Accelerating Edge Inference for Distributed MoE Models with Latency-Optimized Expert Placement
Pith reviewed 2026-05-18 22:48 UTC · model grok-4.3
The pith
Prism places experts across edge servers to cut MoE inference latency by exploiting sparsity and input locality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By leveraging the intrinsic sparsity and input locality of MoE workloads, an activation-aware placement strategy that balances local request coverage with memory utilization, supplemented by a runtime migration mechanism, minimizes inter-server communication and optimizes expert distribution under diverse resource constraints, resulting in up to 30.6% lower inference latency.
What carries the argument
Activation-aware placement strategy that balances local request coverage with memory utilization, together with a runtime migration mechanism for adapting to dynamic workloads.
If this is right
- Collaborative edge serving becomes viable for large-capacity MoE models without cloud infrastructure.
- Communication overhead drops because most expert activations stay local to the server that receives the request.
- The system continues to perform when hardware varies across servers and when request patterns shift over time.
- Lower latency makes real-time edge applications using sparse large models more practical.
Where Pith is reading between the lines
- If locality holds across more datasets, similar placement logic could apply to other sparse neural architectures beyond MoE.
- Edge deployments could reduce reliance on remote data centers, improving response times and data privacy.
- The same balancing of coverage and memory might extend to energy or thermal constraints on battery-powered devices.
Load-bearing premise
The approach assumes that the intrinsic sparsity and input locality of MoE workloads can be reliably exploited to minimize inter-server communication even under heterogeneous hardware constraints and dynamic workloads.
What would settle it
Running the same MoE models on a multi-server edge testbed with measured input traces and observing no reduction in cross-server transfers or latency would show the placement strategy does not deliver the claimed gains.
Figures






read the original abstract
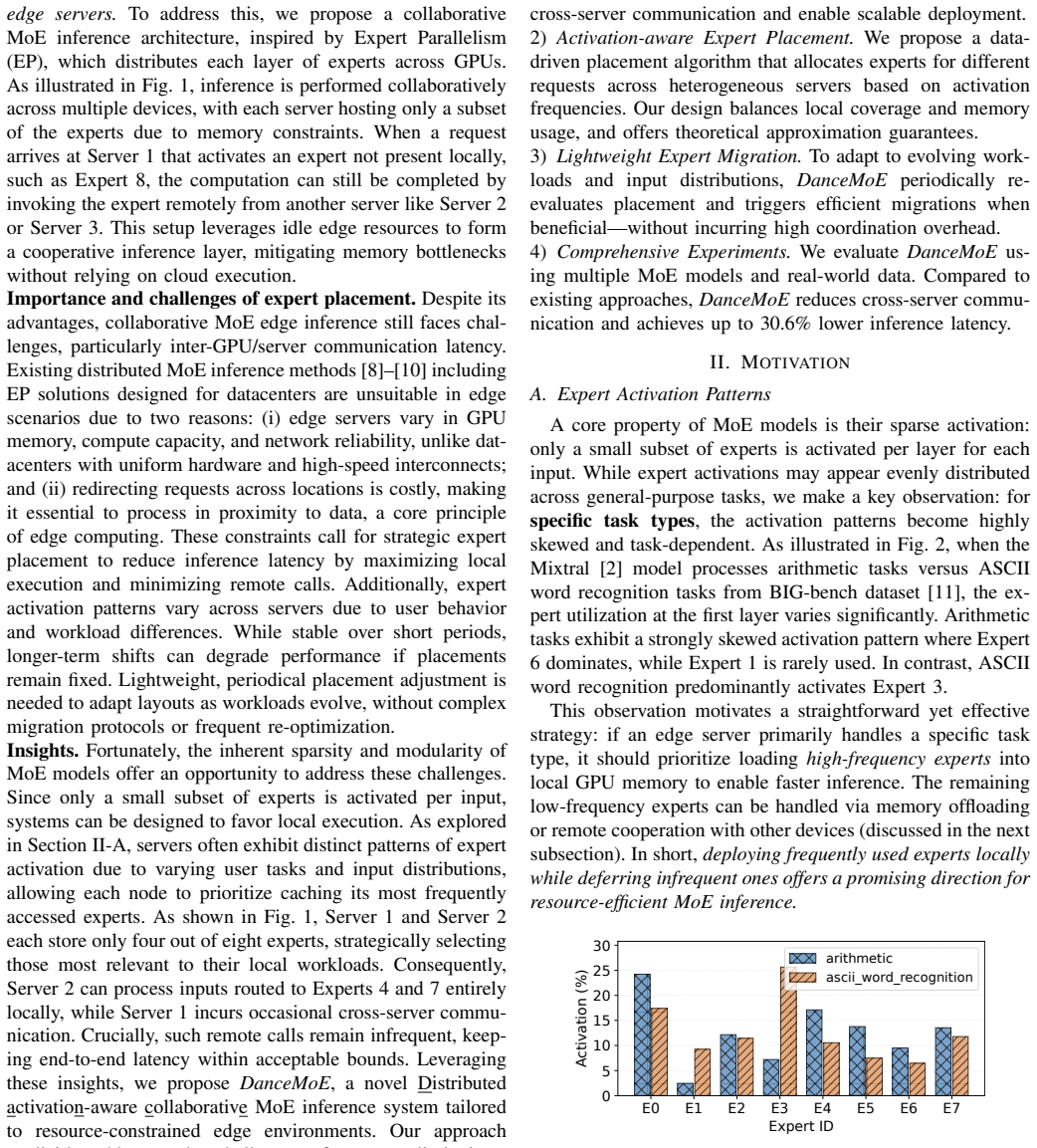
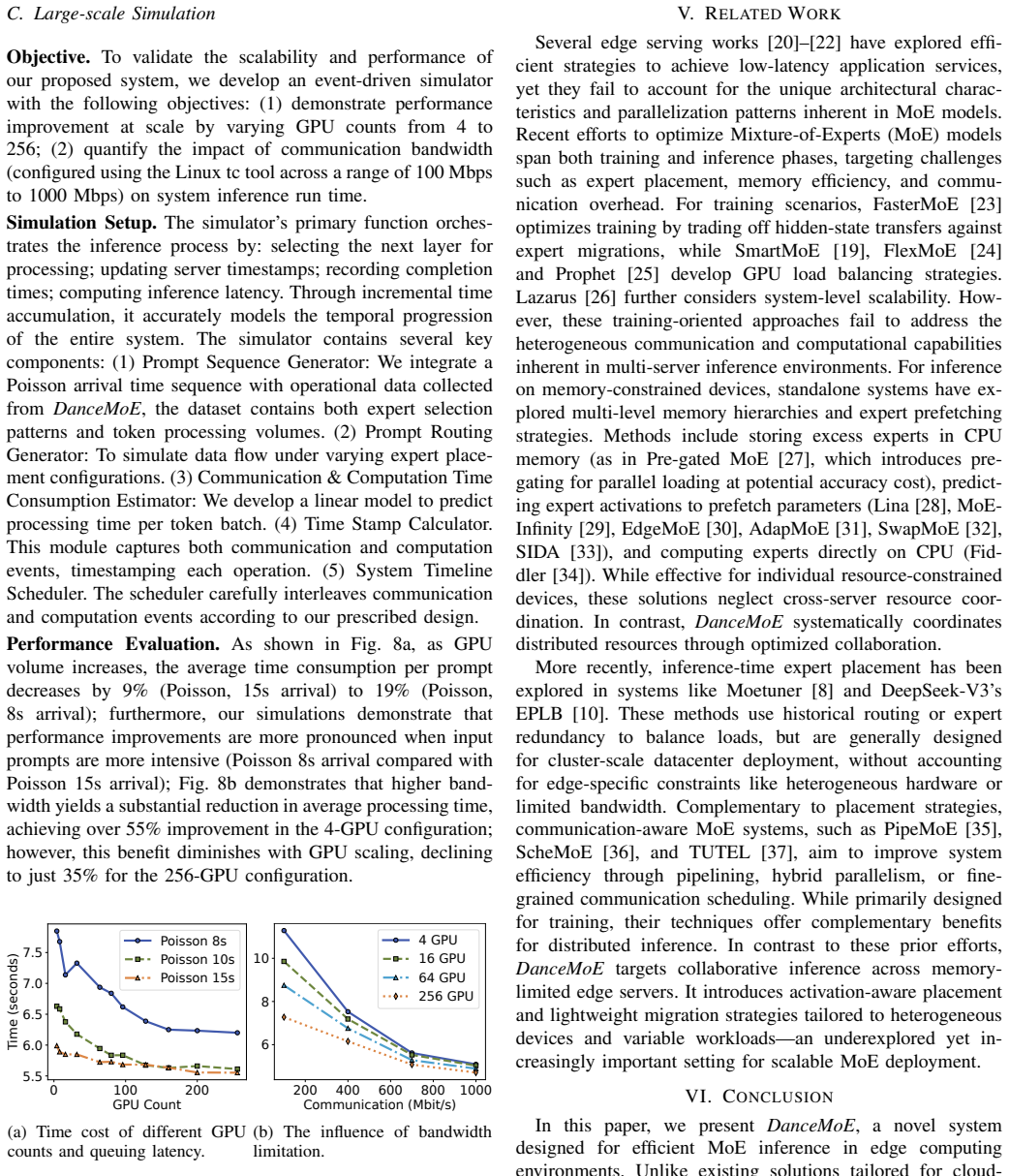
The emergence of Mixture-of-Experts (MoE) has transformed the scaling of large language models by enabling vast model capacity through sparse activation. Yet, converting these performance gains into practical edge deployment remains difficult, as the massive memory footprint and communication demands often overwhelm resource-limited environments. While centralized cloud-based solutions are available, they are frequently plagued by prohibitive infrastructure costs, latency issues, and privacy concerns. Moreover, existing edge-oriented optimizations largely overlook the complexities of heterogeneous hardware, focusing instead on isolated or uniform device setups. In response, this paper proposes Prism, an inference framework engineered for collaborative MoE serving across diverse GPU-equipped edge servers. By leveraging the intrinsic sparsity and input locality of MoE workloads, Prism minimizes inter-server communication and optimizes expert placement within diverse resource constraints. The framework integrates an activation-aware placement strategy that balances local request coverage with memory utilization, supplemented by a runtime migration mechanism to adapt expert distribution to dynamic workload changes. Experiments on contemporary MoE models and datasets demonstrate that Prism reduces inference latency by up to 30.6% and significantly lowers communication costs compared to state-of-the-art baselines, confirming the effectiveness of cooperative edge-based MoE serving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Prism, a framework for collaborative MoE inference across heterogeneous GPU-equipped edge servers. It introduces an activation-aware expert placement strategy that balances local request coverage with memory constraints and a runtime migration mechanism to adapt to workload changes, exploiting MoE sparsity and input locality to reduce inter-server communication. Experiments on contemporary MoE models and datasets are reported to achieve up to 30.6% lower inference latency and reduced communication costs versus state-of-the-art baselines.
Significance. If the performance claims are robustly supported, the work would be significant for practical edge deployment of large MoE models, offering a path to lower latency, reduced cloud dependency, and better privacy. The combination of static placement and dynamic migration tailored to MoE properties addresses a relevant gap in distributed systems for edge AI.
major comments (2)
- [§5] §5 (Experimental Evaluation): The headline result of up to 30.6% latency reduction is presented without explicit details on the number of distinct hardware profiles tested, the frequency and magnitude of injected workload shifts, or statistical significance across runs. This directly impacts the central claim that the placement-plus-migration approach reliably exploits sparsity and locality under heterogeneous and dynamic conditions, as the skeptic note correctly flags.
- [§4.2] §4.2 (Runtime Migration Mechanism): No overhead analysis or bound is provided for the cost of expert migration itself; if migration frequency is high under realistic dynamism, the net communication savings could be eroded, undermining the reported latency gains.
minor comments (2)
- [Abstract] Abstract and §5: The phrase 'significantly lowers communication costs' should be accompanied by concrete percentages or absolute values for clarity and comparability.
- [§3] Notation in §3 (System Model): Define the placement variables and locality metric more formally, perhaps with a small example or pseudocode, to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the presentation of our experimental results and analysis.
read point-by-point responses
-
Referee: [§5] §5 (Experimental Evaluation): The headline result of up to 30.6% latency reduction is presented without explicit details on the number of distinct hardware profiles tested, the frequency and magnitude of injected workload shifts, or statistical significance across runs. This directly impacts the central claim that the placement-plus-migration approach reliably exploits sparsity and locality under heterogeneous and dynamic conditions, as the skeptic note correctly flags.
Authors: We appreciate this observation on the experimental evaluation. The current manuscript describes the heterogeneous GPU setups and the dynamic workload changes used to test Prism, but we agree that greater explicitness would better substantiate the central claims. In the revised version, we will expand §5 to include: an enumerated list of the distinct hardware profiles (specific GPU models, memory sizes, and server counts); the precise parameters for workload shifts (e.g., shift frequency in terms of request intervals and magnitude as percentage changes in activation distributions); and statistical reporting with means and standard deviations over repeated runs. These additions will more clearly demonstrate the reliability of the latency reductions under the tested heterogeneous and dynamic conditions. revision: yes
-
Referee: [§4.2] §4.2 (Runtime Migration Mechanism): No overhead analysis or bound is provided for the cost of expert migration itself; if migration frequency is high under realistic dynamism, the net communication savings could be eroded, undermining the reported latency gains.
Authors: We acknowledge the importance of quantifying migration overhead to validate the net benefits. Section 4.2 presents the design of the runtime migration mechanism and its use of MoE sparsity and locality, yet does not include a dedicated cost analysis. In the revision, we will add an overhead analysis to §4.2 that measures migration time and communication volume across scenarios and derives a practical bound on migration frequency based on observed input locality patterns. This will show that, under realistic dynamism, the overhead remains limited and does not erode the reported communication savings or latency improvements. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces Prism as a new engineering framework combining activation-aware expert placement and runtime migration for distributed MoE inference on heterogeneous edge servers. Its central claims rest on empirical experiments measuring latency and communication reductions against baselines, not on any closed mathematical derivation, parameter fitting renamed as prediction, or self-citation chain. No equations, uniqueness theorems, or ansatzes are presented that reduce to the inputs by construction; the workload sparsity and locality assumptions are treated as external properties to be exploited rather than defined into the result. The reported performance numbers therefore constitute independent evidence rather than tautological restatements.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
activation-aware placement algorithm that balances local coverage and memory usage... greedy assignment An returned by Algorithm 2 satisfies Un(An) ≥ (1−1/e)·Un(A∗n)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,” Journal of Machine Learning Research , vol. 23, no. 120, pp. 1–39, 2022
work page 2022
-
[2]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bam- ford, D. S. Chaplot, D. d. l. Casas, E. B. Hanna, F. Bressand et al. , “Mixtral of experts,” arXiv preprint arXiv:2401.04088 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan et al., “Deepseek-v3 technical report,” arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
NVIDIA, “Geforce rtx 40 series,” https://www.nvidia.com/en- us/geforce/graphics-cards/40-series/, 2025
work page 2025
-
[5]
Gpunion: Autonomous gpu sharing on campus,
Y . Li, Y . Zhang, H. Liao, G. Tang, and D. Guo, “Gpunion: Autonomous gpu sharing on campus,” https://arxiv.org/html/2507.18928v1, 2025
-
[7]
Fate: Fast edge inference of mixture-of-experts models via cross-layer gate,
Z. Fang, Z. Hong, Y . Huang, Y . Lyu, W. Chen, Y . Yu, F. Yu, and Z. Zheng, “Fate: Fast edge inference of mixture-of-experts models via cross-layer gate,” https://arxiv.org/html/2502.12224v2, 2025
-
[8]
Moetuner: Optimized mixture of expert serving with balanced expert placement and token routing
S. Go and D. Mahajan, “Moetuner: Optimized mixture of expert serving with balanced expert placement and token routing,” arXiv preprint arXiv:2502.06643, 2025
-
[9]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catan- zaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism,” arXiv preprint arXiv:1909.08053 , 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[10]
Expert Parallelism Load Balancer (EPLB),
DeepSeek, “Expert Parallelism Load Balancer (EPLB),” https://github. com/deepseek-ai/EPLB, 2025, accessed: March 24, 2025
work page 2025
-
[11]
Beyond the imitation game: Quantifying and extrapolating the capabilities of language models,
B. bench authors, “Beyond the imitation game: Quantifying and extrapolating the capabilities of language models,” Transactions on Machine Learning Research , 2023. [Online]. Available: https: //openreview.net/forum?id=uyTL5Bvosj
work page 2023
-
[12]
Moe-infinity: Efficient moe inference on personal machines with sparsity-aware expert cache,
L. Xue, Y . Fu, Z. Lu, L. Mai, and M. Marina, “Moe-infinity: Efficient moe inference on personal machines with sparsity-aware expert cache,” 2024
work page 2024
-
[13]
R. Qin, Z. Li, W. He, J. Cui, F. Ren, M. Zhang, Y . Wu, W. Zheng, and X. Xu, “Mooncake: Trading more storage for less computation — a KVCache-centric architecture for serving LLM chatbot,” in 23rd USENIX Conference on File and Storage Technologies (FAST 25). Santa Clara, CA: USENIX Association, Feb. 2025, pp. 155–170. [Online]. Available: https://www.usen...
work page 2025
-
[14]
T. M. Cover and J. A. Thomas, Elements of Information Theory. Wiley- Interscience, 2006
work page 2006
-
[15]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
A. Liu, B. Feng, B. Wang, B. Wang, B. Liu, C. Zhao, C. Dengr, C. Ruan, D. Dai, D. Guo et al., “Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model,” arXiv preprint arXiv:2405.04434 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Y . Wang, X. Ma, G. Zhang, Y . Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang et al., “Mmlu-pro: A more robust and chal- lenging multi-task language understanding benchmark,” arXiv preprint arXiv:2406.01574, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Pointer sentinel mixture models,
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,” 2016
work page 2016
-
[18]
Taco: Topics in algorithmic code generation dataset.arXiv preprint arXiv:2312.14852,
R. Li, J. Fu, B.-W. Zhang, T. Huang, Z. Sun, C. Lyu, G. Liu, Z. Jin, and G. Li, “Taco: Topics in algorithmic code generation dataset,” arXiv preprint arXiv:2312.14852, 2023
-
[19]
M. Zhai, J. He, Z. Ma, Z. Zong, R. Zhang, and J. Zhai, “ {SmartMoE}: Efficiently training {Sparsely-Activated} models through combining offline and online parallelization,” in 2023 USENIX Annual Technical Conference (USENIX ATC 23) , 2023, pp. 961–975
work page 2023
-
[20]
R. Li, Z. Zhou, X. Zhang, and X. Chen, “Joint application placement and request routing optimization for dynamic edge computing service management,” IEEE Transactions on Parallel and Distributed Systems , vol. 33, no. 12, pp. 4581–4596, 2022
work page 2022
-
[21]
Y . Li, X. Zhang, T. Zeng, J. Duan, C. Wu, D. Wu, and X. Chen, “Task placement and resource allocation for edge machine learning: A gnn- based multi-agent reinforcement learning paradigm,” IEEE Transactions on Parallel and Distributed Systems , vol. 34, no. 12, pp. 3073–3089, 2023
work page 2023
-
[22]
Tapfinger: Task place- ment and fine-grained resource allocation for edge machine learning,
Y . Li, T. Zeng, X. Zhang, J. Duan, and C. Wu, “Tapfinger: Task place- ment and fine-grained resource allocation for edge machine learning,” in IEEE INFOCOM 2023-IEEE Conference on Computer Communications. IEEE, 2023, pp. 1–10
work page 2023
-
[23]
Faster- moe: modeling and optimizing training of large-scale dynamic pre- trained models,
J. He, J. Zhai, T. Antunes, H. Wang, F. Luo, S. Shi, and Q. Li, “Faster- moe: modeling and optimizing training of large-scale dynamic pre- trained models,” in Proceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, 2022, pp. 120–134
work page 2022
-
[24]
Flexmoe: Scaling large-scale sparse pre-trained model training via dynamic device placement,
X. Nie, X. Miao, Z. Wang, Z. Yang, J. Xue, L. Ma, G. Cao, and B. Cui, “Flexmoe: Scaling large-scale sparse pre-trained model training via dynamic device placement,” Proceedings of the ACM on Management of Data, vol. 1, no. 1, pp. 1–19, 2023
work page 2023
-
[25]
Prophet: Fine-grained load balancing for parallel training of large- scale moe models,
W. Wang, Z. Lai, S. Li, W. Liu, K. Ge, Y . Liu, A. Shen, and D. Li, “Prophet: Fine-grained load balancing for parallel training of large- scale moe models,” in 2023 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, 2023, pp. 82–94
work page 2023
-
[26]
Lazarus: Resilient and elastic training of mixture-of-experts models with adaptive expert placement,
Y . Wu, W. Qu, T. Tao, Z. Wang, W. Bai, Z. Li, Y . Tian, J. Zhang, M. Lentz, and D. Zhuo, “Lazarus: Resilient and elastic training of mixture-of-experts models with adaptive expert placement,” arXiv preprint arXiv:2407.04656, 2024
-
[27]
Pre-gated moe: An algorithm-system co-design for fast and scalable mixture-of-expert inference,
R. Hwang, J. Wei, S. Cao, C. Hwang, X. Tang, T. Cao, and M. Yang, “Pre-gated moe: An algorithm-system co-design for fast and scalable mixture-of-expert inference,” in 2024 ACM/IEEE 51st Annual Interna- tional Symposium on Computer Architecture (ISCA) . IEEE, 2024, pp. 1018–1031
work page 2024
-
[28]
Accelerating distributed {MoE} training and inference with lina,
J. Li, Y . Jiang, Y . Zhu, C. Wang, and H. Xu, “Accelerating distributed {MoE} training and inference with lina,” in 2023 USENIX Annual Technical Conference (USENIX ATC 23) , 2023, pp. 945–959
work page 2023
-
[29]
Leyang Xue, Yao Fu, Zhan Lu, Luo Mai, and Mahesh K
L. Xue, Y . Fu, Z. Lu, L. Mai, and M. Marina, “Moe-infinity: Activation- aware expert offloading for efficient moe serving,” arXiv preprint arXiv:2401.14361, 2024
-
[30]
Edgemoe: Fast on-device inference of moe-based large language models,
R. Yi, L. Guo, S. Wei, A. Zhou, S. Wang, and M. Xu, “Edgemoe: Fast on-device inference of moe-based large language models,” arXiv preprint arXiv:2308.14352, 2023
-
[31]
Adapmoe: Adaptive sensitivity-based expert gating and management for efficient moe inference,
S. Zhong, L. Liang, Y . Wang, R. Wang, R. Huang, and M. Li, “Adapmoe: Adaptive sensitivity-based expert gating and management for efficient moe inference,” arXiv preprint arXiv:2408.10284 , 2024
-
[32]
Swapmoe: Serving off-the-shelf moe-based large language models with tunable memory budget,
R. Kong, Y . Li, Q. Feng, W. Wang, X. Ye, Y . Ouyang, L. Kong, and Y . Liu, “Swapmoe: Serving off-the-shelf moe-based large language models with tunable memory budget,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 6710–6720
work page 2024
-
[33]
Z. Du, S. Li, Y . Wu, X. Jiang, J. Sun, Q. Zheng, Y . Wu, A. Li, H. Li, and Y . Chen, “Sida: Sparsity-inspired data-aware serving for efficient and scalable large mixture-of-experts models,” Proceedings of Machine Learning and Systems , vol. 6, pp. 224–238, 2024
work page 2024
-
[34]
semanticscholar.org/CorpusID:267211688
K. Kamahori, T. Tang, Y . Gu, K. Zhu, and B. Kasikci, “Fiddler: Cpu- gpu orchestration for fast inference of mixture-of-experts models,” arXiv preprint arXiv:2402.07033, 2024
-
[35]
Pipemoe: Accelerating mixture- of-experts through adaptive pipelining,
S. Shi, X. Pan, X. Chu, and B. Li, “Pipemoe: Accelerating mixture- of-experts through adaptive pipelining,” in IEEE INFOCOM 2023-IEEE Conference on Computer Communications . IEEE, 2023, pp. 1–10
work page 2023
-
[36]
Schemoe: An extensible mixture-of-experts distributed training system with tasks scheduling,
S. Shi, X. Pan, Q. Wang, C. Liu, X. Ren, Z. Hu, Y . Yang, B. Li, and X. Chu, “Schemoe: An extensible mixture-of-experts distributed training system with tasks scheduling,” in Proceedings of the Nineteenth European Conference on Computer Systems , 2024, pp. 236–249
work page 2024
-
[37]
Tutel: Adaptive mixture-of-experts at scale,
C. Hwang, W. Cui, Y . Xiong, Z. Yang, Z. Liu, H. Hu, Z. Wang, R. Salas, J. Jose, P. Ram et al. , “Tutel: Adaptive mixture-of-experts at scale,” Proceedings of Machine Learning and Systems , vol. 5, pp. 269–287, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.