Blurring Mean Shift for Clustering Functional Data: A Scalable Algorithm and Convergence Analysis
Pith reviewed 2026-05-19 04:44 UTC · model grok-4.3
The pith
Blurring mean shift converges for functional data in Hilbert space with a stochastic variant that approximates the full updates for large subsets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The full blurring functional mean shift procedure converges, and when the subset size is sufficiently large the one-step update of the stochastic variant is well approximated by the corresponding update of the full algorithm.
What carries the argument
The blurring kernel applied iteratively to shift functional observations toward density modes inside the Hilbert space.
If this is right
- Clustering proceeds without any preset number of groups.
- The method applies directly to infinite-dimensional observations such as time series or spatial profiles.
- Random partitioning reduces per-iteration cost while preserving the direction of each shift for sufficiently large subsets.
- Convergence of the full procedure supplies a stopping criterion and reliability guarantee for the iterates.
Where Pith is reading between the lines
- The same stochastic-partition idea could be tested on other kernel-based functional clustering routines to check whether one-step approximation still holds.
- Simulation studies that track the distance between full and stochastic trajectories as subset size grows would quantify the approximation rate left implicit in the analysis.
- The Hilbert-space contraction condition might be relaxed to other Banach spaces if the kernel is adjusted accordingly.
Load-bearing premise
The functional observations are elements of a Hilbert space and the blurring kernel is chosen so that the iterative map remains well-defined and contractive in that space.
What would settle it
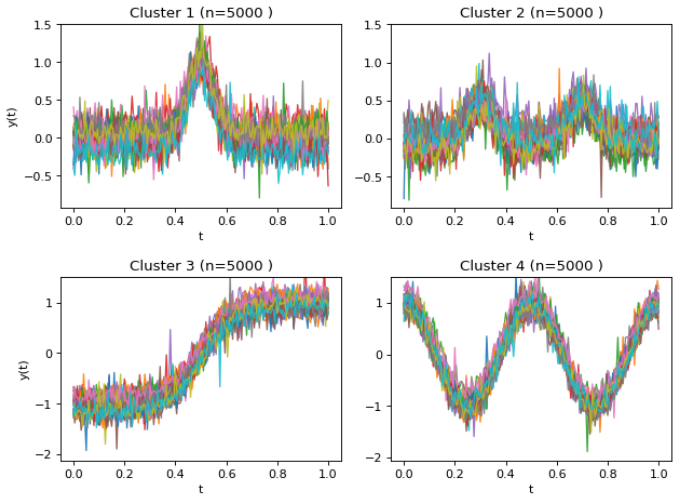
Run the full and stochastic procedures on the hourly Taiwan PM2.5 data or Argo profiles and measure whether the one-step cluster assignments diverge materially once subset size exceeds a moderate fraction of the total sample.
Figures





read the original abstract
This paper extends the blurring mean shift algorithm from vector-valued data to functional data, enabling effective clustering in infinite-dimensional settings without requiring specification of the number of clusters. To address the computational challenges posed by large-scale datasets, we introduce a fast stochastic variant that significantly reduces computational complexity. We provide a rigorous convergence analysis for the full blurring functional mean shift procedure, establishing theoretical guarantees for its iterative behavior. For the stochastic variant, we provide partial theoretical justification by showing that, when the subset size is sufficiently large, its one-step update is well approximated by the corresponding update of the full algorithm. The proposed method is demonstrated through real-data applications, including hourly Taiwan PM$_{2.5}$ measurements and Argo oceanographic profiles. Our key contributions include: (1) extending the blurring mean shift algorithm to functional data in a Hilbert-space setting; (2) developing a scalable stochastic variant based on random partitioning for large-scale data; (3) establishing convergence results for the full blurring functional mean shift algorithm; and (4) demonstrating the scalability and practical usefulness of the proposed method through simulation and real-data applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends the blurring mean shift algorithm to functional data in a Hilbert-space setting for clustering without pre-specifying the number of clusters. It introduces a stochastic variant based on random partitioning to reduce computational cost for large datasets and supplies a convergence analysis for the full deterministic procedure together with a partial result showing that the one-step update of the stochastic variant approximates the full update when the subset size is sufficiently large. The approach is illustrated on hourly Taiwan PM2.5 data and Argo oceanographic profiles.
Significance. If the stated convergence results hold under the Hilbert-space assumptions, the work supplies a theoretically supported, cluster-number-free method for functional data clustering that scales to large samples. The combination of an infinite-dimensional formulation with a stochastic approximation addresses a practical bottleneck in functional data analysis, and the real-data examples indicate applicability to environmental and oceanographic monitoring.
major comments (1)
- Abstract and contributions (4): the partial justification for the stochastic variant is limited to a one-step approximation result. Because the algorithm is iterative, establishing that the stochastic procedure converges requires controlling the accumulation of approximation errors across successive iterations; the manuscript does not provide a uniform-in-iteration error bound or invoke a contraction argument that would prevent error propagation, leaving the overall reliability of the stochastic variant for clustering unverified.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. We address the major comment below.
read point-by-point responses
-
Referee: Abstract and contributions (4): the partial justification for the stochastic variant is limited to a one-step approximation result. Because the algorithm is iterative, establishing that the stochastic procedure converges requires controlling the accumulation of approximation errors across successive iterations; the manuscript does not provide a uniform-in-iteration error bound or invoke a contraction argument that would prevent error propagation, leaving the overall reliability of the stochastic variant for clustering unverified.
Authors: We appreciate the referee's observation on this point. The manuscript explicitly describes the result for the stochastic variant as a one-step approximation (see abstract and Section 4), rather than a full convergence guarantee for the iterative procedure. We agree that controlling accumulated approximation errors over multiple iterations would require additional technical arguments, such as a uniform bound or contraction mapping, which are not developed here. In the revised manuscript we will update the abstract and the list of contributions to state more precisely that the stochastic analysis is limited to the one-step case, and we will add a short remark in the discussion section noting that error propagation across iterations remains open for future work. This change will align the stated claims with the actual theorems while preserving the practical motivation and empirical evidence for the stochastic variant. revision: yes
Circularity Check
No circularity: convergence analysis and one-step approximation are independently derived
full rationale
The paper establishes convergence results for the full blurring functional mean shift algorithm in a Hilbert-space setting and separately shows that the stochastic variant's one-step update approximates the full update for large subset sizes. No equations reduce a claimed prediction or convergence guarantee to a fitted parameter or self-referential definition by construction. The provided abstract and contributions list no load-bearing self-citations that justify the central claims, nor any ansatz smuggled via prior work by the same authors. The derivation chain remains self-contained against external benchmarks such as standard mean-shift convergence arguments in functional spaces, yielding no detectable circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Functional observations belong to a Hilbert space in which the mean-shift operator is well-defined
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the notion of a 'surrogate density' ρ(f | {f_i}) = n⁻¹ Σ K_h(‖f−f_i‖_H) … the functional mean shift operator M(f | {f_i}) … Theorem 1 (Convergence properties) … monotonic increase of the average surrogate density … Gâteaux derivative …
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our analysis is carried out in L²([0,1]) … no pointwise smoothness assumptions …
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Springer Science & Business Media, 2000
Denis Bosq.Linear Processes in Function Spaces: Theory and Applications, volume 149. Springer Science & Business Media, 2000
work page 2000
-
[2]
Ling-Jyh Chen, Yao-Hua Ho, Hu-Cheng Lee, Hsuan-Cho Wu, Hao-Min Liu, Hsin-Hung Hsieh, Yu-Te Huang, and Shih-Chun Candice Lung. An open framework for partic- ipatory pm2.5 monitoring in smart cities.IEEE Access, 5:14441–14454, 2017. doi: 10.1109/ACCESS.2017.2723919
-
[3]
On the convergence and consistency of the blurring mean-shift process
Ting-Li Chen. On the convergence and consistency of the blurring mean-shift process. Annals of the Institute of Statistical Mathematics, 67(1):157–176, 2015
work page 2015
-
[4]
Yizong Cheng. Mean shift, mode seeking, and clustering.IEEE Transactions on Pattern Analysis and Machine Intelligence, 17(8):790–799, 1995
work page 1995
-
[5]
The functional mean-shift algorithm for mode hunting and clustering in infinite dimensions
Mattia Ciollaro, Christopher Genovese, Jing Lei, and Larry Wasserman. The functional mean-shift algorithm for mode hunting and clustering in infinite dimensions.arXiv preprint arXiv:1408.1187, 2014. 32
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[6]
Dorin Comaniciu and Peter Meer. Mean shift: A robust approach toward feature space analysis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(5):603–619, 2002
work page 2002
-
[7]
Fr´ ed´ eric Ferraty, Nadia Kudraszow, and Philippe Vieu. Nonparametric estimation of a surrogate density function in infinite-dimensional spaces.Journal of Nonparametric Statis- tics, 24(2):447–464, 2012. doi: 10.1080/10485252.2012.671943. URLhttps://doi.org/ 10.1080/10485252.2012.671943
-
[8]
Keinosuke Fukunaga and Larry Hostetler. The estimation of the gradient of a density function, with applications in pattern recognition.IEEE Transactions on Information Theory, 21(1):32–40, 1975
work page 1975
-
[9]
Journal of Classification , year=1985, volume=
Lawrence Hubert and Phipps Arabie. Comparing partitions.Journal of Classification, 2 (1):193–218, 1985. doi: 10.1007/BF01908075
-
[10]
Tsay.Statistical Learning for Big Dependent Data
Daniel Pe˜ na and Ruey S. Tsay.Statistical Learning for Big Dependent Data. John Wiley and Sons, Inc., Hoboken, NJ, 2021
work page 2021
-
[11]
Shang-Ying Shiu, Yen-Shiu Chin, Szu-Han Lin, and Ting-Li Chen. Randomized self- updating process for clustering large-scale data.Statistics and Computing, 34(1):47, 2024
work page 2024
-
[12]
Annie PS Wong, Susan E Wijffels, Stephen C Riser, Sylvie Pouliquen, Shigeki Hosoda, Dean Roemmich, John Gilson, Gregory C Johnson, Kim Martini, David J Murphy, et al. Argo data 1999–2019: Two million temperature-salinity profiles and subsurface velocity observations from a global array of profiling floats.Frontiers in Marine Science, 7:700, 2020
work page 1999
-
[13]
Ryoya Yamasaki and Toshiyuki Tanaka. Convergence analysis of mean shift.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 46(10):6688–6698, 2024
work page 2024
-
[14]
A functional-data approach to the argo data
Drew Yarger, Stilian Stoev, and Tailen Hsing. A functional-data approach to the argo data. The Annals of Applied Statistics, 16(1):216–246, 2022. 33
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.