A Bayesian approach to model uncertainty in single-cell genomic data
Pith reviewed 2026-05-19 01:24 UTC · model grok-4.3
The pith
A variational Bayesian framework assigns probabilistic cluster memberships to single-cell genomic data rather than fixed identities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
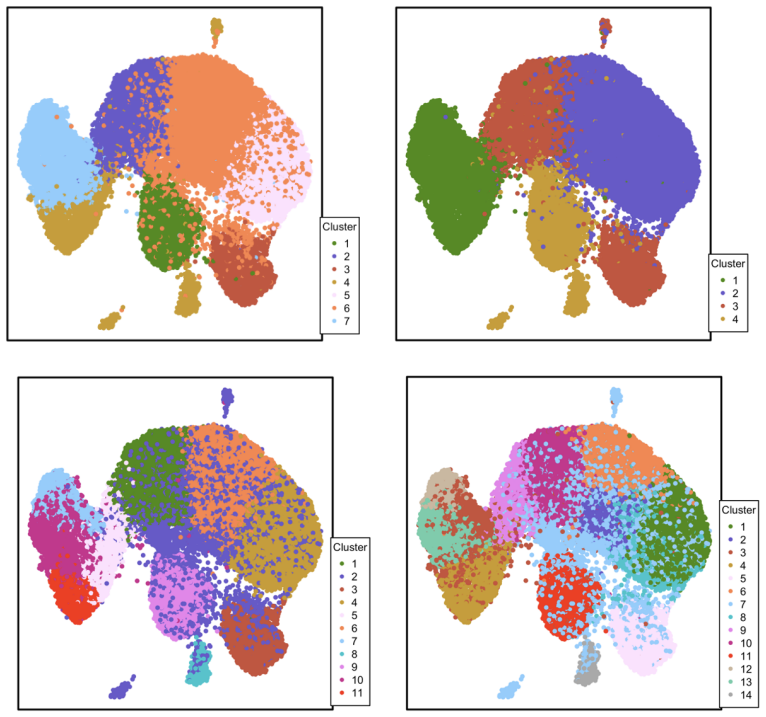
This study introduces a variational Bayesian framework for clustering and analysing single-cell genomic data, employing a Bayesian Gaussian mixture model to estimate the probabilistic association of cells with distinct clusters. This approach captures cellular transitions, yielding biologically coherent insights into neurogenesis and breast cancer progression. The inferred clustering probabilities enable further analyses, including Differential Expression Analysis and pseudotime analysis. Furthermore, we propose utilising the misclustering rate and Area Under the Curve in clustering scRNA-seq data as an innovative metric to quantitatively evaluate overall clustering performance.
What carries the argument
Bayesian Gaussian mixture model with variational inference to estimate probabilistic cell-to-cluster associations
Load-bearing premise
Single-cell genomic count data is well-represented by a Bayesian Gaussian mixture model whose variational approximation yields reliable probabilistic cluster assignments without substantial bias from the inference method or data preprocessing choices.
What would settle it
Independent single-cell datasets of neurogenesis or breast cancer progression in which the probabilistic assignments fail to align with established marker genes for transitional states or fail to improve pseudotime ordering relative to hard clustering.
Figures















read the original abstract
Network models provide a powerful framework for analysing single-cell count data, facilitating the characterisation of cellular identities, disease mechanisms, and developmental trajectories. However, uncertainty modeling in unsupervised learning with genomic data remains insufficiently explored. Conventional clustering methods assign a singular identity to each cell, potentially obscuring transitional states during differentiation or mutation. This study introduces a variational Bayesian framework for clustering and analysing single-cell genomic data, employing a Bayesian Gaussian mixture model to estimate the probabilistic association of cells with distinct clusters. This approach captures cellular transitions, yielding biologically coherent insights into neurogenesis and breast cancer progression. The inferred clustering probabilities enable further analyses, including Differential Expression Analysis and pseudotime analysis. Furthermore, we propose utilising the misclustering rate and Area Under the Curve in clustering scRNA-seq data as an innovative metric to quantitatively evaluate overall clustering performance. This methodological advancement enhances the resolution of single-cell data analysis, enabling a more nuanced characterisation of dynamic cellular identities in development and disease.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a variational Bayesian framework based on a Gaussian mixture model for unsupervised clustering of single-cell genomic count data. The approach aims to model uncertainty in cell identities via probabilistic cluster assignments rather than hard clustering, thereby capturing transitional states during processes such as neurogenesis and breast cancer progression. The inferred probabilities are used to support downstream tasks including differential expression analysis and pseudotime inference, and the authors propose misclustering rate together with AUC as quantitative metrics for evaluating clustering performance on scRNA-seq data.
Significance. If the variational approximation produces reliable soft assignments that are not materially distorted by the Gaussian likelihood on normalized count data, the method could offer a principled way to quantify uncertainty in single-cell clustering and improve resolution of dynamic cellular trajectories. The explicit proposal of misclustering rate and AUC as evaluation metrics is a concrete, falsifiable contribution that could be adopted more broadly if shown to correlate better with biological ground truth than conventional indices.
major comments (2)
- [Abstract / Methods] Abstract and Methods: The central claim that the variational Bayesian GMM yields reliable probabilistic assignments capturing cellular transitions rests on the assumption that a Gaussian likelihood (after normalization) adequately represents single-cell count data. Single-cell counts are discrete, zero-inflated, and overdispersed; the Gaussian model implicitly assumes symmetric continuous errors and homoscedasticity, which can bias posterior probabilities near cluster boundaries. The manuscript should either replace the likelihood with a count-appropriate model (e.g., negative binomial) or provide quantitative checks (e.g., posterior predictive diagnostics or comparison of transition probabilities against known marker gradients) demonstrating that the approximation does not introduce systematic bias in the neurogenesis and breast-cancer results.
- [Results] Results: The abstract asserts that the framework yields 'biologically coherent insights' into neurogenesis and breast cancer progression and that the probabilities enable further analyses, yet no quantitative validation details, baseline comparisons (e.g., against standard GMM, Leiden, or scVI), or error analysis are supplied in the visible text. Without these, the support for the utility claim remains qualitative and the load-bearing assertion that the method improves resolution of transitional states cannot be evaluated.
minor comments (1)
- [Methods / Evaluation] The manuscript should define the misclustering rate and AUC explicitly (including how ground-truth labels are obtained for the AUC calculation) and compare them against established metrics such as adjusted Rand index or normalized mutual information on the same datasets.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major point below and indicate the revisions that will be incorporated into the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: The central claim that the variational Bayesian GMM yields reliable probabilistic assignments capturing cellular transitions rests on the assumption that a Gaussian likelihood (after normalization) adequately represents single-cell count data. Single-cell counts are discrete, zero-inflated, and overdispersed; the Gaussian model implicitly assumes symmetric continuous errors and homoscedasticity, which can bias posterior probabilities near cluster boundaries. The manuscript should either replace the likelihood with a count-appropriate model (e.g., negative binomial) or provide quantitative checks (e.g., posterior predictive diagnostics or comparison of transition probabilities against known marker gradients) demonstrating that the approximation does not introduce systematic bias in the neurogenesis and breast-cancer results.
Authors: We agree that the Gaussian likelihood after normalization represents an approximation to the discrete, zero-inflated nature of raw scRNA-seq counts. Our implementation follows the standard preprocessing pipeline used across the field (log-transformation, scaling, and selection of highly variable genes) to render the data suitable for continuous mixture modeling. To directly evaluate whether this approximation introduces systematic bias in the soft assignments, the revised manuscript will add posterior predictive checks: we will draw replicated datasets from the fitted variational posterior and compare their marginal distributions against the observed normalized data. In addition, we will quantify the alignment between inferred cluster-transition probabilities and known marker-gene gradients along the neurogenesis trajectory. These diagnostics will be reported in a new subsection of the Results. revision: yes
-
Referee: [Results] Results: The abstract asserts that the framework yields 'biologically coherent insights' into neurogenesis and breast cancer progression and that the probabilities enable further analyses, yet no quantitative validation details, baseline comparisons (e.g., against standard GMM, Leiden, or scVI), or error analysis are supplied in the visible text. Without these, the support for the utility claim remains qualitative and the load-bearing assertion that the method improves resolution of transitional states cannot be evaluated.
Authors: The manuscript already reports quantitative performance via the proposed misclustering rate and AUC on both simulated and real data, together with downstream differential-expression and pseudotime results that demonstrate utility. Nevertheless, to make the comparative evaluation fully explicit, the revised Results section will include side-by-side benchmarks against a standard (non-Bayesian) GMM, Leiden clustering, and scVI, using the same misclustering-rate and AUC metrics. These additions will directly quantify the improvement in resolution of transitional states. revision: yes
Circularity Check
Standard variational Bayesian GMM application shows no circular derivation
full rationale
The paper applies a variational Bayesian Gaussian mixture model to single-cell count data for probabilistic clustering, as described in the abstract. No equations, derivations, or self-citations are presented that reduce the claimed outputs (probabilistic assignments, DE analysis, pseudotime) to inputs by construction. The framework is positioned as a standard unsupervised learning method whose results enable downstream analyses, with proposed metrics (misclustering rate, AUC) serving as independent evaluation tools rather than tautological re-expressions of fitted parameters. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Single-cell genomic count data can be modeled as arising from a Gaussian mixture distribution in a suitable latent space.
- domain assumption Variational inference provides a sufficiently accurate approximation to the posterior for probabilistic cluster assignments.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
employing a Bayesian Gaussian mixture model to estimate the probabilistic association of cells with distinct clusters... likelihood is a mixture of Gaussians... posterior estimate of the cluster assignment probability
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
regularised graph Laplacian... singular value decomposition... asymptotically multivariate Gaussian distributed in the spectral embeddings
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat_induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dirichlet distribution is used to model the mixture weights... Variational Bayesian estimation of a Gaussian Mixture Model (VB-GMM)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Breast cancer at-risk: n = 25636 cells, p = 16822 RNA transcripts
-
[2]
Embryo cortical development: n = 41734 cells, p = 16862 RNA transcripts. This test dataset incorporates all the embryo cortical data in V1 region from gestational week 17 to gestational week 22, representing the broadest range of gestational weeks allowed for research with human embryos due to ethical constraints. 13 4.2 Specification of our statistical m...
work page 1982
-
[3]
A stochastic network approach to clustering and visualising single-cell genomic count data
Bartlett TE, Chandna S, Roy S. A stochastic network approach to clustering and visualising single-cell genomic count data. arXiv preprint arXiv:230302498. 2023
work page 2023
-
[4]
Feature selection and dimension reduction for single-cell RNA-Seq based on a multinomial model
Townes FW, Hicks SC, Aryee MJ, Irizarry RA. Feature selection and dimension reduction for single-cell RNA-Seq based on a multinomial model. Genome biology. 2019;20:1-16. 19
work page 2019
-
[5]
Regularized spectral clustering under the degree-corrected stochastic blockmodel
Qin T, Rohe K. Regularized spectral clustering under the degree-corrected stochastic blockmodel. Advances in neural information processing systems. 2013;26
work page 2013
-
[6]
Modularity and community structure in networks
Newman ME. Modularity and community structure in networks. Proceedings of the national academy of sciences. 2006;103(23):8577-82
work page 2006
-
[7]
A statistical interpretation of spectral embedding: the generalised random dot product graph
Rubin-Delanchy P , Cape J, Tang M, Priebe CE. A statistical interpretation of spectral embedding: the generalised random dot product graph. Journal of the Royal Statistical Society Series B: Statistical Methodology. 2022;84(4):1446-73
work page 2022
-
[8]
Mammary stem cells and progenitors: targeting the roots of breast cancer for prevention
Tharmapalan P , Mahendralingam M, Berman HK, Khokha R. Mammary stem cells and progenitors: targeting the roots of breast cancer for prevention. The EMBO journal. 2019;38(14):e100852
work page 2019
-
[9]
The pivotal roles of the epithelial membrane protein family in cancer invasiveness and metastasis
Ahmat Amin MKB, Shimizu A, Ogita H. The pivotal roles of the epithelial membrane protein family in cancer invasiveness and metastasis. Cancers. 2019;11(11):1620
work page 2019
-
[10]
KLF6-SV1 drives breast cancer metastasis and is associated with poor survival
Hatami R, Sieuwerts AM, Izadmehr S, Y ao Z, Qiao RF , Papa L, et al. KLF6-SV1 drives breast cancer metastasis and is associated with poor survival. Science translational medicine. 2013;5(169):169ra12-2
work page 2013
-
[11]
Endothelin-1 Enriched Tumor Phenotype Predicts Breast Cancer Recurrence
Tamkus D, Sikorskii A, Gallo KA, Wiese DA, Leece C, Madhukar BV, et al. Endothelin-1 Enriched Tumor Phenotype Predicts Breast Cancer Recurrence. International Scholarly Research Notices. 2013;2013(1):385398
work page 2013
-
[12]
How mechanisms of stem cell polarity shape the human cerebral cortex
Andrews MG, Subramanian L, Salma J, Kriegstein AR. How mechanisms of stem cell polarity shape the human cerebral cortex. Nature Reviews Neuroscience. 2022;23(12):711-24
work page 2022
-
[13]
De Rosa A, Pellegatta S, Rossi M, Tunici P , Magnoni L, Speranza MC, et al. A radial glia gene marker, fatty acid binding protein 7 (FABP7), is involved in proliferation and invasion of glioblastoma cells. PloS one. 2012;7(12):e52113
work page 2012
-
[14]
Dok5 is involved in the signaling pathway of neurotrophin-3 against TrkC-induced apoptosis
Pan Y , Zhang J, Liu W, Shu P , Yin B, Yuan J, et al. Dok5 is involved in the signaling pathway of neurotrophin-3 against TrkC-induced apoptosis. Neuroscience letters. 2013;553:46-51
work page 2013
-
[15]
Variational inference for Dirichlet process mixtures
Blei DM, Jordan MI. Variational inference for Dirichlet process mixtures. Journal of Bayesian Analysis. 2006;1(1):121-44
work page 2006
-
[16]
Newson R. Parameters behind “nonparametric” statistics: Kendall’s tau, Somers’ D and median differences. The Stata Journal. 2002;2(1):45-64. B Additional information Funding This work was supported in part by the Research Innovation Fund awarded by Birkbeck, University of London, UK. License 20
work page 2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.