Robust fuzzy clustering with cellwise outliers
Pith reviewed 2026-05-19 00:46 UTC · model grok-4.3
The pith
Fuzzy clustering detects and corrects individual outlying cells by using relationships among variables that are specific to each cluster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a robust fuzzy clustering procedure can simultaneously control the fuzziness of unit assignments and identify outlying cells by exploiting the cluster-specific relationships among variables that the fuzzy approach itself uncovers, thereby correcting those cells without discarding the rest of the information in a contaminated row.
What carries the argument
The joint procedure that couples fuzzy membership degrees with cellwise outlier detection and imputation, letting the memberships highlight reliable cells and the within-cluster variable relationships serve as the basis for correction.
If this is right
- Reliable cells inside contaminated cases remain available for cluster assignment instead of being lost.
- Cluster-specific variable relationships improve the accuracy of cellwise outlier identification.
- Tuning parameters allow users to balance fuzziness against robustness to contamination.
- Simulation studies and real-data examples show the method works under cellwise contamination scenarios.
Where Pith is reading between the lines
- The same idea of using fuzzy memberships to guide cell correction might transfer to other partitioning methods that produce soft assignments.
- In very high dimensions the approach could reduce the need for separate imputation steps before clustering.
- Users could test whether the corrected data matrix yields downstream predictions or visualizations that are more stable than those from casewise robust alternatives.
Load-bearing premise
The fuzzy clustering step can still recover accurate cluster-specific variable relationships even when some individual cells are contaminated.
What would settle it
Apply the method to a simulated data set with known cellwise outliers and check whether the detected and corrected cells match the planted anomalies more closely than a standard fuzzy clustering run followed by separate outlier screening.
Figures























read the original abstract
In a data matrix, we may distinguish between cases, each represented by a row vector for a statistical unit, and cells, which correspond to single entries of the data matrix. Recent developments in Robust Statistics have introduced the cellwise contamination paradigm, which assumes contamination on cells rather than on entire cases. This approach becomes particularly relevant as the number of variables increases. Indeed, discarding or downweighting entire cases because of a few anomalous cells in them, as done by traditional (casewise) robust methods, can result in substantial information loss, since the non-contaminated (or reliable) cells can still be highly informative. This philosophy can also be considered in fuzzy clustering, by assuming that reliable cells within a case may still provide useful information for determining fuzzy memberships. A robust fuzzy clustering proposal is thus introduced in this work, combining the advantages of dealing with outlying cells and simultaneously controlling the degree of fuzziness of unit assignments. The cluster-specific relationships among variables, detected by the fuzzy clustering approach, are also key to better identifying outlying cells and correct them. The strengths of the proposed methodology are illustrated through a simulation study and two real-world applications. The effects of the model's tuning parameters are explored, and some guidance for users on how to set them suitably is provided.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a robust fuzzy clustering method for data matrices subject to cellwise contamination. It combines fuzzy membership assignments with mechanisms to detect and correct outlying cells by exploiting cluster-specific variable relationships, thereby avoiding the information loss of traditional casewise robust approaches. The proposal is evaluated via a simulation study and two real-world applications, with exploration of tuning parameters for fuzziness and outlier detection.
Significance. If the iterative procedure reliably recovers cluster structures and relationships under cellwise noise, the work would meaningfully extend robust statistics and fuzzy clustering to high-dimensional settings where partial contamination is common. The dual focus on controlling assignment fuzziness while using detected relationships for cell correction represents a potentially useful synthesis, provided the fixed-point behavior is stable.
major comments (2)
- [Abstract / Algorithm] Abstract and method description: The central claim that 'the cluster-specific relationships among variables detected by the fuzzy clustering approach are key to better identifying outlying cells and correct them' depends on the fuzzy procedure reliably estimating those relationships even when cellwise contamination is present. No breakdown-point analysis or consistency result for the alternation between membership updates and cell corrections is supplied, leaving open the risk that early-iteration distance metrics biased by contamination produce self-reinforcing errors rather than accurate imputations.
- [Simulation study] Simulation study: While the effects of tuning parameters are explored, the description supplies no concrete performance metrics (e.g., adjusted Rand index, cellwise false-positive rates) or comparison against existing cellwise-robust or fuzzy methods under controlled contamination levels. This weakens the empirical support for the claim that the approach outperforms casewise alternatives without substantial information loss.
minor comments (2)
- [Abstract] The abstract is clear but would benefit from a one-sentence statement of the objective function or key update rules to allow readers to gauge technical novelty immediately.
- [Tuning parameters] Guidance on setting the tuning parameters for fuzziness and outlier detection is provided, yet explicit default values or a data-driven selection procedure would improve usability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [Abstract / Algorithm] Abstract and method description: The central claim that 'the cluster-specific relationships among variables detected by the fuzzy clustering approach are key to better identifying outlying cells and correct them' depends on the fuzzy procedure reliably estimating those relationships even when cellwise contamination is present. No breakdown-point analysis or consistency result for the alternation between membership updates and cell corrections is supplied, leaving open the risk that early-iteration distance metrics biased by contamination produce self-reinforcing errors rather than accurate imputations.
Authors: We acknowledge the absence of a formal breakdown-point analysis or consistency result for the iterative alternation. The proposed method relies on an alternating optimization scheme in which fuzzy memberships and cell corrections are updated sequentially, with the simulations demonstrating stable recovery of cluster structures and variable relationships across contamination levels. To address the concern, we will add a discussion subsection on the iterative procedure, its initialization, and the empirical safeguards against self-reinforcing errors, while clarifying that the contribution is primarily methodological and simulation-supported rather than theoretical. revision: yes
-
Referee: [Simulation study] Simulation study: While the effects of tuning parameters are explored, the description supplies no concrete performance metrics (e.g., adjusted Rand index, cellwise false-positive rates) or comparison against existing cellwise-robust or fuzzy methods under controlled contamination levels. This weakens the empirical support for the claim that the approach outperforms casewise alternatives without substantial information loss.
Authors: We agree that explicit quantitative metrics and direct comparisons would strengthen the empirical evidence. The current simulation section explores tuning-parameter effects and illustrates performance, but we will revise it to report adjusted Rand index values for clustering accuracy, cellwise false-positive and false-negative rates for outlier detection, and comparisons against representative cellwise-robust and fuzzy clustering baselines under controlled contamination scenarios. These additions will provide clearer support for the advantages over casewise approaches. revision: yes
Circularity Check
No significant circularity; proposal integrates existing robust cellwise and fuzzy clustering concepts without reducing claims to inputs by construction.
full rationale
The paper proposes a new algorithm for robust fuzzy clustering under cellwise contamination, alternating between membership estimation and cell correction using cluster-specific relationships. No equations or steps in the abstract or described method show a result defined in terms of itself, a fitted parameter renamed as a prediction, or a central claim justified solely by overlapping self-citation. The approach is presented as building on prior robust statistics literature with new integration, validated via simulations and real data, rendering the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- tuning parameters for fuzziness and outlier detection
Forward citations
Cited by 1 Pith paper
-
Cellwise Outliers
Cellwise outliers can contaminate over half the cases even at low proportions, necessitating specialized robust techniques for location, covariance, regression, PCA, and tensor data that differ from casewise approaches.
Reference graph
Works this paper leans on
-
[1]
J. MacQueen, Some methods for classification and analysis of multivari- ate observations, in: Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics, Univer- sity of California Press, Berkeley, Calif., 1967, pp. 281–297
work page 1967
-
[2]
G. H. Ball, D. J. Hall, A clustering technique for summarizing multi- variate data, Syst. Res. 12 (1967) 153–155
work page 1967
-
[3]
G. J. McLachlan, D. Peel, Finite mixture models, Wiley, New York, 2000
work page 2000
-
[4]
Bezdek, Pattern recognition with fuzzy objective function algorithms, Plenum Press, New York, 1981
J. Bezdek, Pattern recognition with fuzzy objective function algorithms, Plenum Press, New York, 1981
work page 1981
-
[5]
J. C. Dunn, A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters, J. Cybernet. 3 (3) (1973) 32–57. 34
work page 1973
-
[6]
D. E. Gustafson, W. C. Kessel, Fuzzy clustering with a fuzzy covariance matrix, in: Proceedings of the IEEE lnternational Conference on Fuzzy Systems, San Diego, 1979, p. 761–766
work page 1979
-
[7]
E. Trauwaert, L. Kaufman, P. Rousseeuw, Fuzzy clustering algorithms based on the maximum likelihood priciple, Fuzzy Sets Syst. 42 (2) (1991) 213–227
work page 1991
-
[8]
P. J. Rousseeuw, E. Trauwaert, L. Kaufman, Fuzzy clustering using scatter matrices, Comput. Stat. Data Anal. 23 (1) (1996) 135–151
work page 1996
-
[9]
P. J. Rousseeuw, E. Trauwaert, L. Kaufman, Fuzzy clustering with high contrast, J. Comput. Appl. Math. 64 (1) (1995) 81–90
work page 1995
-
[10]
P. J. Huber, Robust estimation of a location parameter, Ann. Math. Stat. 35 (1) (1964) 73–101
work page 1964
-
[11]
L. A. Garc´ ıa-Escudero, A. Gordaliza, C. Matr´ an, A. Mayo-´Iscar, A gen- eral trimming approach to robust cluster analysis, Ann. Stat. 36 (3) (2008) 1324–1345
work page 2008
- [12]
-
[13]
P. J. Rousseeuw, Least median of squares regression, J. Am. Stat. Assoc. 79 (388) (1984) 871–880
work page 1984
-
[14]
P. J. Rousseeuw, Multivariate estimation with high breakdown point, in: W. Grossmann, G. Pflug, I. Vincze, W. Wertz (Eds.), Mathematical Statistics and Applications, 1985, pp. 283–297
work page 1985
-
[15]
R. N. Dave, Characterization and detection of noise in clustering, Pat- tern Recognit. 12 (11) (1991) 657–664
work page 1991
-
[16]
F. Alqallaf, S. Van Aelst, V. J. Yohai, R. H. Zamar, Propagation of outliers in multivariate data, Ann. Stat. 37 (1) (2009) 311–331
work page 2009
-
[17]
J. Raymaekers, P. J. Rousseeuw, The cellwise minimum covariance de- terminant estimator, J. Am. Stat. Assoc. 119 (548) (2023) 2610–2621
work page 2023
-
[18]
D. B. Rubin, Inference and missing data, Biometrika 63 (3) (1976) 581– 592. 35
work page 1976
-
[19]
A. P. Dempster, N. M. Laird, D. B. Rubin, Maximum likelihood from incomplete data via the EM algorithm, J. R. Stat. Soc., Series B (Sta- tistical Methodology) 39 (1) (1977) 1–38
work page 1977
-
[20]
G. Zaccaria, L. Garc´ ıa-Escudero, F. Greselin, A. Mayo- ´Iscar, Cellwise outlier detection in heterogeneous populations, Technometrics (2025) 1–16doi:10.1080/00401706.2025.2497822
-
[21]
P. Puchhammer, I. Wilms, P. Filzmoser, A smooth multi-group Gaussian Mixture Model for cellwise robust covariance estimation, arXiv (2025) https://doi.org/10.48550/arXiv.2504.02547
-
[22]
J. Raymaekers, P. J. Rousseeuw, Challenges of cell- wise outliers, Econometrics and Statistics (2024) https://doi.org/10.1016/j.ecosta.2024.02.002
-
[23]
Z. Ghahramani, M. Jordan, Learning from incomplete data, Tech. Rep. AI Lab Memo No. 1509, CBCL Paper No. 108, MIT AI Lab (1995)
work page 1995
- [24]
-
[25]
Hampel, Beyond location parameters: robust concepts and methods, Bull
F. Hampel, Beyond location parameters: robust concepts and methods, Bull. Int. Stat. Inst. 46 (1) (1975) 375–382
work page 1975
- [26]
-
[27]
Robust fuzzy clustering with cellwise outliers
L. Garc´ ıa-Escudero, A. Mayo-Iscar, Robust clustering based on trim- ming, Wiley Interdiscip. Rev. Comput. Stat. 16 (4) (2024) e1658. 36 Supplementary Material to “Robust fuzzy clustering with cellwise outliers” This document includes the supplementary material to the main article “Robust fuzzy clustering with cellwise outliers”. Specifically, it contain...
work page 2024
-
[28]
Additional results on the effects of the tuning parameters In Figure 18, we display the ∆ ij values with α = 0.05 for the last three variables of the artificial data set, whose generation is detailed in the main article (first example). As also for the first two variables, the choice of α = 0.05, which corresponds to the true level of contamination in the...
work page 2000
-
[29]
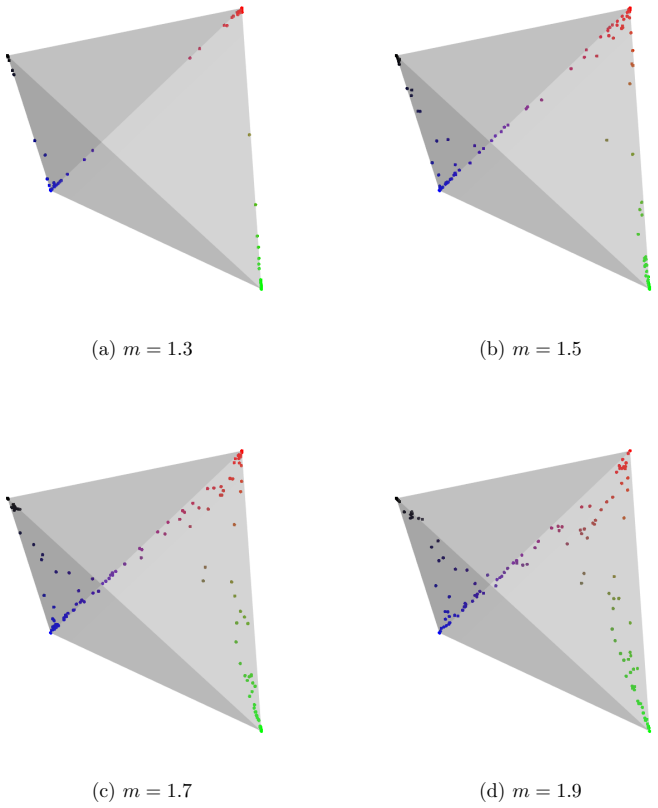
Additional results for the real data analyses 7.1. Body fat data set The preliminary analysis described in Section 4.1 of the main article on the body fat data set allows us to choose the fuzzifier parameter m. Specif- ically, we select m by examining the fuzzification obtained by cellFCLUST. Recalling that we select c = 2 to avoid obtaining only one elon...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.