Patient-Adaptive Echocardiography using Cognitive Ultrasound
Pith reviewed 2026-05-18 23:14 UTC · model grok-4.3
The pith
A diffusion model selects the most informative focused ultrasound transmits to produce high-quality heart images with fewer scans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a cognitive ultrasound modality based on posterior sampling with a temporal diffusion model can perceive and reconstruct cardiac anatomy from partial observations and subsequently acquire the most informative focused transmits, outperforming non-adaptive strategies in image quality metrics while enabling real-time high-frame-rate imaging.
What carries the argument
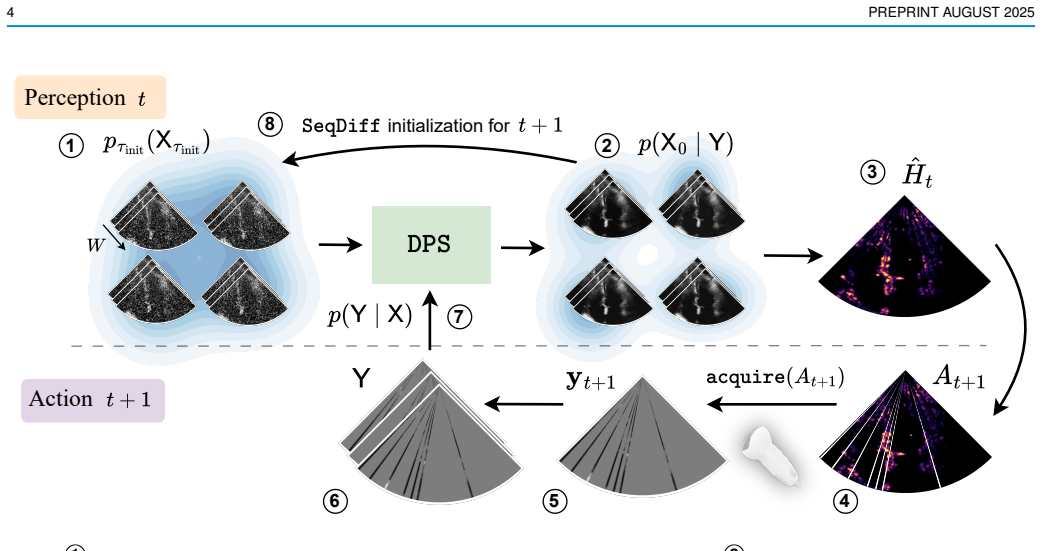
Temporal diffusion model for posterior sampling that reconstructs anatomy and selects optimal focused transmit planes or lines from incomplete data.
If this is right
- Reduces the number of focused transmits needed for high-quality images.
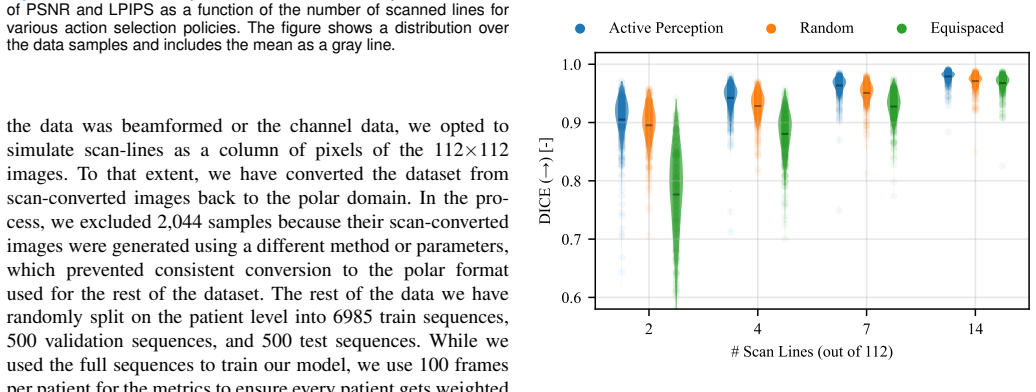
- Outperforms random and equispaced subsampling in distortion and perceptual metrics.
- Improves generalized contrast-to-noise ratio from 0.83 to 0.89 over diverging wave transmits.
- Enables left ventricle segmentation with 0.91 average Dice coefficient using only 2 of 112 lines.
- Supports real-time GPU execution raising frame rate from 46 Hz to 58 Hz.
Where Pith is reading between the lines
- The approach may apply to other ultrasound applications like abdominal or vascular imaging where adaptive focusing could help.
- Future work could test if the model can handle pathological variations in heart structure not well represented in training.
- Combining this selection with real-time feedback loops might allow the system to track moving structures more effectively during acquisition.
Load-bearing premise
The temporal diffusion model trained on prior data can reliably infer the most informative next focused transmit from partial observations of cardiac anatomy without introducing reconstruction artifacts.
What would settle it
Observing that on unseen patient echocardiograms the adaptive method yields lower or equal generalized contrast-to-noise ratio and perceptual quality compared to equispaced selection with equal transmit count would falsify the superiority claim.
Figures







read the original abstract
Focused transmits are the most commonly used transmit strategy for echocardiograms, but suffer from relatively low frame rates, and in 3D, even lower volume rates. Fast imaging based on unfocused transmits has disadvantages such as motion decorrelation and limited harmonic imaging capabilities. This work introduces a patient-adaptive focused transmit and receive scheme that has the ability to drastically reduce the number of transmits needed to produce a high-quality ultrasound image. The method relies on posterior sampling with a temporal diffusion model to perceive and reconstruct the anatomy based on partial observations, while subsequently acquiring the most informative transmits. This cognitive ultrasound modality outperforms random and equispaced subsampling in terms of distortion and perceptual metrics on the 2D EchoNet-Dynamic dataset and a 3D Philips dataset, where we actively select focused elevation planes. Furthermore, our method improves generalized contrast-to-noise ratio from 0.83 to 0.89 compared to the same number of diverging wave transmits on six in-house echocardiograms. Additionally, we can segment the left ventricle, with on average 0.91 Dice-S{\o}rensen coefficient, through simulating using 2 out of 112 lines. Finally, our method can be run in real-time on GPU accelerators from 2023, increasing the maximum achievable frame-rate from 46 Hz to 58 Hz. The code is publicly available at https://tue-bmd.github.io/casl/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a patient-adaptive echocardiography technique that employs a temporal diffusion model for posterior sampling to dynamically select focused transmits based on partial observations of cardiac anatomy. It reports superior performance over random and equispaced subsampling in distortion and perceptual metrics on the EchoNet-Dynamic and Philips datasets, an increase in generalized contrast-to-noise ratio (gCNR) from 0.83 to 0.89 on six in-house echocardiograms relative to diverging wave transmits, a Dice-Sørensen coefficient of 0.91 for left ventricle segmentation using only 2 out of 112 lines, and real-time GPU execution that boosts frame rates from 46 Hz to 58 Hz. The code is made publicly available.
Significance. Should the empirical advantages prove robust, the work offers a promising direction for cognitive ultrasound systems that adaptively optimize transmit strategies to achieve high-quality imaging at elevated frame rates. This could address longstanding limitations in both 2D and 3D echocardiography. The public code availability facilitates reproducibility and further research in the field.
major comments (3)
- [§4.2] The gCNR improvement from 0.83 to 0.89 is reported for only six in-house echocardiograms without standard deviations, confidence intervals, or results from statistical hypothesis testing. With this limited sample size, patient-to-patient variations in anatomy and imaging conditions could readily explain the 0.06 difference, weakening support for the claimed superiority of the adaptive method.
- [Methods] No information is provided on the training of the temporal diffusion model, such as hyperparameter tuning, cross-validation strategy, or safeguards against data leakage from the in-house scans into the model training. These details are essential to assess whether the posterior sampling reliably selects informative transmits without introducing reconstruction artifacts.
- [§5.3] The left ventricle segmentation result with 0.91 Dice using 2/112 lines is presented without comparison to baselines or analysis of failure cases, making it hard to gauge the practical utility of the reduced transmit scheme for downstream tasks.
minor comments (2)
- The abstract contains a formatting issue with 'S{o}rensen' that should be corrected to the proper Sørensen coefficient name.
- [Figure 3] Ensure that all subfigures are clearly labeled and that the color scales for the ultrasound images are consistent across comparisons.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We address each of the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [§4.2] The gCNR improvement from 0.83 to 0.89 is reported for only six in-house echocardiograms without standard deviations, confidence intervals, or results from statistical hypothesis testing. With this limited sample size, patient-to-patient variations in anatomy and imaging conditions could readily explain the 0.06 difference, weakening support for the claimed superiority of the adaptive method.
Authors: We agree that the small sample size of six in-house echocardiograms limits the strength of the statistical claims and that standard deviations and hypothesis testing would provide better context. The in-house dataset was limited by the practical difficulties of acquiring paired adaptive and diverging wave acquisitions under identical conditions. In the revised manuscript, we will report the standard deviation of the gCNR values across the six cases and include a note on the preliminary nature of these results due to the sample size. We will also perform and report a paired t-test if the data distribution permits. This addresses the concern while maintaining that the consistent improvement observed supports the method's promise. revision: partial
-
Referee: [Methods] No information is provided on the training of the temporal diffusion model, such as hyperparameter tuning, cross-validation strategy, or safeguards against data leakage from the in-house scans into the model training. These details are essential to assess whether the posterior sampling reliably selects informative transmits without introducing reconstruction artifacts.
Authors: We thank the referee for pointing out this omission in the Methods section. The temporal diffusion model was trained solely on the EchoNet-Dynamic and Philips datasets using patient-wise cross-validation to avoid leakage. The in-house echocardiograms were used exclusively for evaluation and were not part of the training or validation sets. In the revised manuscript, we will expand the Methods to include details on hyperparameter selection (e.g., learning rate, number of diffusion steps), the cross-validation procedure, and explicit statements confirming no data leakage from in-house scans. We believe these additions will clarify that the posterior sampling is reliable and does not introduce artifacts from training data contamination. revision: yes
-
Referee: [§5.3] The left ventricle segmentation result with 0.91 Dice using 2/112 lines is presented without comparison to baselines or analysis of failure cases, making it hard to gauge the practical utility of the reduced transmit scheme for downstream tasks.
Authors: We concur that providing baseline comparisons and failure case analysis would enhance the interpretability of the segmentation results. In the revised version, we will add comparisons of the Dice-Sørensen coefficient for the adaptive method against random subsampling and equispaced transmit selection using the same number of lines. Additionally, we will include a brief analysis of failure cases, such as when key anatomical features are missed due to the sparse sampling, and discuss how these might be mitigated in practice. This will better demonstrate the utility for downstream tasks like left ventricle segmentation. revision: yes
Circularity Check
No circularity: empirical performance gains on held-out data
full rationale
The paper's central results consist of empirical comparisons of image quality metrics (distortion, perceptual scores, gCNR from 0.83 to 0.89) and segmentation Dice (0.91) obtained by running the trained temporal diffusion model on separate test sets: EchoNet-Dynamic, a 3D Philips dataset, and six in-house echocardiograms. These quantities are measured after training and inference on held-out acquisitions; they are not obtained by algebraic rearrangement of the model's own fitted parameters or by re-using the same observations that defined the posterior. No self-definitional equations, fitted-input predictions, or load-bearing self-citations appear in the abstract or method description. The derivation therefore remains externally falsifiable through the reported experiments and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Wise, “Everyone’s a radiologist now,” BMJ : British Medical Journal, vol. 336, no. 7652, pp. 1041–1043, May 2008. [Online]. Available: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2376013/
work page 2008
-
[2]
L. Demi, M. D. Verweij, and K. W. Van Dongen, “Parallel transmit beamforming using orthogonal frequency division multiplexing applied to harmonic Imaging-A feasibility study,” IEEE Transactions on Ul- trasonics, Ferroelectrics, and Frequency Control , vol. 59, no. 11, pp. 2439–2447, Nov. 2012
work page 2012
-
[3]
Emerging wearable ultrasound technology,
H. Huang, R. S. Wu, M. Lin, and S. Xu, “Emerging wearable ultrasound technology,” IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control, vol. 71, no. 7, pp. 713–729, 2023
work page 2023
-
[4]
Wearable ultrasound devices for continuous health monitoring: Current and future prospects,
N. Ottakath, S. Al-Maadeed, A. Bouridane, M. E. Chowdhury, and K. K. Sadasivuni, “Wearable ultrasound devices for continuous health monitoring: Current and future prospects,” in 2024 IEEE 8th Energy Conference (ENERGYCON). IEEE, 2024, pp. 1–6
work page 2024
-
[5]
Ultrasound beamforming: Exploring cloud-native and edge computing solution,
H. Hadri, A. Fail, M. Sadik, and A. Essaken, “Ultrasound beamforming: Exploring cloud-native and edge computing solution,” in 2024 4th Inter- national Conference on Technological Advancements in Computational Sciences (ICTACS). IEEE, 2024, pp. 1339–1343. 10 PREPRINT AUGUST 2025
work page 2024
-
[6]
Active inference and deep generative modeling for cognitive ultrasound,
R. J. Van Sloun, “Active inference and deep generative modeling for cognitive ultrasound,”IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control , pp. 1–1, 2024, conference Name: IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control. [Online]. Available: https://ieeexplore.ieee.org/document/10689436
-
[7]
Deep learning for ultrasound beamforming,
R. J. van Sloun, J. C. Ye, and Y . C. Eldar, “Deep learning for ultrasound beamforming,” 2021. [Online]. Available: https: //arxiv.org/abs/2109.11431
-
[8]
Tissue harmonic imaging: Why does it work?
J. D. Thomas and D. N. Rubin, “Tissue harmonic imaging: Why does it work?” Journal of the American Society of Echocardiography , vol. 11, no. 8, pp. 803–808, Aug. 1998
work page 1998
-
[9]
R. Bajcsy, “Active perception,” Proceedings of the IEEE , vol. 76, no. 8, pp. 966–1005, 1988
work page 1988
-
[10]
V on Helmholtz, Handbuch der physiologischen Optik
H. V on Helmholtz, Handbuch der physiologischen Optik. L. V oss, 1867, vol. 9
-
[11]
Object perception as bayesian inference,
D. Kersten, P. Mamassian, and A. Yuille, “Object perception as bayesian inference,” Annu. Rev. Psychol., vol. 55, no. 1, pp. 271–304, 2004
work page 2004
-
[12]
Modern bayesian experimental design,
T. Rainforth, A. Foster, D. R. Ivanova, and F. Bickford Smith, “Modern bayesian experimental design,” Statistical Science , vol. 39, no. 1, pp. 100–114, 2024
work page 2024
-
[13]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems , vol. 33, pp. 6840– 6851, 2020
work page 2020
-
[14]
Score-Based Generative Modeling through Stochastic Differential Equations
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differ- ential equations,” arXiv preprint arXiv:2011.13456 , 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[15]
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet, “Video diffusion models,” Advances in Neural Information Processing Systems, vol. 35, pp. 8633–8646, 2022
work page 2022
-
[16]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502 , 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[17]
Tweedie’s formula and selection bias,
B. Efron, “Tweedie’s formula and selection bias,” Journal of the Amer- ican Statistical Association , vol. 106, no. 496, pp. 1602–1614, 2011
work page 2011
-
[18]
Diffusion Posterior Sampling for General Noisy Inverse Problems
H. Chung, J. Kim, M. T. Mccann, M. L. Klasky, and J. C. Ye, “Diffusion posterior sampling for general noisy inverse problems,” arXiv preprint arXiv:2209.14687, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
A. Ramkumar and A. K. Thittai, “Strategic undersampling and recovery using compressed sensing for enhancing ultrasound image quality,”IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control , vol. 67, no. 3, pp. 547–556, 2019
work page 2019
-
[20]
Compressive sensing for raw rf signals reconstruction in ultrasound,
D. Friboulet, H. Liebgott, and R. Prost, “Compressive sensing for raw rf signals reconstruction in ultrasound,” in 2010 IEEE International Ultrasonics Symposium. IEEE, 2010, pp. 367–370
work page 2010
-
[21]
Sparse convolutional beamforming for ultrasound imaging,
R. Cohen and Y . C. Eldar, “Sparse convolutional beamforming for ultrasound imaging,” IEEE transactions on ultrasonics, ferroelectrics, and frequency control, vol. 65, no. 12, pp. 2390–2406, 2018
work page 2018
-
[22]
Deep-learning based adaptive ultrasound imaging from sub-nyquist channel data,
A. Mamistvalov, A. Amar, N. Kessler, and Y . C. Eldar, “Deep-learning based adaptive ultrasound imaging from sub-nyquist channel data,”IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control , vol. 69, no. 5, pp. 1638–1648, 2022
work page 2022
-
[23]
Deep-fus: A deep learning platform for functional ultrasound imaging of the brain using sparse data,
T. Di Ianni and R. D. Airan, “Deep-fus: A deep learning platform for functional ultrasound imaging of the brain using sparse data,” IEEE transactions on medical imaging , vol. 41, no. 7, pp. 1813–1825, 2022
work page 2022
-
[24]
D. Xiao, W. M. Pitman, B. Y . Yiu, A. J. Chee, and C. Alfred, “Minimizing image quality loss after channel count reduction for plane wave ultrasound via deep learning inference,” IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control, vol. 69, no. 10, pp. 2849–2861, 2022
work page 2022
-
[25]
Learning sub-sampling and signal recovery with applications in ultrasound imaging,
I. A. Huijben, B. S. Veeling, K. Janse, M. Mischi, and R. J. van Sloun, “Learning sub-sampling and signal recovery with applications in ultrasound imaging,” IEEE Transactions on Medical Imaging , vol. 39, no. 12, pp. 3955–3966, 2020
work page 2020
-
[26]
A review of the gumbel-max trick and its extensions for discrete stochasticity in machine learning,
I. A. Huijben, W. Kool, M. B. Paulus, and R. J. Van Sloun, “A review of the gumbel-max trick and its extensions for discrete stochasticity in machine learning,” IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 2, pp. 1353–1371, 2022
work page 2022
-
[27]
High frame rate ultrasound imaging by means of tensor completion: Application to echocardiogra- phy,
S. Afrakhteh, G. Iacca, and L. Demi, “High frame rate ultrasound imaging by means of tensor completion: Application to echocardiogra- phy,” IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control, vol. 70, no. 1, pp. 41–51, 2022
work page 2022
-
[28]
fastmri: An open dataset and benchmarks for accelerated mri,
J. Zbontar, F. Knoll, A. Sriram, T. Murrell, Z. Huang, M. J. Muck- ley, A. Defazio, R. Stern, P. Johnson, M. Bruno et al. , “fastmri: An open dataset and benchmarks for accelerated mri,” arXiv preprint arXiv:1811.08839, 2018
-
[29]
End-to-end variational net- works for accelerated mri reconstruction,
A. Sriram, J. Zbontar, T. Murrell, A. Defazio, C. L. Zitnick, N. Yakubova, F. Knoll, and P. Johnson, “End-to-end variational net- works for accelerated mri reconstruction,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part II 23 . Springer, 2020, pp. 64–73
work page 2020
-
[30]
Learning-based optimization of the under-sampling pattern in mri,
C. D. Bahadir, A. V . Dalca, and M. R. Sabuncu, “Learning-based optimization of the under-sampling pattern in mri,” in Information Processing in Medical Imaging: 26th International Conference, IPMI 2019, Hong Kong, China, June 2–7, 2019, Proceedings 26 . Springer, 2019, pp. 780–792
work page 2019
-
[31]
Learning sampling and model-based signal recovery for compressed sensing mri,
I. A. Huijben, B. S. Veeling, and R. J. van Sloun, “Learning sampling and model-based signal recovery for compressed sensing mri,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2020, pp. 8906–8910
work page 2020
-
[32]
Active deep probabilistic subsampling,
H. Van Gorp, I. Huijben, B. S. Veeling, N. Pezzotti, and R. J. Van Sloun, “Active deep probabilistic subsampling,” in International Conference on Machine Learning. PMLR, 2021, pp. 10 509–10 518
work page 2021
-
[33]
End- to-end sequential sampling and reconstruction for mri,
T. Yin, Z. Wu, H. Sun, A. V . Dalca, Y . Yue, and K. L. Bouman, “End- to-end sequential sampling and reconstruction for mri,” arXiv preprint arXiv:2105.06460, 2021
-
[34]
O. Nolan, T. Stevens, W. L. van Nierop, and R. V . Sloun, “Active diffusion subsampling,” Transactions on Machine Learning Research ,
-
[35]
Available: https://openreview.net/forum?id=OGifiton47
[Online]. Available: https://openreview.net/forum?id=OGifiton47
-
[36]
End-to-end adaptive dy- namic subsampling and reconstruction for cardiac mri,
G. Yiasemis, J.-J. Sonke, and J. Teuwen, “End-to-end adaptive dy- namic subsampling and reconstruction for cardiac mri,” arXiv preprint arXiv:2403.10346, 2024
-
[37]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international con- ference, Munich, Germany, October 5-9, 2015, proceedings, part III 18 . Springer, 2015, pp. 234–241
work page 2015
-
[38]
Solving linear inverse problems provably via posterior sampling with latent diffusion models,
L. Rout, N. Raoof, G. Daras, C. Caramanis, A. Dimakis, and S. Shakkot- tai, “Solving linear inverse problems provably via posterior sampling with latent diffusion models,” Advances in Neural Information Process- ing Systems, vol. 36, 2024
work page 2024
-
[39]
D. Stojanovski, U. Hermida, P. Lamata, A. Beqiri, and A. Gomez, “Echo from noise: synthetic ultrasound image generation using diffusion models for real image segmentation,” in International Workshop on Advances in Simplifying Medical Ultrasound . Springer, 2023, pp. 34– 43
work page 2023
-
[40]
Dehazing ultrasound using diffusion models,
T. S. Stevens, F. C. Meral, J. Yu, I. Z. Apostolakis, J.-L. Robert, and R. J. Van Sloun, “Dehazing ultrasound using diffusion models,” IEEE Transactions on Medical Imaging , 2024
work page 2024
-
[41]
Ultrasound image reconstruction with denoising diffusion restoration models,
Y . Zhang, C. Huneau, J. Idier, and D. Mateus, “Ultrasound image reconstruction with denoising diffusion restoration models,” in Interna- tional Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2023, pp. 193–203
work page 2023
-
[42]
Sequential posterior sampling with diffusion models,
T. S. Stevens, O. Nolan, J.-L. Robert, and R. J. Van Sloun, “Sequential posterior sampling with diffusion models,” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
work page 2025
-
[43]
Approximating the kullback leibler di- vergence between gaussian mixture models,
J. R. Hershey and P. A. Olsen, “Approximating the kullback leibler di- vergence between gaussian mixture models,” in2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07 , vol. 4. IEEE, 2007, pp. IV–317
work page 2007
-
[44]
zea: A Toolbox for Cognitive Ultrasound Imaging,
T. S. Stevens, W. L. van Nierop, B. Luijten, V . van de Schaft, O. I. Nolan, B. Federici, L. D. van Harten, S. W. Penninga, N. I. Schueler, and R. J. van Sloun, “zea: A Toolbox for Cognitive Ultrasound Imaging,” Jul. 2025. [Online]. Available: https://github.com/tue-bmd/zea
work page 2025
-
[45]
Video-based AI for beat-to-beat assessment of cardiac function,
D. Ouyang, B. He, A. Ghorbani, N. Yuan, J. Ebinger, C. P. Langlotz, P. A. Heidenreich, R. A. Harrington, D. H. Liang, E. A. Ashley, and J. Y . Zou, “Video-based AI for beat-to-beat assessment of cardiac function,” Nature, vol. 580, no. 7802, pp. 252–256, Apr. 2020
work page 2020
-
[46]
JAX: composable transformations of Python+NumPy programs,
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman- Milne, and Q. Zhang, “JAX: composable transformations of Python+NumPy programs,” 2018. [Online]. Available: http: //github.com/jax-ml/jax
work page 2018
-
[47]
High Volume Rate 3D Ultrasound Reconstruction with Diffusion Models
T. S. Stevens, O. Nolan, O. Somphone, J.-L. Robert, and R. J. van Sloun, “High volume rate 3d ultrasound reconstruction with diffusion models,” arXiv preprint arXiv:2505.22090 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.