Cache Your Prompt When It's Green: Carbon-Aware Caching for Large Language Model Serving
Pith reviewed 2026-05-19 13:09 UTC · model grok-4.3
The pith
GreenCache cuts carbon from LLM serving by dynamically trading storage costs against compute savings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GreenCache derives time-varying resource allocation plans by analyzing the observed correlation between carbon emission and SLO satisfaction, allowing it to reconfigure cache and storage resources under changing workloads so that total carbon falls while latency constraints continue to hold for the large majority of requests.
What carries the argument
Carbon-SLO correlation analysis that periodically produces new resource allocation plans balancing embodied storage carbon against operational compute savings.
If this is right
- Caching decisions must explicitly account for embodied carbon in high-speed SSDs once models reach 70B scale or larger.
- Resource reconfigurations can be recomputed on the fly to keep the carbon-latency balance under real workload variation.
- Operational carbon saved by KV-cache reuse can be quantified against storage costs to produce net emission reductions.
- The same correlation-driven approach can be applied across different regional electricity grids with varying carbon intensity.
Where Pith is reading between the lines
- Operators could pre-position caches during forecasted low-carbon periods if carbon-intensity forecasts were fed into the allocation planner.
- The embodied-versus-operational tradeoff logic may transfer to other storage-intensive AI services such as retrieval-augmented generation systems.
- Hardware vendors could use the framework's carbon accounting to guide development of lower-embodied-carbon persistent storage for inference clusters.
Load-bearing premise
Carbon emissions and latency performance remain reliably correlated enough that measured relationships can drive reconfigurations that lower emissions without violating service targets.
What would settle it
A workload trace in which the measured carbon-SLO correlation no longer predicts actual emissions or latency after reconfiguration, causing either higher total carbon or more than 10 percent of requests to miss their latency bounds.
Figures







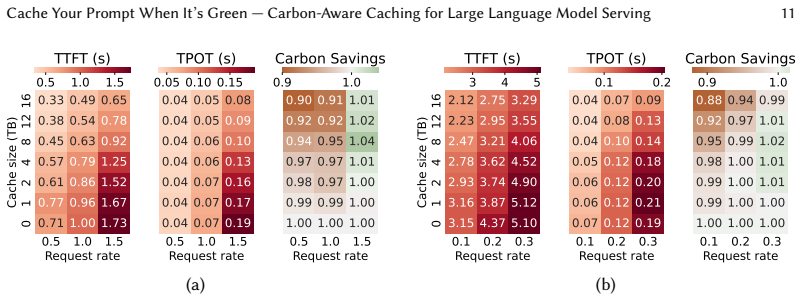

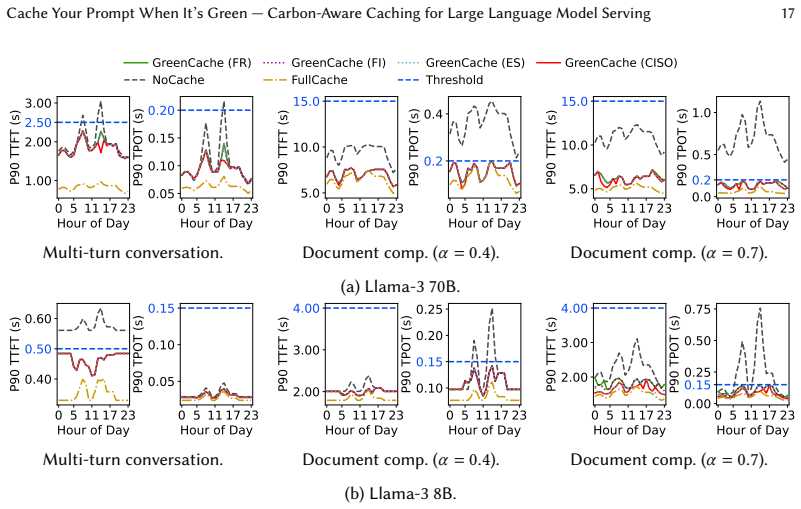



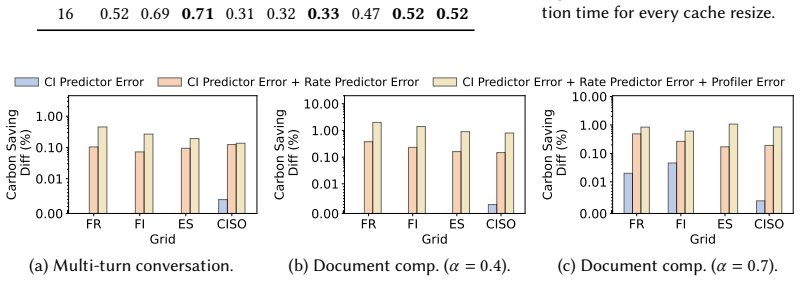



read the original abstract
As large language models (LLMs) become widely used, their environmental impact, especially carbon emission, has attracted more attention. Prior studies focus on compute-related carbon emissions. In this paper, we find that storage is another key contributor. LLM caching, which saves and reuses KV caches for repeated context, reduces operational carbon by avoiding redundant computation. However, this benefit comes at the cost of embodied carbon from high-capacity, high-speed SSDs. As LLMs scale, the embodied carbon of storage grows significantly. To address this tradeoff, we present GreenCache, a carbon-aware cache management framework that dynamically derives resource allocation plans for LLM serving. GreenCache analyzes the correlation between carbon emission and SLO satisfaction, reconfiguring the resource over time to keep the balance between SLO and carbon emission under dynamic workloads. Evaluations from real traces demonstrate that GreenCache achieves an average carbon reduction of 15.1 % when serving Llama-3 70B in the FR grid, with reductions reaching up to 25.3 %, while staying within latency constraints for > 90 % of requests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GreenCache, a carbon-aware cache management framework for LLM serving. It dynamically derives resource allocation plans by analyzing correlations between carbon emissions and SLO satisfaction, reconfiguring resources to balance operational carbon savings from KV-cache reuse against embodied carbon costs of high-capacity SSDs under dynamic workloads. Evaluations on real traces report an average 15.1% carbon reduction (up to 25.3%) for Llama-3 70B in the FR grid while maintaining latency constraints for >90% of requests.
Significance. If the embodied-carbon modeling and dynamic reconfiguration hold, the result is significant because it extends carbon awareness beyond compute to storage decisions in LLM inference, an area that grows with model scale. The use of real traces for concrete percentage reductions and the net-carbon signal for cache sizing provide practical, falsifiable evidence that could guide sustainable serving systems.
major comments (2)
- [§5 Evaluation] §5 Evaluation, results for Llama-3 70B: the headline 15.1% (max 25.3%) net carbon reduction is computed as operational savings minus embodied carbon of additional high-capacity SSDs. The manuscript provides no sensitivity sweep on amortization horizon, utilization factor, or manufacturing carbon intensity; these parameters directly determine whether the embodied term is non-negligible and whether the reported percentages remain valid.
- [§4.2] §4.2 Dynamic reconfiguration: the logic that keeps >90% SLO compliance while using the net-carbon signal assumes the carbon-SLO correlation can be reliably measured and acted upon under bursty workloads. No concrete description or pseudocode is given for how the correlation is estimated or how error in that estimate propagates to the reconfiguration decisions.
minor comments (2)
- [Abstract] Abstract: 'FR grid' is used without expansion on first occurrence; a parenthetical definition would improve readability.
- [Evaluation] Figure captions in the evaluation section could explicitly state the number of trace runs and whether error bars represent standard deviation or min/max across runs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of robustness and clarity in our carbon-aware caching framework. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of results and algorithmic details.
read point-by-point responses
-
Referee: [§5 Evaluation] §5 Evaluation, results for Llama-3 70B: the headline 15.1% (max 25.3%) net carbon reduction is computed as operational savings minus embodied carbon of additional high-capacity SSDs. The manuscript provides no sensitivity sweep on amortization horizon, utilization factor, or manufacturing carbon intensity; these parameters directly determine whether the embodied term is non-negligible and whether the reported percentages remain valid.
Authors: We agree that a sensitivity analysis on amortization horizon, SSD utilization, and manufacturing carbon intensity would improve the robustness of the net-carbon claims. In the revised manuscript we will add an appendix with sweeps over amortization periods of 1–5 years, utilization factors from 30% to 80%, and manufacturing intensities drawn from multiple sources (e.g., US, EU, and global averages). The new results will show that the reported 15.1% average (up to 25.3%) reduction remains positive and statistically significant across the tested ranges, while also identifying the boundary conditions under which the embodied term becomes dominant. revision: yes
-
Referee: [§4.2] §4.2 Dynamic reconfiguration: the logic that keeps >90% SLO compliance while using the net-carbon signal assumes the carbon-SLO correlation can be reliably measured and acted upon under bursty workloads. No concrete description or pseudocode is given for how the correlation is estimated or how error in that estimate propagates to the reconfiguration decisions.
Authors: We acknowledge that §4.2 currently lacks an explicit algorithmic description. In the revision we will expand this section with (i) a step-by-step description of the correlation estimator that uses a sliding window over recent request traces to compute Pearson correlation between per-request carbon cost and SLO violation probability, (ii) pseudocode for the estimator and the subsequent resource-reconfiguration rule, and (iii) a short error-propagation analysis that injects Gaussian noise into the correlation estimate and reports the resulting SLO compliance distribution. These additions will demonstrate that the >90% compliance threshold is preserved even under moderate estimation error typical of bursty workloads. revision: yes
Circularity Check
No circularity; results are empirical evaluations on external traces
full rationale
The paper introduces GreenCache as a dynamic resource reconfiguration framework driven by observed correlations between carbon emissions and SLO satisfaction. All reported outcomes (15.1 % average reduction, up to 25.3 %, >90 % SLO compliance) are obtained directly from trace-driven experiments on real workloads for Llama-3 70B. No equations, predictions, or first-principles derivations are presented that reduce by construction to fitted parameters, self-definitions, or self-citations. The embodied-carbon tradeoff is treated as an input measurement rather than a derived result, so the central claims remain independent of any circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Storage embodied carbon from high-capacity SSDs is a significant and quantifiable contributor that can be dynamically traded against compute carbon savings
Reference graph
Works this paper leans on
-
[1]
Bilge Acun, Benjamin Lee, Fiodar Kazhamiaka, Kiwan Maeng, Udit Gupta, Manoj Chakkaravarthy, David Brooks, and Carole-Jean Wu. 2023. Carbon Explorer: A Holistic Framework for Designing Carbon Aware Datacenters. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). Associat...
-
[2]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 2024). USENIX Association, Santa Clara, CA, USA, 117–134. https://w...
work page 2024
-
[3]
Azure. 2024. Azure LLM inference trace 2024. https://github.com/Azure/AzurePublicDataset/blob/master/ AzureLLMInferenceDataset2024.md
work page 2024
-
[4]
Fu Bang. 2023. GPTCache: An Open-Source Semantic Cache for LLM Applications Enabling Faster Answers and Cost Savings. InProceedings of the 3rd Workshop for Natural Language Processing Open Source Software (NLP-OSS 2023). Association for Computational Linguistics, Singapore, 212–218. doi:10.18653/v1/2023.nlposs-1.24
-
[5]
Noman Bashir, Varun Gohil, Anagha Belavadi Subramanya, Mohammad Shahrad, David Irwin, Elsa Olivetti, and Christina Delimitrou. 2024. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon- Aware Scheduling. InProceedings of the 2024 ACM Symposium on Cloud Computing (SoCC). Association for Computing Machinery, New York, NY, USA, ...
-
[6]
Benjamin Berg, Daniel S. Berger, Sara McAllister, Isaac Grosof, Sathya Gunasekar, Jimmy Lu, Michael Uhlar, Jim Carrig, Nathan Beckmann, Mor Harchol-Balter, and Gregory R. Ganger. 2020. The CacheLib Caching Engine: Design and Experiences at Scale. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX Association, Virtual, 75...
work page 2020
-
[7]
Anvita Bhagavathula, Leo Han, and Udit Gupta. 2024. Understanding the Implications of Uncertainty in Embodied Carbon Models for Sustainable Computing. InWorkshop on Sustainable Computer Systems (HotCarbon). ACM, New York, NY, USA, 1–7
work page 2024
-
[8]
Hendrik Borghorst. 2018. rapl-read-ryzen. https://github.com/djselbeck/rapl-read-ryzen
work page 2018
-
[9]
L. Breslau, Pei Cao, Li Fan, G. Phillips, and S. Shenker. 1999. Web caching and Zipf-like distributions: evidence and implications. InIEEE INFOCOM ’99. Conference on Computer Communications. Proceedings. Eighteenth Annual Joint Conference of the IEEE Computer and Communications Societies. The Future is Now (Cat. No.99CH36320), Vol. 1. IEEE Computer Societ...
-
[10]
Zhiliang Chen, Xinyuan Niu, Chuan-Sheng Foo, and Bryan Kian Hsiang Low. 2025. Broaden your SCOPE! Efficient Multi-turn Conversation Planning for LLMs with Semantic Space. InThe Thirteenth International Conference on Learning Representations (ICLR). OpenReview.net, Singapore. https://openreview.net/forum?id=3cgMU3TyyE
work page 2025
- [11]
-
[12]
COIN-OR Foundation. 2005–. CBC (Coin-or branch and cut) solver. https://github.com/coin-or/Cbc. Open-source MILP solver from the COIN-OR project
work page 2005
-
[13]
Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y
Damai Dai, Chengqi Deng, Chenggang Zhao, R.x. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, Zhenda Xie, Y.k. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. 2024. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. InProceedings of the 62nd Annual Meeting of the Assoc...
-
[14]
DeepSeek. 2025. DeepSeek. https://chat.deepseek.com/
work page 2025
-
[15]
Dell Technologies. 2019. Life Cycle Assessment of Dell R740. https://www.delltechnologies.com/asset/en-us/products/ servers/technical-support/Full_LCA_Dell_R740.pdf. 24 Yuyang Tian, Desen Sun, Yi Ding, and Sihang Liu
work page 2019
-
[16]
Yi Ding and Tianyao Shi. 2024. Sustainable LLM Serving: Environmental Implications, Challenges, and Opportunities. In2024 IEEE 15th International Green and Sustainable Computing Conference (IGSC). IEEE, IEEE, Austin, TX, USA, 37–38
work page 2024
-
[17]
Hang Du, Guoshun Nan, Sicheng Zhang, Binzhu Xie, Junrui Xu, Hehe Fan, Qimei Cui, Xiaofeng Tao, and Xudong Jiang
-
[18]
DocMSU: A Comprehensive Benchmark for Document-Level Multimodal Sarcasm Understanding.Proceedings of the AAAI Conference on Artificial Intelligence38, 16 (Mar. 2024), 17933–17941. doi:10.1609/aaai.v38i16.29748
-
[19]
Electricity Maps. 2025. Electricity Maps. https://www.electricitymap.org/map/
work page 2025
-
[20]
Ahmad Faiz, Sotaro Kaneda, Ruhan Wang, Rita Chukwunyere Osi, Prateek Sharma, Fan Chen, and Lei Jiang. 2024. LLMCarbon: Modeling the End-to-End Carbon Footprint of Large Language Models. InThe Twelfth International Conference on Learning Representations (ICLR). OpenReview.net, Vienna, Austria. https://openreview.net/forum?id= aIok3ZD9to
work page 2024
-
[21]
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. 2024. Cost-Efficient Large Language Model Serving for Multi-turn Conversations with CachedAttention. InUSENIX Annual Technical Conference (ATC). USENIX Association, Santa Clara, CA, 111–126. https://www.usenix. org/conference/atc24/present...
work page 2024
-
[22]
Shiwei Gao, Youmin Chen, and Jiwu Shu. 2025. Fast State Restoration in LLM Serving with HCache. InProceedings of the Twentieth European Conference on Computer Systems (EuroSys). Association for Computing Machinery, New York, NY, USA, 128–143. doi:10.1145/3689031.3696072
-
[23]
Phillipa Gill, Martin Arlitt, Zongpeng Li, and Anirban Mahanti. 2007. YouTube Traffic Characterization: A View from the Edge. InProceedings of the 7th ACM SIGCOMM Conference on Internet Measurement (IMC). Association for Computing Machinery, New York, NY, USA, 15–28. doi:10.1145/1298306.1298310
-
[24]
GitHub. 2024. copilot. https://github.com/features/copilot
work page 2024
-
[25]
Google. 2024. Gemini. https://gemini.google.com/app
work page 2024
-
[26]
Sarah Griffiths. 2020. Why your internet habits are not as clean as you think. https://www.bbc.com/future/article/ 20200305-why-your-internet-habits-are-not-as-clean-as-you-think
work page 2020
-
[27]
Lee, David Brooks, and Carole-Jean Wu
Udit Gupta, Mariam Elgamal, Gage Hills, Gu-Yeon Wei, Hsien-Hsin S. Lee, David Brooks, and Carole-Jean Wu. 2022. ACT: Designing Sustainable Computer Systems with An Architectural Carbon Modeling Tool. InProceedings of the 49th Annual International Symposium on Computer Architecture (ISCA). Association for Computing Machinery, New York, NY, USA, 784–799. do...
-
[28]
Leo Han, Jash Kakadia, Benjamin C. Lee, and Udit Gupta. 2025. Fair-CO2: Fair Attribution for Cloud Carbon Emissions. InProceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA). Association for Computing Machinery, New York, NY, USA, 646–663. doi:10.1145/3695053.3731023
-
[29]
Syed Hasan, Sergey Gorinsky, Constantine Dovrolis, and Ramesh K. Sitaraman. 2014. Trade-offs in optimizing the cache deployments of CDNs. InIEEE INFOCOM 2014 - IEEE Conference on Computer Communications. IEEE, Toronto, Canada, 460–468. doi:10.1109/INFOCOM.2014.6847969
-
[30]
Qi Huang, Ken Birman, Robbert van Renesse, Wyatt Lloyd, Sanjeev Kumar, and Harry C. Li. 2013. An analysis of Facebook photo caching. InProceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles (SOSP). Association for Computing Machinery, New York, NY, USA, 167–181. doi:10.1145/2517349.2522722
-
[31]
Hugging Face. 2023. ShareGPT_Vicuna_unfiltered
work page 2023
-
[32]
Jinwoo Jeong and Jeongseob Ahn. 2025. Accelerating LLM Serving for Multi-turn Dialogues with Efficient Resource Management. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 (ASPLOS). Association for Computing Machinery, New York, NY, USA, 1–15. doi:10.1145/3676641.3716245
-
[33]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. InProceedings of the 55th Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), Regina Barzilay and Min-Yen Kan (Eds.). Association for Computational Linguistics,...
-
[34]
Zhaokang Ke, Dingyi Kang, Bo Yuan, David Du, and Bingzhe Li. 2024. Improving the Sustainability of Solid-State Drives by Prolonging Lifetime. InIEEE Computer Society Annual Symposium on VLSI (ISVLSI). IEEE, Knoxville, TN, USA, 502–507. doi:10.1109/ISVLSI61997.2024.00096
-
[35]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. In Proceedings of the 29th Symposium on Operating Systems Principles (SOSP). Association for Computing Machinery, New York, NY, USA, 611–626. doi...
-
[36]
Ang Li, Xuanran Zong, Srikanth Kandula, Xiaowei Yang, and Ming Zhang. 2011. CloudProphet: Towards Application Performance Prediction in Cloud. InProceedings of the ACM SIGCOMM Conference(Toronto, Ontario, Canada) (SIGCOMM). Association for Computing Machinery, New York, NY, USA, 426–427. doi:10.1145/2018436.2018502 Cache Your Prompt When It’s Green — Carb...
-
[37]
Baolin Li, Rohan Basu Roy, Daniel Wang, Siddharth Samsi, Vijay Gadepally, and Devesh Tiwari. 2023. Toward Sustainable HPC: Carbon Footprint Estimation and Environmental Implications of HPC Systems. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC). Association for Computing Machinery, New Y...
-
[38]
Baolin Li, Siddharth Samsi, Vijay Gadepally, and Devesh Tiwari. 2023. Clover: Toward Sustainable AI with Carbon- Aware Machine Learning Inference Service. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC). Association for Computing Machinery, New York, NY, USA, Article 20, 15 pages. doi:10....
-
[39]
Yueying Li, Omer Graif, and Udit Gupta. 2024. Towards Carbon-efficient LLM Life Cycle. InProceedings of the 3rd Workshop on Sustainable Computer Systems (HotCarbon). ACM, New York, NY, USA
work page 2024
- [40]
-
[41]
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving. In17th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX Association, Boston, MA, 663...
work page 2023
-
[42]
Shuo Liu, Kaining Ying, Hao Zhang, Yue Yang, Yuqi Lin, Tianle Zhang, Chuanhao Li, Yu Qiao, Ping Luo, Wenqi Shao, and Kaipeng Zhang. 2024. ConvBench: A Multi-Turn Conversation Evaluation Benchmark with Hierarchical Ablation Capa- bility for Large Vision-Language Models. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgra...
work page 2024
-
[43]
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, Michael Maire, Henry Hoffmann, Ari Holtzman, and Junchen Jiang. 2024. CacheGen: KV Cache Compression and Streaming for Fast Large Language Model Serving. InProceedings of the ACM SIGCOMM 2024 Conference (SIGCOMM). Associat...
-
[44]
LLMPerf. 2024. LLMPerf Leaderboard
work page 2024
-
[45]
LMCache Team. 2025. KV Cache Size Calculator. https://lmcache.ai/kv_cache_calculator.html
work page 2025
-
[46]
LMCache Team. 2025. LMCache. https://lmcache.ai/
work page 2025
-
[47]
Chuwei Luo, Yufan Shen, Zhaoqing Zhu, Qi Zheng, Zhi Yu, and Cong Yao. 2024. LayoutLLM: Layout Instruction Tuning with Large Language Models for Document Understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Seattle, WA, USA, 15630–15640
work page 2024
-
[48]
Jialun Lyu, Jaylen Wang, Kali Frost, Chaojie Zhang, Celine Irvene, Esha Choukse, Rodrigo Fonseca, Ricardo Bianchini, Fiodar Kazhamiaka, and Daniel S. Berger. 2023. Myths and Misconceptions Around Reducing Carbon Embedded in Cloud Platforms. InProceedings of the 2nd Workshop on Sustainable Computer Systems (HotCarbon). ACM, Boston, MA, USA, Article 7, 7 pa...
-
[49]
Jialun Lyu, Marisa You, Celine Irvene, Mark Jung, Tyler Narmore, Jacob Shapiro, Luke Marshall, Savyasachi Samal, Ioannis Manousakis, Lisa Hsu, Preetha Subbarayalu, Ashish Raniwala, Brijesh Warrier, Ricardo Bianchini, Bianca Schroeder, and Daniel S. Berger. 2023. Hyrax: Fail-in-Place Server Operation in Cloud Platforms. In17th USENIX Symposium on Operating...
work page 2023
-
[50]
Diptyaroop Maji, Prashant Shenoy, and Ramesh K Sitaraman. 2023. Multi-Day Forecasting of Electric Grid Carbon Intensity Using Machine Learning. InProceedings of the 9th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation (BuildSys). ACM, New York, NY, USA, 19–33
work page 2023
-
[51]
Sitaraman, and Prashant Shenoy
Diptyaroop Maji, Ramesh K. Sitaraman, and Prashant Shenoy. 2022. DACF: Day-ahead Carbon Intensity Forecasting of Power Grids using Machine Learning. InProceedings of the Thirteenth ACM International Conference on Future Energy Systems (e-Energy). Association for Computing Machinery, New York, NY, USA. doi:10.1145/3538637.3538849
-
[52]
Sara McAllister, Fiodar Kazhamiaka, Daniel S Berger, Rodrigo Fonseca, Kali Frost, Aaron Ogus, Maneesh Sah, Ricardo Bianchini, George Amvrosiadis, Nathan Beckmann, et al . 2024. A call for research on storage emissions.ACM SIGENERGY Energy Informatics Review4, 5 (2024), 67–75
work page 2024
-
[53]
Berger, George Amvrosiadis, Nathan Beckmann, and Gregory R
Sara McAllister, Yucong "Sherry" Wang, Benjamin Berg, Daniel S. Berger, George Amvrosiadis, Nathan Beckmann, and Gregory R. Ganger. 2024. FairyWREN: A Sustainable Cache for Emerging Write-Read-Erase Flash Interfaces. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX Association, Santa Clara, CA, 745–764. https://www.us...
work page 2024
-
[54]
Meta. 2024. Introducing Meta Llama 3: The most capable openly available LLM to date. https://ai.meta.com/blog/meta- llama-3/. 26 Yuyang Tian, Desen Sun, Yi Ding, and Sihang Liu
work page 2024
-
[55]
Micron. 2025. DDR4 SDRAM memory. https://www.micron.com/products/memory/dram-components/ddr4-sdram
work page 2025
-
[56]
Sophia Nguyen, Beihao Zhou, Yi Ding, and Sihang Liu. 2024. Towards Sustainable Large Language Model Serving. In Proceedings of the 3rd Workshop on Sustainable Computer Systems (HotCarbon). ACM, New York, NY, USA
work page 2024
-
[57]
OpenAI. 2023. ChatGPT. https://chatgpt.com/
work page 2023
-
[58]
Ashraf, Christian Engelmann, Mallikarjun Shankar, and James H
George Ostrouchov, Don Maxwell, Rizwan A. Ashraf, Christian Engelmann, Mallikarjun Shankar, and James H. Rogers
-
[59]
GPU lifetimes on titan supercomputer: Survival analysis and reliability. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC). IEEE/ACM, Atlanta, Georgia, USA, 41
-
[60]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Íñigo Goiri, Aashaka Shah, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise improves GPU usage by splitting LLM inference phases. InInternational Symposium on Computer Architecture (ISCA). IEEE Press, Buenos Aires, Argentina, 118–132
work page 2024
-
[61]
Smith, Nima PourNejatian, Anthony B
Cheng Peng, Xi Yang, Aokun Chen, Kaleb E. Smith, Nima PourNejatian, Anthony B. Costa, Cheryl Martin, Mona G. Flores, Ying Zhang, Tanja Magoc, Gloria Lipori, Duane A. Mitchell, Naykky S. Ospina, Mustafa M. Ahmed, William R. Hogan, Elizabeth A. Shenkman, Yi Guo, Jiang Bian, and Yonghui Wu. 2023. A study of generative large language model for medical researc...
-
[62]
PuLP developers. 2025. PuLP: A Python Linear Programming API
work page 2025
-
[63]
pyNVML Developers. 2025. pyNVML. https://pypi.org/project/nvidia-ml-py/
work page 2025
- [64]
-
[65]
Siddharth Samsi, Dan Zhao, Joseph McDonald, Baolin Li, Adam Michaleas, Michael Jones, William Bergeron, Jeremy Kepner, Devesh Tiwari, and Vijay Gadepally. 2023. From Words to Watts: Benchmarking the Energy Costs of Large Language Model Inference. InIEEE High Performance Extreme Computing Conference (HPEC). IEEE, Boston, MA, USA, 1–9. doi:10.1109/HPEC58863...
-
[66]
Samsung. 2023. Samsung V-NAND SSD 990 PRO. https://download.semiconductor.samsung.com/resources/data- sheet/samsung_nvme_ssd_990_pro_datasheet_rev.2.0.pdf
work page 2023
-
[67]
Seagate. 2025. The Decarbonizing Data Report. https://www.seagate.com/ca/en/resources/decarbonizing-data-report/
work page 2025
-
[68]
ShareGPT. 2023. ShareGPT
work page 2023
- [69]
-
[70]
Tianyao Shi, Yanran Wu, Sihang Liu, and Yi Ding. 2025. Disaggregated Speculative Decoding for Carbon-Efficient LLM Serving.IEEE Computer Architecture Letters24, 2 (2025), 369–372. doi:10.1109/LCA.2025.3630094
-
[71]
Taylor G. Smith et al. 2017–. pmdarima: ARIMA estimators for Python. http://www.alkaline-ml.com/pmdarima
work page 2017
-
[72]
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. 2025. DynamoLLM: Designing LLM Inference Clusters for Performance and Energy Efficiency. InIEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, Las Vegas, NV, USA, 1348–1362. doi:10.1109/HPCA61900.2025.00102
-
[73]
Swamit Tannu and Prashant J. Nair. 2023. The Dirty Secret of SSDs: Embodied Carbon.SIGENERGY Energy Inform. Rev.3, 3 (Oct. 2023), 4–9. doi:10.1145/3630614.3630616
-
[74]
Gemini Team. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv:2403.05530 [cs.CL] https://arxiv.org/abs/2403.05530
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[75]
Jaylen Wang, Daniel S. Berger, Fiodar Kazhamiaka, Celine Irvene, Chaojie Zhang, Esha Choukse, Kali Frost, Rodrigo Fonseca, Brijesh Warrier, Chetan Bansal, Jonathan Stern, Ricardo Bianchini, and Akshitha Sriraman. 2025. Designing Cloud Servers for Lower Carbon. InProceedings of the 51st Annual International Symposium on Computer Architecture (ISCA). IEEE P...
-
[76]
Vinnie Wong. 2023. Gen AI’s Environmental Ledger: A Closer Look at the Carbon Footprint of ChatGPT. https: //piktochart.com/blog/carbon-footprint-of-chatgpt/
work page 2023
-
[77]
Carole-Jean Wu, Ramya Raghavendra, Udit Gupta, Bilge Acun, Newsha Ardalani, Kiwan Maeng, Gloria Chang, Fiona Aga, Jinshi Huang, Charles Bai, et al. 2022. Sustainable AI: Environmental implications, challenges and opportunities. Proceedings of Machine Learning and Systems (MLSys)(2022)
work page 2022
-
[78]
Leyi Yan, Linda Wang, Sihang Liu, and Yi Ding. 2025. EnsembleCI: Ensemble Learning for Carbon Intensity Forecasting. InProceedings of the 16th ACM International Conference on Future and Sustainable Energy Systems (E-Energy). Association for Computing Machinery, New York, NY, USA, 208–212. doi:10.1145/3679240.3734630
-
[79]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang
-
[80]
InProceedings of the Twentieth European Conference on Computer Systems (EuroSys)
CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion. InProceedings of the Twentieth European Conference on Computer Systems (EuroSys). Association for Computing Machinery, New York, NY, USA, 94–109. doi:10.1145/3689031.3696098 Cache Your Prompt When It’s Green — Carbon-Aware Caching for Large Language Model Serving 27
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.