Quality Assessment of Noisy and Enhanced Speech with Limited Data: UWB-NTIS System for VoiceMOS 2024
Pith reviewed 2026-05-19 12:02 UTC · model grok-4.3
The pith
A two-stage transfer learning approach with wav2vec 2.0 predicts P.835 quality scores from only 100 labeled utterances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
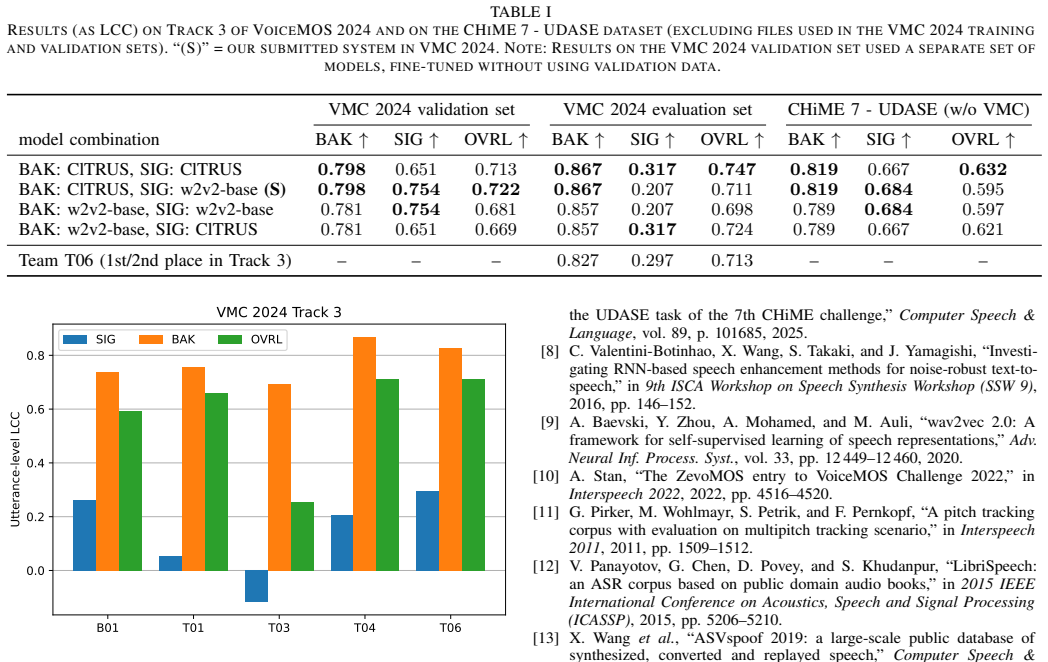
The central claim is that wav2vec 2.0 fine-tuned first on automatically labeled noisy and enhanced speech and then adapted to a small set of 100 subjectively rated utterances yields accurate non-intrusive estimates of SIG, BAK, and OVRL. In the official evaluation the resulting system achieved the best BAK correlation of 0.867 and second-place OVRL correlation of 0.711. Post-challenge experiments further established that enriching the initial fine-tuning data with artificially degraded samples raises the SIG correlation from 0.207 to 0.516, confirming that targeted data generation combined with staged transfer learning is effective under severe data constraints.
What carries the argument
wav2vec 2.0 with a two-stage transfer learning strategy that first fine-tunes on automatically labeled noisy data and then adapts to the limited subjectively rated challenge set.
If this is right
- BAK prediction reaches a linear correlation of 0.867 with human ratings.
- OVRL prediction reaches a linear correlation of 0.711 and places second in the challenge.
- SIG prediction rises from 0.207 to 0.516 correlation once artificially degraded data are added to the first fine-tuning stage.
- Transfer learning plus targeted synthetic data generation supports P.835 estimation when only 100 subjective labels are available.
Where Pith is reading between the lines
- The same staged approach could apply to other perceptual audio tasks where human ratings are scarce but synthetic degradations are easy to produce.
- Stronger results on BAK and OVRL than on SIG suggest the model acquires more robust noise-related representations than signal-distortion ones.
- Deploying the predictor in real communication pipelines could enable continuous quality monitoring without reference signals or fresh subjective tests.
- Evaluating the system on speech in unseen languages or acoustic environments would test whether the wav2vec features supply adequate cross-domain transfer.
Load-bearing premise
Features learned from automatically labeled noisy data in the first fine-tuning stage transfer usefully to the small set of 100 subjectively rated utterances for all three P.835 metrics.
What would settle it
Train an otherwise identical model directly on the 100 challenge utterances without the initial noisy-data fine-tuning stage; if its correlations on BAK, OVRL, and SIG match or exceed those of the two-stage system, the benefit of the transfer step is refuted.
Figures

read the original abstract
We present a system for non-intrusive prediction of speech quality in noisy and enhanced speech, developed for Track 3 of the VoiceMOS 2024 Challenge. The task required estimating the ITU-T P.835 metrics SIG, BAK, and OVRL without reference signals and with only 100 subjectively labeled utterances for training. Our approach uses wav2vec 2.0 with a two-stage transfer learning strategy: initial fine-tuning on automatically labeled noisy data, followed by adaptation to the challenge data. The system achieved the best performance on BAK prediction (LCC=0.867) and a very close second place in OVRL (LCC=0.711) in the official evaluation. Post-challenge experiments show that adding artificially degraded data to the first fine-tuning stage substantially improves SIG prediction, raising correlation with ground truth scores from 0.207 to 0.516. These results demonstrate that transfer learning with targeted data generation is effective for predicting P.835 scores under severe data constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a two-stage transfer learning system based on wav2vec 2.0 for non-intrusive prediction of ITU-T P.835 metrics (SIG, BAK, OVRL) on noisy and enhanced speech. With only 100 subjectively labeled utterances available for the VoiceMOS 2024 Challenge Track 3, the approach first fine-tunes on automatically labeled noisy data and then adapts to the challenge set. Official results report the best BAK performance (LCC=0.867) and second-place OVRL (LCC=0.711); post-challenge experiments show SIG correlation rising from 0.207 to 0.516 after adding artificially degraded data.
Significance. If the central claims hold, the work demonstrates that targeted transfer learning and synthetic data augmentation can yield competitive non-intrusive quality predictors under extreme data constraints. The official challenge rankings and the quantified post-challenge gain supply direct empirical support, with clear relevance to practical evaluation of speech enhancement systems where reference signals and large subjective corpora are unavailable.
major comments (2)
- §3.2 (two-stage fine-tuning description): The initial fine-tuning stage relies on automatically labeled noisy data to learn representations that transfer to subjective P.835 scores, yet the manuscript provides no correlation analysis, error characterization, or held-out validation between the automatic labels and human SIG/BAK/OVRL judgments. This assumption is load-bearing for the claim that the first stage meaningfully aids adaptation on the 100-utterance target set.
- §4.3 (post-challenge experiments): The reported SIG improvement (0.207 → 0.516) after adding artificially degraded data is a key result, but the data-generation procedure, labeling method, and exact composition of the augmented set are described at a level that prevents assessment of reproducibility or isolation of the performance source.
minor comments (2)
- Table 1: The baseline and ablation rows would benefit from explicit indication of whether the reported LCC values are on the official test set or a validation split.
- §2: A brief comparison table with other VoiceMOS 2024 submissions (beyond the final ranking) would help situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment below and indicate the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: §3.2 (two-stage fine-tuning description): The initial fine-tuning stage relies on automatically labeled noisy data to learn representations that transfer to subjective P.835 scores, yet the manuscript provides no correlation analysis, error characterization, or held-out validation between the automatic labels and human SIG/BAK/OVRL judgments. This assumption is load-bearing for the claim that the first stage meaningfully aids adaptation on the 100-utterance target set.
Authors: We agree that a direct analysis of the relationship between automatic labels and human judgments would strengthen the justification for the two-stage procedure. In the revised manuscript we add a new paragraph to §3.2 that reports Pearson correlations and mean absolute errors between the automatic labels and the subjective scores on a held-out subset of the noisy data. We also discuss the implications of the observed label noise for representation learning and note that the final challenge performance and ablation results provide indirect evidence that the first stage is beneficial. revision: yes
-
Referee: §4.3 (post-challenge experiments): The reported SIG improvement (0.207 → 0.516) after adding artificially degraded data is a key result, but the data-generation procedure, labeling method, and exact composition of the augmented set are described at a level that prevents assessment of reproducibility or isolation of the performance source.
Authors: We accept that the current description is insufficient for full reproducibility. The revised §4.3 will specify the exact degradation operations (noise types, SNR ranges, and other distortions), the automatic labeling pipeline applied to the augmented utterances, the total number of added samples, and their source distribution. We will also include an ablation that isolates the contribution of the augmented data to the SIG correlation gain. revision: yes
Circularity Check
No significant circularity: results from independent challenge evaluation and external data generation
full rationale
The paper describes an empirical ML pipeline using wav2vec 2.0 fine-tuned in two stages on automatically labeled noisy data then adapted to 100 challenge utterances, with final performance measured via official VoiceMOS 2024 evaluation on held-out test data (LCC values reported directly against subjective ground truth). No equations, derivations, or first-principles claims are present that reduce to fitted parameters or self-referential definitions. Post-challenge experiments with artificially degraded data are separate and externally generated, providing independent validation. The central results are falsifiable outputs on an external benchmark rather than quantities defined by construction from the model's own inputs or prior self-citations.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage transfer learning strategy: initial fine-tuning on automatically labeled noisy data, followed by adaptation to the challenge data
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
wav2vec 2.0 with a two-stage transfer learning strategy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The V oiceMOS Challenge 2024: Beyond speech quality prediction,
W.-C. Huang, S.-W. Fu, E. Cooper, R. E. Zezario, T. Toda, H.-M. Wang, J. Yamagishi, and Y . Tsao, “The V oiceMOS Challenge 2024: Beyond speech quality prediction,” in 2024 IEEE Spoken Language Technology Workshop (SLT), 2024, pp. 803–810
work page 2024
-
[2]
Ensemble of deep neural network models for MOS prediction,
M. Kuneˇsov´a, J. Matou ˇsek, J. Lehe ˇcka, J. ˇSvec, J. Mich ´alek, D. Tihelka, M. Bul´ın, Z. Hanzl´ıˇcek, and M. ˇRez´aˇckov´a, “Ensemble of deep neural network models for MOS prediction,” in ICASSP, 2023, pp. 1–5
work page 2023
-
[3]
Zero- shot out-of-domain is no joke: Lessons learned in the V oiceMOS 2023 MOS prediction challenge,
M. Kuneˇsov´a, J. Lehe ˇcka, J. Mich ´alek, J. Matou ˇsek, and J. ˇSvec, “Zero- shot out-of-domain is no joke: Lessons learned in the V oiceMOS 2023 MOS prediction challenge,” in Interspeech, 2024, pp. 4913–4917
work page 2023
-
[4]
Three years of V oiceMOS challenges: Lessons learned by the UWB-NTIS-TTS team,
M. Kune ˇsov´a, J. Matou ˇsek, J. Lehe ˇcka, J. ˇSvec, D. Tihelka, and Z. Hanzl´ıˇcek, “Three years of V oiceMOS challenges: Lessons learned by the UWB-NTIS-TTS team,” [manuscript in preparation] , 2025
work page 2025
-
[5]
Mean opinion score (MOS) terminol- ogy,
ITU-T Recommendation P.800.1, “Mean opinion score (MOS) terminol- ogy,” International Telecommunication Union, Tech. Rep., 2003
work page 2003
-
[6]
ITU-T Recommendation P.835, “Subjective test methodology for eval- uating speech communication systems that include noise suppression algorithm,” International Telecommunication Union, Tech. Rep., 2003
work page 2003
-
[7]
S. Leglaive, M. Fraticelli, H. ElGhazaly, L. Borne, M. Sadeghi, S. Wis- dom, M. Pariente, J. R. Hershey, D. Pressnitzer, and J. P. Barker, “Objective and subjective evaluation of speech enhancement methods in the UDASE task of the 7th CHiME challenge,” Computer Speech & Language, vol. 89, p. 101685, 2025
work page 2025
-
[8]
Investi- gating RNN-based speech enhancement methods for noise-robust text-to- speech,
C. Valentini-Botinhao, X. Wang, S. Takaki, and J. Yamagishi, “Investi- gating RNN-based speech enhancement methods for noise-robust text-to- speech,” in 9th ISCA Workshop on Speech Synthesis Workshop (SSW 9) , 2016, pp. 146–152
work page 2016
-
[9]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Adv. Neural Inf. Process. Syst. , vol. 33, pp. 12 449–12 460, 2020
work page 2020
-
[10]
The ZevoMOS entry to V oiceMOS Challenge 2022,
A. Stan, “The ZevoMOS entry to V oiceMOS Challenge 2022,” in Interspeech 2022, 2022, pp. 4516–4520
work page 2022
-
[11]
A pitch tracking corpus with evaluation on multipitch tracking scenario,
G. Pirker, M. Wohlmayr, S. Petrik, and F. Pernkopf, “A pitch tracking corpus with evaluation on multipitch tracking scenario,” in Interspeech 2011, 2011, pp. 1509–1512
work page 2011
-
[12]
LibriSpeech: an ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “LibriSpeech: an ASR corpus based on public domain audio books,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210
work page 2015
-
[13]
ASVspoof 2019: a large-scale public database of synthesized, converted and replayed speech,
X. Wang et al. , “ASVspoof 2019: a large-scale public database of synthesized, converted and replayed speech,” Computer Speech & Language, vol. 64, p. 101114, 2020
work page 2019
-
[14]
J. Lehe ˇcka, J. ˇSvec, A. Pra ˇz´ak, and J. V . Psutka, “Exploring capabilities of monolingual audio transformers using large datasets in automatic speech recognition of Czech,” in INTERSPEECH, 2022, pp. 1831–1835. APPENDIX A. List of excluded CHiME7 - UDASE files The following files from the CHiME7 - UDASE dataset were excluded from the evaluation in Ta...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.