SmokeSVD: Smoke Reconstruction from A Single View via Progressive Novel View Synthesis and Refinement with Diffusion Models
Pith reviewed 2026-05-19 04:40 UTC · model grok-4.3
The pith
SmokeSVD reconstructs dynamic 3D smoke from a single video using diffusion models for side views and progressive physical refinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SmokeSVD is an efficient and effective framework to progressively reconstruct dynamic smoke from a single video by integrating the generative capabilities of diffusion models with physically guided consistency optimization. It first proposes a physically guided side-view synthesizer based on diffusion models that explicitly incorporates velocity field constraints to generate spatio-temporally consistent side-view images frame by frame. It then iteratively refines novel-view images and reconstructs 3D density fields through a progressive multi-stage process that renders and enhances images from increasing viewing angles. Finally it estimates fine-grained density and velocity fields via diffe
What carries the argument
Physically guided side-view synthesizer based on diffusion models that incorporates velocity field constraints to generate spatio-temporally consistent side-view images frame by frame.
If this is right
- Produces high-quality multi-view image sequences from single-view input.
- Yields fine-grained 3D density and velocity fields usable for re-simulation.
- Supports downstream applications such as editing or physical re-play.
- Runs with better computational efficiency than prior optimization-heavy approaches.
Where Pith is reading between the lines
- The progressive refinement loop could be adapted to other sparse-view fluid problems such as fire or liquid reconstruction.
- Real-time video capture pipelines might incorporate the side-view synthesizer to enable live 3D smoke monitoring.
- The velocity-constrained diffusion step might transfer to non-fluid domains where temporal consistency is the main bottleneck.
Load-bearing premise
The physically guided side-view synthesizer based on diffusion models can generate spatio-temporally consistent side-view images frame by frame that sufficiently alleviate the ill-posedness of single-view reconstruction.
What would settle it
A direct test would compare the synthesized side-view smoke motion against ground-truth multi-view captures; visible temporal flickering or motion mismatch across frames, or failure of the final 3D density field to satisfy Navier-Stokes advection in controlled validation, would show the consistency step does not resolve the ill-posedness.
Figures






















read the original abstract
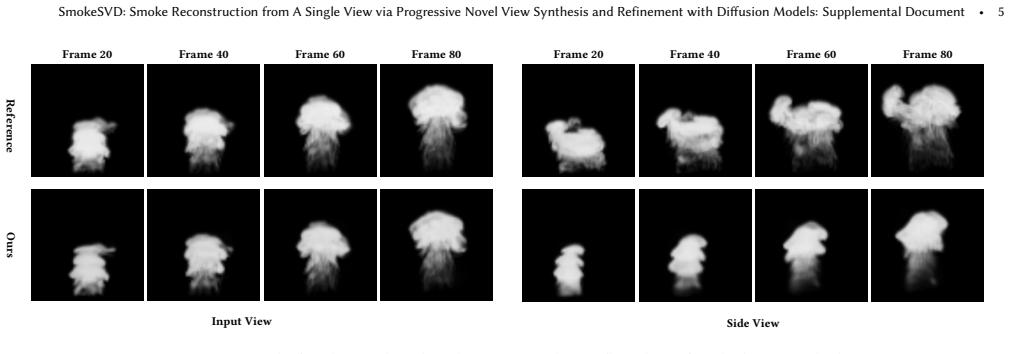
Reconstructing dynamic fluids from sparse views is a long-standing and challenging problem, due to the severe lack of 3D information from insufficient view coverage. While several pioneering approaches have attempted to address this issue using differentiable rendering or novel view synthesis, they are often limited by time-consuming optimization under ill-posed conditions. We propose SmokeSVD, an efficient and effective framework to progressively reconstruct dynamic smoke from a single video by integrating the generative capabilities of diffusion models with physically guided consistency optimization. Specifically, we first propose a physically guided side-view synthesizer based on diffusion models, which explicitly incorporates velocity field constraints to generate spatio-temporally consistent side-view images frame by frame, significantly alleviating the ill-posedness of single-view reconstruction. Subsequently, we iteratively refine novel-view images and reconstruct 3D density fields through a progressive multi-stage process that renders and enhances images from increasing viewing angles, generating high-quality multi-view sequences. Finally, we estimate fine-grained density and velocity fields via differentiable advection by leveraging the Navier-Stokes equations. Our approach supports re-simulation and downstream applications while achieving superior reconstruction quality and computational efficiency compared to state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SmokeSVD, a framework for reconstructing dynamic smoke from a single-view video. It first employs a physically guided side-view synthesizer based on diffusion models that incorporates velocity-field constraints to generate spatio-temporally consistent novel views frame by frame. This is followed by an iterative progressive multi-stage process that renders and refines images from increasing viewing angles to produce high-quality multi-view sequences and reconstruct 3D density fields. Finally, differentiable advection leveraging the Navier-Stokes equations is used to estimate fine-grained density and velocity fields, supporting re-simulation and downstream tasks. The method claims superior reconstruction quality and efficiency relative to prior state-of-the-art approaches.
Significance. If the empirical results hold, the work would constitute a meaningful contribution to single-view fluid reconstruction in computer graphics by demonstrating how diffusion-based generative models, when conditioned on physical velocity constraints and embedded in a progressive refinement pipeline, can mitigate the severe ill-posedness of the problem while preserving physical consistency for re-simulation. The explicit combination of generative synthesis with differentiable physics is a timely and practical direction.
major comments (1)
- [Abstract / Method description of side-view synthesizer] The central claim that the side-view synthesizer 'significantly alleviates the ill-posedness' (abstract) rests on the assumption that velocity-field-conditioned diffusion outputs are sufficiently spatio-temporally consistent. No quantitative evaluation of this consistency (e.g., temporal coherence metrics, optical-flow consistency scores, or ablation on the velocity conditioning) is referenced in the provided description; without such evidence the downstream reconstruction quality gains cannot be attributed to this component.
minor comments (2)
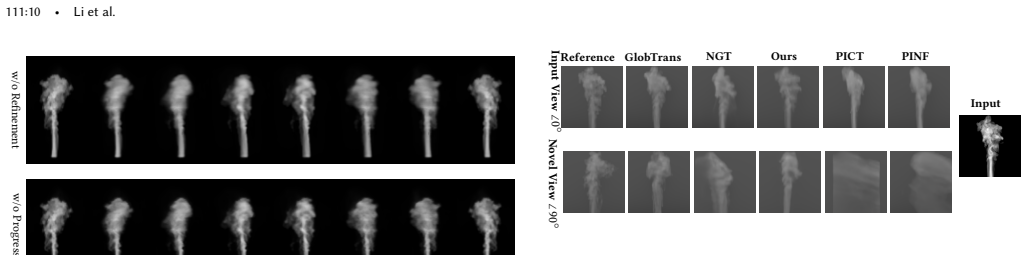
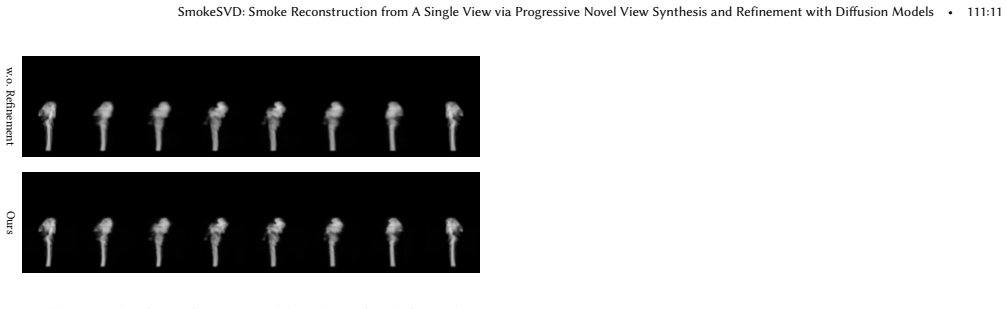
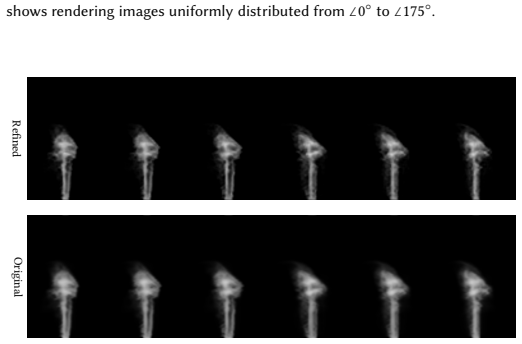
- [Method] The progressive multi-stage refinement process is described at a high level; a diagram or pseudocode outlining the exact sequence of view-angle increments and refinement iterations would improve clarity.
- [Experiments] Comparison to prior work would benefit from explicit citation of the specific baselines used for both reconstruction quality and runtime measurements.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation for minor revision. We address the major comment on the side-view synthesizer below.
read point-by-point responses
-
Referee: [Abstract / Method description of side-view synthesizer] The central claim that the side-view synthesizer 'significantly alleviates the ill-posedness' (abstract) rests on the assumption that velocity-field-conditioned diffusion outputs are sufficiently spatio-temporally consistent. No quantitative evaluation of this consistency (e.g., temporal coherence metrics, optical-flow consistency scores, or ablation on the velocity conditioning) is referenced in the provided description; without such evidence the downstream reconstruction quality gains cannot be attributed to this component.
Authors: We appreciate the referee highlighting the need for quantitative support. The current manuscript demonstrates spatio-temporal consistency primarily through qualitative visual results and the downstream improvements in reconstruction quality and re-simulation. We agree that explicit metrics would strengthen attribution to the velocity conditioning. In the revised version we will add temporal coherence and optical-flow consistency scores together with an ablation isolating the velocity-field constraint. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's pipeline begins with a diffusion-based side-view synthesizer that incorporates velocity field constraints drawn from external Navier-Stokes physics, then proceeds to progressive multi-stage novel-view refinement and final density/velocity estimation via differentiable advection. No step reduces a claimed prediction or first-principles result to a fitted parameter or self-referential definition by construction. The abstract and method outline treat the physical constraints and diffusion priors as independent inputs rather than outputs of the reconstruction itself. No load-bearing self-citations or ansatz smuggling are described. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
progressive multi-stage process that renders and enhances images from increasing viewing angles
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mengyu Chu, Lingjie Liu, Quan Zheng, Erik Franz, Hans-Peter Seidel, Christian Theobalt, and Rhaleb Zayer. 2022. Physics informed neural fields for smoke reconstruction with sparse data. ACM Transactions on Graphics (ToG) 41, 4 (2022), 1–14
work page 2022
-
[2]
Marie-Lena Eckert, Kiwon Um, and Nils Thuerey. 2019. ScalarFlow: a large-scale volumetric data set of real-world scalar transport flows for computer animation and machine learning. ACM Transactions on Graphics (TOG) 38, 6 (2019), 1–16. 8 • Li et al. Ref Input View 1 Input View 2 Unseen View 1 Unseen View 2 2-G𝜌 4-G𝜌 8-G𝜌 16-G𝜌 Scene 1 Input View 1 Input V...
work page 2019
-
[3]
Erik Franz, Barbara Solenthaler, and Nils Thuerey. 2021. Global transport for fluid reconstruction with learned self-supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 1632–1642
work page 2021
- [4]
-
[5]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems 30 Fig. 14. Comparison of the gradient of reconstructed velocity fields by SvDiff with different loss functions at various time...
work page 2017
-
[6]
Theodore Kim, Nils Thürey, Doug James, and Markus Gross. 2008. Wavelet turbulence for fluid simulation. ACM Transactions on Graphics (TOG) 27, 3 (2008), 1–6
work page 2008
-
[7]
Sheng Qiu, Chen Li, Changbo Wang, and Hong Qin. 2021. A Rapid, End-to- end, Generative Model for Gaseous Phenomena from Limited Views. Computer Graphics Forum 40, 6 (2021), 242–257
work page 2021
-
[8]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2020. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020). SmokeSVD: Smoke Reconstruction from A Single View via Progressive Novel View Synthesis and Refinement with Diffusion Models: Supplemental Document • 9
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[9]
Yiming Wang, Siyu Tang, and Mengyu Chu. 2024. Physics-Informed Learning of Characteristic Trajectories for Smoke Reconstruction. In ACM SIGGRAPH 2024 Conference Papers. Association for Computing Machinery, New York, NY, USA, Article 53, 11 pages. doi:10.1145/3641519.3657483
-
[10]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13, 4 (2004), 600–612
work page 2004
-
[11]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[12]
In Proceedings of the IEEE conference on computer vision and pattern recognition
The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition . 586–595
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.