a functional loss enforces consistency with expert physical behavior; and a dynamics-informed prompter extracts cross-domain physical and spectral features to condition the diffusion model. The central claims are a 10.78% average prediction accuracy improvement over competitive baselines and efficiency gains achieved by pre-constructing a model zoo of expert predictors, amortizing fine-tuning into a one-time offline cost.
Significance. If the empirical claims and physical-consistency mechanism hold, the work could meaningfully advance meta-learning for dynamical systems in data-scarce or hardware-constrained settings by replacing gradient-based adaptation with direct generative weight synthesis. The model-zoo amortization strategy is a practical strength that directly addresses deployment efficiency under shifts.
major comments (2)
- [Abstract] Abstract: The functional loss is described only as ensuring 'consistency with expert models in physical behavior' with no mention of explicit terms for governing equations, conservation laws, residual checks, or spectral invariants. If the loss reduces to generic output-space matching on observed trajectories, generated weights could overfit the training distribution while producing unphysical trajectories on shifted regimes, directly undermining the central adaptation claim.
- [Abstract] Abstract: The claim that multi-head attention on weight graphs 'explicitly captures topological coupling within weights' is presented without describing the graph-construction procedure from raw weights or showing that the resulting inductive biases match those of the original dynamics architecture. This construction is load-bearing for preserving physical behavior during generation.
minor comments (1)
- [Abstract] Abstract: The 10.78% accuracy gain is reported without naming the specific baselines, datasets, or statistical measures (error bars, number of runs). These details belong in the experiments section to allow assessment of robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below in a point-by-point manner and indicate where revisions will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: The functional loss is described only as ensuring 'consistency with expert models in physical behavior' with no mention of explicit terms for governing equations, conservation laws, residual checks, or spectral invariants. If the loss reduces to generic output-space matching on observed trajectories, generated weights could overfit the training distribution while producing unphysical trajectories on shifted regimes, directly undermining the central adaptation claim.
Authors: We agree that the abstract is high-level and does not enumerate the specific terms. Section 3.3 of the manuscript defines the functional consistency loss with explicit components: PDE residual penalties, integral constraints enforcing conservation laws, and frequency-domain spectral matching. These terms are designed to promote physical behavior beyond simple trajectory matching. We will revise the abstract to include a concise reference to these physics-informed elements. revision: yes
-
Referee: [Abstract] Abstract: The claim that multi-head attention on weight graphs 'explicitly captures topological coupling within weights' is presented without describing the graph-construction procedure from raw weights or showing that the resulting inductive biases match those of the original dynamics architecture. This construction is load-bearing for preserving physical behavior during generation.
Authors: The referee is correct that the abstract omits procedural details. Section 3.2 specifies the graph construction: weight tensors are mapped to nodes with edges derived from layer connectivity and parameter-sharing patterns in the source architecture; multi-head attention then operates on this graph. Ablation studies in Section 4 confirm retention of the original inductive biases. We will add a brief clarifying clause to the abstract describing the abstraction step. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes a generative meta-learning approach that abstracts expert weights into graphs, applies multi-head attention, introduces a functional loss for behavioral consistency, and uses a dynamics-informed prompter to condition a diffusion model. Reported accuracy gains of 10.78% are presented as outcomes of experimental comparisons against baselines, with the model zoo amortizing costs offline. No load-bearing step reduces by the paper's own equations or self-citations to a fitted parameter or self-referential definition; the generative process and loss terms are independent of the final performance metrics, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- diffusion model conditioning features
axioms (2)
- domain assumption Abstracting expert weights as weight graphs allows multi-head attention to capture topological coupling
- domain assumption Functional loss guarantees physical behavior consistency between generated and expert models
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we design a functional loss to ensure that the generated models achieve consistency with expert models in physical behavior... L_func = E ||f_ŵ(x_i) - f_w(x_i)||²
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
abstract expert weights as novel weight graphs, utilizing multi-head attention to explicitly capture topological coupling
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learning Dynamical Systems from Partial Observations
Ayed, I., de B´ezenac, E., Pajot, A., Brajard, J., and Gallinari, P. Learning dynamical systems from partial observations. arXiv preprint arXiv:1902.11136,
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[2]
Bedionita, S., Andreis, B., Lee, H., Jeong, W., Chong, S., Hutter, F., and Hwang, S. J. Diffusion-based neu- ral network weights generation. In13th International Conference on Learning Representations, ICLR 2025, pp. 47860–47891. International Conference on Learning Representations, ICLR,
work page 2025
- [3]
-
[4]
Chen, T., Zhou, H., Li, Y ., Wang, H., Gao, C., Shi, R., Zhang, S., and Li, J. Building flexible machine learning models for scientific computing at scale.arXiv preprint arXiv:2402.16014, 2024a. Chen, W., Song, J., Ren, P., Subramanian, S., Morozov, D., and Mahoney, M. W. Data-efficient operator learning via unsupervised pretraining and in-context learnin...
-
[5]
Ding, J., Liu, C., Zheng, Y ., Zhang, Y ., Yu, Z., Li, R., Chen, H., Piao, J., Wang, H., Liu, J., et al. Artificial intelligence for complex network: Potential, methodology and application.arXiv preprint arXiv:2402.16887,
-
[6]
Dupont, E., Kim, H., Eslami, S., Rezende, D., and Rosen- baum, D. From data to functa: Your data point is a function and you can treat it like one.arXiv preprint arXiv:2201.12204,
-
[7]
Kofinas, M., Knyazev, B., Zhang, Y ., Chen, Y ., Burghouts, G. J., Gavves, E., Snoek, C. G., and Zhang, D. W. Graph neural networks for learning equivariant representations of neural networks.arXiv preprint arXiv:2403.12143,
-
[8]
Koupa¨ı, A. K., Benet, J. M., Yin, Y ., Vittaut, J.-N., and Gallinari, P. Geps: Boosting generalization in parametric pde neural solvers through adaptive conditioning.arXiv preprint arXiv:2410.23889,
-
[9]
Li, D., Wu, A., Li, Y ., Wang, Y ., and Han, Y . Continual adap- tation: Environment-conditional parameter generation for object detection in dynamic scenarios. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4434–4443, 2025a. Li, R., Cheng, J., Wang, H., Liao, Q., and Li, Y . Predicting the dynamics of complex system via mu...
-
[10]
Drag- and-drop llms: Zero-shot prompt-to-weights
Liang, Z., Tang, D., Zhou, Y ., Zhao, X., Shi, M., Zhao, W., Li, Z., Wang, P., Sch ¨urholt, K., Borth, D., et al. Drag- and-drop llms: Zero-shot prompt-to-weights. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. Liang, Z., Tang, D., Zhou, Y ., Zhao, X., Shi, M., Zhao, W., Li, Z., Wang, P., Sch¨urholt, K., Borth, D., et al. D...
-
[11]
Liu, J., Li, R., Wang, H., Yu, Z., Liu, C., Ding, J., and Li, Y . Beyond equilibrium: Non-equilibrium foundations should underpin generative processes in complex dynam- ical systems.arXiv preprint arXiv:2505.18621,
-
[12]
Meynent, L., Melev, I., Sch¨urholt, K., Kauermann, G., and Borth, D. Structure is not enough: Leveraging behavior for neural network weight reconstruction.arXiv preprint arXiv:2503.17138,
-
[13]
Nzoyem, R. D., Barton, D. A., and Deakin, T. Neural context flows for meta-learning of dynamical systems. arXiv preprint arXiv:2405.02154,
-
[14]
Shape generation via weight space learning.arXiv preprint arXiv:2503.21830,
Plattner, M., Berzins, A., and Brandstetter, J. Shape generation via weight space learning.arXiv preprint arXiv:2503.21830,
-
[15]
Rahman, M. A., Ross, Z. E., and Azizzadenesheli, K. U-no: U-shaped neural operators.arXiv preprint arXiv:2204.11127,
- [16]
-
[17]
Plug- and-play diffusion features for text-driven image-to- image translation
Tumanyan, N., Geyer, M., Bagon, S., and Dekel, T. Plug- and-play diffusion features for text-driven image-to- image translation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pp. 1921–1930,
work page 1921
-
[18]
Neural network diffusion.arXiv preprint arXiv:2402.13144,
Wang, K., Tang, D., Zeng, B., Yin, Y ., Xu, Z., Zhou, Y ., Zang, Z., Darrell, T., Liu, Z., and You, Y . Neural network diffusion.arXiv preprint arXiv:2402.13144,
-
[19]
Recurrent diffusion for large-scale parameter generation.arXiv preprint arXiv:2501.11587,
Wang, K., Tang, D., Zhao, W., Sch ¨urholt, K., Wang, Z., and You, Y . Recurrent diffusion for large-scale parameter generation.arXiv preprint arXiv:2501.11587,
-
[20]
Yuan, Y ., Shao, C., Ding, J., Jin, D., and Li, Y . Spatio- temporal few-shot learning via diffusive neural network generation.arXiv preprint arXiv:2402.11922,
-
[21]
Zero-shot forecasting of network dynamics through weight flow matching
Zhou, S., Li, R., Wang, H., and Li, Y . Zero-shot forecasting of network dynamics through weight flow matching. In Proceedings of the ACM Web Conference 2026, pp. 1540– 1550,
work page 2026
-
[22]
13 Generative Adaptation of Dynamics to Environmental Shifts via Weight-space Diffusion Supplementary Material A. Limitations & Future Work DynaDiff currently generates expert models of a fixed architecture, which may not be optimal for all possible environmental complexities. A promising future direction is to extend the generative paradigm to synthesize...
work page 2024
-
[23]
The second approach is meta-learning (Finn et al., 2017)
employed more advanced architectures to improve computational efficiency and approximation capabilities. The second approach is meta-learning (Finn et al., 2017). These methods capture cross-environment invariants through environment-shared weights and fine-tune environment-specific weights or contexts on limited data from new environments for adaptation,...
work page 2017
-
[24]
frame differential equation forward and inverse problems as natural language statements, pre-train transformers, and provide solution examples for new environments as context to enhance model performance. Compared to these works, we innovatively treat the complete model weights as generated objects and explicitly model their joint distribution with the en...
work page 2024
-
[25]
employ urban knowledge graph as prompts to guide diffusion for generating spatio-temporal prediction model weights for new cities. Zhang et al. (2024) replace the inner loop gradient updates of the meta learning with diffusion-generated weights. Xie et al. (2024) improve test-time generalization on time-varying systems by weight generation. Recent works (...
work page 2024
-
[26]
The Cylinder flow system is simulated using the lattice Boltzmann method (LBM) (Vlachas et al., 2022), with dynamics governed by the Navier-Stokes equations for turbulent flow around a cylindrical obstacle. The system is discretized using a lattice velocity grid, and the relaxation time is determined based on the kinematic viscosity and Reynolds number. D...
work page 2022
-
[27]
Additionally, we report the storage overhead of the model zoo and the hyperparameter settings during generation. During training, we uniformly use the Adam optimizer with a learning rate of 1e−4, and other parameters are set to their default values. Table 4.Detailed settings of the model zoo for each systems. Cylinder flow Lambda–Omega Kolmgorov Flow Navi...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.