eLLM: Elastic Memory Management Framework for Efficient LLM Serving
Pith reviewed 2026-05-19 09:38 UTC · model grok-4.3
The pith
eLLM unifies LLM memory management by letting tensors and KV caches share an elastic GPU pool that expands into CPU memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
eLLM introduces a Virtual Tensor Abstraction that separates tensor virtual addresses from physical GPU memory, an Elastic Memory Mechanism that performs runtime inflation and deflation using CPU as an extensible buffer, and a Lightweight Scheduling Strategy with SLO-aware policies. Together these components remove the isolation between static tensor management and page-table-based KV cache virtualization that currently limits utilization.
What carries the argument
Virtual Tensor Abstraction that decouples virtual address space from physical GPU memory, enabling a unified pool for dynamic inflation and deflation.
If this is right
- Decoding throughput increases by a factor of 2.32 over current systems.
- Batch sizes for 128K-token inputs can grow by a factor of three on the same hardware.
- Memory fragmentation drops because activations, weights, and KV caches are now managed inside one elastic pool.
- SLO constraints remain satisfied through the lightweight scheduling policy that balances inflation and deflation decisions.
Where Pith is reading between the lines
- The same ballooning idea could be tested on other bursty GPU workloads such as real-time video generation or scientific simulations.
- If transfer overhead stays low, future servers might be built with tighter CPU-GPU memory integration rather than larger GPU-only memory.
- Operators could measure whether the higher utilization actually lowers total cost of ownership when serving variable-length traffic.
Load-bearing premise
Moving data between GPU and CPU memory at runtime can be done fast enough to meet strict latency targets without creating new bandwidth bottlenecks.
What would settle it
A trace showing that CPU-GPU transfers during deflation push end-to-end decoding latency above the target SLO for 128K-token batches.
Figures








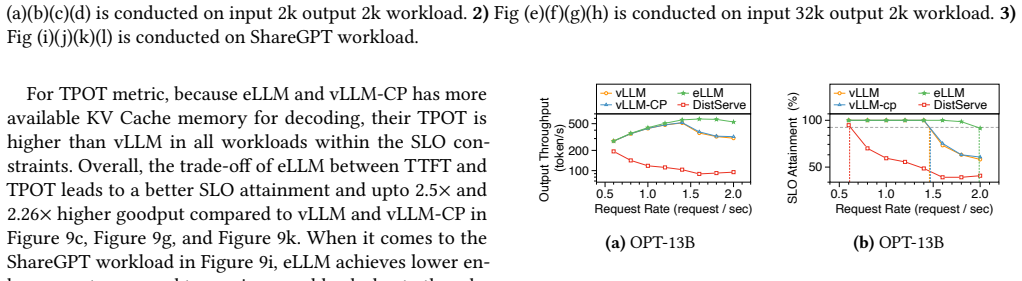
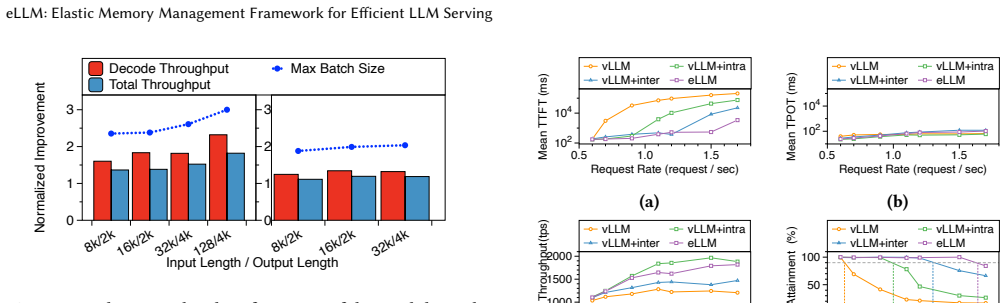
read the original abstract
Large Language Models are increasingly being deployed in datacenters. Serving these models requires careful memory management, as their memory usage includes static weights, dynamic activations, and key-value caches. While static weights are constant and predictable, dynamic components such as activations and KV caches change frequently during runtime, presenting significant challenges for efficient memory management. Modern LLM serving systems typically handle runtime memory and KV caches at distinct abstraction levels: runtime memory management relies on static tensor abstractions, whereas KV caches utilize a page table-based virtualization layer built on top of the tensor abstraction. This virtualization dynamically manages KV caches to mitigate memory fragmentation. However, this dual-level approach fundamentally isolates runtime memory and KV cache management, resulting in suboptimal memory utilization under dynamic workloads, which can lead to a nearly 20% drop in throughput. To address these limitations, we propose eLLM, an elastic memory management framework inspired by the classical memory ballooning mechanism in operating systems. The core components of eLLM include: (1) Virtual Tensor Abstraction, which decouples the virtual address space of tensors from the physical GPU memory, creating a unified and flexible memory pool; (2) an Elastic Memory Mechanism that dynamically adjusts memory allocation through runtime memory inflation and deflation, leveraging CPU memory as an extensible buffer; and (3) a Lightweight Scheduling Strategy employing SLO-aware policies to optimize memory utilization and effectively balance performance trade-offs under stringent SLO constraints. Comprehensive evaluations demonstrate that eLLM significantly outperforms state-of-the-art systems, 2.32x higher decoding throughput, and supporting 3x larger batch sizes for 128K-token inputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces eLLM, an elastic memory management framework for LLM serving that unifies runtime memory and KV cache handling. It proposes (1) Virtual Tensor Abstraction to decouple tensor virtual addresses from physical GPU memory, (2) an Elastic Memory Mechanism for runtime inflation/deflation that uses CPU memory as an extensible buffer, and (3) a Lightweight SLO-aware Scheduling Strategy. The central claims are that this approach overcomes the ~20% throughput loss of dual-level management and delivers 2.32x higher decoding throughput plus 3x larger batch sizes for 128K-token inputs versus state-of-the-art systems.
Significance. If the performance results hold under rigorous evaluation, the work could improve memory utilization and batching efficiency in LLM inference serving by adapting classical OS ballooning ideas to the GPU-CPU hierarchy. The unified abstraction and scheduler are conceptually appealing for dynamic workloads; explicit credit is due if the manuscript supplies reproducible code, detailed workload traces, or quantitative transfer-overhead measurements that allow independent verification of the SLO claims.
major comments (2)
- [§5] §5 (Evaluation) and abstract: the central 2.32x throughput and 3x batch-size claims for 128K inputs are load-bearing, yet the section supplies no experimental setup details, baseline descriptions, workload characteristics, error bars, or quantitative bounds on GPU-CPU transfer frequency/size. Given PCIe bandwidth (32-64 GB/s) versus HBM, even infrequent large KV-cache transfers could produce latency spikes the SLO scheduler cannot mask; this directly undercuts the performance claims and must be addressed with concrete measurements.
- [§3.2] §3.2 (Elastic Memory Mechanism): the description of runtime inflation/deflation and CPU buffer usage does not analyze or bound transfer latency under the SLO constraints stated in §3.3. This is load-bearing because the abstract's performance gains rest on the assumption that the lightweight scheduler hides these costs; without such analysis the mechanism's practicality remains unverified.
minor comments (1)
- [Abstract] Abstract: the statement of a 'nearly 20% drop in throughput' from the dual-level approach would be strengthened by a citation to the specific prior system or measurement that produced this figure.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate additional details and analysis.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation) and abstract: the central 2.32x throughput and 3x batch-size claims for 128K inputs are load-bearing, yet the section supplies no experimental setup details, baseline descriptions, workload characteristics, error bars, or quantitative bounds on GPU-CPU transfer frequency/size. Given PCIe bandwidth (32-64 GB/s) versus HBM, even infrequent large KV-cache transfers could produce latency spikes the SLO scheduler cannot mask; this directly undercuts the performance claims and must be addressed with concrete measurements.
Authors: We agree that §5 requires substantially more detail to support the reported performance gains. In the revised manuscript we will expand the evaluation section with: (1) complete experimental setup including hardware (GPU/CPU models, PCIe generation), software baselines (exact versions of vLLM, TensorRT-LLM, etc.), and workload characteristics (token-length distributions, batch-size ranges, and trace sources); (2) error bars and statistical significance from multiple runs; and (3) quantitative measurements of GPU–CPU transfer frequency, average and maximum transfer sizes, and their observed latency impact. We have already collected these data and will add a dedicated subsection bounding transfer overhead relative to PCIe bandwidth and demonstrating that the SLO scheduler masks spikes under the evaluated workloads. revision: yes
-
Referee: [§3.2] §3.2 (Elastic Memory Mechanism): the description of runtime inflation/deflation and CPU buffer usage does not analyze or bound transfer latency under the SLO constraints stated in §3.3. This is load-bearing because the abstract's performance gains rest on the assumption that the lightweight scheduler hides these costs; without such analysis the mechanism's practicality remains unverified.
Authors: We acknowledge the need for explicit latency analysis. In the revision we will augment §3.2 with a new subsection that (a) models and empirically bounds inflation/deflation latency as a function of KV-cache size and PCIe bandwidth, (b) reports worst-case and average-case transfer times observed in our experiments, and (c) shows how these bounds are incorporated into the SLO-aware scheduler of §3.3. The added analysis will demonstrate that the scheduler’s policies keep end-to-end latency within the stated SLOs even when occasional large transfers occur. revision: yes
Circularity Check
No circularity: claims rest on empirical evaluations of proposed architecture
full rationale
The paper describes an engineering framework (virtual tensor abstraction, elastic inflation/deflation to CPU buffer, SLO-aware scheduler) inspired by OS ballooning and evaluates it on throughput and batch-size metrics. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the derivation of the core mechanisms or the reported gains. The 2.32x throughput and 3x batch-size results are presented as outcomes of the implemented system under test rather than quantities defined in terms of themselves or prior author work. The derivation chain is therefore self-contained and externally falsifiable via the described experiments.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Virtual Tensor Abstraction
no independent evidence
-
Elastic Memory Mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Virtual Tensor Abstraction... Elastic Memory Mechanism that dynamically adjusts memory allocation through runtime memory inflation and deflation, leveraging CPU memory as an extensible buffer
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat.induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lightweight Scheduling Strategy employing SLO-aware policies
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Nair, Ilya Soloveychik, and Purushotham Kamath
Muhammad Adnan, Akhil Arunkumar, Gaurav Jain, Prashant J. Nair, Ilya Soloveychik, and Purushotham Kamath. 2024. Keyformer: KV Cache reduction through key tokens selection for Efficient Generative Inference. In Proceedings of the Seventh Annual Conference on Machine Learning and Systems, MLSys 2024, Santa Clara, CA, USA, May 13-16, 2024, Phillip B. Gibbons...
work page 2024
-
[2]
Amey Agrawal, Junda Chen, Íñigo Goiri, Ramachandran Ramjee, Chao- jie Zhang, Alexey Tumanov, and Esha Choukse. 2024. Mnemosyne: Parallelization Strategies for Efficiently Serving Multi-Million Con- text Length LLM Inference Requests Without Approximations. CoRR abs/2409.17264 (2024)
-
[3]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. In 18th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2024, Santa Clara, CA, USA, July 10-12, 2024, Ada Gavrilovska and ...
work page 2024
-
[4]
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. 2023. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023 , Houda Bouamor, Juan Pino,...
work page 2023
-
[5]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[6]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022 , Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh (Eds.)
work page 2022
-
[7]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova
-
[9]
BERT: Pre-training of Deep Bidirectional Transformers for Lan- guage Understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu- man Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers) , Jill Burstein, Christy Doran, and Th...
work page 2019
-
[10]
Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Nanning Zheng, and Furu Wei. 2023. LongNet: Scaling Transformers to 1, 000, 000, 000 Tokens. CoRR abs/2307.02486 (2023). https://doi.org/10.48550/arXiv.2307.02486
-
[11]
Cong Guo, Rui Zhang, Jiale Xu, Jingwen Leng, Zihan Liu, Ziyu Huang, Minyi Guo, Hao Wu, Shouren Zhao, Junping Zhao, and Ke Zhang. 2024. GMLake: Efficient and Transparent GPU Memory Defragmentation 12 eLLM: Elastic Memory Management Framework for Efficient LLM Serving for Large-scale DNN Training with Virtual Memory Stitching. In Proceedings of the 29th ACM...
-
[12]
Chi Han, Qifan Wang, Hao Peng, Wenhan Xiong, Yu Chen, Heng Ji, and Sinong Wang. 2024. LM-Infinite: Zero-Shot Extreme Length General- ization for Large Language Models. In Proceedings of the 2024 Confer- ence of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexi...
-
[13]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016 . IEEE Computer Society, 770–778
work page 2016
-
[14]
Ke Hong, Guohao Dai, Jiaming Xu, Qiuli Mao, Xiuhong Li, Jun Liu, Kangdi Chen, Yuhan Dong, and Yu Wang. 2024. FlashDecoding++: Faster Large Language Model Inference with Asynchronization, Flat GEMM Optimization, and Heuristics. In Proceedings of the Seventh Annual Conference on Machine Learning and Systems, MLSys 2024, Santa Clara, CA, USA, May 13-16, 2024...
work page 2024
-
[15]
Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. 2024. KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization. In Advances in Neural Information Process- ing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver...
work page 2024
-
[16]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[17]
Efficient memory management for large language model serving with pagedattention
Efficient Memory Management for Large Language Model Serving with PagedAttention. In Proceedings of the 29th Symposium on Operating Systems Principles, SOSP 2023, Koblenz, Germany, October 23-26, 2023 , Jason Flinn, Margo I. Seltzer, Peter Druschel, Antoine Kaufmann, and Jonathan Mace (Eds.). ACM, 611–626. https://doi.org/ 10.1145/3600006.3613165
-
[18]
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avashalom Manevich, Nir Rat- ner, Noam Rozen, Erez Shwartz, Mor Zusman, and Yoav Shoham
-
[19]
Jamba: A Hybrid Transformer-Mamba Language Model
Jamba: A Hybrid Transformer-Mamba Language Model. CoRR abs/2403.19887 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Hao Liu, Wilson Yan, Matei Zaharia, and Pieter Abbeel. 2024. World Model on Million-Length Video And Language With Blockwise RingAttention. CoRR abs/2402.08268 (2024). https://doi.org/10.48550/ arXiv.2402.08268
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. 2024. KIVI: A Tuning- Free Asymmetric 2bit Quantization for KV Cache. In Forty-first Inter- national Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net
work page 2024
-
[22]
OpenAI. 2023. GPT-4 Technical Report. CoRR abs/2303.08774 (2023). https://doi.org/10.48550/arXiv.2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[23]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Z. Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chil- amkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala
-
[24]
PyTorch: An Imperative Style, High-Performance Deep Learn- ing Library. In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada , Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garn...
work page 2019
-
[25]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. In 51st ACM/IEEE Annual International Symposium on Computer Architecture, ISCA 2024, Buenos Aires, Argentina, June 29 - July 3, 2024 . IEEE, 118–132
work page 2024
-
[26]
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. 2023. Efficiently Scaling Transformer Inference. In Proceedings of the Sixth Conference on Machine Learning and Systems, MLSys 2023, Miami, FL, USA, June 4-8, 2023, Dawn Song, Michael Carbin, and Tianqi Chen (Eds.). mlsys.org
work page 2023
- [27]
-
[28]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Mooncake: Trading More Storage for Less Computation - A KVCache-centric Architecture for Serving LLM Chatbot. In 23rd USENIX Conference on File and Storage Technologies, FAST 2025, Santa Clara, CA, February 25-27, 2025, Haryadi S. Gunawi ...
work page 2025
-
[29]
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. 2024. Llumnix: Dynamic Scheduling for Large Language Model Serving. In 18th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2024, Santa Clara, CA, USA, July 10-12, 2024, Ada Gavrilovska and Douglas B. Terry (Eds.). USENIX Association, 173–191
work page 2024
-
[30]
Sharegpt teams. 2023. Sharegot. https://sharegpt.com/
work page 2023
-
[31]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie- Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models. CoRR abs/2302.13971 (2023). https: //doi.org/10.48550/arXiv.2302.13971
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[32]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Alma- hairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton- Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain- of-Thought Prompting Elicits Reasoning in Large Language Models. 13 Jiale Xu, Rui Zhang, Yi Xiong, Cong Guo, Zihan Liu, Yangjie Zhou, Weiming Hu, Hao Wu, Changxu Shao, Ziqing Wang, Yongjie Yuan, Junping Zhao, Minyi Guo, and Ji...
work page 2022
-
[34]
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. 2024. LoongServe: Efficiently Serving Long-Context Large Language Models with Elastic Sequence Parallelism. In Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles, SOSP 2024, Austin, TX, USA, November 4-6, 2024 , Emmett Witchel, Christopher J. Rossbach, An...
-
[35]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient Streaming Language Models with Attention Sinks. In The Twelfth International Conference on Learning Representa- tions, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
work page 2024
-
[36]
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. 2024. Magpie: Alignment Data Synthesis from Scratch by Prompt- ing Aligned LLMs with Nothing. CoRR abs/2406.08464 (2024). https://huggingface.co/datasets/Magpie-Align/Magpie-Reasoning- V2-250K-CoT-Deepseek-R1-Llama-70B
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. In 16th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2022, Carlsbad, CA, USA, July 11-13, 2022 , Marcos K. Aguilera and Hakim Weatherspoon (Eds.). USENIX Association, 521–538
work page 2022
-
[38]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona T. Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shus- ter, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. 2022. OPT: Open Pre-trained Transformer Language Models. CoRR abs/2205.01068 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Barrett, Zhangyang Wang, and Beidi Chen
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark W. Barrett, Zhangyang Wang, and Beidi Chen. 2023. H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models. In Advances in Neural Information Processing Systems 36: Annual Confer- ence on Neural Inform...
work page 2023
-
[40]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. In 18th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2024, Santa Clara, CA, USA, July 10-12, 2024 , Ada Gavrilovska and Douglas ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.