Analysis of Floating-Point Matrix Multiplication Computed via Integer Arithmetic
Pith reviewed 2026-05-19 09:06 UTC · model grok-4.3
The pith
Floating-point matrix multiplication via integer slices can become inaccurate or inefficient when rows of A or columns of B are badly scaled.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The integer-slice method yields a floating-point approximation to AB whose error is governed by the number of slices and by the scaling of the input rows and columns; a simple a-priori formula gives the minimal slice count needed for a prescribed accuracy, yet this count grows or the accuracy guarantee fails when the input matrices are badly scaled.
What carries the argument
Splitting each floating-point entry of A and B into a fixed number of integer slices whose exact products are summed in floating-point arithmetic.
If this is right
- A cheap estimator now exists for the number of integer multiplications required to reach a given accuracy target.
- Badly scaled rows or columns force either more slices or a larger error than the basic bound predicts.
- The method remains attractive on tensor-core hardware provided the scaling issue is recognized.
- The number of slices offers a direct, predictable performance-accuracy tradeoff once scaling is controlled.
Where Pith is reading between the lines
- A cheap row-and-column scaling step performed before slicing could reduce the slice count needed on typical data.
- The same error model could be used to adapt the number of slices locally inside blocked algorithms.
- Similar slicing ideas may appear in other linear-algebra kernels that already rely on matrix multiplication.
- Hardware vendors could expose a scaling-aware variant of the integer matrix-multiply instruction.
Load-bearing premise
The analysis assumes that the integer slices can be chosen so the floating-point accumulation error stays bounded independently of how the magnitudes are distributed inside each row of A or column of B, without any extra preprocessing or dynamic scaling.
What would settle it
Take a matrix A whose first row contains entries differing by ten orders of magnitude, apply the estimator to choose the slice count for a modest target accuracy, compute the product on hardware, and observe whether the relative forward error exceeds the target by more than a small constant factor.
Figures

















read the original abstract
Ootomo, Ozaki, and Yokota [Int. J. High Perform. Comput. Appl., 38 (2024), p. 297-313] have proposed a strategy to recast a floating-point matrix multiplication in terms of integer matrix products. The factors A and B are split into integer slices, the product of these slices is computed exactly, and AB is approximated by accumulating these integer products in floating-point arithmetic. This technique is particularly well suited to mixed-precision matrix multiply-accumulate units with integer support, such as the NVIDIA tensor cores or the AMD matrix cores. The number of slices allows for performance-accuracy tradeoffs: more slices yield better accuracy but require more multiplications, which in turn reduce performance. We propose an inexpensive way to estimate the minimum number of multiplications needed to achieve a prescribed level of accuracy. Our error analysis shows that the algorithm may become inaccurate (or inefficient) if rows of A or columns of B are badly scaled. We perform a range of numerical experiments, both in simulation and on the latest NVIDIA GPUs, that confirm the analysis and illustrate strengths and weaknesses of the algorithm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes a technique for recasting floating-point matrix multiplication AB as a sum of exact integer matrix products obtained by splitting the factors A and B into integer slices. It proposes an inexpensive estimator for the minimal number of slices (hence multiplications) needed to meet a target accuracy, derives error bounds under standard floating-point rounding models, and shows analytically that the method can become inaccurate or inefficient when rows of A or columns of B are badly scaled. The analysis is supported by numerical experiments both in simulation and on NVIDIA GPUs with tensor cores.
Significance. If the central error bounds and estimator hold, the work supplies a practical, low-overhead tool for accuracy-performance trade-offs on mixed-precision hardware supporting integer matrix operations. The explicit identification of scaling-induced degradation is a useful practical warning. The combination of analysis with GPU experiments provides concrete evidence of both strengths and limitations.
major comments (2)
- [§3.2] §3.2 (error analysis and slice estimator): the derivation of the minimum-slice estimator implicitly assumes that slice boundaries can always be chosen so the floating-point accumulation error after summing the integer-slice products remains bounded independently of the magnitude distribution inside each row of A or column of B. For highly nonuniform intra-row magnitudes this assumption may fail because individual integer products can still produce mantissa overflow during accumulation; the manuscript does not supply a concrete counter-example or additional bound quantifying the residual dependence on dynamic range.
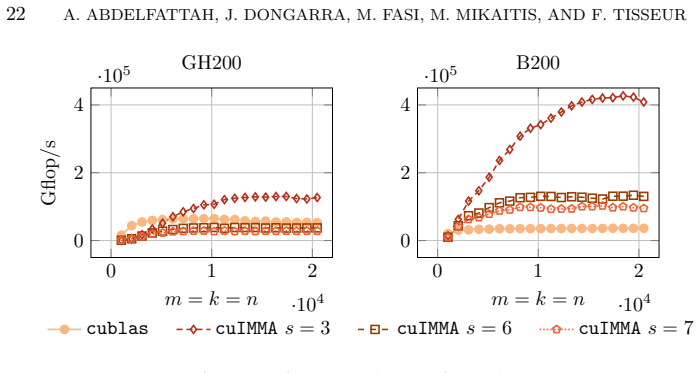
- [§4] §4 (numerical experiments): the reported GPU timings and error measurements confirm the scaling warning only for the tested matrices; no table or figure isolates the estimator's predicted slice count versus observed error when rows are deliberately scaled with increasing dynamic range (e.g., entries drawn from log-uniform distributions). Adding such a controlled experiment would directly test whether the estimator remains reliable under the weakest assumption identified in the analysis.
minor comments (2)
- Notation for the slice-selection estimator is introduced without an explicit algorithmic listing; a short pseudocode block would clarify how the inexpensive estimator is evaluated in practice.
- Figure captions for the GPU experiments should state the matrix dimensions, data types, and number of runs used to generate the plotted error and timing values.
Simulated Author's Rebuttal
We thank the referee for the careful reading of our manuscript and the constructive comments. We address the two major comments below, indicating the changes we will make to the revised version.
read point-by-point responses
-
Referee: [§3.2] §3.2 (error analysis and slice estimator): the derivation of the minimum-slice estimator implicitly assumes that slice boundaries can always be chosen so the floating-point accumulation error after summing the integer-slice products remains bounded independently of the magnitude distribution inside each row of A or column of B. For highly nonuniform intra-row magnitudes this assumption may fail because individual integer products can still produce mantissa overflow during accumulation; the manuscript does not supply a concrete counter-example or additional bound quantifying the residual dependence on dynamic range.
Authors: We appreciate the referee's observation regarding the potential limitations of the error bounds in §3.2 under highly nonuniform magnitude distributions within rows or columns. The current analysis employs standard rounding error models that bound the accumulation error in terms of the number of slices and machine precision, assuming slice boundaries are selected based on the overall dynamic range. However, as noted, for distributions with large intra-row variations, intermediate products might lead to larger local errors. To address this, we will revise the manuscript to include a concrete counter-example demonstrating the effect and derive an additional bound that accounts for the maximum dynamic range within each row or column. This will clarify the conditions under which the estimator remains reliable. revision: yes
-
Referee: [§4] §4 (numerical experiments): the reported GPU timings and error measurements confirm the scaling warning only for the tested matrices; no table or figure isolates the estimator's predicted slice count versus observed error when rows are deliberately scaled with increasing dynamic range (e.g., entries drawn from log-uniform distributions). Adding such a controlled experiment would directly test whether the estimator remains reliable under the weakest assumption identified in the analysis.
Authors: We agree that a more targeted experiment would better validate the estimator under the conditions highlighted in the analysis. Our existing experiments in §4 do include matrices with varying row and column scalings to illustrate the scaling-induced degradation, but they do not specifically isolate the estimator's accuracy for log-uniform distributions with controlled increases in dynamic range. In the revised version, we will add a new subsection or figure that presents results for such matrices, comparing the predicted number of slices from the estimator against the observed errors. This will provide direct evidence of the estimator's robustness or limitations in these cases. revision: yes
Circularity Check
Error analysis derives bounds from standard FP rounding models without reduction to fitted inputs or self-citations
full rationale
The paper derives its error bounds and slice-count estimator from established floating-point rounding error models applied to accumulation of exact integer-slice products. No equations reduce the claimed accuracy estimator or scaling warnings to quantities fitted from the target data or defined circularly in terms of the output accuracy. The cited prior work on the integer-slice strategy is external (Ootomo et al.), not self-citation, and the analysis remains self-contained against external FP arithmetic benchmarks rather than relying on load-bearing self-references or ansatzes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Integer matrix products are computed exactly with no rounding error.
- standard math Floating-point accumulation follows standard rounding error bounds.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our error analysis shows that the algorithm may become inaccurate (or inefficient) if rows of A or columns of B are badly scaled... ζ_{A,B} := 2^{-s_A t} κ_A + 2^{-s_B t} κ_B + ...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The Ozaki scheme... splitting into integer slices... accumulation in floating-point arithmetic
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Interim report on binary floating-point formats for machine learning , tech. report, Oct. 2024, https://github.com/P3109/Public/blob/cf6d2ea9df1fd97cafc4fef6feb73966dd35521b/ Shared%20Reports/IEEE%20WG%20P3109%20Interim%20Report.pdf. Version 0.9.1
work page 2024
-
[2]
NVIDIA Blackwell Architecture Technical Brief , NVIDIA, Mar. 2024, https://nvdam.widen. net/s/xqt56dflgh/nvidia-blackwell-architecture-technical-brief. V1.0
work page 2024
-
[3]
A. Abdelfattah, H. Anzt, E. G. Boman, E. Carson, T. Cojean, J. Dongarra, A. Fox, M. Gates, N. J. Higham, X. S. Li, J. Loe, P. Luszczek, S. Pranesh, S. Rajamanickam, T. Ribizel, B. F. Smith, K. Swirydowicz, S. Thomas, S. Tomov, Y. M. Tsai, and U. M. Yang, A survey of numerical linear algebra methods utilizing mixed-precision arithmetic , Int. J. High Perfo...
work page 2021
-
[4]
A. Abdelfattah, N. Beams, R. Carson, P. Ghysels, T. Kolev, T. Stitt, A. Vargas, S. Tomov, and J. Dongarra , MAGMA: Enabling exascale performance with accelerated BLAS and LAPACK for diverse GPU architectures , Int. J. High Perform. Comput. Appl., (2024), https://doi.org/10.1177/10943420241261960
-
[5]
E. Agullo, J. Demmel, J. Dongarra, B. Hadri, J. Kurzak, J. Langou, H. Ltaief, P. Luszczek, and S. Tomov , Numerical linear algebra on emerging architectures: The PLASMA and MAGMA projects , J. Phys.: Conf. Ser., 180 (2009), p. 012037, https: //doi.org/10.1088/1742-6596/180/1/012037
-
[6]
P. Amestoy, A. Buttari, N. J. Higham, J.-Y. L’Excellent, T. Mary, and B. Vieubl ´e, Five-precision GMRES-based iterative refinement, SIAM J. Matrix Anal. Appl., 45 (2024), p. 529–552, https://doi.org/10.1137/23m1549079
-
[7]
C. Bertin, N. Brisebarre, B. Dupont de Dinechin, C.-P. Jeannerod, C. Monat, J.-M. Muller, S.-K. Raina, and A. Tisserand , A floating-point library for integer processors , in Advanced Signal Processing Algorithms, Architectures, and Implementations XIV, F. T. Luk, ed., vol. 5559, SPIE, Oct. 2004, p. 101, https://doi.org/10.1117/12.557168
-
[8]
E. Carson and N. J. Higham , A new analysis of iterative refinement and its application to accurate solution of ill-conditioned sparse linear systems, SIAM J. Sci. Comput., 39 (2017), pp. A2834–A2856, https://doi.org/10.1137/17M1122918
-
[9]
E. Carson and N. J. Higham , Accelerating the solution of linear systems by iterative re- finement in three precisions , SIAM J. Sci. Comput., 40 (2018), pp. A817–A847, https: //doi.org/10.1137/17M1140819
-
[10]
E. Carson, N. J. Higham, and S. Pranesh , Three-precision GMRES-based iterative refine- ment for least squares problems , SIAM J. Sci. Comput., 42 (2020), pp. A4063–A4083, https://doi.org/10.1137/20m1316822
-
[11]
J. J. Dongarra, P. Luszczek, and A. Petitet , The LINPACK benchmark: Past, present and future, Concurrency Computat.: Pract. Exper., 15 (2003), pp. 803–820, https://doi. org/10.1002/cpe.728
-
[12]
M. D. Ercegovac and T. Lang, Digital Arithmetic, Morgan Kauffmann, San Francisco, CA, USA, 2004, https://doi.org/10.1016/b978-1-55860-798-9.x5000-3
-
[13]
M. Fasi, N. J. Higham, F. Lopez, T. Mary, and M. Mikaitis , Matrix multiplication in multiword arithmetic: Error analysis and application to GPU tensor cores , SIAM J. Sci. Comput., 45 (2023), p. C1–C19, https://doi.org/10.1137/21m1465032
-
[14]
M. Fasi, N. J. Higham, M. Mikaitis, and S. Pranesh, Numerical behavior of NVIDIA tensor cores, PeerJ Comput. Sci., 7 (2021), pp. e330(1–19), https://doi.org/10.7717/peerj-cs.330
-
[15]
B. Feng, Y. Wang, G. Chen, W. Zhang, Y. Xie, and Y. Ding , EGEMM-TC: Accelerating scientific computing on tensor cores with extended precision , in Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, vol. 18 of PPoPP ’21, ACM, Feb. 2021, p. 278–291, https://doi.org/10.1145/3437801.3441599
-
[16]
G. H. Golub and C. F. Van Loan , Matrix Computations , Johns Hopkins University Press, Baltimore, MD, USA, 4th ed., 2013
work page 2013
-
[17]
2022, https://docs.graphcore.ai/projects/isa/en/latest/ static/TileVertexISA-IPU21-1.3.1.pdf
Graphcore, Tile Vertex ISA , Dec. 2022, https://docs.graphcore.ai/projects/isa/en/latest/ static/TileVertexISA-IPU21-1.3.1.pdf. Release 1.3.1 for the Mk IPU with FP8 support
work page 2022
-
[18]
G. Henry, P. T. P. Tang, and A. Heinecke , Leveraging the bfloat16 artificial intelligence datatype for higher-precision computations, in Proceedings of the 2019 IEEE 26th Sympo- sium on Computer Arithmetic (ARITH), IEEE, June 2019, https://doi.org/10.1109/arith. 2019.00019. MATRIX MULTIPLICATION WITH INTEGER ARITHMETIC 27
-
[19]
N. J. Higham , Accuracy and Stability of Numerical Algorithms , Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2nd ed., 2002, https://doi.org/10.1137/1. 9780898718027
work page doi:10.1137/1 2002
-
[20]
N. J. Higham and T. Mary , Mixed precision algorithms in numerical linear algebra , Acta Numerica, 31 (2022), pp. 347–414, https://doi.org/10.1017/s0962492922000022
-
[21]
N. J. Higham and M. Mikaitis, Anymatrix: An extensible MATLAB matrix collection, Numer. Algorithms, 90 (2021), pp. 1175–1196, https://doi.org/10.1007/s11075-021-01226-2
-
[22]
N. J. Higham and M. Mikaitis, Anymatrix: An extensible MATLAB matrix collection. users’ guide, MIMS EPrint 2021.15, Manchester Institute for Mathematical Sciences, The Uni- versity of Manchester, UK, Oct. 2021, http://eprints.maths.manchester.ac.uk/2834/
work page 2021
-
[23]
N. J. Higham and S. Pranesh , Exploiting lower precision arithmetic in solving symmetric positive definite linear systems and least squares problems , SIAM J. Sci. Comput., 43 (2021), pp. A258–A277, https://doi.org/10.1137/19M1298263
-
[24]
IEEE Standard for Floating-Point Arithmetic, IEEE Std 754-2019 (revision of IEEE Std 754- 2008), Institute of Electrical and Electronics Engineers, Piscataway, NJ, USA, July 2019, https://doi.org/10.1109/IEEESTD.2019.8766229
-
[25]
C.-P. Jeannerod and S. M. Rump, Improved error bounds for inner products in floating-point arithmetic, SIAM J. Matrix Anal. Appl., 34 (2013), p. 338–344, https://doi.org/10.1137/ 120894488
work page 2013
-
[26]
G. Li, J. Xue, L. Liu, X. Wang, X. Ma, X. Dong, J. Li, and X. Feng , Unleashing the low-precision computation potential of tensor cores on GPUs , in Proceedings of the 2021 IEEE/ACM International Symposium on Code Generation and Optimization, vol. 521, IEEE, Feb. 2021, p. 90–102, https://doi.org/10.1109/cgo51591.2021.9370335
-
[27]
Z. Lin, A. Sun, X. Zhang, and Y. Lu, MixPert: Optimizing mixed-precision floating-point em- ulation on GPU integer tensor cores, in Proceedings of the 25th ACM SIGPLAN/SIGBED International Conference on Languages, Compilers, and Tools for Embedded Systems, LCTES ’24, New York, June 2024, ACM Press, p. 34–45, https://doi.org/10.1145/3652032. 3657567
-
[28]
Y. Luo, Z. Zhang, R. Wu, H. Liu, Y. Jin, K. Zheng, M. Wang, Z. He, G. Hu, L. Chen, T. Hu, J. Wang, M. Chen, M. Dmitry, K. Vladimir, B. Maxim, Y. Hu, G. Chen, and Z. Huang, Ascend HiFloat8 format for deep learning, arXiv:2409.16626 [cs.LG], Sept. 2024, https://doi.org/10.48550/ARXIV.2409.16626
-
[29]
Z. Ma, H. Wang, G. Feng, C. Zhang, L. Xie, J. He, S. Chen, and J. Zhai , Efficiently emulating high-bitwidth computation with low-bitwidth hardware , in Proceedings of the 36th ACM International Conference on Supercomputing, vol. 46 of ICS ’22, ACM Press, June 2022, p. 1–12, https://doi.org/10.1145/3524059.3532377
-
[30]
S. Markidis, S. W. D. Chien, E. Laure, I. B. Peng, and J. S. Vetter , NVIDIA tensor core programmability, performance & precision, in Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), May 2018, https: //doi.org/10.1109/ipdpsw.2018.00091
-
[31]
P. Micikevicius, S. Oberman, P. Dubey, M. Cornea, A. Rodriguez, I. Bratt, R. Grisenthwaite, N. Jouppi, C. Chou, A. Huffman, M. Schulte, R. Wittig, D. Jani, and S. Deng , OCP 8-bit floating point specitication (OFP8) , tech. re- port, Open Compute Project, June 2023, https://www.opencompute.org/documents/ ocp-8-bit-floating-point-specification-ofp8-revisio...
work page 2023
-
[32]
P. Micikevicius, D. Stosic, N. Burgess, M. Cornea, P. Dubey, R. Grisenthwaite, S. Ha, A. Heinecke, P. Judd, J. Kamalu, N. Mellempudi, S. Oberman, M. Shoeybi, M. Siu, and H. Wu, FP8 formats for deep learning , arXiv:2209/05433 [cs.LG], Sept. 2022, https: //doi.org/10.48550/ARXIV.2209.05433. Revised September 2022
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2209.05433 2022
-
[33]
D. Mukunoki, K. Ozaki, T. Ogita, and T. Imamura , DGEMM Using Tensor Cores, and Its Accurate and Reproducible Versions, Springer-Verlag, 2020, p. 230–248, https://doi.org/ 10.1007/978-3-030-50743-5 12
-
[34]
D. Mukunoki, K. Ozaki, T. Ogita, and T. Imamura , Accurate matrix multiplication on binary128 format accelerated by Ozaki scheme , in Proceedings of the 50th International Conference on Parallel Processing, ICPP 2021, ACM, Aug. 2021, p. 1–11, https://doi.org/ 10.1145/3472456.3472493
-
[35]
B. Noune, P. Jones, D. Justus, D. Masters, and C. Luschi, 8-bit numerical formats for deep neural networks, arXiv:2206.02915 [cs.LG], June 2022, https://doi.org/10.48550/ARXIV. 2206.02915
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[36]
NVIDIA Corporation, NVIDIA Turing GPU architecture, Tech. Report WP-09183-001 v01, 2018, https://images.nvidia.com/aem-dam/en-zz/Solutions/design-visualization/ technologies/turing-architecture/NVIDIA-Turing-Architecture-Whitepaper.pdf. 28 A. ABDELFATTAH, J. DONGARRA, M. FASI, M. MIKAITIS, AND F. TISSEUR
work page 2018
-
[37]
NVIDIA Corporation , NVIDIA A100 tensor core GPU architecture , tech. re- port, 2020, https://images.nvidia.com/aem-dam/en-zz/Solutions/data-center/ nvidia-ampere-architecture-whitepaper.pdf
work page 2020
-
[38]
report, 2022, https: //resources.nvidia.com/en-us-data-center-overview/gtc22-whitepaper-hopper
NVIDIA Corporation, NVIDIA H100 tensor core GPU architecture, tech. report, 2022, https: //resources.nvidia.com/en-us-data-center-overview/gtc22-whitepaper-hopper
work page 2022
-
[39]
2025, https://docs.nvidia.com/cuda/ pdf/ptx isa 8.7.pdf
NVIDIA Corporation, CUDA PTX ISA, NVIDIA, Jan. 2025, https://docs.nvidia.com/cuda/ pdf/ptx isa 8.7.pdf. Release 8.7
work page 2025
- [40]
-
[41]
K. Ozaki, T. Ogita, S. Oishi, and S. M. Rump , Error-free transformations of matrix mul- tiplication by using fast routines of matrix multiplication and its applications , Numer. Algorithms, 59 (2012), p. 95–118, https://doi.org/10.1007/s11075-011-9478-1
-
[42]
K. Ozaki, T. Ogita, S. Oishi, and S. M. Rump , Generalization of error-free transformation for matrix multiplication and its application , Nonlinear Theory Appl., 4 (2013), p. 2–11, https://doi.org/10.1587/nolta.4.2
-
[43]
A. Petitet, R. C. Whaley, J. Dongarra, and A. Cleary, HPL: A portable implementation of the High-Performance Linpack benchmark for distributed-memory computers, Version 2.3, 2018, https://www.netlib.org/benchmark/hpl/
work page 2018
-
[44]
L. Pisha and L. Ligowski , Accelerating non-power-of-2 size Fourier transforms with GPU tensor cores, in Proceedings of the 2021 IEEE International Parallel and Distributed Pro- cessing Symposium (IPDPS), vol. 19, May 2021, p. 507–516, https://doi.org/10.1109/ ipdps49936.2021.00059
-
[45]
S. M. Rump, T. Ogita, and S. Oishi, Accurate floating-point summation part I: Faithful round- ing, SIAM J. Sci. Comput., 31 (2008), p. 189–224, https://doi.org/10.1137/050645671
-
[46]
Online: https://digitalassets.tesla.com/tesla-contents/image/upload/ tesla-dojo-technology.pdf
Tesla, Tesla Dojo technology, a guide to Tesla’s configurable floating point formats & arithmetic . Online: https://digitalassets.tesla.com/tesla-contents/image/upload/ tesla-dojo-technology.pdf. Accessed: 27th of May, 2025
work page 2025
-
[47]
Y. Uchino, K. Ozaki, and T. Imamura , Performance enhancement of the Ozaki scheme on integer matrix multiplication unit , arXiv:2409.13313 [cs.DC], Sept. 2024, https://doi.org/ 10.48550/arXiv.2409.13313
-
[48]
Y. Uchino, K. Ozaki, and T. Imamura , Performance enhancement of the ozaki scheme on integer matrix multiplication unit , Int. J. High Perform. Comput. Appl., (2025), https: //doi.org/10.1177/10943420241313064
-
[49]
P. Valero-Lara, I. Jorquera, F. Lui, and J. Vetter, Mixed-precision S/DGEMM using the TF32 and TF64 frameworks on low-precision AI tensor cores , in Proceedings of the SC 23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis, SC-W 2023, ACM, Nov. 2023, p. 179–186, https://doi.org/10.1145/ 3624062.3624084
-
[50]
M. van Baalen, A. Kuzmin, S. S. Nair, Y. Ren, E. Mahurin, C. Patel, S. Subramanian, S. Lee, M. Nagel, J. Soriaga, and T. Blankevoort , FP8 versus INT8 for efficient deep learning inference, arXiv:2303.17951 [cs.LG],, Mar. 2023, https://doi.org/10.48550/ ARXIV.2303.17951. Revised in June 2023
-
[51]
J. H. Wilkinson , Rounding Errors in Algebraic Processes , Notes on Applied Science No. 32, Her Majesty’s Stationery Office, London, UK, 1963. Also published by Prentice-Hall, Englewood Cliffs, NJ, USA. Reprinted by Dover, New York, 1994
work page 1963
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.