SGEMM-cube: Precision-Recovery FP32 GEMM Approximation on Ascend NPUs with FP16 Matrix Engines
Pith reviewed 2026-05-19 02:54 UTC · model grok-4.3
The pith
SGEMM-cube approximates FP32 GEMM on Ascend NPUs' FP16 engines by splitting inputs into high and residual FP16 parts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SGEMM-cube demonstrates that a two-component FP32-to-FP16 splitting strategy, reconstructing the product from high-high and high-low terms while omitting the low-low term, allows FP32-accuracy GEMM approximation on FP16-only Ascend NPU matrix engines. Analysis of round-to-nearest conversion, underflow, residual scaling, and accumulation order under the Ascend execution model clarifies the range and accuracy limitations, and standard high-performance GEMM techniques are adapted to the software-managed memory hierarchy, enabling up to 65.3 TFLOP/s or 77 percent of the FP32-equivalent peak defined by the three-GEMM decomposition cost.
What carries the argument
The two-component FP32-to-FP16 splitting strategy, in which each FP32 operand is represented by an FP16 high component and a scaled FP16 residual component, with the matrix product reconstructed from the dominant high-high and high-low terms.
Load-bearing premise
All input magnitudes lie within the representable FP16 dynamic range and the truncation error from omitting the low-low term plus round-to-nearest conversion, underflow, and accumulation-order effects remain acceptable.
What would settle it
Measuring relative error on a set of inputs with magnitudes exceeding FP16 range or verifying whether accuracy on moderate-range inputs fails to approach FP32 SGEMM levels when run on Ascend 910A hardware.
Figures









read the original abstract
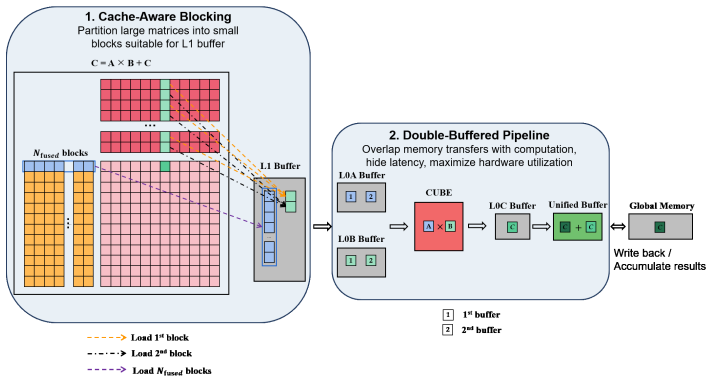
Modern AI accelerators provide high-throughput low-precision matrix engines, but their support for FP32 GEMM is often limited or inefficient. This work presents SGEMM-cube, a precision-recovery FP32 GEMM approximation on Ascend NPUs using FP16 Cube units. Rather than claiming bit-exact FP32 approximation, SGEMM-cube targets near-FP32 accuracy for inputs whose magnitudes are representable within the FP16 dynamic range. The method follows a two-component FP32-to-FP16 splitting strategy related to Ozaki-style and Ootomo-style schemes: each FP32 operand is represented by an FP16 high component and a scaled FP16 residual component, and the matrix product is reconstructed from the dominant high-high and high-low terms while omitting the low-low term. The main contribution of this paper is not a new splitting paradigm, but an architecture-specific realization and analysis of this precision-recovery scheme on Ascend NPUs. We analyze the effects of round-to-nearest conversion, underflow, residual scaling, and accumulation order under the Ascend execution model, and clarify the range and accuracy limitations of the approach. We further adapt standard high-performance GEMM techniques, including L1-aware blocking and double-buffered pipelining, to the software-managed memory hierarchy of Ascend NPUs. Experiments on Ascend 910A show that SGEMM-cube recovers substantially higher accuracy than native FP16 GEMM and approaches FP32 SGEMM accuracy for moderate-range inputs, while achieving up to 65.3 TFLOP/s, corresponding to 77\% of the FP32-equivalent peak defined by the three-GEMM decomposition cost. These results demonstrate that FP32-accuracy GEMM approximation can be made practical on FP16-only NPU matrix engines, provided that its range, error, and implementation constraints are explicitly managed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SGEMM-cube, a precision-recovery approximation for FP32 GEMM on Ascend NPUs using FP16 Cube matrix engines. It uses a two-component splitting strategy where each FP32 operand is split into an FP16 high part and a scaled FP16 residual, reconstructs the product from high-high and high-low terms (omitting low-low), analyzes effects of round-to-nearest, underflow, residual scaling, and accumulation order, adapts L1-aware blocking and double-buffered pipelining for the NPU's software-managed memory, and reports experimental results on Ascend 910A achieving up to 65.3 TFLOP/s (77% of the FP32-equivalent three-GEMM peak) with substantially higher accuracy than native FP16 GEMM for moderate-range inputs.
Significance. If the reported results hold, this work is significant for showing a practical hardware-specific way to obtain near-FP32 accuracy GEMM on FP16-only matrix engines, addressing a limitation in many AI accelerators. It earns credit for the explicit analysis of round-to-nearest conversion, underflow, and accumulation order under the Ascend model, the adaptation of standard GEMM optimizations to the software-managed hierarchy, and the concrete, falsifiable throughput (65.3 TFLOP/s) and accuracy measurements against an externally defined three-GEMM peak. These elements provide useful benchmarks and implementation guidance for mixed-precision computing on NPUs.
minor comments (3)
- [Abstract] Abstract: the phrase 'approaches FP32 SGEMM accuracy' would be strengthened by a brief quantitative statement of the observed error reduction (e.g., orders of magnitude or relative error ranges) for the moderate-range regime.
- [Analysis section] The residual scaling factor is listed as a free parameter; a short table or paragraph showing its chosen value and sensitivity to underflow on Ascend would improve reproducibility.
- [Experiments] Experiments: input matrix generation for the moderate-range tests should be described more precisely (distribution, magnitude bounds) to allow independent verification of the accuracy claims.
Simulated Author's Rebuttal
We thank the referee for the constructive summary and positive evaluation of the significance of SGEMM-cube. The recommendation for minor revision is noted, and we appreciate the recognition of the architecture-specific analysis, error modeling, and concrete throughput/accuracy results. No specific major comments appear in the provided report, so we have no point-by-point rebuttals to offer at this stage. We remain ready to incorporate any editorial or minor clarifications in the revised version.
Circularity Check
No significant circularity
full rationale
The paper describes an architecture-specific implementation and empirical evaluation of a known two-component FP32-to-FP16 splitting approach (explicitly related to prior Ozaki-style and Ootomo-style schemes) on Ascend NPUs. It analyzes hardware effects such as round-to-nearest conversion, underflow, residual scaling, and accumulation order under the Ascend model, then reports measured accuracy and throughput (65.3 TFLOP/s reaching 77% of an externally defined three-GEMM peak). No equations, fitted parameters, or self-citations reduce the reported results to quantities defined inside the paper; the central claims rest on direct measurement against external benchmarks and acknowledged range limitations rather than internal derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- residual scaling factor
axioms (1)
- standard math Standard round-to-nearest-even behavior and dynamic-range limits of IEEE FP16 and FP32
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The method decomposes each FP32 operand into two FP16 values... tunable scaling strategy... termwise accumulation scheme... cache-aware blocking and double-buffered pipeline... 77% of the FP32-equivalent theoretical peak
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Rules 1 and 2 collectively define the allowable bounds for the scaling exponent sb... sb = 12 is a reasonable and robust choice
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
H. Yu, H. Li, H. Shi, T. S. Huang, G. Hua, Any-precision deep neur al networks, in: Proceedings of the AAAI Conference on Artificial In telli- gence, Vol. 35, 2021, pp. 10763–10771
work page 2021
- [2]
-
[3]
A. Vansteenkiste, J. Leliaert, M. Dvornik, M. Helsen, F. Garcia- Sanchez, B. Van Waeyenberge, The design and verification of mumax3, AIP ad - vances 4 (10) (2014)
work page 2014
-
[4]
G. P. M¨ uller, M. Hoffmann, C. Dißelkamp, D. Sch¨ urhoff, S. Mavro s, M. Sallermann, N. S. Kiselev, H. J´ onsson, S. Bl¨ ugel, Spirit: Multi- functional framework for atomistic spin simulations, Physical revie w b 99 (22) (2019) 224414
work page 2019
-
[5]
B. D. Wozniak, F. D. Witherden, F. P. Russell, P. E. Vincent, P. H. Kelly, Gimmik—generating bespoke matrix multiplication kernels for accelerators: Application to high-order computational fluid dynam ics, Computer Physics Communications 202 (2016) 12–22
work page 2016
-
[6]
M. Cawkwell, E. Sanville, S. Mniszewski, A. M. Niklasson, Computing the density matrix in electronic structure theory on graphics proc essing units, Journal of chemical theory and computation 8 (11) (2012) 4094– 4101
work page 2012
-
[7]
P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia , B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh, et al., Mixed precision training, arXiv preprint arXiv:1710.03740 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [8]
-
[9]
A. Haidar, S. Tomov, J. Dongarra, N. J. Higham, Harnessing gpu ten- sor cores for fast fp16 arithmetic to speed up mixed-precision iter ative refinement solvers, in: SC18: International Conference for High Perfor- mance Computing, Networking, Storage and Analysis, IEEE, 2018, pp. 603–613
work page 2018
-
[10]
N. J. Higham, T. Mary, Mixed precision algorithms in numerical linea r algebra, Acta Numerica 31 (2022) 347–414
work page 2022
-
[11]
H. Liao, J. Tu, J. Xia, H. Liu, X. Zhou, H. Yuan, Y. Hu, Ascend: a scalable and unified architecture for ubiquitous deep neural netw ork computing: Industry track paper, in: 2021 IEEE International S ym- posium on High-Performance Computer Architecture (HPCA), IEE E, 2021, pp. 789–801
work page 2021
- [12]
-
[13]
S. Markidis, S. W. Der Chien, E. Laure, I. B. Peng, J. S. Vetter , Nvidia tensor core programmability, performance & precision, in: 2018 IE EE international parallel and distributed processing symposium works hops (IPDPSW), IEEE, 2018, pp. 522–531
work page 2018
-
[14]
B. Feng, Y. Wang, G. Chen, W. Zhang, Y. Xie, Y. Ding, Egemm-tc : ac- celerating scientific computing on tensor cores with extended prec ision, in: Proceedings of the 26th ACM SIGPLAN symposium on principles and practice of parallel programming, 2021, pp. 278–291
work page 2021
- [15]
-
[16]
M. Fasi, N. J. Higham, M. Mikaitis, S. Pranesh, Numerical behavio r of nvidia tensor cores, PeerJ Computer Science 7 (2021) e330
work page 2021
-
[17]
Z. Ma, H. Wang, G. Feng, C. Zhang, L. Xie, J. He, S. Chen, J. Zh ai, Ef- ficiently emulating high-bitwidth computation with low-bitwidth hard- ware, in: Proceedings of the 36th ACM International Conference on Supercomputing, 2022, pp. 1–12. 23
work page 2022
-
[18]
G. Li, J. Xue, L. Liu, X. Wang, X. Ma, X. Dong, J. Li, X. Feng, Un- leashing the low-precision computation potential of tensor cores o n gpus, in: 2021 IEEE/ACM International Symposium on Code Generation an d Optimization (CGO), IEEE, 2021, pp. 90–102
work page 2021
-
[19]
W. Kahan, Ieee standard 754 for binary floating-point arithme tic, Lec- ture Notes on the Status of IEEE 754 (94720-1776) (1996) 11. 24
work page 1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.