Non-Intrusive Automatic Speech Recognition Refinement: A Survey
Pith reviewed 2026-05-21 23:31 UTC · model grok-4.3
The pith
Non-intrusive ASR refinement methods fall into five main classes, supported by a proposed set of standardized comparison metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that non-intrusive refinement of ASR systems, which preserves the original model architecture, can be grouped into five classes—fusion, re-scoring, correction, distillation, and training adjustment—each covering distinct families of methods with identifiable strengths and suitable application contexts. It further claims that reviewing domain adaptation techniques, cataloging common datasets, and introducing a standardized metric set will enable more consistent evaluation and help close identified research gaps in building more robust transcription pipelines.
What carries the argument
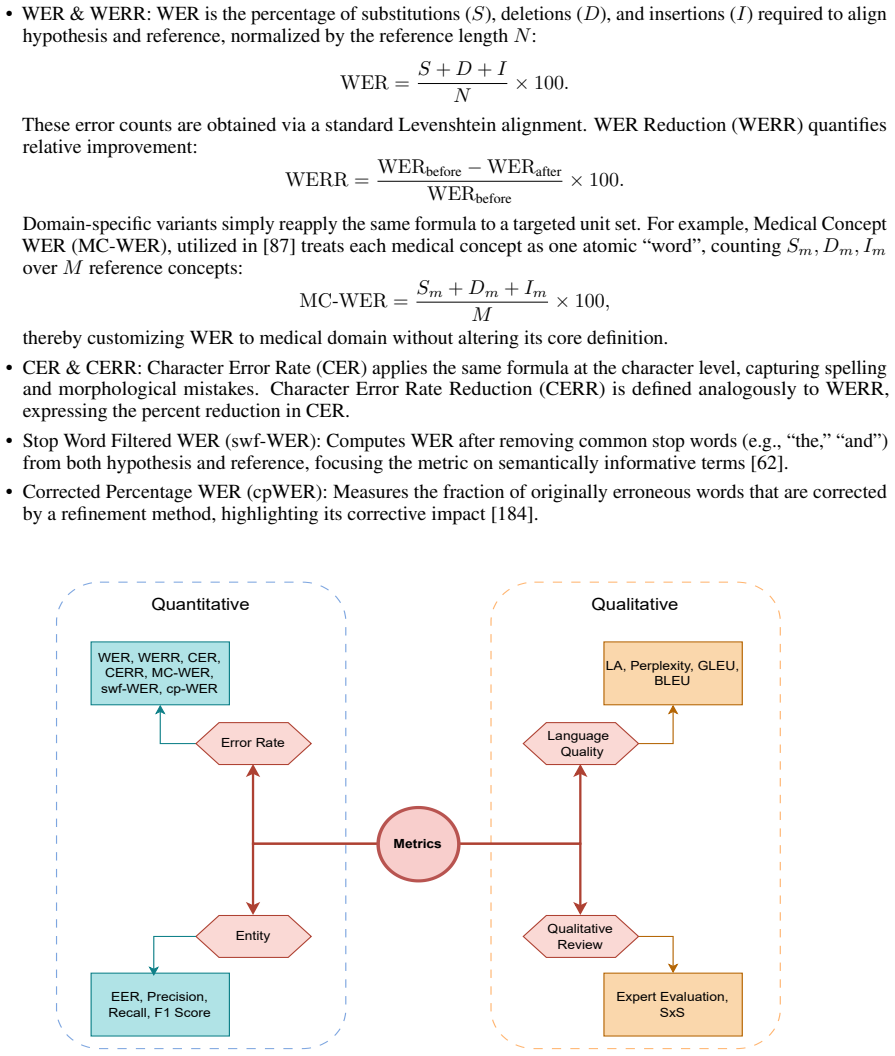
The five-class taxonomy (fusion, re-scoring, correction, distillation, and training adjustment) that partitions non-intrusive refinement methods and supports the proposed standardized evaluation metrics.
If this is right
- Practitioners gain clearer guidance for choosing a refinement approach based on the documented trade-offs and ideal scenarios for each class.
- Future papers can report results on the proposed standardized metrics to allow direct head-to-head comparisons.
- Domain adaptation work can be mapped onto the taxonomy to reveal which classes are under-explored in specialized vocabularies or noisy environments.
- Identified research gaps direct attention toward hybrid methods that combine elements from multiple classes.
- The structured overview reduces duplication of effort when designing new refinement pipelines.
Where Pith is reading between the lines
- The same five-class lens could be tested on non-intrusive refinement of related audio tasks such as speaker diarization or emotion recognition.
- Standardized metrics might evolve into community benchmarks that speed progress across the broader speech-processing field.
- Automated tools could eventually suggest the most suitable class for a given error pattern observed in a deployed ASR system.
- Similar taxonomies might be developed for non-intrusive post-processing in neighboring domains like machine translation or image captioning.
Load-bearing premise
That essentially all existing non-intrusive refinement techniques fit into one of the five classes with minimal overlap or gaps.
What would settle it
A published non-intrusive ASR refinement method whose core mechanism cannot be assigned to any single class or that overlaps substantially with two or more classes.
Figures



read the original abstract
Automatic Speech Recognition (ASR) is an integral component of modern technology, powering applications such as voice-activated assistants, transcription services, and accessibility tools. Yet ASR systems continue to struggle with the inherent variability of human speech, such as accents, dialects, and speaking styles, as well as environmental interference, including background noise. Moreover, domain-specific conversations often employ specialized terminology, which can exacerbate transcription errors. These shortcomings not only degrade raw ASR accuracy but also propagate mistakes through subsequent natural language processing pipelines. Because redesigning an ASR model is costly and time-consuming, non-intrusive refinement techniques that leave the model's architecture intact have become increasingly popular. In this survey, we review current non-intrusive refinement approaches and group them into five classes: fusion, re-scoring, correction, distillation, and training adjustment. For each class, we outline the main methods, advantages, drawbacks, and ideal application scenarios. Beyond method classification, this work surveys adaptation techniques aimed at refining ASR in domain-specific contexts, reviews commonly used evaluation datasets along with their construction processes, and proposes a standardized set of metrics to facilitate fair comparisons. Finally, we identify open research gaps and suggest promising directions for future work. By providing this structured overview, we aim to equip researchers and practitioners with a clear foundation for developing more robust, accurate ASR refinement pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey reviews non-intrusive ASR refinement methods that preserve the underlying model architecture. It groups existing approaches into five classes (fusion, re-scoring, correction, distillation, and training adjustment), describes the main techniques, advantages, drawbacks, and application scenarios for each class, surveys domain-adaptation techniques, reviews evaluation datasets and their construction, proposes a standardized set of metrics for fair comparisons, and identifies open research gaps with suggested future directions.
Significance. If the five-class taxonomy proves exhaustive and minimally overlapping, the work would supply a useful organizing framework for the growing literature on ASR refinement and could help standardize evaluation practices through the proposed metrics. The explicit coverage of datasets and construction processes is a constructive contribution that may aid reproducibility in the field.
major comments (1)
- [Section introducing the five-class taxonomy (following the abstract's description of grouping current approaches)] The claim that the five classes provide a comprehensive categorization with minimal overlap is load-bearing for the survey's organizational value. Explicit inclusion/exclusion criteria or decision rules for assigning papers to classes (e.g., how a hybrid method that fuses external features while also performing post-hoc correction is classified) are needed to resolve boundary cases such as distillation during domain adaptation versus training adjustment or lattice re-scoring versus correction.
minor comments (2)
- [Abstract] The abstract is clear but would benefit from a sentence indicating the approximate number of papers reviewed or the time span of the literature covered to convey the survey's scope.
- [Class-specific sections] Ensure that each class section consistently reports the same level of detail on advantages, drawbacks, and ideal scenarios so that readers can easily compare across classes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential organizing value of the survey. We address the major comment below and will incorporate the requested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Section introducing the five-class taxonomy (following the abstract's description of grouping current approaches)] The claim that the five classes provide a comprehensive categorization with minimal overlap is load-bearing for the survey's organizational value. Explicit inclusion/exclusion criteria or decision rules for assigning papers to classes (e.g., how a hybrid method that fuses external features while also performing post-hoc correction is classified) are needed to resolve boundary cases such as distillation during domain adaptation versus training adjustment or lattice re-scoring versus correction.
Authors: We agree that explicit classification criteria strengthen the taxonomy and will add a dedicated subsection immediately after the taxonomy overview. This subsection will define each class by its primary mechanism and intervention stage in the ASR pipeline: fusion for methods integrating external information at the acoustic or embedding level; re-scoring for post-decoding operations on lattices or n-best lists; correction for text-level post-processing; distillation for knowledge transfer from a teacher model; and training adjustment for modifications to the training procedure or fine-tuning that leave the architecture unchanged. For hybrid methods, we will adopt a primary-mechanism rule (with secondary aspects noted) and include a decision flowchart. Boundary cases will be explicitly discussed: distillation within domain adaptation will be placed under distillation with a cross-reference to training adjustment; lattice re-scoring will be distinguished from correction by whether the operation remains in the lattice domain. These additions will make assignment reproducible without altering the existing class descriptions or examples. revision: yes
Circularity Check
Survey taxonomy draws from external literature with no self-referential reduction
full rationale
This is a literature survey paper whose core contribution is reviewing and grouping existing non-intrusive ASR refinement methods drawn from independently published external works. The five-class taxonomy (fusion, re-scoring, correction, distillation, training adjustment) is presented as an organizational framework in the abstract and introduction, not as a mathematical derivation, fitted prediction, or quantity defined in terms of itself. No equations, self-citation load-bearing uniqueness theorems, or ansatzes appear in the provided text that would make any claim equivalent to its own inputs by construction. The paper explicitly references prior work for methods, datasets, and metrics, satisfying the criterion of being self-contained against external benchmarks. No circular steps are identifiable under the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Redesigning an ASR model is costly and time-consuming
Reference graph
Works this paper leans on
-
[1]
Automatic speech recognition errors detection and correction: A review
Rahhal Errattahi, Asmaa El Hannani, and Hassan Ouahmane. Automatic speech recognition errors detection and correction: A review. In Procedia Computer Science, volume 128, pages 32–37, 2018
work page 2018
-
[2]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems 30 (NeurIPS 2017), 2017
work page 2017
-
[3]
C., Parmar, N., Zhang, Y., Yu, J.,
Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv preprint arXiv:2005.08100, 2020
-
[4]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. In Advances in Neural Information Processing Systems 33, pages 12449–12460, 2020
work page 2020
-
[5]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International Conference on Machine Learning, pages 28492–28518. PMLR, 2023
work page 2023
-
[6]
Dolphin: A large-scale automatic speech recognition model for eastern languages
Yangyang Meng, Jinpeng Li, Guodong Lin, Yu Pu, Guanbo Wang, Hu Du, Zhiming Shao, Yukai Huang, Ke Li, and Wei-Qiang Zhang. Dolphin: A large-scale automatic speech recognition model for eastern languages. In arXiv preprint arXiv:2503.20212, 2025
-
[7]
Jonathan G. Fiscus. A post-processing system to yield reduced word error rates: Recognizer output voting error reduction (rover). In 1997 IEEE Workshop on Automatic Speech Recognition and Understanding Proceedings, pages 347–354. IEEE, 1997
work page 1997
-
[8]
ASR Context-Sensitive Error Correction Based on Microsoft N-Gram Dataset
Youssef Bassil and Paul Semaan. Asr context-sensitive error correction based on microsoft n-gram dataset. arXiv preprint arXiv:1203.5262, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[9]
Sainath, Zhijeng Chen, and Rohit Prabhavalkar
Anjuli Kannan, Yonghui Wu, Patrick Nguyen, Tara N. Sainath, Zhijeng Chen, and Rohit Prabhavalkar. An analysis of incorporating an external language model into a sequence-to-sequence model. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5828. IEEE, 2018
work page 2018
-
[10]
H. Huang and F. Peng. An empirical study of efficient asr rescoring with transformers. In arXiv preprint arXiv:1910.11450, 2019
-
[11]
Shiliang Zhang, Ming Lei, and Zhijie Yan. Investigation of transformer based spelling correction model for ctc-based end-to-end mandarin speech recognition. In Interspeech, pages 2180–2184, 2019
work page 2019
-
[12]
Spelling error correction with soft-masked bert
Shaohua Zhang, Haoran Huang, Jicong Liu, and Hang Li. Spelling error correction with soft-masked bert. arXiv preprint arXiv:2005.07421, 2020
-
[13]
K. Hu, R. Pang, T. N. Sainath, and T. Strohman. Transformer based deliberation for two-pass speech recognition. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), pages 68–74. IEEE, 2021. 21
work page 2021
-
[14]
Yuchun Shu, Bo Hu, Yifeng He, Hao Shi, Longbiao Wang, and Jianwu Dang. Error correction by paying attention to both acoustic and confidence references for automatic speech recognition. arXiv preprint arXiv:2407.12817, 2024
-
[15]
Deliberation networks: Sequence generation beyond one-pass decoding
Yingce Xia, Fei Tian, Lijun Wu, Jianxin Lin, Tao Qin, Nenghai Yu, and Tie-Yan Liu. Deliberation networks: Sequence generation beyond one-pass decoding. In Advances in Neural Information Processing Systems 30 (NeurIPS 2017), 2017
work page 2017
-
[16]
Cross-modal transformer-based neural correction models for automatic speech recognition
Tomohiro Tanaka, Ryo Masumura, Mana Ihori, Akihiko Takashima, Takafumi Moriya, Takanori Ashihara, Shota Orihashi, and Naoki Makishima. Cross-modal transformer-based neural correction models for automatic speech recognition. In arXiv preprint arXiv:2107.01569, 2021. Preprint
-
[17]
Xingyi Cheng, Weidi Xu, Kunlong Chen, Shaohua Jiang, Feng Wang, Taifeng Wang, Wei Chu, and Yuan Qi. Spellgcn: Incorporating phonological and visual similarities into language models for chinese spelling check. arXiv preprint arXiv:2004.14166, 2020
-
[18]
Jiajun He, Zekun Yang, and Tomoki Toda. Ed-cec: Improving rare word recognition using asr postprocessing based on error detection and context-aware error correction. In 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 1–6. IEEE, 2023
work page 2023
-
[19]
Towards contextual spelling correction for customization of end-to-end speech recognition systems
Xiaoqiang Wang et al. Towards contextual spelling correction for customization of end-to-end speech recognition systems. arXiv preprint arXiv:2203.00888, mar 2022
- [20]
-
[21]
Michael Hentschel, Yuta Nishikawa, Tatsuya Komatsu, and Yusuke Fujita. Keep decoding parallel with effective knowledge distillation from language models to end-to-end speech recognisers. In ICASSP 2024 - IEEE International Conference on Acoustics, Speech and Signal Processing, pages 10876–10880. IEEE, 2024
work page 2024
-
[22]
Internal language model training for domain-adaptive end-to-end speech recognition
Zhong Meng, Naoyuki Kanda, Yashesh Gaur, Sarangarajan Parthasarathy, Eric Sun, Liang Lu, Xie Chen, Jinyu Li, and Yifan Gong. Internal language model training for domain-adaptive end-to-end speech recognition. In ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 7338–7342. IEEE, 2021
work page 2021
-
[23]
Shubham Toshniwal, Anjuli Kannan, Chung-Cheng Chiu, Yonghui Wu, Tara N. Sainath, and Karen Livescu. A comparison of techniques for language model integration in encoder-decoder speech recognition. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), pages 369–375. IEEE, 2018
work page 2018
-
[25]
Saeed Saadat, Majid Khalilizad Darounkolaei, Mohsen Qorbani, Atefe Hemmat, and Sadaf Hariri. Enhancing clinical documentation with ai: Reducing errors, improving interoperability, and supporting real-time note-taking. InfoScience Trends, 2(1):1–13, 2025
work page 2025
-
[26]
Sainath, Ralf Schlüter, and Shinji Watanabe
Rohit Prabhavalkar, Takaaki Hori, Tara N. Sainath, Ralf Schlüter, and Shinji Watanabe. End-to-end speech recognition: A survey. In Proceedings of the IEEE/ACM Transactions on Audio, Speech, and Language Processing, volume 32, pages 325–351, 2023
work page 2023
-
[27]
Duc Le, Mahaveer Jain, Gil Keren, Suyoun Kim, Yangyang Shi, Jay Mahadeokar, Julian Chan, et al. Contextual- ized streaming end-to-end speech recognition with trie-based deep biasing and shallow fusion. In arXiv preprint arXiv:2104.02194, 2021
-
[28]
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V . Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. In arXiv preprint arXiv:1609.08144, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[29]
Towards better decoding and language model integration in sequence to sequence models
Jan Chorowski and Navdeep Jaitly. Towards better decoding and language model integration in sequence to sequence models. In arXiv preprint arXiv:1612.02695, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[30]
Zhuo Gong, Daisuke Saito, Sheng Li, Hisashi Kawai, and Nobuaki Minematsu. Can we train a language model inside an end-to-end asr model? investigating effective implicit language modeling. In Proceedings of the Second Workshop on When Creative AI Meets Conversational AI, pages 42–47, 2022
work page 2022
-
[31]
Internal language model estimation for domain-adaptive end-to-end speech recognition
Zhong Meng, Sarangarajan Parthasarathy, Eric Sun, Yashesh Gaur, Naoyuki Kanda, Liang Lu, Xie Chen, Rui Zhao, Jinyu Li, and Yifan Gong. Internal language model estimation for domain-adaptive end-to-end speech recognition. In 2021 IEEE Spoken Language Technology Workshop (SLT), pages 243–250. IEEE, 2021
work page 2021
-
[32]
A density ratio approach to language model fusion in end-to- end automatic speech recognition
Erik McDermott, Hasim Sak, and Ehsan Variani. A density ratio approach to language model fusion in end-to- end automatic speech recognition. In 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 434–441. IEEE, 2019. 22
work page 2019
-
[33]
Internal language model esti- mation based adaptive language model fusion for domain adaptation
Rao Ma, Xiaobo Wu, Jin Qiu, Yanan Qin, Haihua Xu, Peihao Wu, and Zejun Ma. Internal language model esti- mation based adaptive language model fusion for domain adaptation. In ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
work page 2023
-
[34]
Iterative shallow fusion of backward language model for end-to-end speech recognition
Atsunori Ogawa, Takafumi Moriya, Naoyuki Kamo, Naohiro Tawara, and Marc Delcroix. Iterative shallow fusion of backward language model for end-to-end speech recognition. In ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
work page 2023
-
[35]
Takaaki Hori, Martin Kocour, Adnan Haider, Erik McDermott, and Xiaodan Zhuang. Delayed fusion: Inte- grating large language models into first-pass decoding in end-to-end speech recognition. In arXiv preprint arXiv:2501.09258, 2025
-
[36]
Chan-Jan Hsu, Yi-Chang Chen, Feng-Ting Liao, Pei-Chen Ho, Yu-Hsiang Wang, Po-Chun Hsu, and Da shan Shiu. Let’s fuse step by step: A generative fusion decoding algorithm with llms for multi-modal text recognition. arXiv preprint arXiv:2405.14259, 2024
-
[37]
Salsa: Speedy asr-llm synchronous aggregation
Ashish Mittal, Darshan Prabhu, Sunita Sarawagi, and Preethi Jyothi. Salsa: Speedy asr-llm synchronous aggregation. In arXiv preprint arXiv:2408.16542, 2024
-
[38]
Lusheng Zhang, Shie Wu, and Zhongxun Wang. End-to-end speech recognition with deep fusion: Leveraging external language models for low-resource scenarios. In Proceedings of Electronics, volume 14, page 802, 2025
work page 2025
-
[39]
Cold Fusion: Training Seq2Seq Models Together with Language Models
Anuroop Sriram, Heewoo Jun, Sanjeev Satheesh, and Adam Coates. Cold fusion: Training seq2seq models together with language models. In arXiv preprint arXiv:1708.06426, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Language model integration based on memory control for sequence to sequence speech recognition
Jaejin Cho, Shinji Watanabe, Takaaki Hori, Murali Karthick Baskar, Hirofumi Inaguma, Jesus Villalba, and Najim Dehak. Language model integration based on memory control for sequence to sequence speech recognition. In ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6191–6195. IEEE, 2019
work page 2019
-
[41]
Suyoun Kim, Yuan Shangguan, Jay Mahadeokar, Antoine Bruguier, Christian Fuegen, Michael L. Seltzer, and Duc Le. Improved neural language model fusion for streaming recurrent neural network transducer. In ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 7333–7337. IEEE, 2021
work page 2021
-
[42]
Large Scale Distributed Acoustic Modeling With Back-off N-grams
Ciprian Chelba, Peng Xu, Fernando Pereira, and Thomas Richardson. Large scale distributed acoustic modeling with back-off n-grams. In arXiv preprint arXiv:1302.1123, 2013. Available at: http://arxiv.org/abs/1302. 1123
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[43]
Asr rescoring and confidence estimation with electra
Hayato Futami, Hirofumi Inaguma, Masato Mimura, Shinsuke Sakai, and Tatsuya Kawahara. Asr rescoring and confidence estimation with electra. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 380–387. IEEE, 2021
work page 2021
-
[44]
X. Chen, Y . Wang, M. J. F. Gales, and P. C. Woodland. Two efficient lattice rescoring methods using recurrent neural network language models. In IEEE/ACM Transactions on Audio, Speech, and Language Processing, volume 24, pages 1438–1449, 2016
work page 2016
-
[45]
Lattice Rescoring Strategies for Long Short Term Memory Language Models in Speech Recognition
S. Kumar, M. Nirschl, D. Holtmann-Rice, H. Liao, A. T. Suresh, and F. Yu. Lattice rescoring strategies for long short term memory language models in speech recognition. In arXiv preprint arXiv:1711.05448, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
A. Gandhe and A. Rastrow. Audio-attention discriminative language model for asr rescoring. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 7944–7948. IEEE, 2020
work page 2020
-
[47]
Sainath, Ruoming Pang, and Rohit Prabhavalkar
Ke Hu, Tara N. Sainath, Ruoming Pang, and Rohit Prabhavalkar. Deliberation model based two-pass end-to-end speech recognition. In ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7799–7803. IEEE, 2020
work page 2020
- [48]
-
[49]
Domain-aware neural language models for speech recognition
Linda Liu, Yile Gu, Aditya Gourav, Ankur Gandhe, Shashank Kalmane, Denis Filimonov, Ariya Rastrow, and Ivan Bulyko. Domain-aware neural language models for speech recognition. In arXiv preprint arXiv:2101.03229, 2021
-
[50]
W. Li, J. Qin, C.-C. Chiu, R. Pang, and Y . He. Parallel rescoring with transformer for streaming on-device speech recognition. In Proceedings of Interspeech 2020, pages 2122–2126, 2020
work page 2020
-
[51]
T. Udagawa, M. Suzuki, G. Kurata, N. Itoh, and G. Saon. Effect and analysis of large-scale language model rescoring on competitive asr systems. In Proceedings of Interspeech 2022, pages 1–5, 2022. 23
work page 2022
- [52]
-
[53]
Effective sentence scoring method using bert for speech recognition
Joonbo Shin, Yoonhyung Lee, and Kyomin Jung. Effective sentence scoring method using bert for speech recognition. In Proceedings of the Eleventh Asian Conference on Machine Learning (ACML), volume 101 of Proceedings of Machine Learning Research, pages 1081–1093, 2019
work page 2019
-
[54]
J. Salazar, D. Liang, T. Q. Nguyen, and K. Kirchhoff. Masked language model scoring. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), pages 2699–2712, 2020
work page 2020
-
[55]
Rescorebert: Discriminative speech recognition rescoring with bert
Liyan Xu, Yile Gu, Jari Kolehmainen, Haidar Khan, Ankur Gandhe, Ariya Rastrow, Andreas Stolcke, and Ivan Bulyko. Rescorebert: Discriminative speech recognition rescoring with bert. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7727–7731, may 2022
work page 2022
-
[56]
Innovative bert-based reranking language models for speech recognition
Shih-Hsuan Chiu and Berlin Chen. Innovative bert-based reranking language models for speech recognition. In arXiv preprint arXiv:2104.04950, 2021
-
[57]
P. G. Shivakumar, J. Kolehmainen, Y . Gu, A. Gandhe, A. Rastrow, and I. Bulyko. Discriminative speech recogni- tion rescoring with pre-trained language models. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2023
work page 2023
-
[58]
Y . Yu, C.-H. H. Yang, J. Kolehmainen, P. G. Shivakumar, Y . Gu, S. Ryu, R. Ren, Q. Luo, A. Gourav, I.-F. Chen, Y .-C. Liu, T. Dinh, A. Gandhe, D. Filimonov, S. Ghosh, A. Stolcke, A. Rastrow, and I. Bulyko. Low-rank adaptation of large language model rescoring for parameter-efficient speech recognition, 2023. arXiv preprint arXiv:2309.15223
-
[59]
J. Kolehmainen, Y . Gu, A. Gourav, P. G. Shivakumar, A. Gandhe, A. Rastrow, and I. Bulyko. Personalization for bert-based discriminative speech recognition rescoring. In Proceedings of Interspeech, pages 366–370, 2023
work page 2023
- [60]
-
[61]
Y . Asano, S. Hassan, P. Sharma, A. Sicilia, K. Atwell, D. Litman, and M. Alikhani. Contextual asr error handling with llms augmentation for goal-oriented conversational ai. In Proceedings of the 2025 International Conference on Computational Linguistics: Industry Track (COLING), 2025
work page 2025
-
[62]
Saki Imai, Tahiya Chowdhury, and Amanda Stent. Evaluating open-source asr systems: Performance across diverse audio conditions and error correction methods. In Proceedings of the 31st International Conference on Computational Linguistics, pages 5027–5039, 2025
work page 2025
-
[63]
Repairing asr output by artificial development and ontology based learning
Chandrasekhar Anantaram, Amit Sangroya, Mrinal Rawat, and Aishwarya Chhabra. Repairing asr output by artificial development and ontology based learning. In IJCAI, pages 5799–5801, 2018
work page 2018
-
[64]
Tag and correct: high precision post-editing approach to correction of speech recognition errors
Tomasz Zietkiewicz. Tag and correct: high precision post-editing approach to correction of speech recognition errors. In 2022 17th Conference on Computer Science and Intelligence Systems (FedCSIS) , pages 939–942. IEEE, 2022
work page 2022
-
[65]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, 2019
work page 2019
-
[66]
Correcting chinese spelling errors with phonetic pre-training
Ruiqing Zhang, Chao Pang, Chuanqiang Zhang, Shuohuan Wang, Zhongjun He, Yu Sun, Hua Wu, and Haifeng Wang. Correcting chinese spelling errors with phonetic pre-training. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2250–2261, 2021
work page 2021
-
[67]
Clinical dialogue transcription error correction using seq2seq models
Gayani Nanayakkara, Nirmalie Wiratunga, David Corsar, Kyle Martin, and Anjana Wijekoon. Clinical dialogue transcription error correction using seq2seq models. In Multimodal AI in Healthcare: A Paradigm Shift in Health Intelligence, pages 41–57. Springer International Publishing, Cham, 2022
work page 2022
-
[68]
Faspell: A fast, adaptable, simple, powerful chinese spell checker based on dae-decoder paradigm
Yuzhong Hong, Xianguo Yu, Neng He, Nan Liu, and Junhui Liu. Faspell: A fast, adaptable, simple, powerful chinese spell checker based on dae-decoder paradigm. In Proceedings of the 5th Workshop on Noisy User- generated Text (W-NUT 2019), pages 160–169, 2019
work page 2019
-
[69]
Boosting chinese asr error correction with dynamic error scaling mechanism
Jiaxin Fan, Yong Zhang, Hanzhang Li, Jianzong Wang, Zhitao Li, Sheng Ouyang, Ning Cheng, and Jing Xiao. Boosting chinese asr error correction with dynamic error scaling mechanism. arXiv preprint arXiv:2308.03423, 2023
-
[70]
Integrated semantic and phonetic post-correction for chinese speech recognition
Yi-Chang Chen, Chun-Yen Cheng, Chien-An Chen, Ming-Chieh Sung, and Yi-Ren Yeh. Integrated semantic and phonetic post-correction for chinese speech recognition. arXiv preprint arXiv:2111.08400, 2021. 24
-
[71]
Neural error corrective language models for automatic speech recognition
Kazuya Tanaka, Yusuke Masumura, and Tatsuya Kawahara. Neural error corrective language models for automatic speech recognition. In Proc. INTERSPEECH, 2018
work page 2018
-
[72]
Correction of automatic speech recognition with transformer sequence-to-sequence model
Oleksii Hrinchuk, Mariya Popova, and Boris Ginsburg. Correction of automatic speech recognition with transformer sequence-to-sequence model. In ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7074–7078. IEEE, 2020
work page 2020
-
[74]
Semantically corrected amharic automatic speech recognition
Samuael Adnew and Paul Pu Liang. Semantically corrected amharic automatic speech recognition. arXiv preprint arXiv:2404.13362, 2024
-
[75]
Crossmodal asr error correction with discrete speech units
Yuanchao Li, Pinzhen Chen, Peter Bell, and Catherine Lai. Crossmodal asr error correction with discrete speech units. In 2024 IEEE Spoken Language Technology Workshop (SLT), pages 431–438. IEEE, 2024
work page 2024
-
[76]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrah- man Mohamed. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021
work page 2021
- [77]
- [78]
-
[79]
Visual information matters for asr error correction
Vanya Bannihatti Kumar, Shanbo Cheng, Ningxin Peng, and Yuchen Zhang. Visual information matters for asr error correction. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
work page 2023
- [80]
-
[81]
Jinxi Guo, Tara N. Sainath, and Ron J. Weiss. A spelling correction model for end-to-end speech recognition. In ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 5651–5655. IEEE, 2019
work page 2019
-
[82]
Global attention decoder for chinese spelling error correction
Zhao Guo, Yuan Ni, Keqiang Wang, Wei Zhu, and Guotong Xie. Global attention decoder for chinese spelling error correction. In Findings of the Association for Computational Linguistics (ACL), pages 1419–1428, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.