Agentic AI and Hallucinations
Pith reviewed 2026-05-19 03:12 UTC · model grok-4.3
The pith
AI agents exert more verification effort when facing users who most fear hallucinations, raising prices in accuracy-sensitive sectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
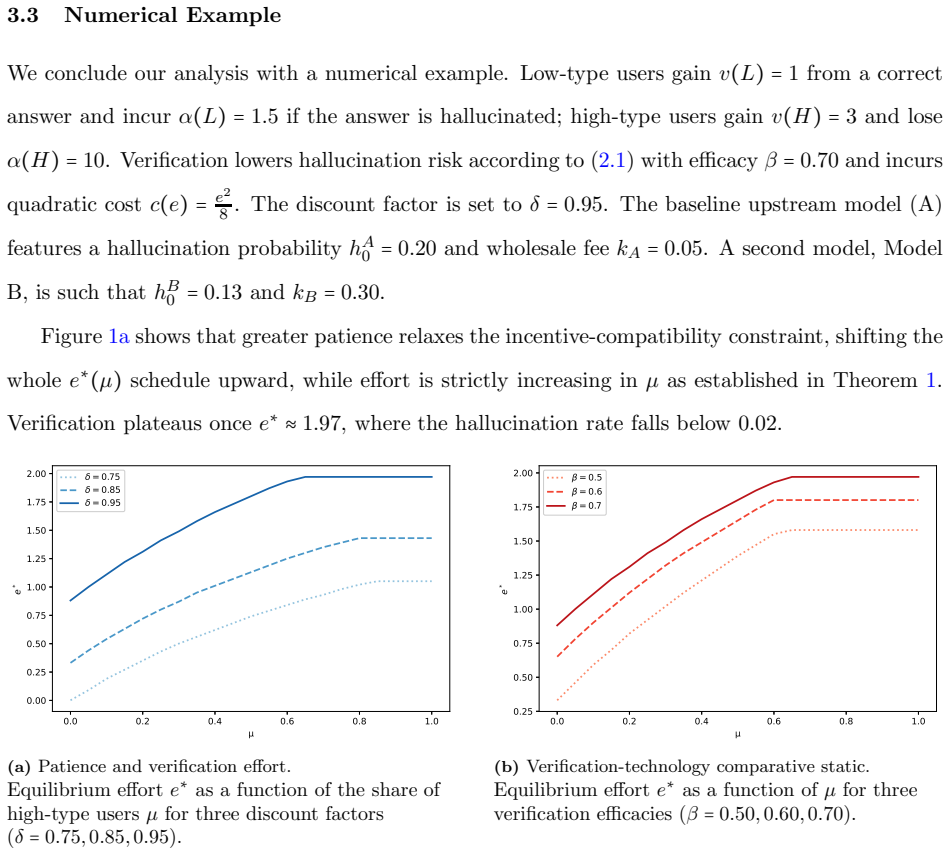
A unique reputational equilibrium exists under nontrivial discounting. The equilibrium effort, and thus the price, increases with the share of users who have high accuracy concerns, implying that hallucination-sensitive sectors, such as law and medicine, endogenously lead to more serious verification efforts in agentic AI markets.
What carries the argument
The reputational equilibrium created by permanent interaction halts after hallucinations, which disciplines agents through the loss of all future rents and creates incentives for costly verification.
If this is right
- Equilibrium verification effort and prices rise as the share of high-accuracy users grows.
- Sectors with strong accuracy demands, such as law and medicine, endogenously produce more reliable AI services.
- Competitive pricing reflects differences in user accuracy concerns across market segments.
- Nontrivial discounting is required for the equilibrium to be unique.
Where Pith is reading between the lines
- The same permanent-loss mechanism could apply to other AI errors if they also terminate user relationships.
- Raising user awareness of accuracy risks could improve overall verification levels across the market.
- The market may segment over time into high-verification services for concerned users and lower-cost options for tolerant ones.
Load-bearing premise
A hallucination causes the interaction to halt permanently, thereby disciplining agents through the loss of all future rents from that user.
What would settle it
Data on whether AI agents serving legal or medical clients show measurably higher verification rates or prices than agents serving entertainment or casual users.
Figures

read the original abstract
We model a competitive market where AI agents buy answers from upstream generative models and resell them to users who differ in how much they value accuracy and in how much they fear hallucinations. Agents can privately exert effort for costly verification to lower hallucination risks. Since interactions halt in the event of a hallucination, the threat of losing future rents disciplines effort. A unique reputational equilibrium exists under nontrivial discounting. The equilibrium effort, and thus the price, increases with the share of users who have high accuracy concerns, implying that hallucination-sensitive sectors, such as law and medicine, endogenously lead to more serious verification efforts in agentic AI markets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models a competitive market in which AI agents purchase outputs from upstream generative models and resell them to heterogeneous users who differ in their valuation of accuracy and their aversion to hallucinations. Agents privately choose costly verification effort that reduces the probability of hallucinations. The central modeling assumption is that a detected hallucination permanently terminates the relationship with that user, so that the loss of all future rents disciplines effort. Under nontrivial discounting the model yields a unique reputational equilibrium; equilibrium verification effort and the resulting market price both rise with the measure of high-accuracy-concern users. The paper concludes that hallucination-sensitive sectors such as law and medicine will therefore induce higher endogenous verification effort.
Significance. If the equilibrium characterization is correct, the paper supplies a clean reputational mechanism that links user heterogeneity to verification incentives in agentic-AI markets. The comparative-static result offers a theoretical rationale for why professional domains may observe more careful agent behavior without external mandates. The contribution lies in embedding a standard repeated-game discipline device inside a competitive market for AI services; its value depends on whether the permanent-halt assumption can be relaxed without overturning the main prediction.
major comments (3)
- [§2] §2 (model primitives): the incentive-compatibility constraint for verification effort equates marginal cost to the discounted loss of all future rents only because the continuation value after a hallucination is set to zero for that user-agent pair. The paper should derive the equilibrium effort level explicitly under a positive continuation probability (e.g., user forgiveness or switching) and show whether the comparative static on the share of high-accuracy users survives; without this check the load-bearing role of the permanent-halt assumption remains untested.
- [§3, Proposition 1] §3, Proposition 1: uniqueness of the reputational equilibrium is asserted under nontrivial discounting, yet the proof sketch is not supplied. The argument appears to rely on a contraction-mapping or fixed-point property of the best-reply correspondence; an explicit statement of the mapping and the conditions on the discount factor that guarantee uniqueness would allow readers to assess whether the result is robust to small changes in the user-type distribution.
- [§4] §4 (comparative statics): the claim that equilibrium effort rises with the share of high-accuracy users follows from the shift in the effective continuation value when the population composition changes. The paper should report the derivative of equilibrium effort with respect to this share (or the relevant cross-partial) and confirm that it remains positive when the hallucination probability is allowed to depend on effort in a non-linear way.
minor comments (2)
- [§2] Notation for the user-type distribution and the effort cost function should be introduced once in §2 and used consistently thereafter; several equations reuse symbols without redefinition.
- [Abstract] The abstract states existence and the comparative static without any functional forms or proof outline; a one-sentence sketch of the key incentive constraint in the abstract would improve accessibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We respond to each major point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§2] §2 (model primitives): the incentive-compatibility constraint for verification effort equates marginal cost to the discounted loss of all future rents only because the continuation value after a hallucination is set to zero for that user-agent pair. The paper should derive the equilibrium effort level explicitly under a positive continuation probability (e.g., user forgiveness or switching) and show whether the comparative static on the share of high-accuracy users survives; without this check the load-bearing role of the permanent-halt assumption remains untested.
Authors: We agree that the zero-continuation-value assumption after a detected hallucination is central to generating strict incentives for verification. This choice is motivated by the permanent reputational damage observed in professional domains. To address the concern directly, we will add an extension in the revised Section 2 that introduces a continuation probability γ ∈ (0,1) (capturing forgiveness or user switching). We derive the modified incentive-compatibility condition and show analytically that the equilibrium effort remains strictly increasing in the share of high-accuracy users provided γ is below a threshold that depends on the discount factor. The main comparative static therefore survives for plausible values of γ. revision: yes
-
Referee: [§3, Proposition 1] §3, Proposition 1: uniqueness of the reputational equilibrium is asserted under nontrivial discounting, yet the proof sketch is not supplied. The argument appears to rely on a contraction-mapping or fixed-point property of the best-reply correspondence; an explicit statement of the mapping and the conditions on the discount factor that guarantee uniqueness would allow readers to assess whether the result is robust to small changes in the user-type distribution.
Authors: We acknowledge that the uniqueness argument was only sketched. In the revision we will supply a complete proof in an appendix. We define the best-reply mapping T that sends a candidate effort profile to the optimal verification level given the induced continuation values. We then show that T is a contraction with modulus β(1-ε) < 1 whenever the discount factor β is sufficiently close to 1 and the type distribution satisfies a mild continuity condition. This establishes uniqueness and also clarifies the robustness to small perturbations in the user-type measure. revision: yes
-
Referee: [§4] §4 (comparative statics): the claim that equilibrium effort rises with the share of high-accuracy users follows from the shift in the effective continuation value when the population composition changes. The paper should report the derivative of equilibrium effort with respect to this share (or the relevant cross-partial) and confirm that it remains positive when the hallucination probability is allowed to depend on effort in a non-linear way.
Authors: We will report the explicit derivative de*/dμ in the revised Section 4, where μ denotes the measure of high-accuracy users. The sign is positive because an increase in μ raises the average continuation value that disciplines effort. For non-linear hallucination technologies (e.g., exponential or convex specifications), we will add a short analytical argument and a numerical illustration confirming that the relevant cross-partial remains positive under standard convexity of the verification cost function. These additions will be included in the revised manuscript. revision: partial
Circularity Check
No circularity: standard repeated-game IC derivation from explicit modeling assumptions
full rationale
The paper posits a competitive market for AI agents who exert costly verification effort, with the explicit assumption that a hallucination permanently halts the interaction for that user-agent pair. This converts the problem into an infinitely repeated moral-hazard setting whose incentive-compatibility constraint equates marginal verification cost to the discounted loss of continuation rents. The claimed unique equilibrium under nontrivial discounting and the comparative static (effort and price rising in the measure of high-accuracy users) are direct consequences of solving that IC constraint under the stated population composition; they are not definitions or renamings of the inputs. No self-citation, fitted parameter, or ansatz is invoked to close the derivation. The model is therefore self-contained against its own primitives.
Axiom & Free-Parameter Ledger
free parameters (2)
- discount factor
- share of high-accuracy users
axioms (2)
- domain assumption A hallucination terminates the relationship and eliminates all future rents from that user.
- domain assumption Agents can privately choose costly verification effort that reduces hallucination probability.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Since interactions halt in the event of a hallucination, the threat of losing future rents disciplines effort. ... c(e) ≤ δ[h(m,0)−h(m,e)] VC
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Equilibrium effort e* is strictly increasing in the share of high-type users μ
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Asgari, E., N. Monta \ n a-Brown, M. Dubois, S. Khalil, J. Balloch, J. A. Yeung, and D. Pimenta (2025). A Framework to Assess Clinical Safety and Hallucination Rates of LLMs for Medical Text Summarisation . npj Digital Medicine\/ 8\/ (1), 274
work page 2025
-
[2]
Athey, S. C., K. A. Bryan, and J. S. Gans (2020). The allocation of decision authority to human and artificial intelligence. AEA Papers and Proceedings\/ 110 , 80--84
work page 2020
- [3]
-
[4]
Canayaz, M. (2025). AI Agency . Available at SSRN 5109326\/
work page 2025
-
[5]
Colback, L. (2025). AI Agents: From Co-pilot to Autopilot . https://www.ft.com/content/3e862e23-6e2c-4670-a68c-e204379fe01f. [Accessed 22-07-2025]
work page 2025
- [6]
-
[7]
Levin, J. (2003). Relational incentive contracts. American Economic Review\/ 93\/ (3), 835--857
work page 2003
- [8]
-
[9]
Shavit, Y., S. Agarwal, M. Brundage, S. Adler, C. O’Keefe, R. Campbell, T. Lee, P. Mishkin, T. Eloundou, A. Hickey, et al. (2023). Practices for Governing Agentic AI Systems . Research Paper, OpenAI\/
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.