Machine-Learning-Powered Specification Testing in Linear Instrumental Variable Models
Pith reviewed 2026-05-19 09:43 UTC · model grok-4.3
The pith
A residual-prediction test powered by machine learning checks linear IV model specification under mean independence of the structural error from the instruments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the mean independence of the structural error from the instruments, the linear IV model is well-specified if and only if the 2SLS residuals are unpredictable from the instruments. The proposed test implements this idea by training a machine learning predictor on a sample split and testing whether its out-of-sample prediction error is better than a null benchmark, yielding a valid p-value that controls type I error asymptotically and has power against misspecifications where the residuals carry information about the instruments.
What carries the argument
The residual prediction test, which assesses whether two-stage least squares residuals are predictable from the instruments using sample splitting and an arbitrary machine learning method.
If this is right
- The test applies directly to just-identified IV models where classical overidentification tests cannot be used.
- It maintains validity under heteroskedasticity and clustering through appropriate variance estimators.
- The method extends to weak instrument settings by inverting an Anderson-Rubin-type statistic.
- Consistency holds against a broad class of alternatives where the structural error depends on the instruments.
Where Pith is reading between the lines
- This test can be applied in many empirical studies that rely on exactly identified IV designs.
- The approach opens the door to using more flexible predictors to increase detection power for subtle misspecifications.
- Similar residual-based testing ideas could be explored in other econometric models with endogeneity corrections.
Load-bearing premise
The structural error term is mean independent of the instruments.
What would settle it
If repeated applications of the test to data generated from a correctly specified linear IV model reject the null hypothesis at rates exceeding the nominal level, the asymptotic type I error control would be falsified.
Figures







read the original abstract
The linear instrumental variable (IV) model is widely used in observational studies, yet its validity hinges on strong assumptions. Classical specification tests such as the Sargan-Hansen J test are limited to overidentified settings and are therefore not applicable in the common just-identified case, where the number of instruments is equal to the number of endogenous variables. We propose a novel test for the well-specification of the linear IV model under the assumption that the structural error is mean independent of the instruments. This assumption enables specification testing even in the just-identified setting. Our approach uses the idea of residual prediction: if the two-stage least squares residuals can be predicted from the instruments better than chance, this indicates misspecification. The resulting test employs sample splitting and a user-chosen machine learning method, and we show asymptotic type I error control and consistency against a broad class of alternatives. We further show how the proposed testing principle can be adapted to settings with weak or many instruments via an Anderson-Rubin-type inversion, thereby substantially extending the applicability. The tests accommodate heteroskedasticity- and cluster-robust inference and are implemented in the R package RPIV and the ivmodels software package for Python.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a residual-prediction test for specification of linear IV models under the mean independence of structural errors and instruments. This enables testing in the just-identified case (where Sargan-Hansen does not apply) by checking whether 2SLS residuals can be predicted from instruments better than chance, using sample splitting and a user-chosen ML method. Asymptotic type I error control and consistency against broad alternatives are claimed, along with an Anderson-Rubin-style inversion extension for weak or many instruments that preserves the orthogonality principle; the tests allow heteroskedasticity- and cluster-robust inference and are implemented in R and Python packages.
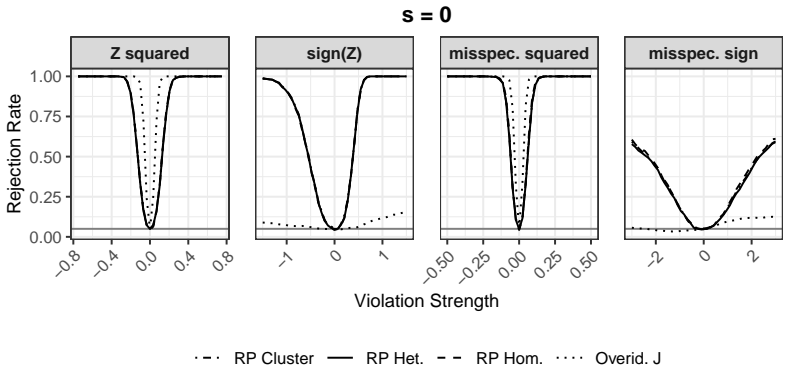
Significance. If the asymptotic results hold, the contribution is meaningful: it fills a practical gap by providing a specification test for the common just-identified IV setting and flexibly incorporates modern ML while retaining valid inference. The AR inversion broadens applicability to weak-instrument regimes. Explicit software implementations and the focus on falsifiable prediction-based diagnostics are strengths that could make the method adoptable in applied work.
major comments (2)
- [§3.1, Theorem 1] §3.1, Theorem 1: the claimed asymptotic normality of the test statistic after robust variance estimation requires explicit rate conditions on the ML predictor (e.g., o_p(n^{-1/4}) uniform convergence of the fitted residuals); without these, the orthogonality argument used to separate estimation error from the prediction step may not go through under the stated mean-independence null.
- [§4.2, Algorithm 2] §4.2, Algorithm 2: the Anderson-Rubin inversion is described at a high level, but the paper does not specify how the critical value or the grid search is adjusted when the underlying test statistic is itself ML-based; this leaves open whether the inversion preserves exact finite-sample size or only asymptotic validity under weak instruments.
minor comments (3)
- The abstract and introduction should cite the precise regularity conditions under which the ML method is allowed (e.g., whether random forests, neural nets, or kernel methods are covered by the same theorem).
- [Table 1] Table 1: the simulation design uses a fixed ML hyper-parameter grid; reporting sensitivity to that choice would strengthen the robustness claim.
- [Eq. (8)] Notation: the symbol for the out-of-sample prediction error in Eq. (8) is easily confused with the in-sample residual; a clearer subscript would help.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and indicate the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.1, Theorem 1] §3.1, Theorem 1: the claimed asymptotic normality of the test statistic after robust variance estimation requires explicit rate conditions on the ML predictor (e.g., o_p(n^{-1/4}) uniform convergence of the fitted residuals); without these, the orthogonality argument used to separate estimation error from the prediction step may not go through under the stated mean-independence null.
Authors: We thank the referee for highlighting this point. Our proof of asymptotic normality for the test statistic relies on sample splitting to achieve Neyman orthogonality between the residual prediction step and the first-stage estimation error. However, to ensure the result holds after robust variance estimation, we agree that explicit rate conditions on the ML predictor are necessary. We will revise §3.1 to state an additional assumption requiring that the ML estimator satisfies o_p(n^{-1/4}) convergence in the relevant norm (uniformly over the instruments), and we will update the statement of Theorem 1 and the proof sketch in the appendix to incorporate this condition explicitly. This clarification does not change the main claims but makes the technical requirements precise. revision: yes
-
Referee: [§4.2, Algorithm 2] §4.2, Algorithm 2: the Anderson-Rubin inversion is described at a high level, but the paper does not specify how the critical value or the grid search is adjusted when the underlying test statistic is itself ML-based; this leaves open whether the inversion preserves exact finite-sample size or only asymptotic validity under weak instruments.
Authors: We appreciate the referee's request for greater detail. The Anderson-Rubin-style inversion is constructed to deliver asymptotic validity under weak or many instruments, inheriting the asymptotic type I error control of the underlying ML-based test; it is not designed to achieve exact finite-sample size control because of the data-dependent ML component. In the revision we will expand the description of Algorithm 2 to specify the grid-search implementation, including the use of asymptotic critical values obtained from the limiting distribution of the ML-based statistic (adjusted for the chosen significance level). We will also add an explicit remark clarifying that the procedure yields asymptotic rather than exact finite-sample validity. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The proposed residual-prediction test constructs its statistic from out-of-sample ML prediction performance on sample-split data, with asymptotic type I error control and consistency derived under the explicit mean-independence assumption. No step reduces a prediction or uniqueness claim to a fitted parameter by construction, nor does the central argument rest on self-citation chains or imported ansatzes. Standard regularity conditions and robust variance estimation support the limits without circular reduction to inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Machine learning method
axioms (1)
- domain assumption Structural error is mean independent of the instruments
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a novel test for the well-specification of the linear IV model under the assumption that the structural error is mean independent of the instruments... residual prediction: if the two-stage least squares residuals can be predicted from the instruments better than chance
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show asymptotic type I error control and consistency against a broad class of alternatives
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
σmin ED,P [ZZ T ] ≥ c,
-
[2]
σmin ED,P [ZX T ] ≥ c, 3. ED,P [ZZ T ] op ≤ C, 4. ED,P [ZX T ] op ≤ C,
-
[3]
Next, we need some kind of uniform central limit theorem and law of large numbers
∥ED,P [Zϵ]∥op ≤ C. Next, we need some kind of uniform central limit theorem and law of large numbers. Assumption 6. It holds that lim n→∞ sup P ∈P sup w∈VD,P (ζ) sup t∈R PP 1 σw √n0 X i∈D (U w i − EP [U w i ]) ≤ t ! − Φ(t) = 0 with U w i = (w(Zi) + AT wZi)ϵi. Due to the boundedness of w, this assumption can often be motivated using the Lindeberg-Feller ce...
work page 2019
-
[4]
√n0∥ˆED[Zϵ] − ED,P [Zϵ]∥2 = OP(1),
-
[5]
∥ˆED[XZ T ] − ED,P [XZ T ]∥op = oP(1), 24
-
[6]
∥ˆED[ZZ T ] − ED,P [ZZ T ]∥op = oP(1),
-
[7]
Finally, we also need a consistent estimator for the asymptotic variance σ2 w
∥ˆED[w(Z)X] − ED,P [w(Z)X]∥2 = oP,W(1). Finally, we also need a consistent estimator for the asymptotic variance σ2 w. Assumption 8. We have an estimator ˆσ2 w of σ2 w that satisfies σ2 w − ˆσ2 w = oP,W(1). Under Assumptions 5, 6, 7 and 8, we have uniform asymptotic normality of the test statistic 1√n0ˆσw P i∈D w(Zi) ˆRi. Theorem 6. Let N(w) be defined in...
-
[8]
EP [∥Zi∥2+η 2 |ϵi|2+η] ≤ C,
-
[9]
EP [∥Zi∥2+η 2 ] ≤ C,
-
[10]
EP [∥Xi∥2 2∥Zi∥2 2] < C ,
-
[11]
EP [∥Xi∥2 2] < C . Proposition 7. If Assumptions 9, 10 and 11 hold and if for all w ∈ W and P ∈ P , EP [S1(w)] = . . . = EP [SG(w)], then (31), the statement of Theorem 6, holds. In particular, (31) holds if E[ϵi|Zi] = 0 for all i ∈ N which is the null-hypothesis of interest. Remark 4. It is important to emphasize that the validity of p-values in our proc...
-
[12]
Then, it holds that ∥ ˆAn ˆBn − AnBn∥ = oP(1)
Assume that the matrices have conformable dimensions, supn∈N supP ∈P ∥An∥op < ∞ and supn∈N supP ∈P ∥Bn∥op < ∞. Then, it holds that ∥ ˆAn ˆBn − AnBn∥ = oP(1)
-
[13]
Assume that A−1 n exists for all n ∈ N and P ∈ P and that supn∈N supP ∈P ∥A−1 n ∥op < ∞. Then, it holds that ∥ ¯A−1 n − A−1 n ∥op = oP(1) (where we set ∥ ¯A−1 n − A−1 n ∥op = ∞ if ¯An is not invertible). Proof. For ease of notation, we sometimes omit the dependence on n in the following. For 1, note that by the triangle inequality and the submultiplicativ...
work page 2019
-
[14]
Hence, (27) follows using Lemma 8 and assertion 3 of Assumption 2
The latter is equal to ( Aw − Aw′)T EP [ZZ T ](Aw − Aw′) ≤ ∥EP [ZZ T ]∥op∥Aw − Aw′∥2 2 and ∥Aw − Aw′∥2 2 ≤ ∥M ∥2 op∥EP [(w(Z) − w′(Z))X]∥2 2 ≤ ∥M ∥2 opE[∥X∥2 2]∥w − w′∥2 L2. Hence, (27) follows using Lemma 8 and assertion 3 of Assumption 2. B.6 Auxiliary Lemmas Here, we collect auxiliary Lemmas for the various proofs. Lemma 11. Let (Vi)i∈N be a sequence o...
work page 2019
-
[15]
If for all δ > 0, it holds that limn→∞ supP ∈P P(|Wn| > δ) = 0, then lim n→∞ sup P ∈P sup t∈R |PP (Vn + Wn ≤ t) − Φ(t)| = 0
-
[16]
If for all δ > 0, it holds that limn→∞ supP ∈P PP (|Wn − 1| > δ) = 0, then lim n→∞ sup P ∈P sup t∈R |PP (Vn/Wn ≤ t) − Φ(t)| = 0. Lemma 14. Consider a sequence of random variables Wn = OP(1) and a sequence of random variables (Vn)n∈N such that Vn = oP(1). Then, VnWn = oP(1). Proof. Let ϵ, δ > 0. Since Wn = OP(1), we can choose M such that for all n ∈ N and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.