Dynamic read & write optimization with TurtleKV
Pith reviewed 2026-05-18 16:53 UTC · model grok-4.3
The pith
TurtleKV achieves balanced high performance in dynamic key-value workloads using a new TurtleTree structure and adjustable memory knobs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
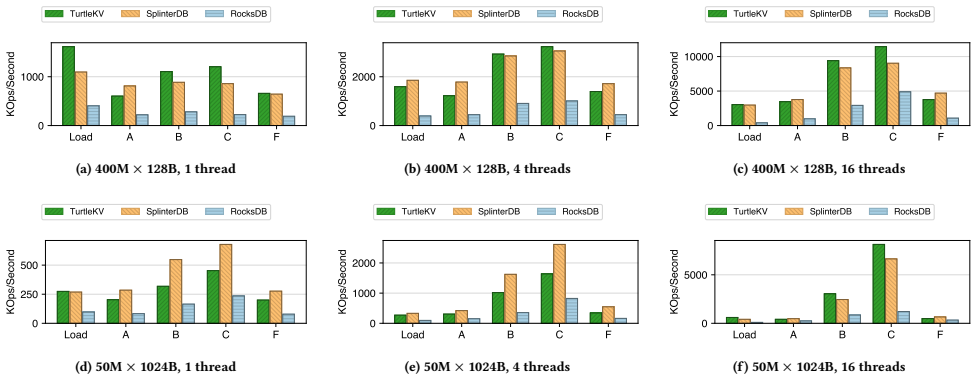
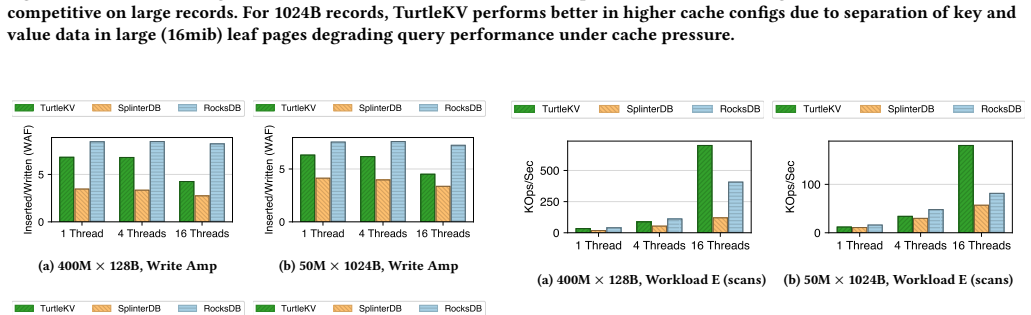
The central discovery is that a read-/write-balanced on-disk structure called the TurtleTree, paired with flexible read-memory and write-memory tuning knobs, supports high performance for mixed and dynamic workloads in a key-value store. The design enables matching state-of-the-art performance on inserts while providing speedups in mixed, point-query, and scan operations compared to existing systems.
What carries the argument
The TurtleTree, a novel read-/write-balanced on-disk structure that supports the dynamic optimization through separate read-memory and write-memory tuning knobs.
Load-bearing premise
The YCSB workload mixes and tuning settings represent real dynamic scenarios without introducing unaccounted bottlenecks or correctness problems in the TurtleTree design.
What would settle it
Running the same YCSB benchmarks on different hardware or with workload mixes that stress memory differently would show if the reported speedups hold or if hidden limitations appear.
Figures







read the original abstract
High read and write performance is important for generic key-value stores, which are foundational to modern applications and databases. Yet, achieving high performance for mixed and dynamic workloads is challenging due to fundamental trade-offs between memory use and I/O for retrieval and updates. Past work emphasizes the trade-off between read- and write-optimization as expressed through primary data structure, in combination with read-memory trade-off mechanisms like caching and filtering. This raises re-tuning costs as optimal trade-off targets change, due to restructuring of stored data. We show that write-memory trade-off mechanisms are under-developed in current designs, and propose a new approach to dynamic key-value store optimization using a novel read-/write-balanced on-disk structure, the TurtleTree, and flexible read-memory & write-memory tuning knobs. We describe how the design of TurtleKV, our prototype, avoids in-memory bottlenecks to achieve high performance across a wide range of tuning parameters. When evaluated using YCSB, TurtleKV matches state-of-the-art SplinterDB for inserts, and is 5x/12x faster than RockDB/WiredTiger. In mixed workloads, TurtleKV is 16-25% faster than SplinterDB, >4x RocksDB, and 3-6x WiredTiger. TurtleKV is 2-9x faster than the others for point-query workloads, and has the best scan performance of the write-optimized systems tested.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TurtleKV, a key-value store that uses a novel TurtleTree on-disk structure together with flexible read-memory and write-memory tuning knobs to support dynamic read/write optimization. The central claim is that this design avoids re-tuning costs and hidden bottlenecks associated with data restructuring in prior systems, delivering high performance across workloads as shown by YCSB benchmarks where TurtleKV matches SplinterDB on inserts, outperforms RocksDB and WiredTiger by large factors, and leads in mixed, point-query, and scan workloads.
Significance. If the empirical results hold under dynamic conditions, the work addresses an under-explored aspect of write-memory trade-offs in KV stores and could enable more adaptive systems for changing workloads. The reported throughput advantages constitute a concrete contribution, though the absence of tests with mid-experiment workload shifts limits verification of the dynamic-adaptation aspect.
major comments (1)
- [Evaluation] Evaluation section: The YCSB results cover separate fixed workloads (insert-only, mixed, point queries, scans) but present no experiments in which read/write ratios or access patterns change during a run. This directly undercuts the central claim that the TurtleTree and memory knobs enable dynamic optimization without re-tuning costs or hidden bottlenecks, as any restructuring overhead or correctness issues would only surface under such transitions.
minor comments (2)
- [Abstract] Abstract: 'RockDB' is likely a typographical error for 'RocksDB'.
- [Abstract] The abstract and results summary provide limited detail on experimental controls, error bars, data-exclusion rules, or how the read/write-memory tuning parameters were selected for each workload.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address the major comment on the evaluation below.
read point-by-point responses
-
Referee: The YCSB results cover separate fixed workloads (insert-only, mixed, point queries, scans) but present no experiments in which read/write ratios or access patterns change during a run. This directly undercuts the central claim that the TurtleTree and memory knobs enable dynamic optimization without re-tuning costs or hidden bottlenecks, as any restructuring overhead or correctness issues would only surface under such transitions.
Authors: We agree that experiments with mid-run workload transitions would provide additional support for the dynamic-optimization claim. The central contribution of TurtleKV is that the TurtleTree is a single balanced on-disk structure that does not require data restructuring when read/write optimization targets change; the read-memory and write-memory knobs simply adjust allocation ratios at runtime. Because no stored data is reorganized, the only cost of a tuning change is the (low) overhead of the knob adjustment itself. The YCSB results demonstrate that high performance is achievable across a wide range of fixed tuning points without hidden bottlenecks, which is the necessary precondition for low-cost dynamic adaptation. We will revise the manuscript to make this design distinction and its implications for dynamic use more explicit. If space and time permit, we are also willing to add a modest dynamic-workload experiment in the revision. revision: partial
Circularity Check
No derivation chain; empirical YCSB results are self-contained
full rationale
The paper describes a new on-disk structure (TurtleTree) and memory knobs for dynamic read/write optimization in TurtleKV, then reports direct throughput measurements from YCSB workloads (insert-only, mixed, point queries, scans). No equations, fitted parameters, or predictions appear in the abstract or described claims; performance numbers are presented as observed results rather than quantities derived from inputs by construction. Self-citations, if present, are not load-bearing for any central result. The evaluation is therefore independent of the patterns that would produce circularity scores above 2.
Axiom & Free-Parameter Ledger
free parameters (1)
- read-memory and write-memory tuning knobs
axioms (1)
- domain assumption Fundamental trade-offs between memory use and I/O for retrieval and updates exist and must be managed in key-value store design.
invented entities (1)
-
TurtleTree
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
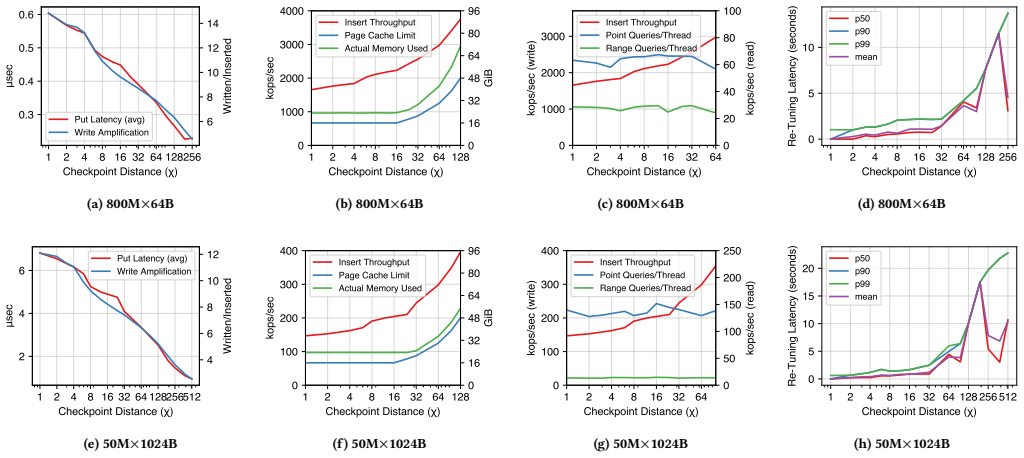
TurtleTrees are a fusion of B+-trees and LSM-trees... checkpoint distance (χ) controls the portion of TurtleKV’s total memory devoted to improving write performance
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify TurtleTrees as belonging to a previously unidentified category of data structures, which we name Bε+-trees
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alok Aggarwal and Jeffrey Vitter, S. 1988. The Input/Output Complexity of Sorting and Related Problems.Commun. ACM31, 9 (Sept. 1988), 1116–1127. https://doi.org/10.1145/48529.48535
-
[2]
Apache. 2025. Apache Cassandra. https://cassandra.apache.org/_/index.html. Retrieved August, 2025
work page 2025
-
[3]
Tony Astolfi, Vidya Silai, and Bhaskar Bora. 2024. Mathworks/Llfs. MathWorks
work page 2024
-
[4]
Manos Athanassoulis, Michael S Kester, Lukas M Maas, Radu Stoica, Stratos Idreos, Anastasia Ailamaki, and Mark Callaghan. 2016. Designing Access Meth- ods: The RUM Conjecture.EDBT(2016)
work page 2016
-
[5]
Michael A. Bender, Alex Conway, Martín Farach-Colton, William Jannen, Yizheng Jiao, Rob Johnson, Eric Knorr, Sara McAllister, Nirjhar Mukherjee, Prashant Pandey, Donald E. Porter, Jun Yuan, and Yang Zhan. 2019. Small Refinements to the DAM Can Have Big Consequences for Data-Structure Design. InThe 31st ACM Symposium on Parallelism in Algorithms and Archit...
-
[6]
Michael A. Bender, Alex Conway, Martín Farach-Colton, William Jannen, Yizheng Jiao, Rob Johnson, Eric Knorr, Sara Mcallister, Nirjhar Mukherjee, Prashant Pandey, Donald E. Porter, Jun Yuan, and Yang Zhan. 2021. External-Memory Dictionaries in the Affine and PDAM Models.ACM Transactions on Parallel Computing8, 3 (Sept. 2021), 1–20. https://doi.org/10.1145/3470635
-
[7]
Bender, Martin Farach-Colton, Jeremy T
Michael A. Bender, Martin Farach-Colton, Jeremy T. Fineman, Yonatan R. Fogel, Bradley C. Kuszmaul, and Jelani Nelson. 2007. Cache-Oblivious Streaming B-trees. InProceedings of the Nineteenth Annual ACM Symposium on Parallel Algorithms and Architectures. ACM, San Diego California USA, 81–92. https: //doi.org/10.1145/1248377.1248393
-
[8]
Michael A Bender, Martin Farach-Colton, William Jannen, Rob Johnson, Bradley C Kuszmaul, Donald E Porter, Jun Yuan, and Yang Zhan. 2015. An Introduction to B𝜀-trees and Write-Optimization.login; magazine40, 5 (Sept. 2015)
work page 2015
-
[9]
Burton H. Bloom. 1970. Space/Time Trade-Offs in Hash Coding with Allowable Errors.Commun. ACM13, 7 (July 1970), 422–426. https://doi.org/10.1145/362686. 362692
-
[10]
Gerth Stølting Brodal and Rolf Fagerberg. 2003. Lower Bounds for External Memory Dictionaries.ACM-SIAM Symposium on Discrete Algorithms (SODA)3 (2003)
work page 2003
-
[11]
Badrish Chandramouli, Guna Prasaad, Donald Kossmann, Justin Levandoski, James Hunter, and Mike Barnett. 2018. FASTER: A Concurrent Key-Value Store with In-Place Updates. InProceedings of the 2018 International Conference on Management of Data. ACM, Houston TX USA, 275–290. https://doi.org/10.1145/ 3183713.3196898
-
[12]
Badrish Chandramouli, Guna Prasaad, Donald Kossmann, Justin Levandoski, James Hunter, and Mike Barnett. 2018. FASTER: An Embedded Concurrent Key-Value Store for State Management.Proceedings of the VLDB Endowment11, 12 (Aug. 2018), 1930–1933. https://doi.org/10.14778/3229863.3236227
- [13]
-
[14]
Douglas Comer. 1979. Ubiquitous B-Tree.Comput. Surveys11, 2 (June 1979), 121–137. https://doi.org/10.1145/356770.356776
-
[15]
Alexander Conway, Vijay Chidambaram, Martin Farach-Colton, and Rob Johnson
-
[16]
SplinterDB: Closing the Bandwidth Gap for NVMe Key-Value Stores.2020 USENIX Annual Technical Conference (USENIX ATC 20)(2020)
work page 2020
-
[17]
Alex Conway, Martín Farach-Colton, and Rob Johnson. 2023. SplinterDB and Maplets: Improving the Tradeoffs in Key-Value Store Compaction Pol- icy.Proceedings of the ACM on Management of Data1, 1 (May 2023), 1–27. https://doi.org/10.1145/3588726
-
[18]
Alex Conway, Martin Farach-Colton, and Philip Shilane. 2018. Optimal Hashing in External Memory. https://doi.org/10.48550/arXiv.1805.09423 arXiv:1805.09423 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1805.09423 2018
-
[19]
Benchmarking cloud serving systems with ycsb,
Brian F. Cooper, Adam Silberstein, Erwin Tam, Raghu Ramakrishnan, and Russell Sears. 2010. Benchmarking cloud serving systems with YCSB. InProceedings of the 1st ACM Symposium on Cloud Computing(Indianapolis, Indiana, USA) (SoCC ’10). Association for Computing Machinery, New York, NY, USA, 143–154. https://doi.org/10.1145/1807128.1807152
-
[20]
Databricks. [n.d.]. Extract Transform Load (ETL). https://www.databricks.com/ discover/etl. Retrieved August, 2025
work page 2025
-
[21]
Niv Dayan, Manos Athanassoulis, and Stratos Idreos. 2017. Monkey: Optimal Navigable Key-Value Store. InProceedings of the 2017 ACM International Con- ference on Management of Data. ACM, Chicago Illinois USA, 79–94. https: //doi.org/10.1145/3035918.3064054
-
[22]
Niv Dayan, Manos Athanassoulis, and Stratos Idreos. 2018. Optimal Bloom Filters and Adaptive Merging for LSM-Trees.ACM Transactions on Database Systems43, 4 (Dec. 2018), 1–48. https://doi.org/10.1145/3276980
-
[23]
Niv Dayan and Stratos Idreos. 2018. Dostoevsky: Better Space-Time Trade-Offs for LSM-Tree Based Key-Value Stores via Adaptive Removal of Superfluous Merging. InProceedings of the 2018 International Conference on Management of Data. ACM, Houston TX USA, 505–520. https://doi.org/10.1145/3183713.3196927
-
[24]
Niv Dayan and Stratos Idreos. 2019. The Log-Structured Merge-Bush & the Wacky Continuum. InProceedings of the 2019 International Conference on Management of Data. ACM, Amsterdam Netherlands, 449–466. https://doi.org/10.1145/3299869. 3319903
-
[25]
Google. [n.d.]. LevelDB. https://github.com/google/leveldb. Retrieved August, 2025
work page 2025
-
[26]
Xiangpeng Hao and Badrish Chandramouli. 2024. Bf-Tree: A Modern Read- Write-Optimized Concurrent Larger-Than-Memory Range Index.Proc. VLDB Endow.17, 11 (July 2024), 3442–3455. https://doi.org/10.14778/3681954.3682012
-
[27]
TGL: a general framework for temporal GNN training on billion-scale graphs
Andy Huynh, Harshal A. Chaudhari, Evimaria Terzi, and Manos Athanas- soulis. 2022. Endure: a robust tuning paradigm for LSM trees under work- load uncertainty.Proc. VLDB Endow.15, 8 (April 2022), 1605–1618. https: //doi.org/10.14778/3529337.3529345
-
[28]
Stratos Idreos, Niv Dayan, Wilson Qin, Mali Akmanalp, Sophie Hilgard, Andrew Ross, James Lennon, Varun Jain, Harshita Gupta, David Li, and Zichen Zhu. 2019. Design Continuums and the Path Toward Self-Designing Key-Value Stores That Know and Learn.Biennial Conference on Innovative Data Systems Research (CIDR) (2019)
work page 2019
-
[29]
Song Jiang, Feng Chen, and Xiaodong Zhang. 2005. CLOCK-Pro: An Effective Improvement of the CLOCK Replacement. (2005)
work page 2005
-
[30]
Bo-kyeong Kim and Dong-Ho Lee. 2015. LSB-Tree: A Log-Structured B-Tree Index Structure for NAND Flash SSDs.Design Automation for Embedded Systems 19, 1-2 (March 2015), 77–100. https://doi.org/10.1007/s10617-014-9139-4
-
[31]
V. Leis, Alfons Kemper, and T. Neumann. 2013. The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases. In2013 IEEE 29th International Conference on Data Engineering (ICDE). IEEE, Brisbane, QLD, 38–49. https://doi.org/10. 1109/ICDE.2013.6544812
-
[32]
Viktor Leis, Florian Scheibner, Alfons Kemper, and Thomas Neumann. 2016. The ART of Practical Synchronization. InProceedings of the 12th International Workshop on Data Management on New Hardware. ACM, San Francisco California, 1–8. https://doi.org/10.1145/2933349.2933352
-
[33]
Baptiste Lepers, Oana Balmau, Karan Gupta, and Willy Zwaenepoel. 2019. KVell: The Design and Implementation of a Fast Persistent Key-Value Store. InPro- ceedings of the 27th ACM Symposium on Operating Systems Principles. ACM, Huntsville Ontario Canada, 447–461. https://doi.org/10.1145/3341301.3359628
-
[34]
Baptiste Lepers, Oana Balmau, Karan Gupta, and Willy Zwaenepoel. 2020. KVell+: Snapshot Isolation without Snapshots.14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20)(2020)
work page 2020
-
[35]
Justin Levandoski and Sudipta Sengupta. [n.d.]. The BW-Tree: A Latch-Free B-Tree for Log-Structured Flash Storage. ([n. d.])
-
[36]
Justin J. Levandoski, David B. Lomet, and Sudipta Sengupta. 2013. The Bw-Tree: A B-tree for new hardware platforms. In2013 IEEE 29th International Conference on Data Engineering (ICDE). 302–313. https://doi.org/10.1109/ICDE.2013.6544834
-
[37]
J. J. Levandoski, D. B. Lomet, and S. Sengupta. 2013. The Bw-Tree: A B-tree for New Hardware Platforms. In2013 IEEE 29th International Conference on Data Engineering (ICDE). IEEE, Brisbane, QLD, 302–313. https://doi.org/10.1109/ICDE. 2013.6544834
-
[38]
Meta Platforms, Inc. 2022. RocksDB. https://rocksdb.org. Retrieved July, 2025
work page 2022
-
[39]
Patrick O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth O’Neil. 1996. The Log-Structured Merge-Tree (LSM-tree).Acta Informatica33, 4 (June 1996), 351–
work page 1996
-
[40]
https://doi.org/10.1007/s002360050048
-
[41]
David A. Patterson. 2004. Latency Lags Bandwith.Commun. ACM47, 10 (Oct. 2004), 71–75. https://doi.org/10.1145/1022594.1022596
-
[42]
Lomet, Xin Liu, Panfeng Zhou, Yongxiang Chen, David Zhang, Jingren Zhou, and Jiesheng Wu
Rui Wang, Xinjun Yang, Feifei Li, David B. Lomet, Xin Liu, Panfeng Zhou, Yongxiang Chen, David Zhang, Jingren Zhou, and Jiesheng Wu. 2024. Bw e -Tree: An Evolution of Bw-tree on Fast Storage. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, Utrecht, Netherlands, 5266–5279. https://doi.org/10.1109/ICDE60146.2024.00396
-
[43]
Ziqi Wang, Andrew Pavlo, Hyeontaek Lim, Viktor Leis, Huanchen Zhang, Michael Kaminsky, and David G. Andersen. 2018. Building a Bw-Tree Takes More Than Just Buzz Words. InProceedings of the 2018 International Con- ference on Management of Data. ACM, Houston TX USA, 473–488. https: //doi.org/10.1145/3183713.3196895
-
[44]
Ke Yi. 2012. Dynamic Indexability and the Optimality of B-Trees.J. ACM59, 4 (Aug. 2012), 1–19. https://doi.org/10.1145/2339123.2339129
-
[45]
Yu, Markos Markakis, Andreas Kipf, Per-Åke Larson, Umar Farooq Minhas, and Tim Kraska
Geoffrey X. Yu, Markos Markakis, Andreas Kipf, Per-Åke Larson, Umar Farooq Minhas, and Tim Kraska. 2022. TreeLine: an update-in-place key-value store for modern storage.Proc. VLDB Endow.16, 1 (Sept. 2022), 99–112. https://doi.org/ 10.14778/3561261.3561270 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.